Linux ----------------------- 文本处理工具
(一)绪论
awk、grep、sed和cut 是Linux 操作文本的四大利器,合称文本四大金刚,也是必须掌握的Linux 命令之一。这四个工具的功能各有侧重:
awk:功能最强大,用于处理和格式化文本,可以进行复杂的文本处理和数据提取,通常用于处理结构化数据,例如 CSV 文件。
grep:主要用于在文本中查找和匹配特定字符串或模式,是一个文本搜索工具。
sed:用于编辑匹配到的文本,可以进行替换、删除、插入等操作,是一个文本编辑工具。
cut:用于从文本中提取指定的字段或列,通常用于文本列的分割。
接下来我们详细分析这四个命令。
(二)awk
awk是一种强大的文本分析工具,主要用于在linux/unix 下对文本和数据进行处理。
对数据进行分析、统计并生成报表,比如网站的访问量,访问的IP 量等等。
awk是一种编程语言,awk可以定义变量、运算符,使用流程控制语句进行深度加工
与分析。awk其名称得自于它的创始人.Alfred Aho 、Peter Weinberger 和 Brian Kernighan
姓氏的首个字母。
awk的处理文本和数据的方式:把文件逐行读入,以空格为默认分隔符将每行切片。
切片的部分再进行各种分析处理。。
语法
awk [选项参数] 'script' var=value file(s) 或 awk [选项参数] -f scriptfile var=value file(s)即 awk 选项参数 ‘命令部分' 文件名,注意:引用shell变量需要双引号引起。
选项参数说明:
- --F : 指定文件拆分分隔符,如果不写默认是空格
- -v : 赋值一个用户定义变量,将外部变量传递给awk
- -f :赋值一个用户定义变量,将外部变量传递给awk
AWK内置变量
| 变量名 | 含义 |
| $n | 指整条变量,当前记录的第n个字段。比如n为1 表示第一个字段 |
| $NF | 表示最后一列的信息,跟变量NF是有区别的,变量NF统计的是每行 列的总数 |
| $0 | 这个变量包含执行过程中当前行的文本内容 |
| ARGC | 命令行参数的个数 |
| ARGIND | 命令行中当前文件的位置 |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g) |
| ENVIRON | 环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分割) |
| FILENAME | 当前输入文件的名 |
| NR | 表示记录数,在执行过程中对应当前的行号 |
| FNR | 同NR;但相对于当前文件 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果真,进行忽略大小写的匹配 |
| NF | 表示字段数,在执行过程中对应当前的字段数。print $NF 打印一行中最后一个字段 |
| OFMT | 数字的输出格式(默认值为%.6g) |
| OFS | 输出字段分隔符(默认是一个空格) |
| ORS | 输出记录分隔符(默认是一个换行符) |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由 match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数字下标分割符(默认是34) |
实例:
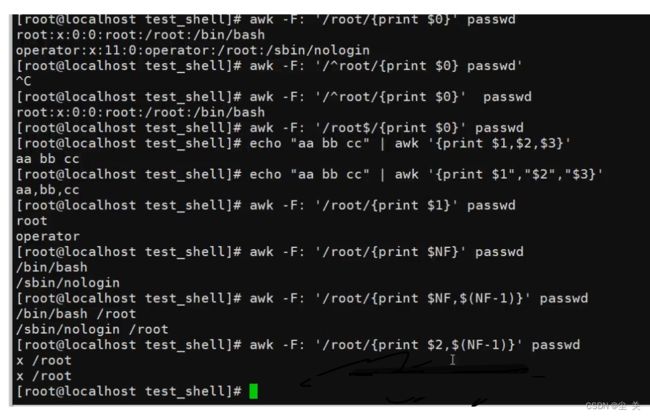
格式化输出 'print'和'printf’
print函数 类似echo,它是换行输出
printf函数 类似echo-n,它不换行输出,可以使用%s,%d进行占位。其中%s表示字符类型,%d数值类型。-表示左对齐,默认右对齐。
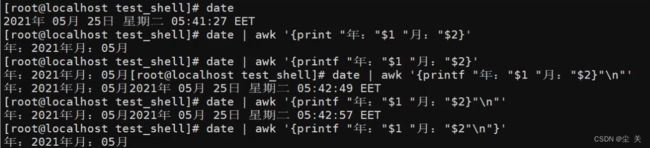
BEGIN……END使用
BEGIN:表示在程序开始前执行。
END:表示所有文件处理完后执行。
用法:'BEGIN‘{开始处理前};{处理中};END{处理结束后}’
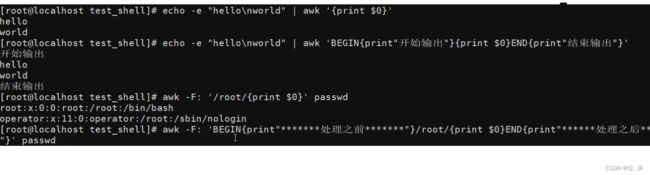
定义变量 -v
![]()
流程控制语句
条件语句——IF 语句
IF 条件语句语法格式如下:
if (condition)
action
也可以使用花括号来执行一组操作:
if (condition)
{
action-1
action-1
.
.
action-n
}
条件语句——IF - ELSE 语句
IF - ELSE 条件语句语法格式如下:
if (condition)
action-1
else
action-2
在条件语句 condition 为 true 时执行 action-1,否则执行 action-2。
条件语句——IF - ELSE - IF
IF - ELSE 条件语句语法格式如下:
if (condition) action-1 else if (condition1) action-2 ……else if (conditionn) action-n
else action-m

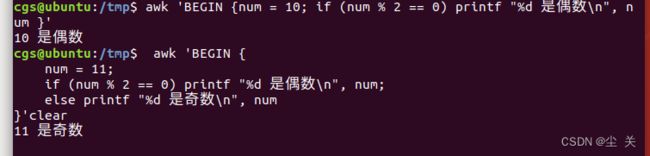

循环——For
For 循环的语法如下:
for (initialisation; condition; increment/decrement)
action
for 语句首先执行初始化动作( initialisation ),然后再检查条件( condition )。如果条件为真,则执行动作( action ),然后执行递增( increment )或者递减( decrement )操作。只要条件为 true 循环就会一直执行。每次循环结束都会进条件检查,若条件为 false 则结束循环。
下面的例子使用 For 循环输出数字 1 至 5:
$ awk 'BEGIN { for (i = 1; i <= 5; ++i) print i }'
循环——While
While 循环的语法如下:
while (condition)
action
While 循环首先检查条件 condition 是否为 true ,若条件为 true 则执行动作 action。此过程一直重复直到条件 condition 为 flase 才停止。
下面是使用 While 循环输出数字 1 到 5 的例子:
$ awk 'BEGIN {i = 1; while (i < 6) { print i; ++i } }'
Break
break 用以结束循环:
在下面的示例子中,当计算的和大于 50 的时候使用 break 结束循环:
Continue
Continue 语句用于在循环体内部结束本次循环,从而直接进入下一次循环迭代。
下面的例子输出 1 到16 之间的偶数:
Exit
Exit 用于结束脚本程序的执行。
该函数接受一个整数作为参数表示 AWK 进程结束状态。 如果没有提供该参数,其默认状态为 0。
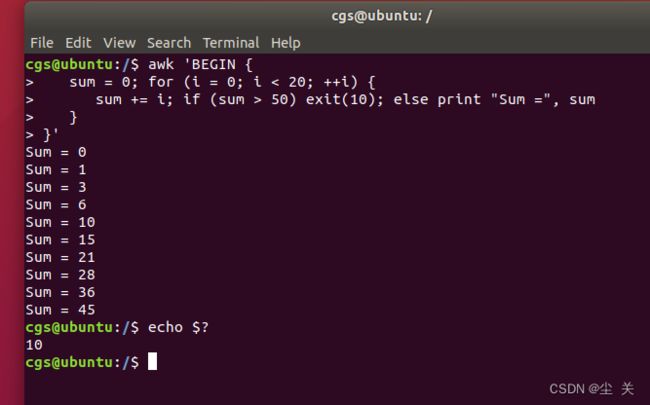
下面例子中当和大于 50 时结束 AWK 程序。
awk 'BEGIN {
sum = 0; for (i = 0; i < 20; ++i) {
sum += i; if (sum > 50) exit(10); else print "Sum =", sum
}
}'
让我们检查一下脚本执行后的返回状态:
$ echo $?
执行上面的命令可以得到如下的结果:
(三)grep
grep是一种强大的文本搜索工具,用于关键字进行过滤,并把匹配到的行进行打印,特别的是他在一个或多个文件中搜索满足模式的文本行。
语法形式:
grep [选项] '关键词' 文件名
常见的grep的选项参数:
| 选项 | 作用 |
| -c | 只输出匹配到的行数 |
| -i | 不区分大小写(只适用于单字符) |
| -v | 显示不包匹配文本的所有行 |
| -w | 按单词搜索 |
| -o | 打印匹配关键字 |
| -A | 显示匹配行即后面多少行 |
| -B | 显示匹配行即前面多少行 |
| -C | 显示匹配行即前后多少行 |
| -e | 使用正则匹配 |
| -E | 使用扩展正则匹配 |
| -h | 查询多文件时不显示文件名 |
| -n | 显示匹配行及行号 |
| -s | 不显示不存在或无匹配文本的错误信息 |
| ^key | 以关键字开头 |
| ^$ | 匹配空行 |
(四)cut
cut:剪切,切割,是一个强大文本处理工具,它是将文本按列进行划分的文本处理。cut命令逐行读入文本,按列划分字段并进行提取、输出等操作。
语法形式:
cut [选项] 文件名
常见的选项参数:
| 参数 | 作用 |
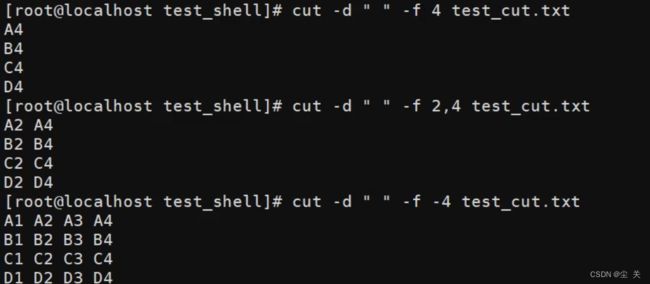
| -f 提取范围 | 列号,获取第几列 |
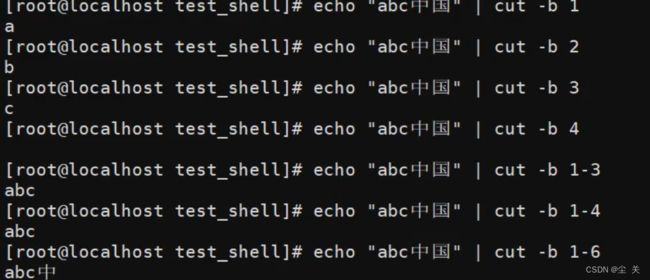
| -c 以字符为例 | 以字符为单位进行分割 |
| -b 提取范围 | 以字节为单位进行分割,这些字节位置将忽略多字节字符边界,除非其指定-n标志 |
| -d 自定义分隔符 | 自定义分隔符,默认为制表符 |
| -n | 与“-b"选项连用,不分隔多字节字符 |
提取范围说明:
| 提取范围 | 说明 |
| n- | 提取指定第n列或字符或字节后面所有数据 |
| n-m | 提取指定第n列或字符或字节到第m列字符或字节中间所有数据 |
| -m | 提取指定第m列或字符或字节前面所有数据 |
| n1,n2…… | 提取枚举列的所有数据 |
示范:

(五)sed
sed是Linux下一款功能强大的非交互流式文本编辑器,可以对文本文件进行增、删、改、查等操作,支持按行、按字段,技正则匹配文本内容,灵活方便,特别适合于大文件的
编辑。
sed工作原理:sed会读取每一行数据到模式空间中,判断当前行是否符合模式匹配要求,符合要求就会执行sed程序命令,否则不会执行sed程序命令,如果不写匹配模式,那么每一行都会执行sed程序命令。
sed的使用语法:
sed [选项参数] [模式匹配|sed程序命令] [文件名]
sed的常用选项:
| 选项 | 作用 |
| -r | 使用扩展正则表达式 |
| -e | 告诉sed将下一个参数解释为一个sd指令,只有当命令行上给出多个sed指令时才需要使用-e |
| -f | 后跟保存sed指令的文件 |
| -i | 直接对内容进行修改,不加-i时默认只是预览,不会对文件做实际修改 |
| -n | 取消默认输出,sed默认会输出所有文本内容,使用-n 参数后只显示处理过的行 |
