大模型进展的主要观点综述
大模型模式的意义可以用两个词来概括:涌现和同质化。涌现意味着一个系统的行为是隐含诱导的,而不是明确构建的;它既是科学兴奋的源泉,也是对意外后果的一种焦虑。同质化表示在广泛的应用程序中构建机器学习系统的方法的整合;它为许多任务提供了强大的杠杆作用,但也会产生单点故障。为了更好地理解新兴和同质化,让我们回顾一下过去30年来它们在人工智能研究中的崛起。
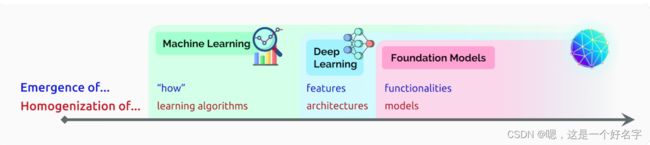
人工智能的故事一直是一个不断涌现和同质化的故事。随着机器学习的引入,任务的执行方式从示例中浮现(自动推断);通过深度学习,用于预测的高级特征出现;通过基础模型,甚至出现了上下文学习等高级功能。与此同时,机器学习使学习算法(例如,逻辑回归),深度学习使模型架构同质化(例如,卷积神经网络),并且基础模型使模型本身均匀化(例如,GPT-3)
1、在自然语言处理(NLP)任务中形成:大模型在NLP中已经形成,所以我们的故事暂时集中在那里。也就是说,就像深度学习在计算机视觉中普及但存在于计算机视觉之外一样,我们将基础模型理解为人工智能的一般范式,而不是以任何方式特定于NLP。到2018年底,NLP领域即将经历另一场地震,标志着大模型时代的开始。在技术层面上,基础模型通过迁移学习[Thrun 1998]和规模来实现。
2、迁移学习与预训练和微调:迁移学习的思想是将从一个任务中学到的“知识”(例如,图像中的对象识别)并将其应用于另一任务(例如,视频中的活动识别)。在深度学习中,预训练是迁移学习的主要方法:模型在代理任务上进行训练(通常只是作为达到目的的手段),然后通过微调适应感兴趣的下游任务。迁移学习使基础模型成为可能,但规模是使它们强大的原因。
规模化需要三个要素:
(1)计算机硬件的改进--例如,GPU吞吐量和内存在过去四年中增加了10倍;
(2)Transformer模型架构的开发[Vaswani et al. 2017],该架构利用硬件的并行性来训练比以前更具表达力的模型
(3)更多训练数据的可用性。
3、数据的可用性和利用数据能力:不能低估数据的可用性和利用数据的能力的重要性。带标注数据集的迁移学习已经成为至少十年的常见实践,例如,在ImageNet数据集上进行预训练[Deng et al. 2009],用于计算机视觉社区的图像分类。然而,标注的高成本对预训练的好处施加了实际限制。
4、自监督学习:另一方面,在自监督学习中,预训练任务是从未标注的数据中自动导出的。例如,用于训练BERT的掩蔽语言建模任务[Devlin et al. 2019]是在给定其周围上下文的情况下预测句子中缺失的单词(例如,我喜欢豆芽)。自监督任务不仅更具可扩展性,只依赖于未标记的数据,而且它们旨在迫使模型预测部分输入,使其比在更有限的标签空间上训练的模型更丰富,可能更有用。
5、自监督学习在单词嵌入方面取得了相当大的进展[Turian et al. 2010; Mikolov et al. 2013;彭宁顿et al. 2014],它将每个单词与上下文无关的向量相关联,为广泛的NLP模型提供了基础。此后不久,基于自回归语言建模的自监督学习(根据前一个单词预测下一个单词)[Dai and Le 2015]变得流行起来。这产生了在上下文中表示单词的模型,例如GPT [拉德福等人2018],埃尔莫[Peters等人2018]和ULMFiT [霍华德和Ruder 2018]。
6、自我监督学习的下一波发展- BERT [Devlin等人2019] GPT-2 [拉德福等人2019],RoBERTA [Liu等人2019],T5 [Raffel et al. 2019],BART [刘易斯et al. 2020 a] -迅速跟进,采用Transformer架构,结合更强大的句子深度双向编码器,并扩展到更大的模型和数据集。
7、虽然人们可以纯粹通过自我监督学习的透镜来看待这最后一波技术发展,但BERT的引入是一个社会学转折点。在2019年之前,使用语言模型的自监督学习基本上是NLP的一个子领域,它与NLP的其他发展并行。在2019年之后,使用语言模型的自监督学习越来越成为NLP的基础,因为使用BERT已经成为常态。接受单一模型可以用于如此广泛的任务,标志着大模型时代的开始。
8、同质化:大模型导致了前所未有的同质化:几乎所有最先进的NLP模型现在都是从几个基础模型中的一个改编而来的,如BERT,RoBERTa,BART,T5等。(基础模型的任何改进都可以为整个NLP带来直接的好处),它也是一种责任;所有人工智能系统都可能继承一些基础模型的相同问题偏差[Bolukbasi et al. 2016;卡利斯坎et al. 2017; Abid et al. 2021,阿利亚是]):公平性,伦理学以进行进一步讨论。
9、研究界的同质化:我们也开始看到研究界的同质化。例如,类似的基于变换器的序列建模方法现在应用于文本[Devlin et al. 2019;拉德福et al. 2019; Raffel et al. 2019],图像[Dosovitskiy et al. 2020; Chen et al. 2020 d]、语音[Liu et al. 2020 d]、表格数据[Yin et al. 2020]、蛋白质序列[Rives et al. 2021]、有机分子[Rothchild et al. 2021]、和强化学习[Chen et al. 2021 b; Janner et al. 2021]。这些例子指出了一个可能的未来,我们有一套统一的工具来开发各种模式的基础模型[Tamkin et al. 2021 b]。
10、多模态模型的形式同质化:除了方法的同质化之外,我们还看到研究社区之间的实际模型以多模态模型的形式同质化-例如,基于语言和视觉数据训练的基础模型[Luo et al. 2020; Kim et al. 2021 a; Cho et al. 2021; Ramesh et al. 2021;拉德福et al. 2021]。数据在某些领域自然是多模态的,例如,医疗图像、结构化数据、医疗保健中的临床文本。因此,多模态基础模型是融合关于一个领域的所有相关信息的自然方式,并适应也跨越多个模式的任务。基础模型的模式也导致了规模的惊人的出现。例如,GPT-3 [Brown et al. 2020],与GPT-2的15亿个参数相比,有1750亿个参数,允许上下文学习,其中语言模型可以通过简单地向下游任务提供提示(任务的自然语言描述)来适应下游任务,这是一种既没有专门训练也没有预期出现的新兴属性。
11、同质化和涌现:以一种潜在的令人不安的方式相互作用。同质化可以潜在地为任务特定数据非常有限的许多领域提供巨大的收益-参见在几个这样的领域中呈现的机会(例如,医疗保健,法律,教育);另一方面,模型中的任何缺陷都会被所有适应模型盲目地继承(公平,道德)。由于基础模型的力量来自于它们的涌现特性,而不是它们明确的构造,现有的基础模型很难理解(评估,理论,可解释性),并且它们有意想不到的失败模式(安全性,鲁棒性)。由于新兴市场在基础模型的能力和缺陷方面产生了很大的不确定性,因此通过这些模型进行积极的同质化是有风险的。从伦理和人工智能安全的角度来看,消除风险是基础模型进一步发展的核心挑战。