Java教程之多级缓存
多级缓存
1. 前言
提到缓存,想必每一位软件工程师都不陌生,它是目前架构设计中提高性能最直接的方式。
缓存技术存在于应用场景的方方面面。从网站提高性能的角度分析,缓存可以放在浏览器,可以放在反向代理服务器,还可以放在应用程序进程内,同时可以放在分布式缓存系统中。
从用户请求数据到数据返回,数据经过了浏览器,CDN,Nginx代理缓存,应用服务器,以及数据库各个环节。每个环节都可以运用缓存技术。

缓存的请求顺序是:用户请求 → HTTP 缓存 → CDN 缓存 → Nginx代理缓存 → 进程内缓存 → 分布式缓存。
在技术的架构每个环节都可以加入缓存,我们看看每个环节是如何应用缓存技术的。
2. HTTP缓存
通常 HTTP 缓存策略分为两种:
- 强缓存
- 协商缓存。
从字面意思我们可以很直观的看到它们的差别:
- 强缓存即强制直接使用缓存。
- 协商缓存就得和服务器协商确认下这个缓存能不能用。
强缓存
强缓存不会向服务器发送请求,直接从缓存中读取资源,在 chrome 控制台的 network 选项中可以看到该请求返回 200 的状态码,并且size显示from disk cache或from memory cache;
协商缓存
协商缓存会先向服务器发送一个请求,服务器会根据这个请求的 request header 的一些参数来判断是否命中协商缓存,如果命中,则返回 304 状态码并带上新的 response header 通知浏览器从缓存中读取资源。
2.1 HTTP 缓存控制
在 HTTP 中,我们可以通过设置响应头以及请求头来控制缓存策略。
强缓存可以通过设置Expires和Cache-Control 两种响应头实现。如果同时存在,Cache-Control优先级高于Expires。
Expires
Expires 响应头,它是 HTTP/1.0 的产物。代表该资源的过期时间,其值为一个绝对时间。它告诉浏览器在过期时间之前可以直接从浏览器缓存中存取数据。由于是个绝对时间,客户端与服务端的时间时差或误差等因素可能造成客户端与服务端的时间不一致,将导致缓存命中的误差。如果在Cache-Control响应头设置了 max-age 或者 s-max-age 指令,那么 Expires 会被忽略。
Expires: Wed, 21 Oct 2015 07:28:00 GMT
Cache-Control
Cache-Control 出现于 HTTP/1.1。可以通过指定多个指令来实现缓存机制。主要用表示资源缓存的最大有效时间。即在该时间端内,客户端不需要向服务器发送请求。优先级高于 Expires。其过期时间指令的值是相对时间,它解决了绝对时间的带来的问题。
Cache-Control: max-age=315360000
Cache-Control 有很多属性,不同的属性代表的意义也不同。
可缓存性
public表明响应可以被任何对象(包括:发送请求的客户端,代理服务器,等等)缓存。private表明响应只能被单个用户缓存,不能作为共享缓存(即代理服务器不能缓存它)no-cache不使用强缓存,需要与服务器验协商缓存验证。no-store缓存不应存储有关客户端请求或服务器响应的任何内容,即不使用任何缓存。
过期
max-age=缓存存储的最大周期,超过这个周期被认为过期。s-maxage=设置共享缓存。会覆盖max-age和expires,私有缓存会忽略它max-stale[=客户端愿意接收一个已经过期的资源,可以设置一个可选的秒数,表示响应不能已经过时超过该给定的时间。] min-fresh=客户端希望在指定的时间内获取最新的响应
重新验证和重新加载
must-revalidate如页面过期,则去服务器进行获取。proxy-revalidate与must-revalidate作用相同,但是用于共享缓存。
其他
only-if-cached不进行网络请求,完全只使用缓存。no-transform不得对资源进行转换和转变。例如,不得对图像格式进行转换。
协商缓存可以通过 Last-Modified/If-Modified-Since和ETag/If-None-Match这两对 Header 来控制。
2.2 Last-Modified、If-Modified-Since
Last-Modified与If-Modified-Since 的值都是 GMT 格式的时间字符串,代表的是文件的最后修改时间。
- 在服务器在响应请求时,会通过
Last-Modified告诉浏览器资源的最后修改时间。 - 浏览器再次请求服务器的时候,请求头会包含
Last-Modified字段,后面跟着在缓存中获得的最后修改时间。 - 服务端收到此请求头发现有
if-Modified-Since,则与被请求资源的最后修改时间进行对比,如果一致则返回 304 和响应报文头,浏览器只需要从缓存中获取信息即可。如果已经修改,那么开始传输响应一个整体,服务器返回:200 OK

但是在服务器上经常会出现这种情况,一个资源被修改了,但其实际内容根本没发生改变,会因为Last-Modified时间匹配不上而返回了整个实体给客户端(即使客户端缓存里有个一模一样的资源)。为了解决这个问题,HTTP/1.1 推出了Etag。Etag 优先级高与Last-Modified。
2.3 Etag、If-None-Match
Etag都是服务器为每份资源生成的唯一标识,就像一个指纹,资源变化都会导致 ETag 变化,跟最后修改时间没有关系,ETag可以保证每一个资源是唯一的。
在浏览器发起请求,浏览器的请求报文头会包含 If-None-Match 字段,其值为上次返回的Etag发送给服务器,服务器接收到次报文后发现 If-None-Match 则与被请求资源的唯一标识进行对比。如果相同说明资源没有修改,则响应返 304,浏览器直接从缓存中获取数据信息。如果不同则说明资源被改动过,则响应整个资源内容,返回状态码 200。
3. CDN缓存
CDN:Content Delivery Network,即内容分发网络,它是构建在现有网络基础上的虚拟智能网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、调度及内容分发等功能模块,使用户在请求所需访问的内容时能够就近获取,以此来降低网络拥塞,提高资源对用户的响应速度。
本地存储和浏览器缓存带来的性能提升主要针对的是浏览器端已经缓存了所需的资源,当发生二次请求相同资源时便能够进行快速响应,避免重新发起请求或重新下载全部响应资源。
这些方法对于首次资源请求的性能提升是无能为力的,若想提升首次请求资源的响应速度,除了资源压缩、图片优化等方式,还可借助CDN技术。
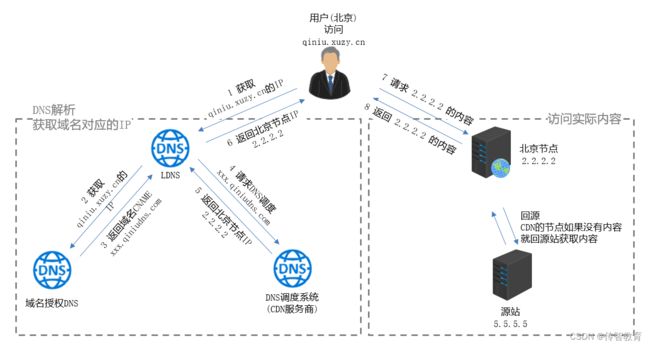
3.1 使用CDN网络资源获取过程
如果使用了CDN网络,则资源获取的大致过程是这样的。
- 由于DNS服务器将对CDN的域名解析权交给了CNAME指向的专用DNS服务器,所以对用户输入域名的解析最终是在CDN专用的DNS服务器上完成的。
- 解析出的结果IP地址并非确定的CDN缓存服务器地址,而是CDN的负载均衡器的地址。
- 浏览器会重新向该负载均衡器发起请求,经过对用户IP地址的距离、所请求资源内容的位置及各个服务器复杂状况的综合计算,返回给用户确定的缓存服务器IP地址。
- 对目标缓存服务器请求所需资源的过程。
这个过程也可能会发生所需资源未找到的情况,那么此时便会依次向其上一级缓存服务器继续请求查询,直至追溯到网站的根服务器并将资源拉取到本地。
3.2 CDN网络的核心功能包括两点:
缓存与回源
缓存指的是将所需的静态资源文件复制一份到CDN缓存服务器上;
回源指的是如果未在CDN缓存服务器上查找到目标资源,或CDN缓存服务器上的缓存资源已经过期,则重新追溯到网站根服务器获取相关资源的过程。
4. Nginx代理缓存
用户请求在达到应用服务器之前,会先访问 Nginx 负载均衡器,如果发现有缓存信息,直接返回给用户。
如果没有发现缓存信息,Nginx 回源到应用服务器获取信息。
另外,有一个缓存更新服务,定期把应用服务器中相对稳定的信息更新到 Nginx 本地缓存中。
Nginx设置缓存有两种方式:
- proxy_cache_path和proxy_cache
- Cache-Control和Pragma
对于站点中不经常修改的静态内容(如图片,JS,CSS),可以在服务器中设置expires过期时间,控制浏览器缓存,达到有效减小带宽流量,降低服务器压力的目的。
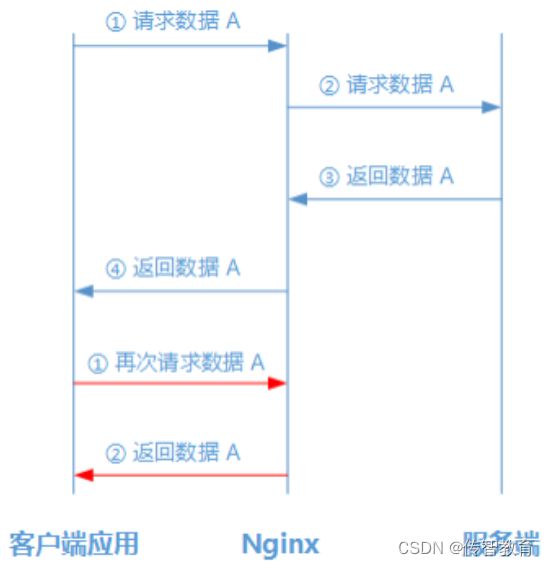
第一步:客户端第一次向Nginx请求数据A;
第二步:当Nginx发现缓存中没有数据A时,会向服务端请求数据A;
第三步:服务端接收到Nginx发来的请求,则返回数据A到Nginx,并且缓存在Nginx;
第四步:Nginx返回数据A给客户端应用;
第五步:客户端第二次向Nginx请求数据A;
第六步:当Nginx发现缓存中存在数据A时,则不会请求服务端;
第七步:Nginx把缓存中的数据A返回给客户端应用。
默认情况下,NGINX尊重Cache-Control源服务器的标头。它不缓存响应Cache-Control设置为Private,No-Cache或No-Store或Set-Cookie在响应头。NGINX只缓存GET和HEAD客户端请求。
如下配置可覆盖这些默认值:
- proxy_buffering默认为on,若proxy_buffering设置为off,则NGINX不会缓存响应。
- proxy_ignore_headers可以配置忽略Cache-Control:
location /images/ {
proxy_cache my_cache;
proxy_ignore_headers Cache-Control;
proxy_cache_valid any 30m;
# ...
}
5. 进程缓存
通过了客户端,CDN,Nginx代理缓存,我们终于来到了应用服务器。应用服务器上部署着一个个应用,这些应用以进程的方式运行着,那么在进程中的缓存是怎样的呢?
进程内缓存又叫托管堆缓存,以 Java 为例,这部分缓存放在 JVM 的托管堆上面,同时会受到托管堆回收算法的影响。
由于其运行在内存中,对数据的响应速度很快,通常我们会把热点数据放在这里。
在进程内缓存没有命中的时候,我们会去搜索进程外的缓存或者分布式缓存。这种缓存的好处是没有序列化和反序列化,是最快的缓存。缺点是缓存的空间不能太大,对垃圾回收器的性能有影响。
目前比较流行的实现有 Ehcache、GuavaCache、Caffeine。这些架构可以很方便的把一些热点数据放到进程内的缓存中。
这里我们需要关注几个缓存的回收策略,具体的实现架构的回收策略会有所不同,但大致的思路都是一致的:
- FIFO(First In First Out):先进先出算法,最先放入缓存的数据最先被移除。
- LRU(Least Recently Used):最近最少使用算法,把最久没有使用过的数据移除缓存。
- LFU(Least Frequently Used):最不常用算法,在一段时间内使用频率最小的数据被移除缓存。
在分布式架构的今天,多应用中如果采用进程内缓存会存在数据一致性的问题。
这里推荐两个方案:
-
消息队列方案
应用在修改完自身缓存数据和数据库数据之后,给消息队列发送数据变化通知,其他应用订阅了消息通知,在收到通知的时候修改缓存数据。
-
定时任务修改方案
为了避免耦合,降低复杂性,对“实时一致性”不敏感的情况下。每个应用都会启动一个定时任务,定时从数据库拉取最新的数据,更新缓存。
进程内缓存有哪些使用场景呢?
- 场景一:只读数据,可以考虑在进程启动时加载到内存。当然,把数据加载到类似 Redis 这样的进程外缓存服务也能解决这类问题。
- 场景二:高并发,可以考虑使用进程内缓存,例如:秒杀。
6. 分布式缓存
说完进程内缓存,自然就过度到进程外缓存了。
与进程内缓存不同,进程外缓存在应用运行的进程之外,它拥有更大的缓存容量,并且可以部署到不同的物理节点,通常会用分布式缓存的方式实现。
分布式缓存是与应用分离的缓存服务,最大的特点是,自身是一个独立的应用/服务,与本地应用隔离,多个应用可直接共享一个或者多个缓存应用/服务。
为了提高缓存的可用性,会在原有的缓存节点上加入 Master/Slave 的设计。当缓存数据写入 Master 节点的时候,会同时同步一份到 Slave 节点。
一旦 Master 节点失效,可以通过代理直接切换到 Slave 节点,这时 Slave 节点就变成了 Master 节点,保证缓存的正常工作。
每个缓存节点还会提供缓存过期的机制,并且会把缓存内容定期以快照的方式保存到文件上,方便缓存崩溃之后启动预热加载。
6.1 缓存雪崩
当缓存失效,缓存过期被清除,缓存更新的时候。请求是无法命中缓存的,这个时候请求会直接回源到数据库。
如果上述情况频繁发生或者同时发生的时候,就会造成大面积的请求直接到数据库,造成数据库访问瓶颈。我们称这种情况为缓存雪崩。
从如下两方面来思考解决方案:
缓存方面:
- 避免缓存同时失效,不同的 key 设置不同的超时时间。
- 增加互斥锁,对缓存的更新操作进行加锁保护,保证只有一个线程进行缓存更新。缓存一旦失效可以通过缓存快照的方式迅速重建缓存。对缓存节点增加主备机制,当主缓存失效以后切换到备用缓存继续工作。
设计方面,这里给出了几点建议供大家参考:
- 熔断机制:某个缓存节点不能工作的时候,需要通知缓存代理不要把请求路由到该节点,减少用户等待和请求时长。
- 限流机制:在接入层和代理层可以做限流,当缓存服务无法支持高并发的时候,前端可以把无法响应的请求放入到队列或者丢弃。
- 隔离机制:缓存无法提供服务或者正在预热重建的时候,把该请求放入队列中,这样该请求因为被隔离就不会被路由到其他的缓存节点。
- 如此就不会因为这个节点的问题影响到其他节点。当缓存重建以后,再从队列中取出请求依次处理。
62. 缓存穿透
缓存一般是 Key,Value 方式存在,一个 Key 对应的 Value 不存在时,请求会回源到数据库。
假如对应的 Value 一直不存在,则会频繁的请求数据库,对数据库造成访问压力。如果有人利用这个漏洞攻击,就麻烦了。
解决方法:如果一个 Key 对应的 Value 查询返回为空,我们仍然把这个空结果缓存起来,如果这个值没有变化下次查询就不会请求数据库了。
将所有可能存在的数据哈希到一个足够大的 Bitmap 中,那么不存在的数据会被这个 Bitmap 过滤器拦截掉,避免对数据库的查询压力。
6.3 缓存击穿
在数据请求的时候,某一个缓存刚好失效或者正在写入缓存,同时这个缓存数据可能会在这个时间点被超高并发请求,成为“热点”数据。
这就是缓存击穿问题,这个和缓存雪崩的区别在于,这里是针对某一个缓存,前者是针对多个缓存。
解决方案:导致问题的原因是在同一时间读/写缓存,所以只有保证同一时间只有一个线程写,写完成以后,其他的请求再使用缓存就可以了。
比较常用的做法是使用 mutex(互斥锁)。在缓存失效的时候,不是立即写入缓存,而是先设置一个 mutex(互斥锁)。当缓存被写入完成以后,再放开这个锁让请求进行访问。