用全文检索构建站内搜索和大数据搜索引擎
全文检索首先对要搜索的文档进行分词,然后形成索引,通过查询索引来查询文档。全文检索是目前搜索引擎,大数据搜索的关键技术。全文检索系统可实现亚秒级的检索速度以及每秒上百次的并发检索支持。
需求:
实现淘宝京东等电商网站中商品信息搜索功能,可以根据关键词(分词)、分类、商品简介,详情等搜索商品信息,可以根据相关度,价格,销量等做排序。
比如,我们搜索“实惠的老人机”

要求:
分词检索:比如我们输入:“实惠的老人机”,有效分词: “实惠” ,“老人机”,"“老人", "机”, 无效分词:“的“, 默认按照商品标题,描述,详情,分类等相关度的高低进行排序(我们不学百度高竞价,以搜索关键词相关度为默认排序),并可以按照用户所选条件进行排序。
解决方案:
1.数据库的Like模糊搜索。(不采用)
数据库Like模糊搜索是典型的顺序扫描方法,数据量大就搜索得特别慢。最重要的是无法进行分词检索。
2.数据库的全文索引。(不推荐)
目前各大数据库的全文索引支持性还不是很好。以MySQL为例子:MySQL不支持中文全文检索。虽然支持英文的全文检索但表的存储引擎要是MyISAM,默认存储引擎InnoDB不支持全文索引(MYSQL5.6以上的InnoDB支持全文索引)。但不支持中文分词,所以我们需要自行扩展。
3.采用Apache的顶级开源项目Solr构建索引库构建全文检索引擎,它是基于Lucene的全文搜索服务器。为了扩容和应对高并发,我们还要搭建SolrCloud集群,这里我们搭建最小的集群模块:2台Solr,各有1台备份机,需要4台Servlet服务容器。
什么是lucene?
Lucene是Apache的一个全文检索引擎工具包,通过lucene可以让程序员快速开发一个全文检索功能。
Lucene实现全文检索的流程
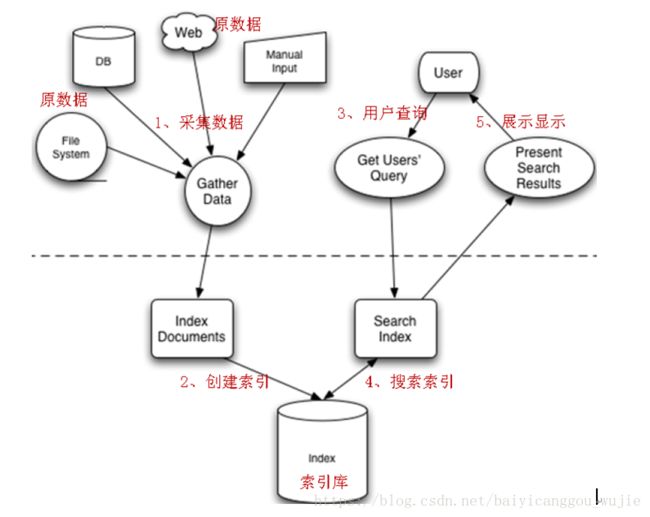
想必小伙伴们都用过下面这个Everything文件搜索工具,接下来我们先用Lucene来实现一个"乞丐版的Everything"文件检索系统。

乞丐版的Everything

我在”C:\Users\hp\Desktop\测试“下放置了以下文件,现在让我们用Lucene进行文件检索,要求检索文件标题和文件内容中含有相关分词的文件并按照搜索关键词出现的频次降序排列。

// 创建索引
@Test
public void testIndex() throws Exception {
// 创建一个indexwriter对象
Directory directory = FSDirectory.open(new File("C:\\Users\\hp\\Desktop\\index")); //索引库存储路径
// Directory directory = new RAMDirectory();//保存索引到内存中 (内存索引库)
Analyzer analyzer = new StandardAnalyzer();// 官方推荐的标准分词器
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, config);
// 1)指定索引库的存放位置Directory对象
// 2)指定一个分析器,对文档内容进行分析
// 第三步:创建field对象,将field添加到document对象中。
File f = new File("C:\\Users\\hp\\Desktop\\测试"); //源文件目录
File[] listFiles = f.listFiles();
for (File file : listFiles) {
// 创建document对象
Document document = new Document();
// 文件名称
String file_name = file.getName();
Field fileNameField = new TextField("fileName", file_name, Store.YES);
// 文件大小
long file_size = FileUtils.sizeOf(file);
Field fileSizeField = new LongField("fileSize", file_size, Store.YES);
// 文件路径
String file_path = file.getPath();
Field filePathField = new StoredField("filePath", file_path);
// 文件内容
String file_content = FileUtils.readFileToString(file);
Field fileContentField = new TextField("fileContent", file_content, Store.YES);
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContentField);
// 使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库
indexWriter.addDocument(document);
}
// 关闭IndexWriter对象。
indexWriter.close();
}运行结果:成功创建了索引库。

我们搜索文件名有"apache"的相关文件:
// 搜索索引
@Test
public void testSearch() throws Exception {
// 第一步:创建一个Directory对象,也就是索引库存放的位置
Directory directory = FSDirectory.open(new File("C:\\Users\\hp\\Desktop\\index"));
// 第二步:创建一个indexReader对象,需要指定Directory对象
IndexReader indexReader = DirectoryReader.open(directory);
// 第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词
Query query = new TermQuery(new Term("fileName", "apache"));
// 第五步:执行查询。
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("搜索到相关文件数:" + topDocs.scoreDocs.length);
// 第六步:返回查询结果。遍历查询结果并输出。
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
// 文件名称
String fileName = document.get("fileName");
System.out.println("文件名称:" + fileName);
// 文件内容
String fileContent = document.get("fileContent");
System.out.println("文件内容:" + fileContent);
// 文件大小
String fileSize = document.get("fileSize");
System.out.println("文件大小:" + fileSize);
// 文件路径
String filePath = document.get("filePath");
System.out.println("文件路径:" + filePath);
System.out.println("------------");
}
// 第七步:关闭IndexReader对象
indexReader.close();
}结果:

现在我们搜索——文件名“语录”,文件内容含有"斗地主"的文件
// 搜索索引:搜索文件名“语录”,文件内容含有"斗地主"的文件
@Test
public void testMultSearch() throws Exception {
// 第一步:创建一个Directory对象,也就是索引库存放的位置
Directory directory = FSDirectory.open(new File("C:\\Users\\hp\\Desktop\\index"));
// 第二步:创建一个indexReader对象,需要指定Directory对象
IndexReader indexReader = DirectoryReader.open(directory);
// 第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 第四步:创建一个Query对象,指定查询的域和查询的关键词
// 参数1: 默认查询的域
// 参数2:采用的分析器
QueryParser queryParser = new QueryParser("fileName", new StandardAnalyzer());
// *:* 域:值
Query query = queryParser.parse("fileName:语录 AND fileContent:斗地主");
// 第五步:执行查询。
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("搜索到相关文件数:" + topDocs.scoreDocs.length);
// 第六步:返回查询结果。遍历查询结果并输出。
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
// 文件名称
String fileName = document.get("fileName");
System.out.println("文件名称:" + fileName);
// 文件内容
String fileContent = document.get("fileContent");
System.out.println("文件内容:" + fileContent);
// 文件大小
String fileSize = document.get("fileSize");
System.out.println("文件大小:" + fileSize);
// 文件路径
String filePath = document.get("filePath");
System.out.println("文件路径:" + filePath);
System.out.println("------------");
}
// 第七步:关闭IndexReader对象
indexReader.close();
}结果:
目前,我们用的是apache提供的标准的分词器,但其实标准分词器对中文的分词bu't不太友好。具体可以写个C++的文件指针测试一下。
// 用C++的文件指针查看标准分析器的分词效果
@Test
public void testTokenStream() throws Exception {
// 创建一个标准分析器对象
// Analyzer analyzer = new StandardAnalyzer();
// Analyzer analyzer = new CJKAnalyzer();
// Analyzer analyzer = new SmartChineseAnalyzer();
Analyzer analyzer = new IKAnalyzer();
// 获得tokenStream对象
// 第一个参数:域名,可以随便给一个
// 第二个参数:要分析的文本内容
// TokenStream tokenStream = analyzer.tokenStream("test",
// "The Spring Framework provides a comprehensive programming and configuration model.");
TokenStream tokenStream = analyzer.tokenStream("test",
"高富帅从过去到未来,一直致力于电动车核心技术的研发,全面保障电动车使用安全,全面提升电动车续航能力,全面优化电动车防盗体验");
// 添加一个引用,可以获得每个关键词
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
// 添加一个偏移量的引用,记录了关键词的开始位置以及结束位置
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
// 将指针调整到列表的头部
tokenStream.reset();
// 遍历关键词列表,通过incrementToken方法判断列表是否结束
while (tokenStream.incrementToken()) {
// 关键词的起始位置
System.out.println("start->" + offsetAttribute.startOffset());
// 取关键词
System.out.println(charTermAttribute);
// 结束位置
System.out.println("end->" + offsetAttribute.endOffset());
}
tokenStream.close();
}
结果:
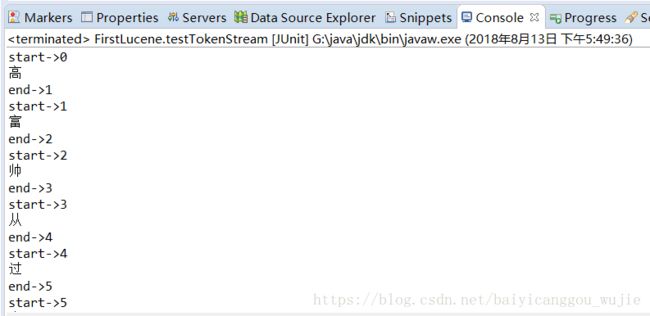
这个不是分词,是拆字呀,明显无法满足要求。这里我们引入第三方的IKAnalyzer中文分词器。注意:创建索引库和查询索引的分词器要保持一致。
查看IKAnalyzer的分词效果:
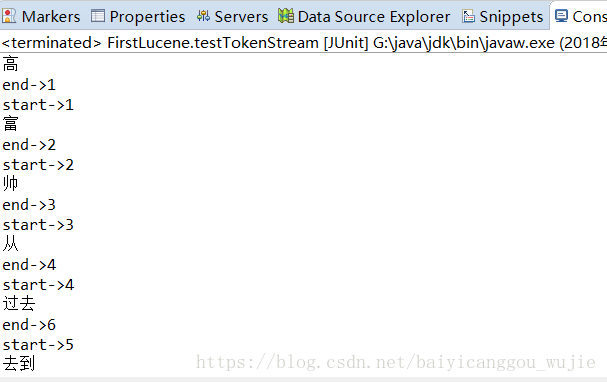
比拆字的好一些,但还是不够理想,以前”高富帅“不是一个词,但现在是一个词,我们需要扩展一下字典库。我们将”高富帅“作为一个分词。
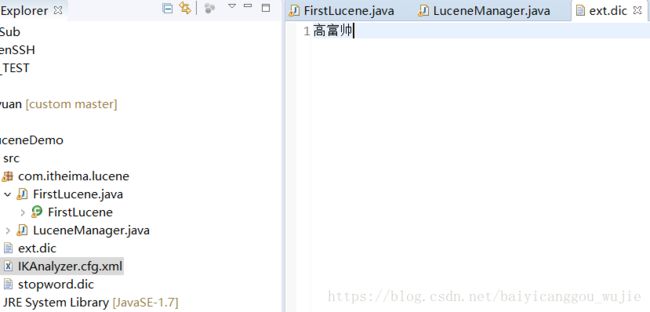
结果完美:

在了解了Lucene以后,我们可以开始在Linux上搭建Solr服务了。
什么是solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr可以独立运行在Jetty(Jetty是Solr内置的一个轻量级Servlet容器)、Tomcat等这些Servlet容器中。
Solr的目标是打造一款企业级的搜索引擎系统,它是基于Lucene一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
搭建步骤
第一步:把solr 的压缩包上传到Linux系统。
第二步:解压solr。

第三步:安装Tomcat,解压缩即可。
第四步:把solr部署到Tomcat下。
第五步:解压缩war包。可以启动Tomcat解压。

第六步:把/root/solr-4.10.3/example/lib/ext目录下的所有的jar包,添加到solr工程中,并加入配置文件到solr工程中。
[root@localhost ext]# pwd
/root/solr-4.10.3/example/lib/ext
[root@localhost ext]# cp * /usr/local/apache-tomcat-8.5.30/webapps/solr/WEB-INF/lib/

第七步:创建一个solrhome。/example/solr目录就是一个solrhome。复制此目录到/usr/local/solr/solrhome
[root@localhost example]# pwd
/root/solr-4.10.3/example
[root@localhost example]# cp -r solr /usr/local/solr/solrhome
[root@localhost example]#
第八步:关联solr及solrhome。需要修改solr工程的web.xml文件。需要删除这里的注释,并将地址改成我们真实的地址。
原来的:
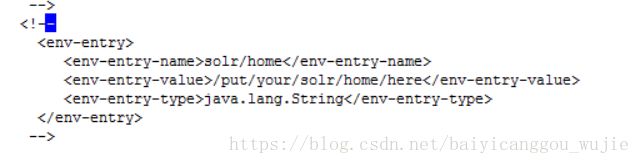
更改后:

第九步:启动Tomcat。
访问地址:http://192.168.25.128:8080/solr/#/,访问成功表示solr搭建成功,这个后台管理系统我们平时只是拿来测试索引库。

Solr的使用
配置业务域
添加文档必须有id域,其他域 必须在solr的schema.xml中定义。
假设我们有这么三张表:商品表,商品详情描述表和商品分类表。
CREATE TABLE `tb_item` (
`id` bigint(20) NOT NULL COMMENT '商品id,同时也是商品编号',
`title` varchar(100) NOT NULL COMMENT '商品标题',
`sell_point` varchar(500) DEFAULT NULL COMMENT '商品卖点',
`price` bigint(20) NOT NULL COMMENT '商品价格,单位为:分',
`num` int(10) NOT NULL COMMENT '库存数量',
`barcode` varchar(30) DEFAULT NULL COMMENT '商品条形码',
`image` varchar(500) DEFAULT NULL COMMENT '商品图片',
`cid` bigint(10) NOT NULL COMMENT '所属类目,叶子类目',
`status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '商品状态,1-正常,2-下架,3-删除',
`created` datetime NOT NULL COMMENT '创建时间',
`updated` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `cid` (`cid`),
KEY `status` (`status`),
KEY `updated` (`updated`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品表';
CREATE TABLE `tb_item_desc` (
`item_id` bigint(20) NOT NULL COMMENT '商品ID',
`item_desc` text COMMENT '商品描述',
`created` datetime DEFAULT NULL COMMENT '创建时间',
`updated` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`item_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品描述表';
CREATE TABLE `tb_item_cat` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '类目ID',
`parent_id` bigint(20) DEFAULT NULL COMMENT '父类目ID=0时,代表的是一级的类目',
`name` varchar(50) DEFAULT NULL COMMENT '类目名称',
`status` int(1) DEFAULT '1' COMMENT '状态。可选值:1(正常),2(删除)',
`sort_order` int(4) DEFAULT NULL COMMENT '排列序号,表示同级类目的展现次序,如数值相等则按名称次序排列。取值范围:大于零的整数',
`is_parent` tinyint(1) DEFAULT '1' COMMENT '该类目是否为父类目,1为true,0为false',
`created` datetime DEFAULT NULL COMMENT '创建时间',
`updated` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `parent_id` (`parent_id`,`status`) USING BTREE,
KEY `sort_order` (`sort_order`)
) ENGINE=InnoDB AUTO_INCREMENT=1183 DEFAULT CHARSET=utf8 COMMENT='商品类目';我们需要商品标题,商品卖点,商品价格,商品图片,分类名称,商品描述做检索,需要在schema.xml中定义以下业务域:
- 商品Id:使用schema.xml中的id域
- 商品标题
- 商品卖点
- 商品价格
- 商品图片
- 分类名称
- 商品描述
创建对应的业务域。
创建步骤:
第一步:把中文分析器添加到solr工程中。
1、把IKAnalyzer2012FF_u1.jar添加到solr工程的lib目录下。
2、把扩展词典、配置文件放到solr工程的WEB-INF/classes目录下。

第二步:配置一个FieldType,制定使用IKAnalyzer。
修改schema.xml文件。

修改Solr的schema.xml文件,添加FieldType,使中文分词器生效:

第三步:配置业务域,type制定使用自定义的FieldType。
设置业务系统Field。
第四步:重启tomcat。
测试使用solrJ管理索引库
写个单元测试类:
往索引库中添加一条记录:
/**
*
* @ClassName: TestSolrManager
* @Description: 测试solrJ管理索引库
* @Company: xx有限公司
* @author WuJie
* @date 2018年8月14日
*/
public class TestSolrManager {
@Test
public void add() throws Exception {
// 1.创建solrserver 建立连接 需要指定地址
SolrServer solrServer = new HttpSolrServer("http://192.168.25.128:8080/solr");
// 2.创建solrinputdocument
SolrInputDocument document = new SolrInputDocument();
// 3.向文档中添加域
document.addField("id", "wujie");
document.addField("item_title", "Hello World, Sorl!");
// 4.将文档提交到索引库中
solrServer.add(document);
// 5.提交
solrServer.commit();
}
}用管理后台查询一下:

一切正常。我们将测试数据删除。

现在,我们正式开始编写开始提出的——电商站内搜索商品的需求。
首先,我们需要将数据库中的商品相关数据导入到索引库中。这里的业务逻辑是:一旦商品相关数据发送更新,需要及时更新索引库。
创建之前提到的相关业务域的POJO:
/**
* 搜索的商品数据POJO
*/
public class SearchItem implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;//商品的id
private String title;//商品标题
private String sell_point;//商品卖点
private Long price;//价格
private String image;//商品图片的路径
private String category_name;//商品分类名称
private String item_desc;//商品的描述
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getSell_point() {
return sell_point;
}
public void setSell_point(String sell_point) {
this.sell_point = sell_point;
}
public Long getPrice() {
return price;
}
public void setPrice(Long price) {
this.price = price;
}
public String getImage() {
return image;
}
public void setImage(String image) {
this.image = image;
}
public String getCategory_name() {
return category_name;
}
public void setCategory_name(String category_name) {
this.category_name = category_name;
}
public String getItem_desc() {
return item_desc;
}
public void setItem_desc(String item_desc) {
this.item_desc = item_desc;
}
public String[] getImages(){
if(this.getImage()!=null){
String[] split = this.getImage().split(",");
return split;
}
return null;
}
}定义mapper接口和mapper映射文件(用的MyBaits3.0):
由于要关联查询3张表,而多表查询用不了MyBaits逆向工程,只能自己写接口和映射文件。
SearchItemMapper.java
//导入所有的商品数据到索引库中
ResultPoJo importAllItems() throws Exception;
//根据查询条件查询
SearchResult search(String queryString,Integer page,Integer rows) throws Exception;SearchItemMapper.xml
SearchItemServiceImpl.class
@Service
public class SearchItemServiceImpl implements SearchItemService {
@Autowired
private SearchItemMapper mapper;
@Autowired
private SolrServer solrServer;
@Autowired
private SearchDao searchDao;
@Override
public ResultPoJo importAllItems() throws Exception {
// 1、查询所有商品数据
List searchItemList = mapper.getSearchItemList();
// 2、创建一个SolrServer对象。
// 3、为每个商品创建一个SolrInputDocument对象。
for (SearchItem searchItem : searchItemList) {
SolrInputDocument document = new SolrInputDocument();
// 4、为文档添加域
document.addField("id", searchItem.getId());
document.addField("item_title", searchItem.getTitle());
document.addField("item_sell_point", searchItem.getSell_point());
document.addField("item_price", searchItem.getPrice());
document.addField("item_image", searchItem.getImage());
document.addField("item_category_name", searchItem.getCategory_name());
document.addField("item_desc", searchItem.getItem_desc());
// 5、向索引库中添加文档
solrServer.add(document);
}
// 提交修改
solrServer.commit();
return ResultPoJo.ok();
}
@Override
public SearchResult search(String queryString, Integer page, Integer rows) throws Exception {
// 1、创建一个SolrQuery对象。
SolrQuery query = new SolrQuery();
// 2、设置查询条件
query.setQuery(queryString);
// 3、设置分页条件
query.setStart((page - 1) * rows);
query.setRows(rows);
// 4、需要指定默认搜索域。
query.set("df", "item_title");
// 5、设置高亮
query.setHighlight(true);
query.addHighlightField("item_title");
query.setHighlightSimplePre("");
query.setHighlightSimplePost("");
// 6、执行查询,调用SearchDao。得到SearchResult
SearchResult result = searchDao.search(query);
// 7、需要计算总页数。
long recordCount = result.getRecordCount();
long pageCount = recordCount / rows;
if (recordCount % rows > 0) {
pageCount++;
}
result.setPageCount(pageCount);
// 8、返回SearchResult
return result;
}
} SearchDao.class
/**
* 由于搜索功能只在搜索工程中用到,可以不写接口,只写类;我们设计接口主要是为了方便不同服务之间相互调用
*
* @ClassName: SearchDao
* @Description: 从索引库中搜索商品的dao
* @Company: xx有限公司
* @author WuJie
* @date 2018年8月14日
*/
@Repository
public class SearchDao {
@Autowired
private SolrServer server;
/*
* 根据查询的条件查询商品的结果集
*/
public SearchResult search(SolrQuery query) throws Exception {
SearchResult searchResult = new SearchResult();
// 1.创建solrserver对象 由spring管理 注入
// 2.直接执行查询
QueryResponse response = server.query(query);
// 3.获取结果集
SolrDocumentList results = response.getResults();
// 设置searchresult的总记录数
searchResult.setRecordCount(results.getNumFound());
// 4.遍历结果集
// 定义一个集合
List searchItems = new ArrayList<>();
// 取高亮
Map>> highlighting = response.getHighlighting();
for (SolrDocument solrDocument : results) {
// 将solrdocument的属性 一个个的设置到 searchItem中
SearchItem item = new SearchItem();
item.setCategory_name(solrDocument.get("item_category_name").toString());
item.setId(Long.parseLong(solrDocument.get("id").toString()));
item.setImage(solrDocument.get("item_image").toString());
// item.setItem_desc(item_desc);
item.setPrice((Long) solrDocument.get("item_price"));
item.setSell_point(solrDocument.get("item_sell_point").toString());
// 取高亮
List list = highlighting.get(solrDocument.get("id")).get("item_title");
// 判断list是否为空
String gaoliangstr = "";
if (null != list && list.size() > 0) {
// 有高亮
gaoliangstr = list.get(0);
} else {
gaoliangstr = solrDocument.get("item_title").toString();
}
item.setTitle(gaoliangstr);
// searchItem 封装到SearchResult中的itemList 属性中
searchItems.add(item);
}
// 5.设置SearchResult 的属性
searchResult.setItemList(searchItems);
return searchResult;
}
} SearchController.class
@Controller
public class SearchController {
@Value("${ITEM_ROWS}")
private Integer ITEM_ROWS;
@Autowired
private SearchItemService service;
/**
* 根据条件搜索商品的数据
*
* @param page
* @param queryString
* @return
*/
@RequestMapping("/search")
public String search(@RequestParam(defaultValue = "1") Integer page, @RequestParam(value = "q") String queryString, Model model) throws Exception {
// 1.引入
// 2.注入
// 3.调用
// 处理乱码:
queryString = new String(queryString.getBytes("iso-8859-1"), "utf-8");
SearchResult result = service.search(queryString, page, ITEM_ROWS);
// 4.设置数据传递到jsp中
model.addAttribute("query", queryString);
model.addAttribute("totalPages", result.getPageCount());// 总页数
model.addAttribute("itemList", result.getItemList());
model.addAttribute("page", page);
return "search";
}
}最终效果:

我们搜索“给力的电动车”,结果:

再测试一波:
我们搜索“价廉物美的手机”:

结果,搜索到一波功能机:

IK中文分词器也存在诸多缺陷,我们还需要对其进行进一步优化。要想完善分词库,提高句子精度,得从词性分析,词&句子情感(情感识别),还有知识的提取,以及依存文法构建等一些东西来实现,已经属于AI人工智能的领域。