python读取PDF文件中跨页表格思路分享
目录
背景
最近需要读取PDF文件中的表格,遇到的一个难点之一是如何识别并合并PDF中跨页表格。在查找资料时这篇文章使用pdfplumber提取pdf中不规则表格给了我思路,这篇文章PDFPlumber使用入门给了我实现的工具,下面我总结一下实现的思路和注意事项。
背景知识
pdfminer将PDF文件安照如下结构解析,其中LTchar就是一个PDF文件中具体的字符,比如“附”、“件”、“一”等。而pdfplumber是在pdfminer基础上改进的,也沿用了这个结构,只不过结构组成成分的命名变了,比如对字符的访问方式改为通过page.chars列表访问,pdfplumber也直接提供了方便使用的抽取文本等函数。
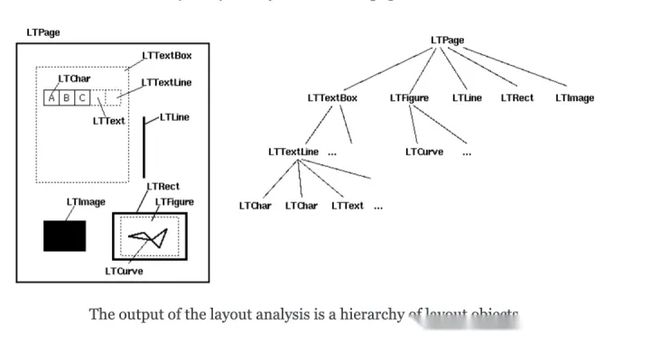
pdfminer解析的PDF文件结构
对于PDF中的每一个字符char,pdfplumber都将其作为对象形式存储,并且有许多属性可以访问,比如字符的坐标x0,y0,x1,y1。x0是字符左侧到页面左侧的距离,y0是字符底部到页面底部的距离,x1是字符字符右侧到页面左侧的距离,y1是字符顶部到页面底部的距离。
而pdfplumber抽取表格的策略是将整个页面page先划分出表格区域table,类似上图的LTTextBox,再横向切分成若干行row,类似上图的LTTextLine,再纵向切分成若干单元格cell,每个cell里就是一个字符,cell就类似于上图的LTChar。对于每个cell和每个row以及每个table,都有一个属性bbox。bbox是一个四元组,我没能找到资料说明这里面都是什么信息,根据我的观察猜测其四个值分别是左侧到页面左侧距离x0,顶部到页面顶部距离y0,右侧到页面左侧距离x1和底部到页面顶部距离y1,可以看作以页面左上角为原点建立坐标系情况下对象左上角坐标(x0,y0)和右下角的坐标(x1,y1)。
实现思路
判断表格是否跨页的特征就是当前页面以表格结尾,并且下一个页面以表格开头,若如此则可以判定这两个表格属于一个跨页表格,需要进行合并。
1.判断当前页面是否以表格结尾
当前页面以表格形式结尾就意味着该表格最底部的文本同时也属于该页面最底部的文本。因此只要比较当前page最后一个char(page读取char是按照从上到下从左到右的顺序读取)的纵坐标y_bottom_char与表格最后一个cell纵坐标y_bottom_cell即可。具体思路见下。
假如以左下角为原点建立坐标系,那么y_bottom_cell<=y_bottom_char就说明表格最底端的文本是页面最底端的文本,也就是页面以表格结尾;如果y_bottom_char 对PDF文件第一页的y_bottom_char的访问方式是pdf_file.pages[0].chars[-1].get('y0'),若考虑空白字符影响见下面注意事项3.pdf_file是通过pdfplumber.open函数打开的pdf文件,pages是pdf_file抽取的所有页面对象,可以访问其chars属性,chars是一个字典列表,存储着所有字符的属性,通过get('y0')获取字符的y0属性。 对PDF文件第一页的y_bottom_cell的访问方式是pdf_file.pages[0].bbox[3] - pdf_file.pages[0].findtables()[-1].bbox[3],若考虑空白字符影响见下面注意事项3.pdf_file.pages[0].bbox[3]是指页面的高度,为何要这么处理见下面注意事项2.findtables()函数返回页面所有Table对象,可以访问其bbox属性,也可以进一步访问其row和cell的bbox属性,但是Table本身的bbox属性从范围来讲就包含了表格最底部文字的纵坐标,因此直接用bbox[3]代替。 当前页面以表格形式开头就意味着该表格最顶部的文本同时也属于该页面最顶部的文本。因此只要比较当前page第一个char的纵坐标y_top_char与表格第一个cell纵坐标y_top_cell即可。具体思路见下。 假如以左下角为原点建立坐标系,那么y_top_cell>=y_top_char就说明表格最顶端的文本是页面最顶端的文本,也就是页面以表格开头;如果y_top_char 对PDF文件第一页的y_top_char的访问方式是pdf_file.pages[0].chars[0].get('y1'),若考虑空白字符影响见下面注意事项3. 对PDF文件第一页的y_top_cell的访问方式是pdf_file.pages[0].bbox[3]-pdf_file.pages[0].findtables()[0].bbox[1],若考虑空白字符影响见下面注意事项3. 本方法没有考虑页眉页脚等非正文文本的影响,如果要处理这种情况,可以先把这些字符剔除; 要注意坐标系的统一,访问页面字符时每个字符都有两个纵坐标y0和y1,分别代表其字符底部到页面底部的距离和字符顶部到页面底部的距离,可以看作是以左下角为原点建立坐标系;而访问表格内字符时其坐标在一个四元组bbox中,第二个坐标是其字符顶部到页面顶部的距离,第四个坐标是其字符底部到页面顶部的距离,可以看作是以左上角为原点建立坐标系。因此要比较页面字符和表格字符的纵坐标的前提是统一坐标系。比如统一左下角为原点,则 经过page.findtables()返回的Table对象中的bbox属性的值我没有找到资料描述其具体是何含义,只是经过自己的观察得出的猜测,如果有大佬发现我猜的不对欢迎指正。 最底部和最顶部字符在我实际写代码时被我替换成了最底部非空字符和最顶部非空字符,因为遇到一种异常情况,即页面以表格结尾,但是表格底部充斥着大量空白字符比如回车、制表符、空格等。这样的情况下page读取char会读到最底部的空白字符,但是读取表格中字符时却没有读到最底部空白字符,而是只读到了最底部非空白字符那一行,造成结果就是读取出来的表格的最底部字符纵坐标大于页面最底部字符纵坐标,判断出页面并非以表格结尾的错误结论。因此要专门对此情况处理,寻找页面最底部非空字符的思路是,从页面最后一个字符开始,不断判断最后一个字符是不是空白字符,是的话就继续往前找,不是的话就结束寻找。 可以加入对连续跨多页表格的处理,就是在判断下一页属于连续表格情况下继续判断下下一页,直到连续表格结束。 通过pdfplumber抽取出来的表格文本只是按行读取出来的文本,有些复杂表格这样读取出来会破坏其原有结构,需要根据具体表格格式进行数据清洗。 更多字符的属性以及pdfplumber抽取表格的详细策略参考这篇文档 PDFPlumber使用入门 使用pdfplumber提取pdf中不规则表格 使用pdfplumber提取pdf中不规则表格 pdfminer提取PDF文件文本和图片代码 Python如何提取PDF的文本和图像 PDF转Excel并数据清洗 数据治理 | 省下一个亿!一文读懂如何用python读取并处理PDF中的表格(赠送本文所用的PDF文件) - 知乎数据治理 | 省下一个亿!一文读懂如何用python读取并处理PDF中的表格(赠送本文所用的PDF文件)目录 一、前言 二、背景案例 三、数据清洗流程 1.理解数据,明确要求 2.清洗数据流程 (1)PDF转化为EXCEL (2)清洗… 复杂表格和图片表格处理 数据治理 | 省下一个亿!一文读懂如何用python读取并处理PDF中的表格(赠送本文所用的PDF文件) 带可选框表格处理 Python操作PDF文件笔记:(二)提取表格内容 - 知乎当PDF文件中存在较为复杂的表格时,推荐使用pdfplumber库进行表格数据的提取。值得注意的是,该库仅支持电脑生成的PDF文件,不支持扫描生成的PDF文件。 1.安装pdfplumber库pdfplumber库作为Python的第三方库,可在…2.判断下一页面是否以表格开头
3.注意事项
代码
import pdfplumber
import pandas as pd
# page_chars最尾部的非空字符
def tail_not_space_char(page_chars):
i = -1
while page_chars[i].get('text').isspace():
i = i - 1
# print(page_chars[i].get('text'), i)
return page_chars[i]
# 返回列表最头部的非空字符
def head_not_space_char(page_chars):
i = 0
while page_chars[i].get('text').isspace():
i += 1
# print(page_chars[i].get('text'), i)
return page_chars[i]
# 将pdf表格数据抽取到文件中
def extract_tables(input_file_path, output_excel_path):
print("========================================表格抽取开始========================================")
# 读取pdf文件,保存为pdf实例
pdf = pdfplumber.open(input_file_path)
# 存储每个页面最底部字符的y0坐标
y0_bottom_char = []
# 存储每个页面最底部表格中最底部字符的y0坐标
y0_bottom_table = []
# 存储每个页面最顶部字符的y1坐标
y1_top_char = []
# 存储每个页面最顶部表格中最顶部字符的y1坐标
y1_top_table = []
# 存储所有页面内的表格文本
text_all_table = []
# 访问每一页
print("1===========开始抽取每页顶部和底部字符坐标及表格文本===========1")
for page in pdf.pages:
# table对象,可以访问其row属性的bbox对象获取坐标
table_objects = page.find_tables()
text_table_current_page = page.extract_tables()
if text_table_current_page:
text_all_table.append(text_table_current_page)
# 获取页面最底部非空字符的y0
y0_bottom_char.append(tail_not_space_char(page.chars).get('y0'))
# 获取页面最底部表格中最底部字符的y0,table对象的bbox以左上角为原点,而page的char的坐标以左下角为原点,可以用page的高度减去table对象的y来统一
y0_bottom_table.append(page.bbox[3] - table_objects[-1].bbox[3])
# 获取页面最顶部字符的y1
y1_top_char.append(head_not_space_char(page.chars).get('y1'))
# 获取页面最顶部表格中最底部字符的y1
y1_top_table.append(page.bbox[3] - table_objects[0].bbox[1])
print("1===========抽取每页顶部和底部字符坐标及表格文本结束===========1")
# 处理跨页面表格,将跨页面表格合并,i是当前页码,对于连跨数页的表,应跳过中间页面,防止重复处理
print("2===========开始处理跨页面表格===========2")
i = 0
while i < len(text_all_table):
print("处理页面{0}/{1}".format(i+1, len(text_all_table)))
# 判断当前页面是否以表格结尾且下一页面是否以表格开头,若都是则说明表格跨行,进行表格合并
# j是要处理的页码,一般情况是当前页的下一页,对于连跨数页情况,也可以是下下一页,跨页数为k
# 若当前页是最后一页就不用进行处理
if i + 1 >= len(text_all_table):
break
j = i + 1
k = 1
# 要处理的页为空时退出
while text_all_table[j]:
if y0_bottom_table[i] <= y0_bottom_char[i] and y1_top_table[j] >= y1_top_table[j]:
# 当前页面最后一个表与待处理页面第一个表合并
text_all_table[i][-1] = text_all_table[i][-1] + text_all_table[j][0]
text_all_table[j].pop(0)
# 如果待处理页面只有一个表,就要考虑下下一页的表是否也与之相连
if not text_all_table[j] and j + 1 < len(text_all_table) and text_all_table[j + 1]:
k += 1
j += 1
else:
i += k
break
else:
i += k
break
print("2===========处理跨页面表格结束===========2")
# 保存excel
print("3===========开始保存表格到excel===========3")
for page_num, page in enumerate(text_all_table):
for table_num, table in enumerate(page):
print("处理表格页面{0}/表格{1}".format(page_num, table_num))
if table:
table_df = pd.DataFrame(table[1:], columns=table[0])
final_filename = output_excel_path + "page{0}_table{1}.xlsx".format(page_num, table_num)
table_df.to_excel(final_filename)
print("生成文件:", final_filename)
print("3===========保存表格到excel结束===========3")
# 保存txt
print("4===========开始保存表格到txt===========4")
for page_num, page in enumerate(text_all_table):
for table_num, table in enumerate(page):
print("处理表格页面{0}/表格{1}".format(page_num, table_num))
if table:
table_df = pd.DataFrame(table[1:], columns=table[0])
final_filename = output_excel_path + "page{0}_table{1}.txt".format(page_num, table_num)
with open(final_filename,"w") as f:
f.write(table_df.to_string())
f.close()
# print("生成文件:", final_filename)
print("4===========保存表格到txt结束===========4")
print("========================================表格抽取结束========================================")
if __name__ == '__main__':
# 抽取表格
input_file = "xx.pdf"
output_excel_path = ""
extract_tables(input_file, output_excel_path)
参考
 https://blog.csdn.net/fuhanghang/article/details/122579548
https://blog.csdn.net/fuhanghang/article/details/122579548
https://www.jianshu.com/p/433db2a387f2
https://zhuanlan.zhihu.com/p/477938551
https://zhuanlan.zhihu.com/p/540574630
https://www.qy.cn/jszx/detail/2298.html
https://zhuanlan.zhihu.com/p/556886560