Intel oneAPI笔记(2)--jupyter官方文档(oneAPI_Intro)学习笔记
前言
本文是对jupyterlab中oneAPI_Essentials/01_oneAPI_Intro文档的学习记录,包含对SYCL、DPC++ extends SYCL、oneAPI Programming models等介绍和SYCL代码的初步演示等内容
oneAPI编程模型综述
oneAPI编程模型提供了一个全面而统一的开发人员工具组合,可以跨硬件目标使用,包括一系列跨越多个工作负载域的性能库,这些库包括针对每个目标体系结构定制编码的函数,因此相同的函数调用可以在支持的体系结构中提供优化性能
多体系结构编程挑战
目前,在以数据为中心的领域,专用工作负载正在增长。每种以数据为中心的硬件通常需要使用不同的语言和库进行编程,因为没有通用的编程语言或 API,这需要维护单独的代码库。开发人员必须学习一整套不同的工具,因为跨平台的工具支持不一致。为每个硬件平台开发软件需要单独的投资,并且几乎无法重用该工作以针对不同的体系结构。
oneAPI的引入
oneAPI作为一种统一编程模型,包括表达并行性的统一和简化的语言和库,它有着很好的开放性,可以与现有的HPC编程模型相互操作
一个简单的例子
%%writefile lab/simple.cpp
//==============================================================
// Copyright © Intel Corporation
//
// SPDX-License-Identifier: MIT
// =============================================================
#include
using namespace sycl;
static const int N = 16;
int main(){
//# define queue which has default device associated for offload
queue q;
std::cout << "Device: " << q.get_device().get_info() << "\n";
//# Unified Shared Memory Allocation enables data access on host and device
int *data = malloc_shared(N, q);
//# Initialization
for(int i=0; i(N), [=] (id<1> i){
data[i] *= 2;
}).wait();
//# Print Output
for(int i=0; i 这是一个简单的SYCL编程例子,第一行%%writefile lab/simple.cpp的作用是,当将这个代码在jupyter lab中的一个cell中点运行时,将会把除了这一行的代码之外的所有代码保存在jupyterlab的/lab(相对路径)的位置的simple.cpp文件当中
也就是说,运行这个之后只会把代码保存在一个文件中:
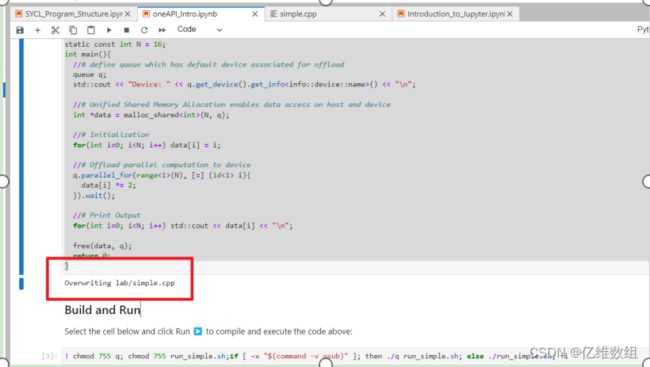

之后,在下一个cell中运行这段代码,才是对上面的代码的真正运行:
! chmod 755 q; chmod 755 run_simple.sh;if [ -x "$(command -v qsub)" ]; then ./q run_simple.sh; else ./run_simple.sh; fi
运行结果

SYCL
sycl代表了一项行业标准化工作,包括对c++数据并行编程的支持,被概括为“面向opencl的c++单源异构编程”。sycl是一个基于opencl的跨平台的抽象层,它使异构处理器的代码能够使用c++以“单一源”风格编写,使编译器能够分析和优化整个程序,而不管代码要在哪个设备上运行
与opencl不同,sycl包含模板和lambda函数,使高级应用程序软件能够清晰地编码,并优化内核代码的加速。
数据并行c++(dpc++)是一个api实现的sycl编译器。利用了现代c++的生产力优势和熟悉的结构,并结合了数据并行性和异构编程的sycl标准
sycl是一种单源语言,其中主机代码和异构加速器内核可以混合在同一源文件中。程序员可以使用熟悉的c++和代用附加功能的库结构,如用于工作定位的队列,用于数据管理的缓冲区,以及用于并行性的parallel_for来指示应该卸载哪部分的计算和数据
oneAPI编程模型
·平台模型
oneAPI的平台模型基于SYCL平台模型,指定一个主机控制一个或多个设备。主机是计算机,通常是基于cpu的系统,执行程序主要部分
每个设备是一个加速器,一个包含计算资源的专用组件,它可以快速执行操作的子集,通常比cpu更快。每个设备包含一个或多个计算单元,每个计算单元包含一个或处理单元,处理单元是单独的计算引擎

·执行模型
执行模型基于SYCL执行模型,它定义并指定代码(称为内核)如何在设备上执行并于控制主机交互,主机执行模型通过命令组在主机和设备之间协调执行和数据管理。命令组是像内核调用和访问器这样的命令的分组,被提交到队列中执行
执行模型指定了如何在访问器上完成计算,从小的一维数据到大的多维数据集的计算分布在nd范围、工作组、子组的层次结构中,都是在工作提交到命令队列时指定的
需要注意的是,实际的内核代码代表一个工作项执行的工作,内核之外的代码控制的是执行多少并行性,工作的数量和分配时由nd范围和工作组的规格来控制
下图描述nd范围、工作组、子组和工作项之间的关系,总工作量是由工作组大小指定,该实例显示了x*y*z的nd范围大小,x’*y’*z’的工作组大小和x’的子组大小。因此有(x*y*z)/(x’*y’*z’)大小的工作组和(x*y*z)/x’大小的子组

·存储模型
基于SYCl*内存模式,它定义了主机和设备如何与内存交互,它协调主机和设备之间的内存分配和管理。内存模型是一种抽象,其目的是概括和适应不同的主机和设备配置。
在这个模型中,内存驻留在主机或设备上,由主机或设备拥有,并通过声明一个内存对象来指定。有两种不同类型的内存对象,缓冲器和镜像。这些内存对象再主机和设备之间的交互通过访问器(accessor)完成,访问器传达了期望的访问设置,例如主机和设备,以及特定的访问模式,例如读和写
考虑这样一种情况,内存通过传统的malloc调用在主机上分配,一旦在主机上分配了内存,就会创建一个缓冲区对象,它使主机分配的内存能够和设备通信,缓冲区类将该类型的项的类型和数量通信给设备进行计算,一旦主机上创建了缓冲区,设备上运行的访问类型就通过访问器accessor对象进行通信。

内核编程模型
支持主机和设备之间的显示并行性,这种并行性之所以显式,是因为程序员决定哪些代码在主机和设备上执行,它不是自动的,内核代码在加速器上执行。
采用oneAPI编程模型的程序支持单一源,这意味着主机代码和设备代码可以在同一个源文件中,但是,在语言一致性和语言特性方面,主机代码和设备代码中接受的源代码存在差异