Hive 分桶表核心知识点
1. Hive 分桶表操作
1.1 数据分桶的定义
分桶是相对分区进行更细粒度的划分。
分桶将整个 hive 表数据内容按照某列属性值的 hash 值进行分区,通过分区将这些表数据划分到多个文件中进行存储。
其实桶的概念就是 MapReduce 分区的概念。物理上每个桶就是目录里的一个文件,一个任务作业产生的桶(即:输出文件)数量和设置的 reduce 任务个数相等。
假设有 hive 表:test_student,按照其字段 s_id 属性分为 3 个桶,那么就是对 s_id 属性值的 hash 值对 3 取模,按照取模结果对数据分桶。如取模结果为 0 的数据记录存放到一个文件,取模为 1 的数据存放到一个文件,取模为 2 的数据存放到一个文件。
1.2 数据分桶的意义
-
在处理大规模数据集时,在开发和修改查询阶段,可以使用整个数据集的一部分进行抽样测试查询、修改,提高开发效率;
-
解决单个表文件数据量过大的问题;
-
分桶表数据进行抽样和 JOIN 时可以提高 MapReduce 程序效率;
1.3 实现分桶的步骤
1.3.1 分桶表功能开启
打开 hive 客户端,在 hive 命令行执行以下命令来开启分桶表功能
#开启分桶表的功能
set hive.enforce.bucketing=true;
1.3.2 设置 Reduce 个数
#设置reduce的个数为3
set mapreduce.job.reduces=3;
1.3.3 创建分桶表
create table student_courses (c_id string, c_name string, t_id string, t_name string)clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
![]()
创建分桶表的关键字为:clustered by,来指定表已存在的列名,注意此处指定的列名 c_id 不需要指定其类型,因为是表 student_courses 存在的字段 c_id,已指定其类型为string,因此在分桶时只需指定字段名即可。
指定数字 3 buckets 表示为分 3 个桶,其他关键字与分区表创建含义一致。
1.4 分桶表加载数据
因为分桶表加载数据底层走的是 MapReduce 任务,所以之前讲到过的分区表的加载数据方式:hdfs dfs -put file... 和 load data[local] inpath...均不适用于分桶表的数据加载,因此只能通过 insert overwrite 的方式来加载数据。
具体分为以下三个步骤:
1.4.1 创建普通表
create table tem_student_courses(c_id string, c_name string, t_id string, t_name string)row format delimited fields terminated by '\t';
1.4.2 普通表加载数据
load data local inpath '/user/your_directory_file/student_course.csv' into table tem_student_courses;
此处本地文件 2_test.csv 的内容如下:
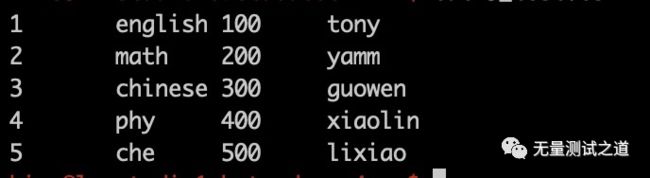

1.4.3 分桶表加载数据
#分桶表从普通表中加载数据
insert overwrite table student_courses select * from tem_student_courses cluster by(c_id);

1.4.4 查看桶信息
#查看分桶表的桶信息
hive> dfs -ls /user/hive/warehouse_uat/test.db/student_courses;

从图中可以看出,在 hdfs 里分桶表 student_courses 内容被分成 3 个文件存储,说明分桶成功。
1.4.5 查看分桶数据
#查看分桶表里分桶的数据
hive> select * from student_courses tablesample(bucket 1 out of 3 on c_id);
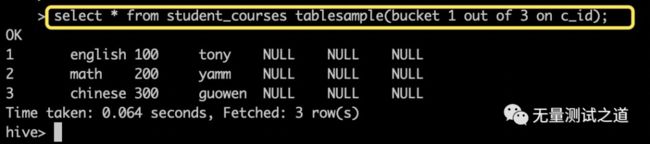
指定关键字:tablesample
2. Hive 分区表与分桶表的异同点
相同点
1. 分区和分桶都是对数据进行更细粒度的处理,便于数据的管理和开发效率的提升。
2. 都有固定且特有的关键字用于指定是否是分区表或分桶表。
不同点
1.表现形式
分区表:是指按照数据表的某列或某些列分为多个区,形式上可以理解为文件夹,可以是一级文件夹,也可以是多级文件夹,类似于目录。
分桶表:是相对分区进行更细粒度的划分,形式上可以理解为将一个文件的内容按照规则划分成多个文件进行存储,类似于文件。
2.关键字
分区表:使用关键字 partitioned by 标记,指定的分区字段名为:伪列(非表中定义的字段),同时需要指定伪列的字段类型。
分桶表:使用关键字 clustered by 标记,指定的分桶字段名为:真实字段(表中已定义的字段),但不需要指定分桶字段的类型,因为在表定义时字段已指定类型。
但是需要指定桶的个数。
3.数量上
分区表:分区个数创建后后续可以依据需求动态增加
分桶表:桶的个数一旦指定,不能再增加
4.作用上
-
分区避免全表扫描,根据 where 条件指定分区列来查询指定目录提高查询速度;
-
分桶保存分桶查询结果的分桶结构(因为数据已经按照分桶字段进行了 hash 散列);
-
分桶表数据进行抽样和 join 时可以提高 MapReduce 程序效率;
欢迎关注【无量测试之道】公众号,回复【领取资源】
Python+Unittest框架API自动化、
Python+Unittest框架API自动化、
Python+Pytest框架API自动化、
Python+Pandas+Pyecharts大数据分析、
Python+Selenium框架Web的UI自动化、
Python+Appium框架APP的UI自动化、
Python编程学习资源干货、
资源和代码 免费送啦~
文章下方有公众号二维码,可直接微信扫一扫关注即可。
备注:我的个人公众号已正式开通,致力于IT互联网技术的分享。
包含:数据分析、大数据、机器学习、测试开发、API接口自动化、测试运维、UI自动化、性能测试、代码检测、编程技术等。
微信搜索公众号:“无量测试之道”,或扫描下方二维码:

添加关注,让我们一起共同成长!