使用 Python 进行自然语言处理第 4 部分:文本表示

一、说明
二、文本表示
- 文本数据以字母、单词、符号、数字或所有这些的集合的形式存在。例如“印度”、“、”、“Covid19”等。
- 在我们将机器学习/深度学习算法应用于文本数据之前,我们必须以数字形式表示文本。单个单词和文本文档都可以转换为浮点数向量。
- 将标记、句子表示为数值向量的过程称为“嵌入”,这些向量的多维空间称为嵌入空间。
- 循环神经网络、长短期记忆网络、变形金刚等深度神经网络架构需要以固定维数值向量的形式输入文本。
2.1 一些术语:
- 文档:文档是许多单词的集合。
- 词汇:词汇是文档中唯一单词的集合。
- Token:Token是离散数据的基本单位。它通常指单个单词或标点符号。
- 语料库:语料库是文档的集合。
- 上下文:单词/标记的上下文是文档中左右围绕该单词/标记的单词/标记。
- 向量嵌入:基于向量的文本数字表示称为嵌入。例如,word2vec 或 GLoVE 是基于语料库统计的无监督方法。像tensorflow和keras这样的框架支持“嵌入层”。
2.2 文本表示应具有以下属性:
- 它应该唯一地标识一个单词(必须是双射)
- 应捕捉单词之间的形态、句法和语义相似性。相关词在欧德空间中应该比不相关词更接近出现。
- 这些表示应该可以进行算术运算。
- 通过表示,计算单词相似性和关系等任务应该很容易。
- 应该很容易从单词映射到其嵌入,反之亦然。
2.3 文本表示的一些突出技术:
- 一次性编码
- 词袋模型 — CountVectorizer 和带有 n 元语法的 CountVectorizer
- Tf-Idf模型
- Word2Vec 嵌入
- 手套包埋
- 快速文本嵌入
- ChatGPT 和 BERT 等 Transformer 使用自己的动态嵌入。
一热编码:
这是将文本表示为数值向量的最简单技术。每个单词都表示为由 0 和 1 组成的唯一“One-Hot”二进制向量。对于词汇表中的每个唯一单词,向量包含一个 1,其余所有值为 0,向量中 1 的位置唯一标识一个单词。
例子:
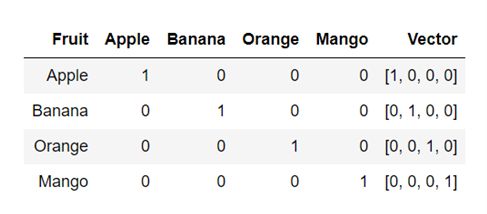
单词 Apple、Banana、Orange 和 Mango 的 OneHot 向量示例
from sklearn.preprocessing import OneHotEncoder
import nltk
from nltk import word_tokenize
document = "The rose is red. The violet is blue."
document = document.split()
tokens = [doc.split(" ") for doc in document]
wordids = {token: idx for idx, token in enumerate(set(document))}
tokenids = [[wordids[token] for token in toke] for toke in tokens]
onehotmodel = OneHotEncoder()
vectors = onehotmodel.fit_transform(tokenids)
print(vectors.todense())2.4 词袋表示:CountVectorizer
请参阅此处的详细信息:https ://en.wikipedia.org/wiki/Bag-of-words_model
词袋 (BoW) 是一种无序的文本表示形式,用于描述文档中单词的出现情况。它具有文档中已知单词的词汇表以及已知单词存在的度量。词袋模型不包含有关文档中单词的顺序或结构的任何信息。
维基百科的例子:
文档1:约翰喜欢看电影。玛丽也喜欢电影。
文件2:玛丽也喜欢看足球比赛。
词汇1:“约翰”、“喜欢”、“去”、“看”、“电影”、“玛丽”、“喜欢”、“电影”、“太”
词汇2:“玛丽”、“也”、“喜欢”、“去”、“看”、“足球”、“游戏”
BoW1 = {“约翰”:1,“喜欢”:2,“观看”:1,“观看”:1,“电影”:2,“玛丽”:1,“太”:1};
BoW2 = {“玛丽”:1,“也”:1,“喜欢”:1,“到”:1,“观看”:1,“足球”:1,“游戏”:1};
Document3 是 document1 和 document2 的并集(包含文档 1 和文档 2 中的单词)
文件3:约翰喜欢看电影。玛丽也喜欢电影。玛丽还喜欢看足球比赛。
BoW3: {“约翰”:1、“喜欢”:3、“观看”:2、“观看”:2、“电影”:2、“玛丽”:2、“太”:1、“也”:1 ,“足球”:1,“游戏”:1}
让我们编写一个函数来在用向量表示文本之前对其进行预处理。
# This process_text() function returns list of cleaned tokens of the text
import numpy
import re
import string
import unicodedata
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
stop_words = stopwords.words('english')
lemmatizer = WordNetLemmatizer()
def process_text(text):
# Remove non-ASCII characters
text = unicodedata.normalize('NFKD', text).encode('ascii', 'ignore').decode('utf-8', 'ignore')
# Remove words not starting with alphabets
text = re.sub(r'[^a-zA-Z\s]', '', text)
# Remove punctuation marks
text = text.translate(str.maketrans('', '', string.punctuation))
#Convert to lower case
text = text.lower()
# Remove stopwords
text = " ".join([word for word in str(text).split() if word not in stop_words])
# Lemmatize
text = " ".join([lemmatizer.lemmatize(word) for word in text.split()])
return text接下来,我们使用 Sklearn 库中的 CountVectorizer 将预处理后的文本转换为词袋表示。
#https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html
#https://stackoverflow.com/questions/27697766/understanding-min-df-and-max-df-in-scikit-countvectorizer
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import nltk
document = ["The", "rose", "is", "red", "The", "violet", "is", "blue"] #, "This is some text, just for demonstration"]
processed_document = [process_text(item) for item in document]
processed_document = [x for x in processed_document if x != '']
print(processed_document)
bow_countvect = CountVectorizer(min_df = 0., max_df = 1.)
matrix = bow_countvect.fit_transform(processed_document)
matrix.toarray()
vocabulary = bow_countvect.get_feature_names_out()
print(matrix)
matrix.todense()2.5 词袋表示:n-grams
Simpe Bag-of-words 模型不存储有关单词顺序的信息。n-gram 模型可以存储这些空间信息。
单词/标记被称为“gram”。n-gram 是出现在文本文档中的一组连续的 n-token。
一元词表示 1 个单词,二元词表示两个词,三元词表示一组 3 个词……
例如对于文本(来自维基百科):
文档1:约翰喜欢看电影。玛丽也喜欢电影。
二元模型将文本解析为以下单元,并像简单的 BoW 模型一样存储每个单元的术语频率。
[“约翰喜欢”、“喜欢”、“看”、“看电影”、“玛丽喜欢”、“喜欢电影”、“也看电影”,]
Bag-of-word 模型可以被认为是 n-gram 模型的特例,其中 n=1
#https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html
from sklearn.feature_extraction.text import CountVectorizer
document = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]
ngram_countvect = CountVectorizer(ngram_range = (2, 2), stop_words = 'english')
#ngram_range paramenter to count vectorizer indicates the lower and upper boundary of the range of n-values for
#different word n-grams or char n-grams to be extracted. All values of n such such that min_n <= n <= max_n will be used.
#For example an ngram_range of (1, 1) means only unigrams, (1, 2) means unigrams and bigrams, and (2, 2) means only bigrams.
matrix = ngram_countvect.fit_transform(document)
vocabulary = ngram_countvect.get_feature_names_out()
matrix.todense()三、Tf-Idf 矢量化器:术语频率 — 逆文档频率
可以在这里找到 TF-IDF 矢量器的非常好的解释
- 文档“d”中术语/单词“w”的 Tf-Idf 分数 tfidf(w,D) 是两个指标的乘积:术语频率 (tf) 和逆文档频率 (idf)。即 tfidf(w, d, C) = tf(w,d)*idf(w,d,C)
- 其中w是术语或单词,d是文档,C是包含总共N个文档(包括文档d)的语料库。
- 词频 tf(w,d) 是文档 d 中单词 w 的频率。术语频率可以根据文档的长度进行调整(出现的原始计数除以文档中的单词数),它可以是对数缩放频率(例如 log(1 + 原始计数)),也可以是布尔频率(例如,如果该术语在文档中出现,则为 1;如果该术语在文档中未出现,则为 0)。
- 文档频率:是一个术语/单词 w 在一组 N 个文档(语料库)中出现的频率。逆文档频率是衡量一个词在语料库中的常见或罕见程度的指标。更少的是 IDF,更常见的是这个词,反之亦然。单词的 IDF 是通过将语料库中的文档总数除以包含该单词的文档数量的对数来计算的。逆文档频率是术语/单词信息量的度量。频繁出现的单词信息量较少。单词的逆文档频率是在一组文档(语料库)中计算的。
from sklearn.feature_extraction.text import TfidfVectorizer
document = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]
tf_idf = TfidfVectorizer(min_df = 0., max_df = 1., use_idf = True)
tf_idf_matrix = tf_idf.fit_transform(document)
tf_idf_matrix = tf_idf_matrix.toarray()
tf_idf_matrix四、词嵌入
上述文本表示方法通常不能捕获单词的语义和上下文。为了克服这些限制,我们使用嵌入。嵌入是通过训练庞大数据集的模型来学习的。这些嵌入通过考虑句子中的相邻单词以及句子中单词的顺序来捕获单词的上下文。三个著名的词嵌入是:Word2Vec、GloVe、FastText
词向量
- 是一个在巨大文本语料库上训练的无监督模型。它创建单词的词汇表以及表示词汇表的向量空间中单词的分布式连续密集向量表示。它捕获上下文和语义的相似性。
- 我们可以指定词嵌入向量的大小。向量总数本质上就是词汇表的大小。
- Word2Vec中有两种不同的模型架构类型——CBOW(连续词袋)模型、Skip Gram模型
CBOW 模型 - 尝试根据源上下文单词预测当前目标单词。Skip Gram 模型尝试预测给定目标单词的源上下文单词。
from gensim.models import word2vec
import nltk
document = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]
tokenized_corpus = [nltk.word_tokenize(doc) for doc in document]
#parameters of word2vec model
# feature_size : integer : Word vector dimensionality
# window_context : integer : The maximum distance between the current and predicted word within a sentence.(2, 10)
# min_word_count : integer : Ignores all words with total absolute frequency lower than this - (2, 100)
# sample : integer : The threshold for configuring which higher-frequency words are randomly downsampled. Highly influencial. - (0, 1e-5)
# sg: integer: Skip-gram model configuration, CBOW by default
wordtovector = word2vec.Word2Vec(tokenized_corpus, window = 3, min_count = 1, sg = 1)
print('Embedding of the word blue')
print(wordtovector.wv['blue'])
print('Size of Embedding of the word blue')
print(wordtovector.wv['blue'].shape)如果您希望查看词汇表中的所有向量,请使用以下代码:
#All the vectors for all the words in our input text
words = wordtovector.wv.index_to_key
wvs = wordtovector.wv[words]
wvs或者将它们转换为 pandas 数据框
import pandas as pd
df = pd.DataFrame(wvs, index = words)
df五、GloVe库(手套)
- 全局向量 (GloVe) 是一种为 Word2Vec 等单词生成密集向量表示的技术。它首先创建一个由(单词,上下文)对组成的巨大的单词-上下文共现矩阵。该矩阵中的每个元素代表上下文中单词的频率。可以应用矩阵分解技术来近似该矩阵。由于 Glove 是在 globar 词-词共现矩阵上进行训练的,因此它使我们能够拥有一个具有有意义的子结构的向量空间。
- Spacy 库支持 GloVe 嵌入。为了使用英语嵌入,我们需要下载管道“en_core_web_lg”,这是大型英语语言管道。我们使用 SpaCy 得到标准的 300 维 GloVe 词向量。
import spacy
import nltk
nlp = spacy.load('en_core_web_lg')
total_vectors = len(nlp.vocab.vectors)
print('Total word vectors:', total_vectors)
document = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]
tokenized_corpus = [nltk.word_tokenize(doc) for doc in document]
vocab = list(set([word for wordlist in tokenized_corpus for word in wordlist]))
glovevectors = np.array([nlp(word).vector for word in vocab])#Spacy's nlp pipeline has the vectors for these words
glove_vec_df = pd.DataFrame(glovevectors, index=vocab)
glove_vec_df如果您想查看单词“violet”的手套向量,请使用代码
glove_vec_df.loc['violet']希望查看所有词汇向量?
glovevectors使用 TSNE 可视化数据点
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne = TSNE(n_components = 2, random_state = 42, n_iter = 250, perplexity = 3)
tsneglovemodel = tsne.fit_transform(glovevectors)
labels = vocab
plt.figure(figsize=(12, 6))
plt.scatter(tsneglovemodel[:, 0], tsneglovemodel[:, 1], c='red', edgecolors='r')
for label, x, y in zip(labels, tsneglovemodel[:, 0], tsneglovemodel[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')六 快速文本
FastText 在 Wikipedia 和 Common Crawl 上进行了训练。它包含在 Wikipedia 和 Crawl 上训练的 157 种语言的词向量。它还包含语言识别和各种监督任务的模型。您可以在 gensim 库中试验 FastText 向量。
import warnings
warnings.filterwarnings("ignore")
from gensim.models.fasttext import FastText
import nltk
document = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]
tokenized_corpus = [nltk.word_tokenize(doc) for doc in document]
fasttext_model = FastText(tokenized_corpus, window = 5, min_count = 1, sg = 1)import warnings
warnings.filterwarnings("ignore")
from gensim.models.fasttext import FastText
import nltk
document = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]
tokenized_corpus = [nltk.word_tokenize(doc) for doc in document]
fasttext_model = FastText(tokenized_corpus, window = 5, min_count = 1, sg = 1)
print('Embedding')
print(fasttext_model.wv['blue'])
print('Embedding Shape')
print(fasttext_model.wv['blue'].shape)要查看词汇表中单词的向量,您可以使用此代码
words_fasttext = fasttext_model.wv.index_to_key
wordvectors_fasttext = fasttext_model.wv[words]
wordvectors_fasttext在本系列的下一篇文章中,我们将介绍文本分类。