Elasticsearch集群及kafka集群原理图解
ES集群单个文档写入流程
1,客户端发起向es集群的9200发起写单个文档的请求
如果请求发送到非主节点,则请求会转发至主节点
主节点会根据写文档的id进行计算,判断要将写文档请求转发至哪个主分片
路由判断标准:
1)如果带id,则根据id的hash值mod集群分片数,取余后得到要发往哪个分片
2)如果不带id,则master会给文档生成一个随机值作为id,并对其进行hash计算后,再mod集群分片数,取余后得到要发往哪个分片
2,假如这里文档经计算需要写入主分片P2,主节点将请求发往节点03的P2,然后主分片02写入文档数据
3,文档写入后,主分片会将文档同步到副本R2,副本R2写入成功后,会通知P2写入成功
4,P2告知主节点数据写入成功
5,主节点通知数据节点数据节点文档写入成功,如果请求是直接发往主节点则无需通知
6,es通过9200告知客户端文档数据写入成功
ES集群单个文档的读流程

1,客户端发起向es集群的9200发起写单个文档的读请求
2,es集群节点收到请求后进行路由判断,计算文档属于哪个分片,计算出后到相应的分片进行读取
3,文档读取后相应请求
4,返回文档数据给客户端
ES集群全量稳定的读流程
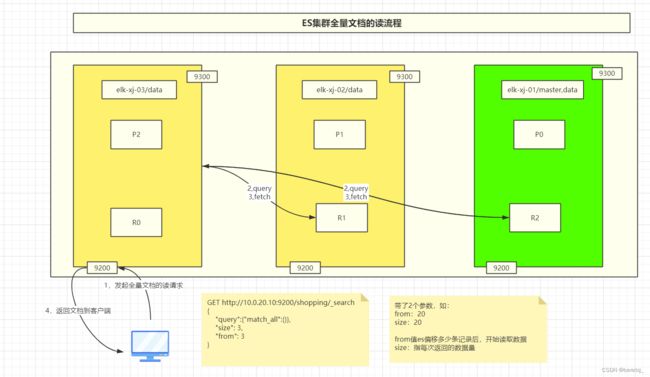
1,客户端发起向es集群的9200发起全量文档读请求
比如集群带了参数from:20 表示从偏移多少条记录后开始读取数据
参数size20:表此每次返回的数据条数
2,节点收到请求后,从本节点及其它节点的分片副本上请求文档数据
3,查询到数据后拉取数据
4,根据from,size参数,从偏移量20开始读取,并每次返回20条记录到客户端
kafka cluster基本原理图解1

Topic:testxj
Partition:testxj这个topic有3个分区
replica:kafka集群的replica是以topic作为逻辑整体为一份副本,所以本例有2个副本
leader:负责testxj分区的读写和与消费者的交互
follower:负责与leader之间进行数据同步,但不与客户端交互
生产者:将数据写入kafka集群的leader分区
消费者:从kafka集群中的leader分区拉取数据
消费者组:也从kafka集群中拉取数据,但组内的消费组不会同时消费同一个分区,避免重复消费
当topic分区改变or消费者组内消费者数量改变时,会触发重分配rebalance,即重新分配消费者与主题分区的对应关系
消费者读取消息的偏移量offset:早期存在zk集群中,后期存在kafka集群的__comsumer_offsets这个topic中
kafka cluster基本原理图解2

kafka集群采取所有副本写入数据
选取leader的时候,如果容忍N个分片(节点)的故障,需要N+1个分片(节点)
但采用此方式延迟较高,所以存在一定概率的小数据量的丢失
ISR机制(In-Sync replica Set)-->针对的是分区
ISR是一个所有follower和leader数据保持一致的机制,leader通过维护ISR列表来得知当前哪些follower的数据和自身保持一致
例1,数据写入了101,102,103所有副本
testxj01-->leader 103-->ISR [101,102,103]
例2,数据写入了101,102的副本
testxj01-->leader 103-->ISR [101,102]
如果follower长时间未向leader同步数据,则会从ISR列表中被删除,默认时长为30秒
如果leader发生故障之后,会从ISR列表中选出新的leader
kafka cluster的ISR机制图解


HW: high water高水位线,等于ISR列表中LEO最小的副本的值
LEO:log end offset日志末尾偏移量,即每个副本写的最新的一条数据的偏移量
数据此时是从101向102,103同步,102同步的快一些,103同步的慢一些
如果此时101出现故障,且30秒未恢复,则101将从集群ISR列表中去除,然后从102,103中选出LEO最大的副本作为leader,然后其他副本改为从新的leader中同步数据
此时,由于101分片写到了I,但其他副本最大只写到了F,所以数据G,H,I将丢失
所以使用kafka,不能用作金额,订单等数据的处理(或者程序本身有机制可以补数据),一般用作大数据分析,个别数据丢失不影响分析结果
选取新leader后的结果如图2
此时102是作为leader,103从102同步数据
如果此时101恢复后从新加入集群,将作为follower从102同步数据,同步是从F开始,ISR列表从新变为101,102,103
zookeerper集群leader选举流程

zookeeper的leader选举流程:
1,服务器依次启动以后,elk-xj-01首先进入looking状态,检查集群是否有leader,如果没有,则投自己一票,然后广播
2,elk-xj-02启动后,也进入looking状态,也会投自己一票,然后广播
3,elk-xj-01和elk-xj-02收到彼此的投票后,会用myid进行比较,谁的myid更大,则谁为leader,所以此时elk-xj-01发现elk-xj-02的myid比自身大,会修改投票,改选elk-xj-02为leader
因为集群主机列表会配置在zk的配置文件中,此时elk-xj-02会发现自己已经获得过半投票
所以,此时elk-xj-02改自己状态为leading,elk-xj-01改自己状态为following
4,elk-xj-03进入集群后,也是先进入looking状态,检查发现集群已经选出了leader,所以修改自身状态为following
这里zookeeper的节点为奇数,因为zookeeper默认采用了Quorums这种方式,即只有集群中超过半数节点投票才能选举出Leader。这样的方式可以确保leader的唯一性,要么选出唯一的leader,要么选举失败,从而防止脑裂和假死,当leader挂掉之后,可以重新选举出新的leader节点使整个集群达成一致;当出现假死现象时,通过epoch大小来拒绝旧的leader发起的请求,这个时候,重新恢复通信的老的leader节点会进入恢复模式,与新的leader节点做数据同步。
假死:由于网络原因导致的心跳超时,或者网络暂时断联,zk集群认为leader死了,但其实leader还存活着。
脑裂:由于假死会发起新的leader选举,选举出一个新的leader,但此时旧的leader网络又恢复了,导致出现了两个leader 。