(景行锐创) 高性能计算平台 Pytorch 深度学习环境超详细教程
文章目录
-
-
- 前言
- 1. 账号申请
- 2. 登录高算平台网站
- 3. 安装 Xshell,Xftp 软件
- 4. 连接高算平台
- 5. 安装 Anaconda
- 6. 安装 CUDA
- 7. 配置 cuDNN
- 8. 安装 torch 和 torchvision
- 9. 提交作业测试
- 10. 解压与压缩文件
- 11. 其他
- 结语
-
前言
目前一些学校为了便于师生进行大规模的计算任务,构建了服务器集群,尽管学校一般都会进行培训和给出操作手册,但往往对于具体的任务缺乏详细地操作流程说明和具体解释。为了方便大家使用 (景行锐创) 高性能计算平台来开展研究,特别是基于 Pytorch 的深度学习任务,我结合自己多次失败的教训和成果的经验总结了这篇完整的高性能计算平台 Pytorch 深度学习环境超详细教程,希望该教程能够为大家提供参考。码字不易,还望三连支持。
1. 账号申请
默认已经申请到高算平台账号,不同学校对于账号的申请可能方式不同,具体可以自行咨询相关部门。
2. 登录高算平台网站
2.1 登录学校的高算平台登录网站。 注意:在校外的话一定要登录 才可以使用高算平台。
2.2 但在这里没法方便安装软件和环境,因此我在本地电脑下载 Xshell 和 Xftp 两个工具,前者主要用来进行远程交互式操作 (黑窗口),后者主要用来传文件。
3. 安装 Xshell,Xftp 软件
3.1 网址:https://www.xshell.com/zh/all-downloads/。

3.2 点击 Xshell, 选择 免费授权页面。
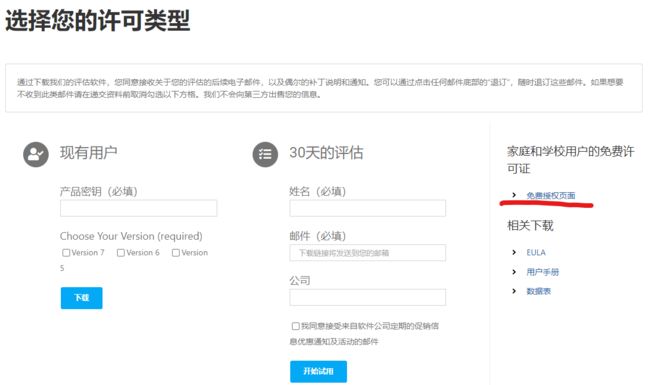
3.3 填写自己的姓名和校园邮箱,选择 两者,点击下载后会在校园邮箱里发来一个下载链接,打开链接地址下载即可。
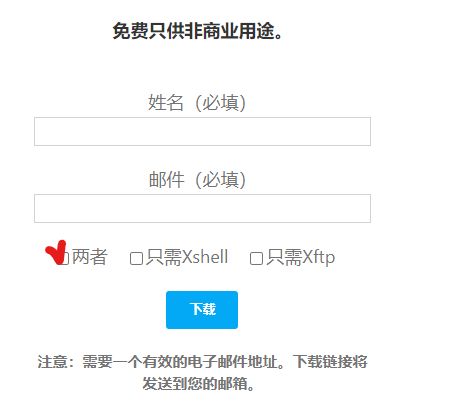
3.4 如果觉得以上操作麻烦,也可以直接使用以下链接下载:
Xshell:https://www.xshell.com/zh/downloading/?token=dTQyZl96em9ENHl0bTIzaVdDSkhXd0Biell6LVNGaUE5WHJtaWhrRVhTNENR
Xftp:https://www.xshell.com/zh/downloading/?token=TmFYTFlJQ1JSM3JGZEJMMlNoUTF3d0Biell6LVNGaUE5WHJtaWhrRVhTNENR
3.5 安装过程很简单,注意更换 安装路径。
4. 连接高算平台
4.1 打开 Xshell。
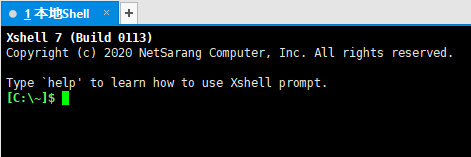
4.2 输入 ssh 10.33.0.102 ,在弹出的窗口里输入 学号,注意这里的远程连接路径可能不同学校存在区别,需要自行咨询或查询手册。

4.3 点击确定,在弹出的窗口里选择 password,填入自己的登录密码。

4.4 点击确定后,输出 connection established 表明连接成功。

4.5 点击菜单栏里的 Xftp 按钮,就可以直接打开 Xftp 并连上个人登录节点。

4.6 如图所示,左边的是本地文件夹,右边的是个人登录节点文件夹;在 Xftp 里直接通过拖拽或者双击就可以拷贝文件到登录节点。

4.7 新注册高算平台在登录节点只有一个 jhupload 文件夹,为了方便后续工作,可以新建文件夹 software,project 和 dataset,分别用来安装软件,存放项目以及暂存数据集,所有上传的压缩包等文件全部放到 jhupload 文件夹。
5. 安装 Anaconda
5.1 由于高算平台的登录节点无法无法访问校园以外的网,所有的软件和包只能离线安装,因此需要提前本地下载好。
5.2 在 Anaconda 的国内镜像源下载,注意软件版本 Anaconda3 和操作系统 Linux_x86_64, 清华源:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/。

5.3 利用 Xftp 将下载的离线安装包拷贝到登录节点的 jhupload 文件夹下。
5.4 在已连接登录节点的 Xshell 中可以看到当前所在路径是 ~,这个就是家目录;输入 cd jhupload 进入离线安装包所在路径 (这个与 windows 一致,cd 是进入目录,cd … 是返回上一级目录)。
![]()
5.5 输入 sh Anaconda3-2021.05-Linux-x86_64.sh 运行安装脚本,后边这个是下载的离线安装包的全名,根据个人实际下载情况可能存在差异;点击回车键继续安装。

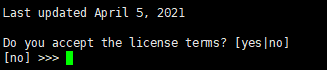
5.6 下面会显示阅读协议,长按回车键到最后。

5.7 输入 yes 接受协议。
5.8 修改 Anaconda 的安装路径在之前新建的文件夹 software 下,注意这里需要输入完整路径,不知道完整路径的可以在 Xftp 的路径栏里复制。

5.9 在复制的路径后添加 /anaconda3,这里不需要手动新建目录,会自动新建,如果已经存在该目录会安装失败;回车后就是漫长的等待。

5.10 安装好后会询问是不是在启动终端的时候就在 conda 环境里(类似 windows 下安装后的 Anaconda Prompt),输入 yes。

5.11 安装完成,这里让你安装 Pycharm,但由于我们没有图像界面就没必要装。
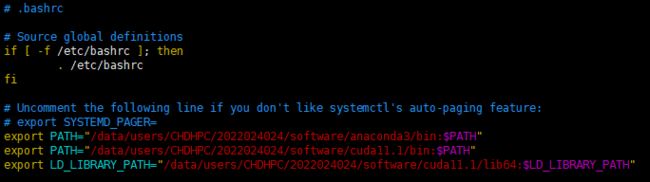
5.12 接下来配置环境变量,输入 vim ~/.bashrc,打开配置文件,需要先点击键盘上的 insert 键才能开始编辑;添加环境变量,键入 export PATH="/data/users/CHDHPC/2022024024/software/anaconda3/bin:$PATH",注意路径是完整路径。

5.13 点击 Esc (键盘上的返回键),输入 :x 退出配置文件,在 Xshell 中输入 source ~/.bashrc 更新配置文件;此时就会进入 Anaconda 的 base 环境,根据 Anaconda 版本的不同,有的会显示为 root。
![]()
5.14 输入 conda -V 判断 conda 命令能不能使用,正常会输出 conda 版本。
![]()
6. 安装 CUDA
6.1 这里我安装的是 cuda 11.1,高算平台支持 cuda 9, 10, 11 各版本,但实测发现低版本会报错,原因不明;下载 cuda 离线安装包时要注意对应系统内核,在 Xshell 中输入cat /proc/version,输出显示 Linux x86_64; cat /etc/redhat-release,输出显示 CentOS 7 版本。

6.2 下载 cuda 的离线安装包,网址:https://developer.nvidia.com/cuda-toolkit-archive,选择 CUDA Tookit 11.1.0。

6.3 在新界面中选择 Linux_x86_64_CentOS_7_runfile (local)。

6.4 此时下拉界面在 bash installer 框里会出现安装该 cuda 需要的命令,但由于登录节点无法访问校园以外的网,因此拷贝链接到浏览器搜索栏回车,稍等就会开始下载。

6.5 同理,将下载好的 cuda 离线安装包利用 Xftp 拷贝到 jhupload 文件夹里;在 Xshell 中进入 jhupload 目录,输入 sh cuda_11.1.0_455.23.05_linux.run, 注意: 后边的 cuda 离线安装包全名根据个人实际下载情况修改。
![]()
6.6 此时可能会报一个错,log file not open,这是因为这台服务器上别人安装过 cuda,需要删掉 cuda-installer.log 文件,但在登录节点没有权限删除,在高算交流群里@管理员帮忙删除即可。
![]()
6.7 删除之后,继续 sh cuda_11.1.0_455.23.05_linux.run,开始安装,输入 accept。

6.8 取消勾选 Driver,这是因为服务器已经存在 NVIDIA 驱动,不需要安装;同时取消勾选 CUDA Demo Suite 和 CUDA Documentation; 注意:上下键移动光标,回车勾选或取消勾选。

6.9 移动光标到 Options,回车后选择 CUDA Toolkit,选择第一项 Chang Toolkit Install Path,这里先提前在家目录的 software 文件夹里新建一个文件夹,起名 cuda11.1,将安装路径改为 /data/users/CHDHPC/2022024024/software/cuda11.1,即 文件夹 cuda11.1 所在的完整路径。

6.10 回车后取消所有已勾选的项目;选择 done 回车。

6.11 再修改 Samples 的安装路径,在之前的 cuda11.1 文件夹下新建文件夹 samples,将安装路径改为 samples 所在的完整路径,/data/users/CHDHPC/2022024024/software/cuda11.1/samples。

6.12 再修改 Library 安装路径,在之前的 cuda11.1 文件夹下新建文件夹 myLib,将安装路径改为 samples 所在的完整路径,/data/users/CHDHPC/2022024024/software/cuda11.1/myLib;这个其实什么也不会装,但以防万一还是把目录改一下。

6.13 回车选择 done ,选择 install 开始安装。
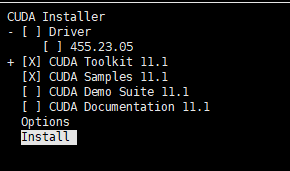
6.14 安装结束后的输出如图,可以看到已经成功安装 CUDA Toolkit。
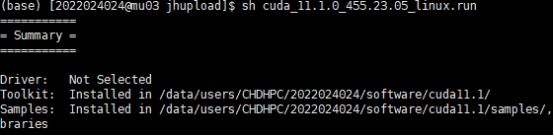
6.15 接下来需要配置环境变量,在 Xshell 中输入 vim ~/.bashrc 打开配置文件,点击键盘上的 insert 键在之前添加的 Anaconda 环境变量后再添加 export PATH="/data/users/CHDHPC/2022024024/software/cuda11.1/bin:$PATH" 和 export LD_LIBRARY_PATH="/data/users/CHDHPC/2022024024/software/cuda11.1/lib64:$LD_LIBRARY_PATH";点击键盘上的 Esc 键,输入 :x 退出编辑;再输入 source ~/.bashrc 更新配置文件。
6.16 利用 nvcc 检查 cuda 是否安装好,输入 nvcc -V 查看 cuda 版本,正常会输出当前 cuda 的版本。

7. 配置 cuDNN
7.1 下载 cudnn 离线包,网址:https://developer.nvidia.com/rdp/cudnn-archive,新用户需要注册,注册好后登录打开网址选择对应版本的 cudnn。

7.2 下载完成后,利用 Xftp 将下载的 cudnn 离线包拷贝到 jhupload 文件夹下,在 Xshell 下进入 jhupload 目录,输入 tar -xzvf cudnn-11.1-linux-x64-v8.0.5.39.tgz 解压 cudnn 压缩包。
7.3 利用以下两条命令拷贝 cudnn 里的文件到 cuda 的安装路径里: 注意:具体路径要根据实际情况修改。
cp /data/users/CHDHPC/2022024024/jhupload/cuda/include/* /data/users/CHDHPC/2022024024/software/cuda11.1/include/
cp /data/users/CHDHPC/2022024024/jhupload/cuda/lib64/* /data/users/CHDHPC/2022024024/software/cuda11.1/lib64/
7.4 查看 cudnn 版本,输入 cat /data/users/CHDHPC/2022024024/software/cuda11.1/include/cudnn_version.h | grep CUDNN_MAJOR -A 2,正常会输出当前的 cudnn 版本,如图说明当前的 cudnn 版本是 8.0.5。

8. 安装 torch 和 torchvision
8.1 这里我们直接将 pytorch 装在 base 下,首先查看 python 版本,输入 python -V,可以看到我安装的 Anaconda 自带的 base 环境下 python 版本为 3.8.8;直接装在 base 下的原因是 base 本身存在大量基础包,不需要额外安装,否则就要一个个单独安装,异常麻烦。
![]()
8.2 安装 Pytorch 1.9.0,官网:https://download.pytorch.org/whl/torch_stable.html,清华源:https://pypi.tuna.tsinghua.edu.cn/simple/torch/;下载对应 cuda11.1,python3.8.8 和 Linux_x86_64 的离线包 .whl。注意:建议官网安装,清华源安装遇到过报错的情况 (不一定会报错)。

8.3 Pytorch 1.9.0 对应的 torchvision 版本是 0.10.0, 如果是官网下载的话继续下拉找到对应 cuda11.1,python3.8.8 和 Linux_x86_64 的离线包 .whl;清华源下载的话需要进入新的网页:https://pypi.tuna.tsinghua.edu.cn/simple/torchvision/。

8.4 将下载好的 torch 和 torchvision 的两个 .whl 文件利用 Xftp 拷贝到 jhupload 文件夹下;在 Xshell 中进入 jhupload 目录,在 base 环境下使用 pip install torch-1.9.0+cu111-cp38-cp38-linux_x86_64.whl 和 pip install torchvision-0.10.0+cu111-cp38-cp38-linux_x86_64.whl 分别安装; 注意:先装 torch 再装 torchvision。

8.5 安装好后,输入 pyhon 进入交互式环境,输入import torch 查看是否能正常导入 torch,可以输入 print(torch.cuda.is_available()) 查看 cuda 是否可以用,正常会输出 False;这是因为登录节点并未分配 NVIDIA 显卡,只有提交作业后才会根据提交的设置进行分配。

8.6 到这里,整个 pytorch 的环境已经配好;一些特殊的包还是需要单独下载安装的,清华源:https://pypi.tuna.tsinghua.edu.cn/simple/;需要什么包,一般在网址后边添加包名搜索即可。
9. 提交作业测试
9.1 准备一个 test.py 文件,功能是检查 cuda 是否可用,可以使用的 gpu 数量,当前的 cuda 版本以及当前节点上的GPU占用情况; 注意 这个测试代码是后边提交作业时会经常用到。
#!/data/users/CHDHPC/2022024024/software/anaconda3/bin/python3
import torch
print(torch.cuda.is_available()) # 检查 cuda 是否可用
print(torch.cuda.device_count()) # 检查可用的 gpu 数量
print(torch.version.cuda) # 查看 cuda 版本
# 下边的代码就是返回服务器上 GPU 的占用情况,这样方便我们选择 GPU 或者节点
import subprocess
ret = subprocess.run('nvidia-smi', shell=True, capture_output=True, timeout=100)
print(ret.stdout.decode('utf8'))
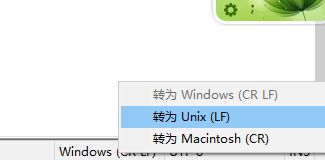
9.2 如果是在 windows 下编辑 test.py 需要将编码格式转为 Unix,这是因为 Windows 和 Linux 操作系统下的回车和换行符存在差异;在 NotePad++ 里可以在右下角操作,其他软件方法不明。
9.3 将该 python 文件放入家目录的 project 文件夹下,右键选择更改权限,将所有权限都给 test.py;如果不授权的话会报错:/apps/jhinno/unischeduler/jobstarter/qgpu_starter: line 8: ./test.py: Permission denied。

9.4 在 Xshell 中进入 project 目录,使用 jsub -q qgpu -m gpu05x8 -e ./error.txt -o ./output.txt -J ceshi ./test.py 提交作业;具体的参数定义如下:
jsub 提交作业命令
-q 指定队列,pytorch 代码一般指定 qgpu 队列
-m 指定代码运行节点
-e 指定错误日志的输出文件,会在文件里写入运行中遇到的错误
-o 指定输出日志的输出文件,会在文件里写入代码的过程输出
-J 为当前提交的作业指定一个名字,一般一次只提交一个作业的话就不用管这个,比如上边的指令就是将作业命名为 ceshi
./test.py 就是前边的测试代码 python 文件
9.5 上述参数中 -q 和 -m 需要自己查阅手册来确定队列和节点,不同的学校可能有不同的标识。
9.6 提交之后在 Xshell 中会输出作业已被提交。

9.7 这时我们可以登录网页版的高算平台,进入我的作业就可以看到提交的作业;状态为 DONE 即程序正常结束,作业名为 ceshi。
![]()
9.8 也可以不登录网页版的高算平台,直接在 Xshell 中输入 jjobs 或者 jjobs 作业号 来查看作业状态;前者是查看当前正在运行或排队的所有作业,后者是查看指定作业号的作业状态。
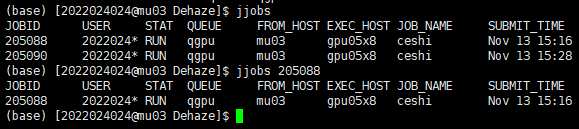
9.9 此时在 test.py 同目录下会出现 error.txt 和 output.txt 文件;打开 error.txt 发现为空,则没有错误输出;打开 output.txt 下拉到最后可以发现输出为 True,7 和 11.1,这说明 pytorch 可以检测到 cuda,当前可以检测到的 gpu 数量为 7, 当前 cuda 版本为 11.1;下拉还会有 GPU 占用情况的输出,可以方便我们后续将作业提交到空闲比较多的 GPU 上去。

9.10 在正式提交后续的作业时,我不建议使用前边这种命令行指定参数的方式提交。除了测试例子中提交作业的方式,还可以使用脚本方式提交作业;即新建一个 test.sh 文件,内容如下,参数的解释见 9.4 节;倒数第二行为 python 解释器的完整路径;最后一行为要运行的 python 文件路径,这个可以使用相对路径,但前提是在 Xshell 进入当前脚本所在文件夹;设置完成后,进入路径使用 jsub < ./test.sh 提交作业。
#!/bin/sh
#JSUB -q qgpu
#JSUB -m gpu04ai
#JSUB -e error.txt
#JSUB -o output.txt
#JSUB -J ceshi
/data/users/CHDHPC/2022024024/software/anaconda3/bin/python3
./test.py
10. 解压与压缩文件
10.1 如果需要被解压或者压缩的文件大小小于 4G,那么我们可以直接使用平台自带的 unzip 或者 zip 命令来实现,注意这并不是说可以直接在 Xshell 中解压,我们仍然需要以作业的形式提交到高算平台来实现。
10.2 解压文件的脚本 unzip.sh 如下所示,注意要对路径进行修改,建议将该脚本文件直接放在与 .zip 文件同目录下。
#!/bin/bash
#JSUB -q normal
#JSUB -e error.txt
#JSUB -o output.txt
#JSUB -J unzip
unzip 'train.zip'
10.3 压缩文件的脚本 zip.sh 如下所示,注意要对路径进行修改,建议将该脚本文件直接放在与 .result 文件夹同目录下。
#!/bin/bash
#JSUB -q normal
#JSUB -e error.txt
#JSUB -o output.txt
#JSUB -J zip
zip -r result.zip ./result
10.4 对于文件大小大于 4G 的情况,就无法使用这个简单的工具了,我们必须安装其他的工具。Linux 下的解压工具很多,这里以安装 7zip 为例,可以用来解压 .zip 格式压缩包;下载 7zip 安装包,网址:https://sourceforge.net/projects/p7zip/;点击 Download 下载最新版。

10.5 将下载好的 7zip 安装包利用 Xftp 拷贝到 jhupload 文件夹下;在 Xshell 中进入 jhupload 目录,输入 tar -jxvf p7zip_16.02_src_all.tar.bz2 解压安装包; 注意: 7zip 安装包的全名要和自己下载的对应。
10.6 解压完成后,cd p7zip_16.02 进入解压得到的文件夹目录, 输入 make all3。
10.7 make 结束后,在 Xftp 里用记事本打开 p7zip_16.02 路径下的 makefile.common 文件,修改 DEST_HOME 的路径为自己计划安装 7zip 的路径 /data/users/CHDHPC/2022024024/software/7zip; 注意 将路径修改成自己对应的。
10.8 修改完成后,make install。
10.9 报错:服务器时钟不对;在 Xftp 里根据文件的修改时间也可以判断确实服务器的时钟不对。

10.10 顺序执行:
find . -type f | xargs -n 5 touch
make clean
make
make install
10.11 修改环境变量;Xshell 输入 vim ~/.bashrc 打开配置文件,在之前添加的 Anaconda 和 cuda 环境变量后边再添加 7zip 的环境变量, 注意 修改路径为自己对应的;完成后点击键盘上的 Esc,再输入 :x 退出编辑。
export PATH="/data/users/CHDHPC/2022024024/software/7zip/bin:$PATH"
10.12 输入 source ~/.bashrc 更新配置文件。
10.13 输入 7za ,正常会输出 7zip 的版本等信息。

10.14 解压示例;在 Xshell 中进入压缩包所在目录,其中 -o 后的参数即解压的目标路径,中间无空格。
7za x 01.zip -o目标路径
10.15 压缩示例;在 Xshell 中进入需要压缩的文件夹所在目录。
7za a 01.7z 文件夹名
10.16 实测发现在本地使用 7zip 来解压或者压缩比较大的文件会特别慢,或许应该对此也使用作业的形式提交到平台来运行,但是具体的方式还没有尝试。。
11. 其他
11.1 常见作业的不同状态及其含义
| 状态 | 含义 |
|---|---|
| RUN | 作业已经提交,程序正在运行 |
| EXIT | 作业异常退出,一般是代码存在问题,可以查看 error.txt 查看报错 |
| DONE | 作业完成,程序正常结束 |
| PEND | 作业正在排队中,程序还未开始运行 |
11.2 提交作业不需要具体指定需要多少个 GPU,只需要在代码里设置好需要的 GPU 数目即可,不设置默认 0 号 GPU;指定 GPU 数量和编号需要在提交的作业文件里进行设置,方法也非常简单,如下。需要注意的是,在设置前将代码改成多卡训练的,否则代码会默认选择指定的 GPU 序列中的第一块卡来执行。
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0, 3, 4'
11.3 提交的主 python 代码第一行需要有解释器的定义,其他被主代码调用的包不需要添加。
#!/data/users/CHDHPC/2022024024/software/anaconda3/bin/python3
11.4 如果需要跑一个完整的项目,引用的代码需要放在与主代码同级目录下才能直接调用,因为在交互式环境中运行 python 不像在 Pycharm 中可以设置 source root 文件夹;但是也可以通过如下方式来调用,在 . 之前的即为该项目下与 train.py 同级的 models 文件夹。
![]()
11.5 如果在作业提交后需要终止作业,可以在网页版高算平台我的作业里终止,也可以在 Xshell 中输入 jctrl kill 作业号 来终止指定作业号的作业;此时再查看作业状态就会显示 DONE。

11.6 报错:SyntaxError: EOL while scanning string literal;这是因为没有将路径放在引号内。
11.7 删除文件或文件夹的时候如果在 Xftp 里删除或非常慢,建议在 Xshell 里使用如下命令来删除。
rm -f 文件名
rm -rf 文件夹
11.8 我建议的一个完整的 Pytorch 作业提交流程是:
a. 将代码文件格式由 windows 格式改为 Unix 格式,即 9.2 节;
b. 在主代码最开始一行加上解释器的定义,即 11.3 节;
c. 先提交运行 test.py 的脚本文件到某一个节点上来判断当前节点上的 GPU 占用情况,即 9.9 节;
d. 选择空闲较大的 GPU 来提交作业,即 11.2 节;
e. 给整个项目文件夹编辑权限,即 9.3 节;
f. 提交主代码文件的脚本文件,即 9.10 节。
结语
如果我的教程对于你的研究有所帮助,麻烦点赞收藏。另外,对于其中存在的不足请大家不吝指出,我会在合适的时间对其进行修改。