Python+Vba+cmd_文件筛选工作流
目标:
写一个可以自动获得并且筛选出几万个具有迭代过程的文件中获取最终的工程文件内容:
1、 用cmd命令行获取基本数据信息
2、 用python排除无效信息(根据文件名,时间…)
3、 用vba写一个excel插件用于录入信息,和基本的增删改查,方便后端使用
时间:
一周+产出:
cmd:
防止中文乱码
CHCP 65001
cmd:
跳转到F盘,和目录
F:
CD Your_path_here
cmd:
遍历并且输出所有需要的文件信息:
dir /s *.ma *.psd *.ZTL *.jpg *.ai *.max *.obj *.tga *.mp3 *.wmv *.avi *.docx *.pdf *.dmp *.mov *.gif *.psb >pathCollition.txt
python:
对信息做筛选
import io
import re
import json
from collections import defaultdict
class InputExportTool:
#def __init__(self):
#导入txt--------------------------------------------------
def readAndShot(self,strRead):
f = io.open(strRead,'r',encoding='utf-8')
fileContents = f.read()
#print(fileContents)
#将所有文件切片--------------------------------------------------
pathList = fileContents.split(" Directory of",-1)
num = 2
print("切片完成:其中第"+str(num)+"个元素为:\n"+pathList[num])
#用键值对归类--------------------------------------------------
print("归类前的长度: "+str(len(pathList)))
dic = {}
for siglePathList in pathList:
siglePathListSplit = siglePathList.split("\n",1)
key = siglePathListSplit[0].strip()
value = siglePathListSplit[1]
if key not in dic:
dic[key] = value
else:
#print(key)
dic[key] += value
print("归类后的长度: "+str(len(dic)))
#print(dic[r'F:\Producer_Backup_20150429\Feedback\Zynga\ZDC\thumbnails\thumbnailer\thumbnailer\thumbnailer'])
#print(dic)
f.close()
return dic
#导出txt--------------------------------------------------
def export(self,dic,strOutPut):
file = io.open(strOutPut,'w',encoding='utf-8')
for k,v in dic.items():
file.write(str(k)+' * '+str(v)+'\n')
file.io.close()
#内容排查---------------------------------------------------
def checkOut(self,strRead):
I = InputExportTool()
#导入txt
f = io.open(strRead,'r',encoding='utf-8')
fileContents = f.read()
#切片
#v1
pathList = fileContents.split(" bytes",-1)
#v2
'''
pathList = re.split('(F:)',fileContents)
for i in range(len(pathList)):
pathList[i] ="F:"+pathList[i]
'''
dic2 = {}
for siglePathList in pathList:
siglePathListSplit = siglePathList.split(" * ",1)
key = siglePathListSplit[0].strip()
#print(key)
#空文件夹的安全校验
try:
value = siglePathListSplit[1]
valueIndex =I.Convert(value)
#基于value建立数组
'''
while(valueIndex.count('\'')):
valueIndex.remove('\'')
while(valueIndex.count(',')):
valueIndex.remove(',')
'''
valueIndex = I.listToString(valueIndex)
#print(valueIndex)
#v1
valueIndex = re.split(r'(\.MOV|\.TGA|\.JPG|\.PSD|\.ai|\.max|\.psd|\.ZTL|\.jpg|\.ma|\.obj|\.tga|\.mp3|\.wmv|\.avi|\.docx|\.pdf|\.dmp|\.mov|\.gif|\.psb|\.mb|\.MB)',value)
valueIndex.append("")
valueIndex = ["".join(i) for i in zip(valueIndex[0::2],valueIndex[1::2])]
del valueIndex[-1]
valueIndexN = []
for i in valueIndex:
valueIndexN.append(i.strip())
dic2[key]=valueIndexN
#删除空文件夹
if not dic2.get(key):
del dic2[key]
#存入字典
#print(valueIndex)
#删除只有jpg的文件夹
counter = 0
for i in range(len([valueIndex])):
de = valueIndex[i].split(".")[-1]
#print(valueIndex[i])
if de =="jpg" or de =="docx" or de == "mov" or de == "pdf" or de == "gif" or de == "tga" or de == "JPG" or de == "TGA" or de == "MOV":
counter+=1
if de == 'ma':
valueIndex[i].split(r'.')[-1] = 'ma/max'
#print(counter)
if counter == len(valueIndex):
#print("needDel:"+ listToString(valueIndex))
del dic2[key]
#只取得每个值的后缀名
"""
print(str(valueIndex[0].split(r'.')[-1]))
for i in range(len(valueIndex)):
valueIndex[i]=str(valueIndex[i].split(r'.')[-1])
"""
except IndexError:
pass
continue
#key = r"F:\Producer_Backup_20150429\Feedback\场景原画\水印"
#print(dic2.get(key) )
print("删除空文件夹后的长度:"+str(len(dic2)))
f.close()
return dic2
def checkOut2(self,strRead):
#导入txt
f = io.open(strRead,'r',encoding='utf-8')
fileContents = f.read()
#切片
pathList = re.split('F:',fileContents)
for i in range(len(pathList)):
pathList[i] ="F:"+pathList[i]
del pathList[0]
#申请字典
dic2={}
#单个数据组
for siglePathList in pathList:
siglePathListSplit = siglePathList.split(" * ",1)
key = siglePathListSplit[0].strip()
value = siglePathListSplit[1].strip()
value_list = eval(value)
s = ""
for i in value_list:
i = i.split(" ")[-1]
s += i + ' + '
print(i)
dic2[key] = s
f.close()
return dic2
#对键值对排序
def sortDic(self,dic):
sorted(dic.items(),key=lambda parameter_list: str(parameter_list[0].split(r'\\')[-1]))
#print(dic)
return dic
#冒泡排序
def bublle_sort(self,data):
for i in range(len(data)-1):
indictor = False
for j in range(len(data)-1-i):
if data[j]>data[j+1]:
data[j],data[j+1] = data[j+1],data[j]
indictor = True
if not indictor:
break
#数组变字符串
def listToString(self,s):
# initialize an empty string
str1 = ""
# traverse in the string
for ele in s:
str1 += ele
# return string
return str1
# 字符串变数组
def Convert(self,string):
list1=[]
list1[:0]=string
return list1
#获取---------------------------------------------------
strRead = 'exprot11111.txt'
strOutPut = 'ForExcel.txt'
#挨个执行一遍
I = InputExportTool()
#I.export(I.sortDic(I.readAndShot(strRead)),strOutPut)
#I.export(I.sortDic(I.checkOut(strRead)),strOutPut)
I.export(I.sortDic(I.checkOut2(strRead)),strOutPut)
#Res:
#F:\Producer_Backup_20150429\Art\Activision\2014.10.28\outsource_art\source_art\model_export\t7_props\p7_can_milk_vintage_set * p7_can_milk_vintage_set.ma + p7_can_milk_vintage_set_high.ma + p7_can_milk_vintage_set_high.ZTL + mtl_p7_can_milk_vintage_metal.psb + mtl_p7_can_milk_vintage_metal_painted_white.psb + mtl_p7_can_milk_vintage_metal_rusty.psb +
#F:\Producer_Backup_20150429\Art\Activision\2014.10.31\outsource_art\source_art\model_export\t7_props\p7_box_case_metal_set * p7_box_case_metal_set.ma + p7_box_case_metal_set_high.ma + p7_box_case_metal_01_large_set.ZTL + p7_box_case_metal_01_medium_set.ZTL + p7_box_case_metal_01_small_set.ZTL + mtl_p7_box_case_metal_01_large.psb + mtl_p7_box_case_metal_01_medium.psb + mtl_p7_box_case_metal_01_metal.psb + mtl_p7_box_case_metal_01_small.psb + mtl_p7_box_case_metal_01_worn_metal.psb + mtl_p7_box_case_metal_02_Aluminum.psb + mtl_p7_box_case_metal_02_large.psb + mtl_p7_box_case_metal_02_medium.psb + mtl_p7_box_case_metal_02_small.psb + mtl_p7_box_case_metal_02_steel.psb + mtl_p7_box_case_metal_02_worn_Aluminum.psb + mtl_p7_box_case_metal_02_worn_steel.psb + mtl_p7_box_case_metal_dirty.psb + mtl_p7_box_case_metal_rubber.psb + mtl_p7_box_case_metal_rust.psb +
#F:\Producer_Backup_20150429\Art\Activision\2014.11.10\outsource_art\source_art\model_export\t7_props\p7_crutch_underam_metal_set * p7_crutch_underam_metal_set.ma + p7_crutch_underam_metal_set_high.ma + mtl_p7_box_case_metal_rust.psb + mtl_p7_crutch_underam_metal.psb + mtl_p7_crutch_underam_metal_aluminum.psb + mtl_p7_crutch_underam_metal_breakfoam.psb + mtl_p7_crutch_underam_metal_dirty.psb + mtl_p7_crutch_underam_metal_foam.psb + mtl_p7_crutch_underam_metal_vinyl.psb + mtl_p7_crutch_underam_metal_worn_aluminum.psb + mtl_p7_crutch_underam_metal_worn_breakfoam.psb + mtl_p7_crutch_underam_metal_worn_dirty.psb + mtl_p7_crutch_underam_metal_worn_foam.psb + mtl_p7_crutch_underam_metal_worn_vinyl.psb +
#...
python:
对相同名字的值进行打印
import io
import re
import json
class SameNameChackerClass:
def __init__(self,txtToRead):
self.txtToRead = txtToRead
def readByLine(self):
f = io.open(self.txtToRead,'r',encoding='utf-8')
fileContents = f.read()
fileContents = fileContents.splitlines()
allPath = []
for singleContentSet in fileContents:
singleContentSetArray = singleContentSet.split(" * ")
gassname = singleContentSetArray[0].rsplit('\\',1)
allPath.append(gassname[-1])
duplicated = set()
seen = set()
for path in allPath:
if path not in seen:
seen.add(path)
else:
duplicated.add('\\'+path)
f.close()
print(duplicated)
def readByLine2(self):
f2 = io.open(self.txtToRead,'r',encoding='utf-8')
fileContents = f2.read()
fileContents = fileContents.splitlines()
allPath2 = []
for singleContentSet in fileContents:
singleContentSetArray = singleContentSet.split(" * ")
gassname = eval(singleContentSetArray[1])
gassnameStr = str(gassname[-1])
allPath2.append(gassnameStr)
print(gassnameStr)
duplicated = set()
seen = set()
for path in allPath2:
if path not in seen:
seen.add(path)
else:
duplicated.add(path)
f2.close()
print(duplicated)
def readByLine3(self):
f2 = io.open(self.txtToRead,'r',encoding='utf-8')
fileContents = f2.read()
fileContents = fileContents.splitlines()
allPath2 = []
for singleContentSet in fileContents:
singleContentSetArray = singleContentSet.split(" * ")
gassname = eval(singleContentSetArray[1])
gassnameStr = str(gassname[-1])
gassnameStr = gassnameStr.rsplit(" ",1)[-1].split(".")[0]
allPath2.append(gassnameStr+'.')
print(gassnameStr)
duplicated = set()
seen = set()
for path in allPath2:
if path not in seen:
seen.add(path)
else:
duplicated.add(path)
f2.close()
print(duplicated)
S = SameNameChackerClass('exprot11111.txt')
S.readByLine3()
python:
对字符中特定部分相同的路径名进行打印import io
import re
import json
def readTxtOne(strRead1):
f = io.open(strRead1,'r',encoding='utf-8')
fileContents = f.read()
#切片
pathList = re.split('F:',fileContents)
for i in range(len(pathList)):
pathList[i] ="F:"+pathList[i]
del pathList[0]
#申请字典
dic2={}
#单个数据组
for siglePathList in pathList:
siglePathListSplit = siglePathList.split(" * ",1)
key = siglePathListSplit[0].strip()
value = siglePathListSplit[1].strip()
dic2[key] = value
f.close()
return dic2
def export(dic,strOutPut):
file = io.open(strOutPut,'w',encoding='utf-8')
for k,v in dic.items():
file.write(str(k)+' * '+str(v)+'\n')
file.io.close()
#执行
print("1")
strRead1 = 'exprot1 - 副本 - 副本 - out.txt'
strRead2 = 'pathCollitionMB_out2.txt'
strOutPut = 'exprot11111.txt'
b=readTxtOne(strRead1)
a=readTxtOne(strRead2)
c = {}
sameKey = {}
for key in a:
if(key in b and a[key] == b[key]):
sameKey[key] = a[key]
print(sameKey)
c = dict(a,**b)
export(c,strOutPut)
#print(strRead1+"与"+strRead2+"共有的路径:"+ a.keys() & b.keys)
python:
根据文件名 猜测文件夹中包含的内容
import io
import re
import json
class GuseeWhatInForlder:
def __init__(self,txtToRead,txtToExprot):
self.txtToRead = txtToRead
self.txtToExprot = txtToExprot
def readByLine(self):
listR=[]
print('reading:...'+self.txtToRead)
f = io.open(self.txtToRead,'r',encoding='utf-8')
fileContents = f.read()
fileContents = fileContents.splitlines()
for singlePathSet in fileContents:
singlePathSetArray = singlePathSet.split(" * ")
gassname = singlePathSetArray[0].rsplit("\\",1)
gassname[-1]
gassname2 = singlePathSetArray[1].strip().replace(' ','').split("+")[0].split(".")[0]
FinalGuess = " 最终文件夹名: "+gassname[-1]+" 包含关键字: "+gassname2
print(FinalGuess)
listR.append(FinalGuess)
f.close()
return listR
def outPut(self):
file = io.open(self.txtToExprot,'w',encoding='utf-8')
G = GuseeWhatInForlder(self.txtToRead,self.txtToExprot)
listR =G.readByLine()
for item in listR:
file.write(str(item)+'\n')
file.io.close()
G = GuseeWhatInForlder('ForExcel.txt','ForExcel_guess.txt')
G.readByLine()
G.outPut()
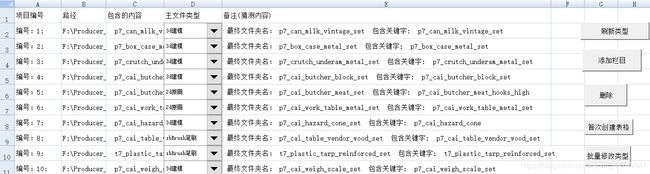
#Res:
#最终文件夹名: Male Khaki Pants 包含关键字: Pants
#最终文件夹名: 20130805 eck Tshirt 包含关键字: Tshirt
#最终文件夹名: Sleeve Button Up Shirt 包含关键字: Shirt
#最终文件夹名: Cutoff Jean Shorts 包含关键字: Shorts
#...
excel vba:
方便录入,给后端读取
'Option Explicit
Public GV As Variables_Global
Type Variables_Global
shtName As String
nameTitle As String
typeName As Variant
initialValue As Variant
addNew As Integer
deletNew As Integer
addNewDefaultOpition As Integer
fromChangeRow As Integer
toChangeRow As Integer
changeTo As Integer
End Type
Private Sub Init()
GV.shtName = "Sheet1"
GV.nameTitle = "项目名 "
GV.typeName = Array("3d建模", "2d原画", "zbRrush笔刷", "类型4", "类型5")
GV.initialValue = Array("2", "1100")
GV.addNew = 5
GV.deletNew = 1
GV.addNewDefaultOpition = 3
'改
GV.fromChangeRow = 1006 + 1
GV.toChangeRow = 937 + 1
GV.changeTo = 2
End Sub
'初次建立表格
Sub Main()
Delet (0)
Init
Log ("初始化成功")
RowNum_Creat (0)
ComboBox_Create (0)
ComboBox_CheckIn
End Sub
Sub Change()
Init
Dim myDropDown As Shape
Dim sName As String
'更改
For i = GV.fromChangeRow To GV.toChangeRow
'Set sName = ActiveSheet.Shape(i).Name
ActiveSheet.Shapes("Combo Box " & i).OLEFormat.Object.ListIndex = GV.changeTo
Next
'关联
ComboBox_CheckIn
End Sub
Sub Add()
Init
ComboBox_Create (GV.addNew)
RowNum_Creat (GV.addNew)
'关联
ComboBox_CheckIn
End Sub
Sub Delete()
Init
Delet (GV.deletNew)
End Sub
Sub ReflashType()
Init
ComboBox_Create (-1)
End Sub
Private Sub Log(tex)
MsgBox (tex)
End Sub
Private Sub RowNum_Creat(Number As Integer)
Select Case Number
Case 0
Set sht = ThisWorkbook.Worksheets(GV.shtName)
For i = GV.initialValue(0) To GV.initialValue(1)
ActiveSheet.Cells(i, 1) = GV.nameTitle & i - 1 & ":"
Next
Case 1 To 9999
For i = ActiveSheet.UsedRange.Rows.Count To ActiveSheet.UsedRange.Rows.Count + Number
ActiveSheet.Cells(i, 1) = GV.nameTitle & i - 1 & ":"
Next
Case Else
Log ("RowNum_Creat_请输入数字")
End Select
End Sub
Private Sub ComboBox_CheckIn()
For i = 2 To ActiveSheet.UsedRange.Rows.Count
ActiveSheet.Shapes("Combo Box " & i).ControlFormat.LinkedCell = "$D$" & i
Next
End Sub
Private Sub ComboBox_Create(Number As Integer)
'PURPOSE: Create a form control combo box and position/size it
Dim Cell As Range
Dim sht As Worksheet
Dim myDropDown As Shape
Dim myArray As Variant
'myArray = Array("Q1", "Q2")
Select Case Number
Case -1
Set sht = ActiveSheet
'刷新
For i = 2 To sht.UsedRange.Rows.Count
Dim myArrayElement As Integer
'记录
myArrayElement = Range("D" & i & ":D" & i).Value
'Create & Dimension to a Specific Cell Range
Set Cell = Range("D" & i & ":D" & i)
Set myDropDown = ActiveSheet.Shapes("Combo Box " & i)
myDropDown.ControlFormat.LinkedCell = "$ C $ & i"
myDropDown.OLEFormat.Object.List = GV.typeName
myDropDown.OLEFormat.Object.ListIndex = myArrayElement
Next
'关联
ComboBox_CheckIn
Case 0
Set sht = ActiveSheet
For i = 2 To sht.UsedRange.Rows.Count
'Create & Dimension to a Specific Cell Range
Set Cell = Range("D" & i & ":D" & i)
With Cell
ActiveSheet.DropDowns.Add(.Left, .Top, .Width, .Height).Name = "Combo Box " & i
End With
Set myDropDown = ActiveSheet.Shapes("Combo Box " & i)
myDropDown.ControlFormat.LinkedCell = "$ C $ & i"
myDropDown.OLEFormat.Object.List = GV.typeName
myDropDown.OLEFormat.Object.ListIndex = 1
Next
Case 1 To 9999
For i = ActiveSheet.UsedRange.Rows.Count + 1 To ActiveSheet.UsedRange.Rows.Count + Number
'Create & Dimension to a Specific Cell Range
Set Cell = Range("D" & i & ":D" & i)
With Cell
ActiveSheet.DropDowns.Add(.Left, .Top, .Width, .Height).Name = "Combo Box " & i
End With
Set myDropDown = ActiveSheet.Shapes("Combo Box " & i)
myDropDown.ControlFormat.LinkedCell = "$ C $ & i"
myDropDown.OLEFormat.Object.List = GV.typeName
myDropDown.OLEFormat.Object.ListIndex = GV.addNewDefaultOpition
Next
Case Else
Log ("ComboBox_Create_请输入数字")
End Select
End Sub
Private Sub Delet(Number As Integer)
' Set sht = ThisWorkbook.Worksheets(GV.shtName)
Dim shp As Shape
Dim dd As Shape
Select Case Number
Case 0
'DeletAllText
For i = 2 To ActiveSheet.UsedRange.Rows.Count
With Range("A" & i & ":D" & i)
.ClearContents
End With
Next
'DeletAllDropDowns
For Each shp In ActiveSheet.Shapes
If Left(shp.Name, 6) = "Button" Then
Else
shp.Delete
End If
Next shp
' Case 1
'
' Log ("Delet_表头不可以删除")
Case 1 To 1000
'DeletSeletRowCell
For i = ActiveSheet.UsedRange.Rows.Count - (Number - 1) To ActiveSheet.UsedRange.Rows.Count
With Range("A" & i & ":D" & i)
.ClearContents
End With
'DeletSeletRowShap
ActiveSheet.Shapes("Combo Box " & i).Delete
Next
Case Else
Log ("Delet_请输入数字")
End Select
End Sub
pic:
最终