论文浅尝 | DSKReG:基于关系GNN的推荐知识图谱可微抽样

笔记整理:李爽,天津大学硕士
链接:https://dl.acm.org/doi/pdf/10.1145/3459637.3482092
动机
在信息爆炸的时代,推荐系统被广泛研究和应用,以发现用户的偏好信息。RS在冷启动时性能较差,如果将知识图谱(Knowledge graph, KG)作为辅助信息,可以缓解冷启动问题。然而,现有的研究大多忽略了KGs中的节点度是偏移的,并且在KGs中的大量交互是推荐不相关的。为了解决这些问题,本文提出了基于关系GNN的推荐知识图谱可微抽样(DSKReG),该方法从KGs中学习连通项的相关分布,并根据该分布选取适合推荐的项目。作者设计了一种可微抽样策略,使相关项目的选择与模型训练过程共同优化。实验结果表明,该模型的性能优于目前最先进的基于KG的推荐系统。
亮点
DSKReG的亮点主要包括:
1.根据关联关系和项目类型计算相关分数进行抽样,可以引导模型选择推荐相关的项目;2.设计一种可微抽样策略,使得模型在优化的同时细化抽样过程。
概念及模型
模型的整体框架如下图所示。
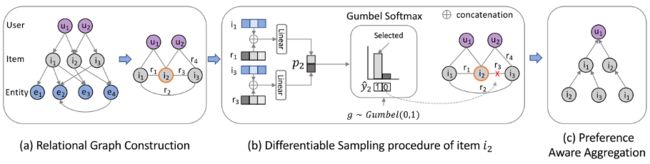
•问题定义
知识感知推荐的目标是预测用户u是否对给定历史交互和KG的项目v有兴趣。在形式上,用户U与项目V的历史交互被表示为用户-项目二部图 ![]() 。KG包含与项目相关的属性,如电影的类型、导演和演员。作者将KG格式化为有向异构图
。KG包含与项目相关的属性,如电影的类型、导演和演员。作者将KG格式化为有向异构图![]() ,例如(James Cameron, isdirectorof, Titanic),其中E和R分别表示实体和关系的集合。因此,知识感知的推荐任务可以形式化为:
,例如(James Cameron, isdirectorof, Titanic),其中E和R分别表示实体和关系的集合。因此,知识感知的推荐任务可以形式化为:
![]()
•关系的邻居构建
节点度偏度限制了KG中稀疏连接的节点的可用邻居项目池。作者提出了“协同交互”模式来建立高阶项目与项目之间的关系,从而缩短相关项目之间的路径距离。从输入KG 中提取协同交互模式,构造一个具有新的协同关系集的项目-项目协同交互无向图 ,其定义如下:
在这些关系的访问之后,将具有协同交互模式的项目连接起来,并构造如框架图(a)所示的项目-项目图。这样可以直接连接高阶邻域,避免接收域的指数增长。将用户-项目二部图 和项目-项目协同交互图 统一为一个关系图。
•可微的抽样
引入可微抽样的邻居选择。交互关系对推荐的相关性因用户而异,并且交互关系是不平衡的。这就带来了一个问题:当潜在邻居池很大时,高度相关的邻居就会减少。为了过滤噪声,保留真正的相关信息,作者引入关系感知采样方法,从关系的角度分配权重。抽样过程首先为每个项目定义一种新的关系感知的相关性得分分布,然后对其进行抽样。项目i的关系感知相关性分数分布 定义如下:

关联项和邻接项共同决定了其邻接相关概率,强调了抽样相关计算中关系感知的必要性。
考虑到计算出的相关性分布,只选择top-k最相关的项。为了使该过程具有可微性并与优化过程相结合,应用Gumbel-Softmax重参数化技巧:
![]()
•偏好感知聚合
在top-k邻居消息传播过程中,除了考虑关系因素外,还应考虑用户偏好。由于用户可能对各种关系有不同的偏好,所以在聚合中考虑这些关系。项目i的嵌入如下:
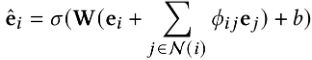

•预测和优化
使用点积生成用户u对项目i的偏好分数,并推断出用户/项目嵌入分别为 和 。预测计算如下:
![]()
使用成对BPR损失优化top-N推荐:

理论分析
实验
作者在三个基准数据集Last.FM, BookCrossing和MovieLens-Sub上进行了实验。为了评估top-N推荐和偏好排名的性能,使用三个标准指标:Recall, Precision和NDCG。分别计算前5项、前10项和前20项的Recall、Precision和NDCG。

如上表所示,本文的模型DSKReG在大多数情况下显著优于最先进的方法。与最强的基线模型相比,DSKReG模型在Last.FM上对于Recall、Precision和NDCG平均分别提高了7.73%、6.2%和9.03%的性能。同样,在BookCrossing上的表现比最佳基线模型高出9.43%、4.97%和19.83%。在MovieLens-Sub数据集上,分别提高了11.47%、15.60%和45.47%的性能。这些结果表明了模型的有效性。令人惊讶的是,DSKReG模型显著提高了NDCG。其中,NDCG@20在三个数据集上分别提高了14.2%、32.0%和37.5%。由于NDCG考虑了位置重要性和项目数来衡量推荐质量,这些结果显示了DSKReG模型在推荐方面的优越性。
作者还做了几个消融实验。
1、关系感知抽样的效果

实验结果如图2所示,结果表明,在Last.FM和MovieLens-Sub上GS的性能优于其他抽样方法。在BookCrossing上,使用L2距离和内积度量的方法可以获得与GS类似的结果。原因可能是这个数据集中的项目之间的关系相对简单,L2距离和内积度量足以建模项目关系。然而,在处理复杂的物品关系方面,GS明显优于其他指标。
2、抽样规模的影响
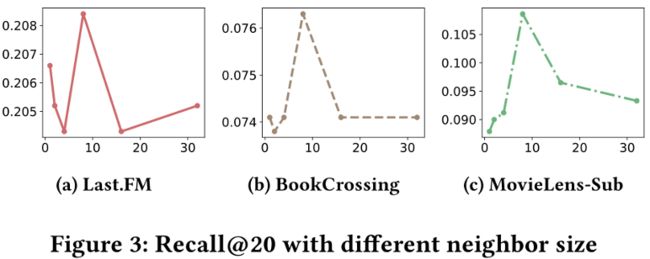
为了检验邻域大小的有效性,作者使用不同的K进行实验,K是采样后邻域的大小。如图3所示,Last.FM、BookCrossing和MovieLens-Sub的最佳邻居大小是8。这表明只有一小部分项目是相关的。本文的模型可以为聚合选择有价值的信息,使得模型在只有8个邻居的情况下获得最佳性能。
总结
文章提出了一种新的框架DSKReG来缓解基于KG的推荐节点度偏移和干扰交互的限制。DSKReG是一种基于采样的关系GNN,它从KGs中提取与推荐相关的信息。作者设计了一种可微分的DSKReG采样策略,并与模型共同优化,学习如何选择top-k相关项目进行聚合。作者在三个公共数据集上进行实验,验证了DSKReG在提高推荐性能方面的有效性。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。