elasticsearch原理及使用
目录
1 简介
1.1 Elasticsearch是什么
1.2 Elasticsearch 的用途是什么
1.3 对比同类中间件
1.3.1 ElasticSearch VS Lucene
1.3.2 ElasticSearch VS Solr
1.3.3 Elasticsearch VS Mysql
2 基本概念和原理
2.1 全文检索
2.1.1 结构化和非结构化数据
2.1.2 全文检索定义
2.1.3 性能问题
2.2 倒排索引
2.2.1 原理
2.2.2 倒排索引构成
2.3 Elasticsearch核心概念
2.3.1 物理设计
2.3.2 逻辑设计
2.3.3 准实时原理
2.3.4 文档写入流程
2.3.5 文档读取流程
2.3.6 锁机制
3 部署说明
Elasticsearch集群安装_风间净琉璃的博客-CSDN博客
4 数据管理
4.1 数据基本操作
4.1.1 索引管理
4.1.2 集群状态相关
4.1.3 Elasticsearch_exporter 监控指标
4.1.4 文档管理
4.2 DSL
4.2.1 记录查询
4.2.2 结果聚合查询(aggs)
4.3 批量操作
Bulk批量操作
批量查询
4.4 分页查询
4.4.1 from+size浅分页
4.4.2 scroll 深分页
4.4.3 search_after 深分页
5 分词器
5.1 简介
5.2 分词器构成
5.2.1 character filter 字符过滤器
5.2.2 tokenizers 分词器
5.2.3 Token filters Token过滤器
5.2.4 关联关系
5.3 写时分词
5.3.1 实验中文分词器
5.4 读时分词
5.5 常用内置分词器介绍
5.5.1 standard analyzer
5.5.2 simple analyzer
5.5.3 whitespace analyzer
5.5.4 stop analyzer
5.5.5 language analyzer
5.5.6 pattern analyzer
5.6 第三方插件分词器
5.6.1 ik_max_word
5.6.2 ik_smart
5.6.3 最佳实践
6 Java接入Elasticsearch-api
6.1 使用步骤
6.2 Elasticsearch客户端
6.2.1 TransportClient
6.2.2 Rest ClientJava REST客户端
6.3 Java High Level REST Client 代码示例
6.3.1 创建客户端连接
6.3.2 索引操作
6.3.3 文档操作
7 性能压测
7.1 esrally doker安装压测
7.1.1 局限性
7.1.2 快速开始
8 使用调优
9 源码分析
9.1 Elasticsearch组件图
Gateway
DistributedLucene Directory
River
Mapping
Search Moudle
Index Moudle
Disvcovery
Scripting
Transport
RESTful Style API
3rd plugins
Java(Netty)
JMX
9.2 Disvcovery源码走读
9.2.3 实现方式
9.2.4 选举Master
9.2.5 流程图
10 中间件监控
10.1 方案1:用Elasticsearch_exporter + Prometheus + Grafana进行监控
10.2 方案2:用metricbeat+elasticsearch+kibana进行监控
10.3 总结
11 轻量型数据采集器Beats
11.1 Beats定义
11.2 常用Beats
11.3 logstash
11.3.1 集中、转换和存储你的数据
12 常用方案说明
12.1 ELK(Elasticsearch+Logstash+Kibana)
12.2 Elasticsearch结合Nebula Graph使用
原因
关键步骤
12.3 Elasticsearch结合Mysql使用
12.4 Elasticsearch结合Hbase使用
12.5 Elasticsearch在TAUC中业务日志使用
12.5.1 如何标记hot-cold节点?
12.5.2 如何实现某索引数据写到指定的node?(根据节点tag即可)
12.5.3 如何实现数据从hot节点迁移到老的cold节点?
12.5.4 凌晨冷热数据批跑
1 简介
1.1 Elasticsearch是什么
Elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件;Elastic Stack 是一套适用于数据采集、扩充、存储、分析和可视化的免费开源工具。人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
1.2 Elasticsearch 的用途是什么
Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
1.3 对比同类中间件
1.3.1 ElasticSearch VS Lucene
Lucene可以被认为迄今为止最先进、性能最好的、功能最全的搜索引擎库(框架)。但是想要使用Lucene,必须使用Java来作为开发语言并将其直接集成到你的应用,并且Lucene的配置及使用非常复杂,你需要深入了解检索的相关只是来理解它是如何工作的。Elasticsearch 在 Apache Lucene 的基础上开发而成.
Lucene缺点
- 只能在Java项目中使用,并且要以jar包的方式直接集成项目中。
- 使用非常复杂——创建索引和搜索索引代码繁杂。
- 不支持集群环境-索引数据不同步(不支持大型项目)
- 索引数据如果太多就不行,索引库和应用所在同一服务器,共同占用硬盘,共用空间少。
但ES能解决上述所有的Lucene问题
1.3.2 ElasticSearch VS Solr
Solr(读作“solar”)是Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。
查询耗时比较
当单纯的对已有数据进行搜索时,Solr更快。
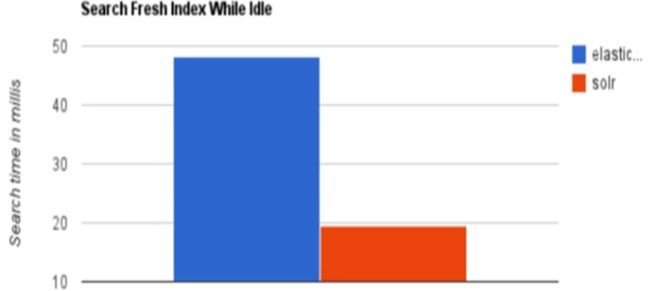
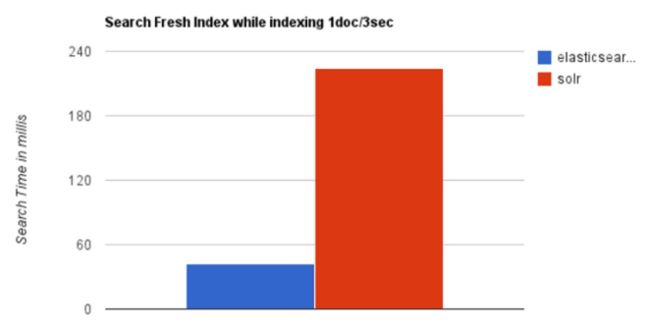
实时建立索引 Elasticsearch具有明显的优势。
不同点
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
1.3.3 Elasticsearch VS Mysql
全文检索支持度
全文检索场景
比如有古诗词如:床前明月光,疑似地上霜。
用户输入“床前明月光”、“床前明月”、“明月光”,期望都能得到“床前明月光,疑似地上霜”这句诗。
mysql常规方案
表结构
CREATE TABLE `poem` ( `id` int(11) NOT NULL, `sentence` varchar(45) DEFAULT NULL, PRIMARY KEY (`id`), FULLTEXT KEY `idx_poem_sentence` (`sentence`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 insert into poem(id,sentence) value(1,"床前明月光,疑是地上霜。"); |
数据准备

like模糊查询结果
| 查询语句 | 查询结果 | 能否得到用户期望输出 |
|---|---|---|
| select * from poem where sentence like "床前明月光%"; |
|
能 |
| select * from poem where sentence like "床前明月%"; |
|
能 |
| select * from poem where sentence like "明月光%"; |
|
否 |



全文索引检索查询结果
| 查询语句 | 查询结果 | 能否得到用户期望输出 |
|---|---|---|
| select * from poem where match (sentence) against ('床前明月光'); | 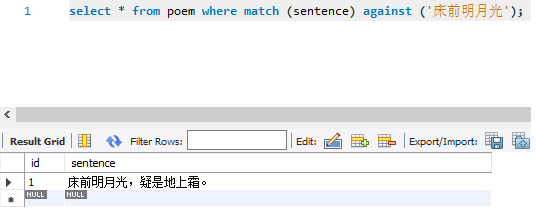 |
能 |
| select * from poem where match (sentence) against ("床前明月"); |  |
否 |
| select * from poem where match (sentence) against ("明月光"); | 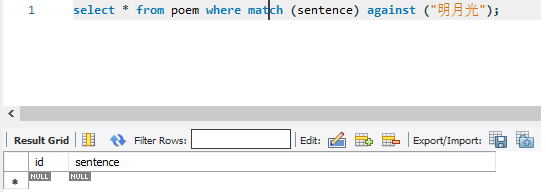 |
否 |
Elasticsearch方案
索引结构及数据准备
## 索引结构
PUT poem
{
"mappings": {
"poem_sentence": {
"properties": {
"sentence": {
"type": "text",
"analyzer": "ik_max_word"
},
"id": {
"type": "long"
}
}
}
}
}
## 插入数据
PUT /poem/_doc/1
{
"id":1,
"sentence":"床前明月光,疑似地上霜。"
} |
查询结果
| 查询语句 | 结果展示 | 能否得到用户期望输出 | |
|---|---|---|---|
|
|
能 | |
|
|
能 | |
|
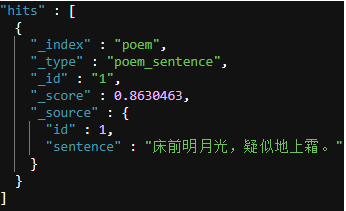 |
能 |


总结
由此可见,对于全文检索支持程度,Elasticsearch优于mysql。
大数据量场景
构造一千万数据对比Mysql与Elasticsearch的新增和查询对比。
2 基本概念和原理
2.1 全文检索
2.1.1 结构化和非结构化数据
结构化数据
结构化数据将数据具有的特征事先以结构化的形式定义好,数据有固定的格式或有限的长度。典型的结构化数据就是传统关系型数据库的表结构,数据特征直接体现在表结构的字段上,所以根据某一特征做数据检索很直接,速度也比较快。
非结构化数据
非结构化数据没有预先定义好的结构化特征,也没有固定格式和固定长度。典型的非结构化数据包括文章、图片、视频、网页、邮件等,其中像HTML网页这种具有一定格式的文档也称为半结构化数据
2.1.2 全文检索定义
对于非结构化的数据检索,被成为全文检索。
例如,假设Mysql有张诗词Poem表,含有四个字段:主键id,诗词名title,作者author和内容content。
| 字段名 | 含义 | 类型 |
|---|---|---|
| id | 主键id | bigint(20) |
| title | 诗词名 | varchar(255) |
| author | 作者 | varchar(60) |
| content | 内容 | text |
对于Poem表来说,整体上是结构化的,比如title、author都可以直接建立索引快速检索。
但content字段是text类型,存储的是非结构化的文本数据。
墙角数枝梅,凌寒独自开。遥知不是雪,为有暗香来。 |
输入"凌寒独自开"去查询这首诗的检索就叫全文检索。
2.1.3 性能问题
与结构化查询相比,全文检索面临的最大问题就是性能问题。全文检索最一般的应用场景是根据一些关键字查找包含这些关键字的文档,比如互联网搜索引擎要实现的功能就是根据一些关键字查找网页。显然,如果没有对文档做特别处理,查找的办法似乎只能是逐条比对。
select * from poem where content like '%凌寒独自开%' |
like语句是无法建立索引的,查询时会进行全表扫描,并且在每个content字段中进行遍历匹配,以找到含有“凌寒独自开”这个关键字的记录,整体复杂度特别高,所以全文检索也是MySQL这类结构关系式数据库无法很好实现的需求。
当然mysql中全文索引支持度也不是很好,除非数据存储前,先进行切词处理,后存储,才能解决全文检索性能问题(但这种方案会对存入原始数据做处理,比较麻烦)。
2.2 倒排索引
全文检索一般是查询包含某一或某些关键字记录,所以通过文档整体值建立的索引对提高查询速度是没有任何帮助的。为了解决这个问题,人们创建了一种新索引方法,这种索引方法就是倒排索引。
2.2.1 原理
正排索引是文档ID到文档内容、单词的关联关系,而倒排索引是单词到文档ID的关联关系。
构建索引过程
例如,现在有文档分别是: hello world, hello elasticsearch,what is elasticsearch,会先经历分词,去重,排序三个阶段生成倒排索引。
分词
文档hello world被分成hello,world两个词term,对应(索引编号,关键词term,文档位置),如(1,hello,1),(2,world,1)。
文档hello elasticsearch被分成hello,elasticsearch两个词term,对应(索引编号,关键词term,文档位置),如(3,hello,2),(4,elasticsearch,2)。
文档what is elasticsearch被分成what,is,elasticsearch三个词term,对应(索引编号,关键词term,文档位置),如(5,what,3),(6,is,3),(7,elasticsearch,3)。
去重
对分词后的结果按照word关键字进行去重,去重会减少索引的数量
排序
对去重后的结果按照word关键字进行排序,排序以便于后续的查询

2.2.2 倒排索引构成
倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
基本概念
文档(Document)
一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。再比如一封邮件,一条短信,一条微博也可以称之为文档。在本书后续内容,很多情况下会使用文档来表征文本信息。
文档集合(Document Collection)
由若干文档构成的集合称之为文档集合。比如海量的互联网网页或者说大量的电子邮件都是文档集合的具体例子。
文档编号(Document ID)
在搜索引擎内部,会将文档集合内每个文档赋予一个唯一的内部编号,以此编号来作为这个文档的唯一标识,这样方便内部处理,每个文档的内部编号即称之为“文档编号”,后文有时会用DocID来便捷地代表文档编号。
单词编号(Word ID)
与文档编号类似,搜索引擎内部以唯一的编号来表征某个单词,单词编号可以作为某个单词的唯一表征。
索引成分
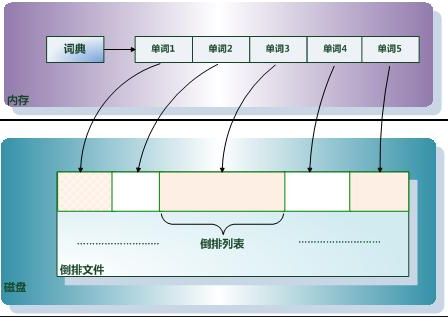
倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
单词词典(Lexicon)
搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList)
倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File)
所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
2.3 Elasticsearch核心概念
Elasticsearch中的概念,按照是否能物理上看见的分为物理设计和逻辑设计。
2.3.1 物理设计
Elasticsearch将每个索引划分为分片,每份分片可以在集群中的不同服务器间迁移。物理设计的配置方式决定了集群的性能、可扩展性和可用性。
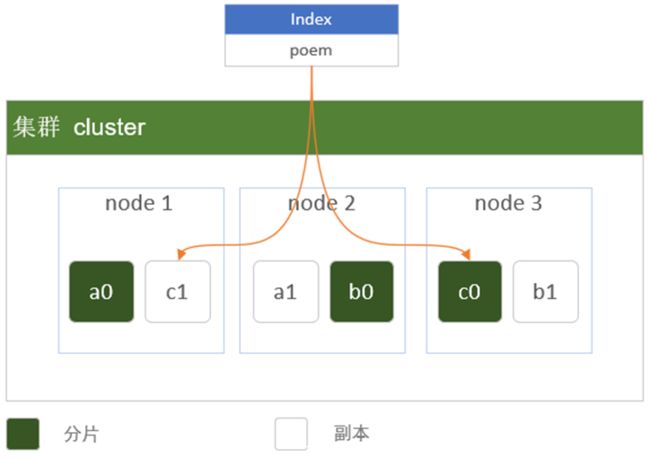
cluster 集群
集群里面包含多个节点,每个属于那个集群都是通过一个配置(集群名称,默认是elasticSearch)来决定的,对于中小型企业来说,刚开始一个集群就一个节点很正常。
Node 节点
集群里面的一个节点,节点也有一个名称,默认是随机分配的,节点名称很重要(在运维管理操作的时候),每个节点默认会去加入一个名叫 elasticsearch 的集群, 如果直接启动一堆节点,那么他们会自动组成一个名为 elasticsearch 的集群, 当然一个节点也可以组成一个 elasticsearch 集群,只不过状态是yellow(警告),正常的状态应该是green(正常。
shards分片
分片是 Elasticsearch 在集群中分发数据的关键。
把分片想象成数据的容器。文档存储在分片中,然后分片分配到集群中的节点上。当集群扩容或缩小,Elasticsearch 将会自动在节点间迁移分片,以使集群保持平衡。
一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。
这类似于 MySql 的分库分表,只不过 Mysql 分库分表需要借助第三方组件而 ES 内部自身实现了此功能。
实列场景: 假设 IndexA 有2个分片,我们向 IndexA 中插入10条数据 (10个文档),那么这10条数据会尽可能平均的分为5条存储在第一个分片,剩下的5条会存储在另一个分片中。 |
分片可以是主分片(primary shard)或者是复制分片(replica shard)。
在集群中唯一一个空节点上创建一个叫做 poem 的索引。默认情况下,一个索引被分配 5 个主分片,下面只分配 3 个主分片和一个复制分片(每个主分片都有一个复制分片):
curl -H "Content-Type: application/json" -XPUT localhost:9200/poem -d '
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}' |
primary shard 主分片
在一个多分片的索引中写入数据时,通过路由来确定具体写入哪一个分片中,大致路由过程如下:
shard = hash(routing) % number_of_primary_shards |
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数 。这个在 0 到 number_of_primary_shards 之间的余数,就是所寻求的文档所在分片的位置。
注意: 1.创建索引需要确定好主分片的数量,并永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。 2.索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据(实际的数量取决于数据、硬件和应用场景)。 |
replica shard 副本
复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的 shard 取回文档。
每个主分片都有一个或多个副本分片,当主分片异常时,副本可以提供数据的查询等操作。主分片和对应的副本分片是不会在同一个节点上的,所以副本分片数的最大值是 n -1(其中 n 为节点数)。
当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整,根据需求扩大或者缩小规模。如把复制分片的数量从原来的 1 增加到 2 :
curl -H "Content-Type: application/json" -XPUT localhost:9200/poem/_settings -d '
{
"number_of_replicas": 2
}' |
分片本身就是一个完整的搜索引擎,它可以使用单一节点的所有资源。主分片或者复制分片都可以处理读请求——搜索或文档检索,所以数据的冗余越多,能处理的搜索吞吐量就越大。
对文档的新建、索引和删除请求都是写操作,必须在主分片上面完成之后才能被复制到相关的副本分片,ES 为了提高写入的能力这个过程是并发写的,同时为了解决并发写的过程中数据冲突的问题,ES 通过乐观锁的方式控制,每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。一旦所有的副本分片都报告写成功才会向协调节点报告成功,协调节点向客户端报告成功。
分片个数
分片个数是越多越好,还是越少越好了?根据整个索引的数据量来判断。
实列场景: 如果 IndexA 所有数据文件大小是300G,改怎么定制方案了?(可以通过Head插件来查看) |
建议:(仅参考) 1、每一个分片数据文件小于30GB 2、每一个索引中的一个分片对应一个节点 3、节点数大于等于分片数 |
根据建议,至少需要 10 个分片。
结果: 建10个节点 (Node),Mapping 指定分片数为 10,满足每一个节点一个分片,每一个分片数据带下在30G左右。
SN(分片数) = IS(索引大小) / 30
NN(节点数) = SN(分片数) + MNN(主节点数[无数据]) + NNN(负载节点数)
分片个数建议
分配分片时主要考虑的你的数据集的增长趋势。
我们也经常会看到一些不必要的过度分片场景. 从ES社区用户对这个热门主题(分片配置)的分享数据来看, 用户可能认为过度分配是个绝对安全的策略(这里讲的过度分配是指对特定数据集, 为每个索引分配了超出当前数据量(文档数)所需要的分片数)。
要知道, 你分配的每个分片都是有额外的成本的:
1.每个分片本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源。 2.每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降。 3.ES使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差。 |
如果你真的担心数据的快速增长, 我们建议你多关心这条限制: ElasticSearch推荐的最大JVM堆空间是30~32G, 所以把你的分片最大容量限制为30GB, 然后再对分片数量做合理估算. 例如, 你认为你的数据能达到200GB, 我们推荐你最多分配7到8个分片。
总之, 不要现在就为你可能在三年后才能达到的10TB数据做过多分配. 如果真到那一天, 你也会很早感知到性能变化的。
尽管本部分并未详细讨论副本分片, 但我们推荐你保持适度的副本数并随时可做相应的增加. 如果你正在部署一个新的环境, 也许你可以参考我们的基于副本的集群的设计.这个集群有三个节点组成, 每个分片只分配了副本. 不过随着需求变化, 你可以轻易的调整副本数量。
分片查询
我们可以指定es去具体的分片查询从而进一步的实现es极速查询。
randomizeacross shards
随机选择分片查询数据,es的默认方式
_local
优先在本地节点上的分片查询数据然后再去其他节点上的分片查询,本地节点没有IO问题但有可能造成负载不均问题。数据量是完整的。
_primary
只在主分片中查询不去副本查,一般数据完整。
_primary_first
优先在主分片中查,如果主分片挂了则去副本查,一般数据完整。
_only_node
只在指定id的节点中的分片中查询,数据可能不完整。
_prefer_node
优先在指定你给节点中查询,一般数据完整。
_shards
在指定分片中查询,数据可能不完整。
_only_nodes
可以自定义去指定的多个节点查询,es不提供此方式需要改源码。
/**
* 指定分片 查询
*/
@Test
public void testPreference()
{
SearchResponse searchResponse = transportClient.prepareSearch(index)
.setTypes("add")
//.setPreference("_local")
//.setPreference("_primary")
//.setPreference("_primary_first")
//.setPreference("_only_node:ZYYWXGZCSkSL7QD0bDVxYA")
//.setPreference("_prefer_node:ZYYWXGZCSkSL7QD0bDVxYA")
.setPreference("_shards:0,1,2")
.setQuery(QueryBuilders.matchAllQuery()).setExplain(true).get();
SearchHits hits = searchResponse.getHits();
System.out.println(hits.getTotalHits());
SearchHit[] hits2 = hits.getHits();
for(SearchHit h : hits2)
{
System.out.println(h.getSourceAsString());
}
} |
主分片不均引起的问题
Elasticsearch在并发查询量大的情况下,访问流量超过了集群中单个Elasticsearch实例的处理能力,Elasticsearch服务端会触发保护性的机制,拒绝执行新的访问,并且抛出EsRejectedExecutionException异常,通过观察ES集群发现了下面的几个问题:
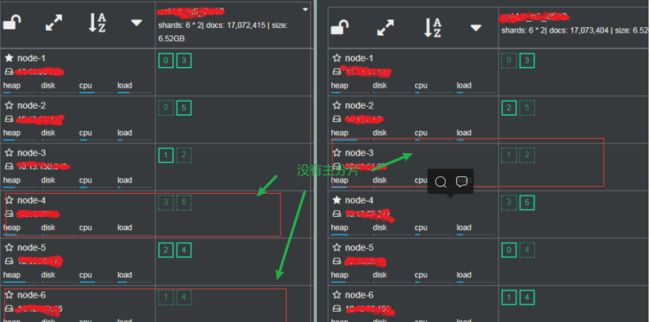
1)primary shard主副分片分布不均:图中有三个节点都没有主分片,cpu占用极低
2)master node既是master node又是data node:master node既要做数据检索,也要做集群的负载均衡转发器,导致每个集群的master node的CPU都很高,因此每次告警首先都是master node。
解决方案
| 方案名称 | 操作步骤 | 优点 | 缺点 | |
|---|---|---|---|---|
| 手动移动分片(分片和副本无法移动到同一个节点) |
|
操作简单,恢复时间短;不必修改master node的配置,master node长期负载后高 | 索引大,移动时有很高的IO,索引容易损坏,需要做备份,不能解决master node既是数据节点又是负载均衡转发器的问题 | |
| reindex新索引 | 1、重新建立索引 2、reindex原有索引到新索引 3、为新索引建立旧索引的别名 3、删除旧索引 |
可以重新配置master node和data node,主从负载均衡 | 费时间,容易数据丢失,需要验证数据一致性 |
2.3.2 逻辑设计
用于索引和搜索的基本单位是文档,可以将其认为是关系数据库里面的一行。文档以类型来分组,类型包含若干个文档,类似表格包含若干行。一个或多个类型存在于同一个索引中,索引是更大的容器,类似myslq中的数据库概念。

索引 index
索引是映射类型的容器,它非常像关系型数据库,是独立的大量文档集合。一个索引就是一个拥有几分相似特征的文档的集合。如下就是新增一个索引:
PUT poem
{
"mappings": {
"poem_sentence": {
"properties": {
"sentence": {
"type": "text",
"analyzer": "ik_max_word"
},
"id": {
"type": "long"
}
}
}
}
} |
映射 Mapping
定义一个文档mapping处理数据的方式和规则方面的限制(Schema),如某个字段的数据类型、默认值、分词器、是否被索引等等,这些都是映射里面可以设置的。
类型 Type
Type比喻成一张表,把index比喻成数据库.ES7以后将会完全抛弃type。
文档 document
一个文档是一个可被索引的基础信息单元,类似一条记录。文档以JSON(Javascript Object Notation)格式来表示。如下就是新增一个文档:
{
"took" : 47,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.8630463,
"hits" : [
{
"_index" : "poem",
"_type" : "poem_sentence",
"_id" : "1",
"_score" : 0.8630463,
"_source" : {
"id" : 1,
"sentence" : "床前明月光,疑似地上霜。"
}
}
]
}
}
|
字段 field
相当于是数据表的字段|列。
字段类型 field type
每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等。
2.3.3 准实时原理
elasticsearch 被称为准实时搜索,原因是对 Elasticsearch 的写入操作成功后,写入的数据需要1秒钟后才能被搜索到,因此 Elasticsearch 搜索是准实时或者又称为近实时(near real time)。
elasticsearch底层使用的 Lucene,而 Lucene 的写入是实时的。但 Lucene 的实时写入意味着每一次写入请求都直接将数据写入硬盘,因此频繁的I/O操作会导致很大的性能问题。
原理讲解
下图是ES写操作流程,当一个写请求发送到ES后,Elasticsearch将数据写入 memory buffer 中,并添加事务日志(translog)。如果每次一条数据写入内存后立即写到硬盘文件上,由于写入的数据肯定是离散的,因此写入硬盘的操作也就是随机写入了。硬盘随机写入的效率相当低,会严重降低ES的性能。
因此ES在设计时在 memory buffer 和硬盘间加入了 Linux 的页面高速缓存(File system cache)来提高ES的写效率。
当写请求发送到ES后,ES将数据暂时写入 memory buffer 中,此时写入的数据还不能被查询到。默认设置下,ES每1秒钟将 memory buffer 中的数据 refresh 到 Linux 的 File system cache,并清空 memory buffer,此时写入的数据就可以被查询到了。
但 File system cache 依然是内存数据,一旦断电,则 File system cache 中的数据全部丢失。默认设置下,ES每30分钟调用 fsync 将 File system cache 中的数据 flush 到硬盘。因此需要通过 translog 来保证即使因为断电 File system cache 数据丢失,es 重启后也能通过日志回放找回丢失的数据。
translog 默认设置下,每一个 index、delete、update 或 bulk 请求都会直接 fsync 写入硬盘。为了保证 translog 不丢失数据,在每一次请求之后执行 fsync 确实会带来一些性能问题。对于一些允许丢失几秒钟数据的场景下,可以通过设置 index.translog.durability 和 index.translog.sync_interval 参数让 translog 每隔一段时间才调用 fsync 将事务日志数据写入硬盘。
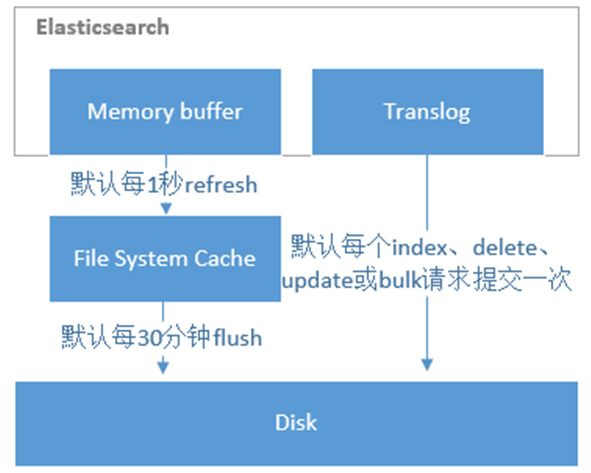
修改刷新时间
对于需要写入后实时查询的数据,可以通过手动 refresh 操作将 memory buffer 的数据立即写入到 File system cache。当然,该解决方案的代价就是降低了 ES 的写性能。
单个文档更新后立即 refresh
PUT /test/_doc/1?refresh
{"test": "test"}
PUT /test/_doc/2?refresh=true
{"test": "test"} |
refresh整个索引的memory buffer
POST /test/_refresh |
2.3.4 文档写入流程
ES 集群中每个节点通过路由都知道集群中的文档的存放位置,所以每个节点都有处理读写请求的能力。
在一个写请求被发送到某个节点后,该节点即为协调节点,协调节点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上。假设 shard = hash(routing) % 4 = 0 ,则过程大致如下:

1.选择任意一个DataNode发送请求,例如:node2。此时,node2就成为一个coordinating node(协调节点) 2.计算得到文档要写入的分片`shard=hash(routing)%number_of_primary_shards` routing是一个可变值,默认是文档的_id 3.coordinating node会进行路由,将请求转发给对应的primary shard所在的DataNode(假设primary shard在node1、replica shard在node2) 4.node1节点上的Primary Shard处理请求,写入数据到索引库中,并将数据同步到Replica shard 5.Primary Shard和Replica Shard都保存好了文档,返回client |
2.3.5 文档读取流程
ES数据的读取是通过文档id来进行查询获取的。
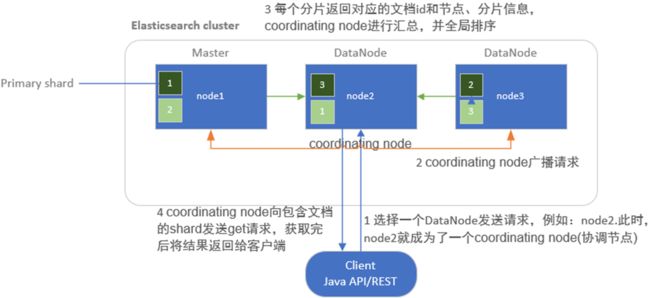
1.client发起查询请求,某个DataNode接收到请求,该DataNode就会成为协调节点(Coordinating Node)协调节点(Coordinating Node) 2.将查询请求广播到每一个数据节点,这些数据节点的分片会处理该查询请求 3.每个分片进行数据查询,将符合条件的数据放在一个优先队列中,并将这些数据的文档ID、节点信息、分片信息返回给协调节点,协调节点将所有的结果进行汇总,并进行全局排序 4.协调节点向包含这些文档ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据返回给客户端 |
2.3.6 锁机制
并发控制尤为重要,有两种通用的方案可以确保数据在并发更新时的正确性。
悲观并发控制
悲观锁的含义:我认为每次更新都有冲突的可能,并发更新这种操作特别不靠谱,我只相信只有严格按我定义的粒度进行串行更新,才是最安全的,一个线程更新时,其他的线程等着,前一个线程更新完成后,下一个线程再上。
关系型数据库中广泛使用该方案,常见的表锁、行锁、读锁、写锁,依赖redis或memcache等实现的分布式锁,都属于悲观锁的范畴。明显的特征是后续的线程会被挂起等待,性能一般来说比较低,不过自行实现的分布式锁,粒度可以自行控制(按行记录、按客户、按业务类型等),在数据正确性与并发性能方面也能找到很好的折衷点
乐观锁并发控制
乐观锁的含义:我认为冲突不经常发生,我想提高并发的性能,如果真有冲突,被冲突的线程重新再尝试几次就好了。
在使用关系型数据库的应用,也经常会自行实现乐观锁的方案,有性能优势,方案实现也不难,还是挺吸引人的。
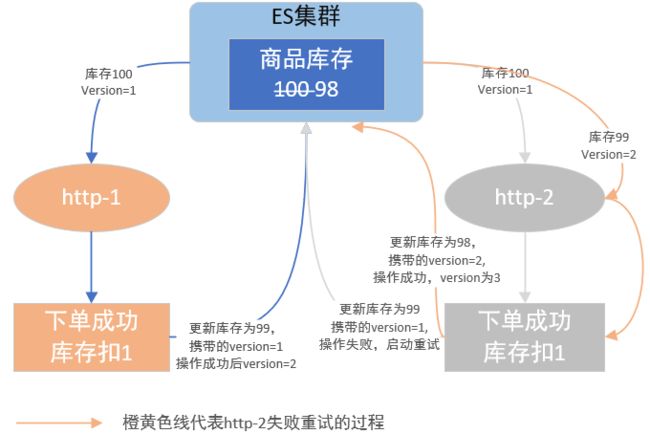
Elasticsearch默认使用的是乐观锁方案,前面介绍的_version字段,记录的就是每次更新的版本号,只有拿到最新版本号的更新操作,才能更新成功,其他拿到过期数据的更新失败,由客户端程序决定失败后的处理方案,一般是重试。
ES的乐观锁方案
若http-2向ES提交更新数据时,ES会判断提交过来的版本号与当前document版本号,document版本号单调递增,如果提交过来的版本号比document版本号小,则说明是过期数据,更新请求将提示错误,过程图如下:
乐观锁关键字
关于乐观锁老版本的关键字时_version,新版本的关键子是if_seq_no和if_primary_term。
_version
ES老版本中针对文档级别的乐观锁。
## 更新文档
PUT /poem/_doc/1
{
"id":1,
"sentence":"床前明月光,疑似地上霜。。"
}
## 返回更新结果,_version版本号被加1
{
"_index" : "poem",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
|
if_seq_no与_primary_term
_seq_no:文档版本号,作用同_version。
_primary_term:文档所在位置,作用整个索引。
## 以上的_seq_no为1,插入该条记录后
PUT /poem/_doc/1?if_seq_no=1&if_primary_term=1
{
"id":1,
"sentence":"举头望明月,低头思故乡。"
}
## 返回更新结果,_seq_no版本加1
{
"_index" : "poem",
"_type" : "_doc",
"_id" : "1",
"_version" : 4,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
} |
3 部署说明
部署安装请见另一个blog
Elasticsearch集群安装_风间净琉璃的博客-CSDN博客
这里没有涉及同义词文件上传。
4 数据管理
数据管理包括集群的状态查看、索引管理、文档管理、DSL查询、聚合查询以及锁机制。
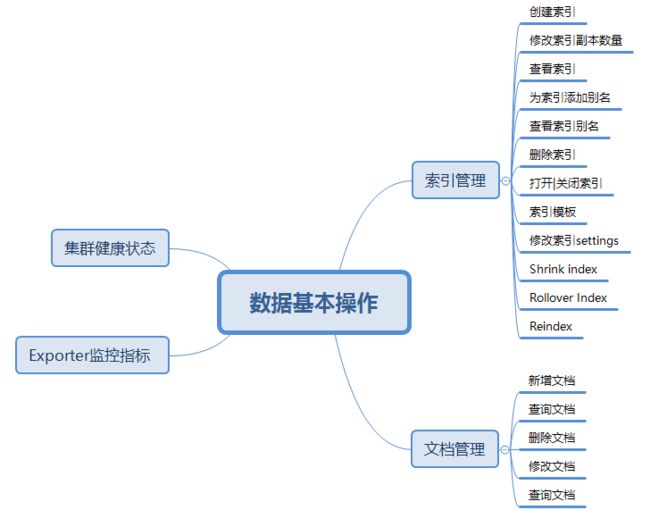
4.1 数据基本操作
该部分主要是索引的管理、文档管理、集群状态信息查询和Exporter监控指标。
4.1.1 索引管理
顾名思义是对索引的管理,以下操作均在Kibana上执行。
创建索引
## 添加索引
PUT poems
{
"mappings": {
"poem_sentence": {
"properties": {
"sentence": {
"type": "text",
"analyzer": "ik_max_word"
},
"id": {
"type": "long"
}
}
}
}
}
## 添加索引成功
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "poems"
} |
修改索引副本数量
## 修改索引副本数量
PUT poems/_settings
{
"number_of_replicas": 3
}
## 副本分片变为3
{
"poems" : {
"settings" : {
"index" : {
"creation_date" : "1641522469199",
"number_of_shards" : "5",
"number_of_replicas" : "3",
"uuid" : "g1VFN5uKTk6_b5zXaVlQeQ",
"version" : {
"created" : "6080599"
},
"provided_name" : "poems"
}
}
}
} |
查看索引
## 查看索引
GET poems
## 索引结果
{
"poems" : {
"aliases" : { },
"mappings" : {
"poem_sentence" : {
"properties" : {
"id" : {
"type" : "long"
},
"sentence" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1641522469199",
"number_of_shards" : "5",
"number_of_replicas" : "3",
"uuid" : "g1VFN5uKTk6_b5zXaVlQeQ",
"version" : {
"created" : "6080599"
},
"provided_name" : "poems"
}
}
}
} |
为索引添加别名
## 为索引添加别名
put poems/_alias/poems_lalala
## 结果
{
"acknowledged" : true
} |
查看索引的别名
## GET poems/_alias
## 结果
{
"poems" : {
"aliases" : {
"poems_lalala" : { }
}
}
}
|
删除索引
## 删除语句
DELETE poem
## 删除结果
{
"acknowledged" : true
} |
关闭索引
关闭索引后,新增|查询文档会失败。
## 关闭索引
POST poems/_close
## 关闭结果
{
"acknowledged" : true
} |
打开索引
## 打开索引
POST poems/_open
## 打开所以结果
{
"acknowledged" : true,
"shards_acknowledged" : true
} |
索引模板
索引模板,简而言之,是一种复用机制,就像一些项目的开发框架如 Laravel 一样,省去了大量的重复,体力劳动。当新建一个 Elasticsearch 索引时,自动匹配模板,完成索引的基础部分搭建。
模板主要构成成分:
{
"order": 0, // 模板优先级
"template": "sample_info*", // 模板匹配的名称方式
"settings": {...}, // 索引设置
"mappings": {...}, // 索引中各字段的映射定义
"aliases": {...} // 索引的别名
} |
## 构建一个索引模板
PUT /_template/template_name
{
"template" : "example-*",
"order":1,
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"type1" : {
"_source" : {"enabled" : false }
}
}
}
## 构建结果
{
"acknowledged" : true
} |
修改索引settings
## 先关闭
POST poems/_close
## 再设置
PUT poems/_settings
{
"number_of_replicas": 3,
"index":{
"analysis.analyzer.default.type":"ik_max_word",
"analysis.search_analyzer.default.type":"ik_smart"
}
}
## 最后打开
POST poems/_open |
Shrink index
将源索引按照特定的规则缩小成一个比源索引拥有更少主分片的新索引。
使用前提
1.选择一个shrink节点的存储必须可以满足源索引数据的两倍。 2.目标索引不能成存在。 3.目标索引的主分片必须少于源索引的主分片数,且目标索引中主分片的数量必须是源索引中主分片数量的一个因子。 4.目标索引的单个分片的总文档数不能超过2147483519个。shrink的时候要计算好最少主分片数。 5.主分片数的个数是素数的话,只能收缩成一个主分片。 |
功能实现
1.采用源索引的配置创建一个目标索引(新索引),降低了主分片数量 2.然后将源索引中的Lucene的segments硬链接到目标索引中。 (如果文件系统不支持硬链接,那么所有segments都被复制到新索引中,这是一个更耗时的过程。) 3.对目标索引进行恢复操作,就好像它是一个刚刚重新打开的关闭索引。 |
举例说明
1.创建一个主分片数为5的索引。
| PUT gudong20211220001 "settings": { |
2. 查询分片情况
| GET _cat/shards/gudong20211220001?v |
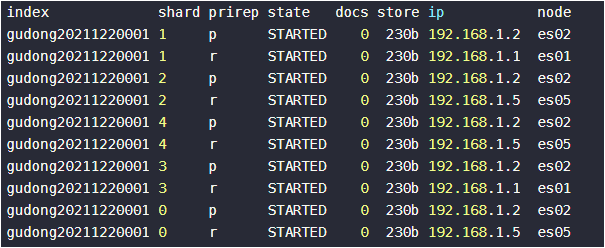
3.源索引禁止写,同时选择一个节点进行shrink
PUT /gudong20211220001/_settings
{
"settings": {
"index.routing.allocation.require._name": "es05",
"index.blocks.write": true
}
} |
4.查询分片变化,发现进行shrink的节点有索引的一套完整数据。

5.缩小索引
POST gudong20211220001/_shrink/gudong20211220002?copy_settings=true
{
"settings": {
"index.routing.allocation.require._name": null,
"index.blocks.write": null
}
} |
POST gudong20211220001/_shrink/gudong20211220002?copy_settings=true
{
"settings": {
"index.routing.allocation.require._name": null,
"index.blocks.write": null,
"index.soft_deletes.enabled": true
}
} |
6.查询分片分配,主分片也是在shrink节点上的。

源索引的分片不会在shrik之后进行重新分配,源索引一般进行删除处理。
过程监控
GET _cat/recovery/gudong20211220002?v |
Rollover Index
最早项目中没有Index滚动功能,随着数据增多Index变得巨大后效率急剧降低。
后来加了逻辑,每个月滚动一次Index。但是这样还是不能应对每个Index差异化的数据增加速度。
再后来就加了滚动判断逻辑,数据量或数据行数达到阈值就滚动到下一个Index,而且我们去掉了影响性能的TTL机制,而是采用按配置来删以天为基础单位、及滚动产生的index,极大提升了性嗯呢该。但是后来发生了一次怎么也找不到原因的bug,是由于获取Index大小和行数的返回出了问题。正好要升级到ES 6.x,看到有Rollover Index API,特别记录一笔,以备将来可查。
简介
ES Rollover Index API的大致逻辑:
使用类似xxx-0的格式建立index,注意必须是短横线-+数字结尾。
建立index时,需要一同添加别名,用来滚动,如xxx-write
一个专门的线程定时调用Rollover Index API: xxx-write/_rollover,并传入滚动条件以及新index的mappings、settings等。如果满足条件,会自动按传入的参数创建新的index并附加滚动别名如xxx-write,并去掉老的index的滚动别名如xxx-write。
你的写入线程不用停机,只要一直用滚动别名xxx-write来写入就行,不用操心写到哪里了。
举例
1.创建新索引
## 创建一个新索引
PUT isp_log-20220107
## 返回结果
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "isp_log-20220107"
}
|
2.指定一个专门 进行rollover(滚动写入) 的索引别名。索引别名isp_log-write-alias 是为了数据写入使用
#为索引再指定一个只用来 rollover 的别名
POST _aliases
{
"actions": [
{
"add": {
"index": "isp_log-20220107",
"alias": "isp_log-write-alias"
}
}
]
} |
rollover别名isp_log-write-alias只需要在创建第一个索引时指定一次,后面isp_log-write-alias会自动滚动指向:isp_log-20220108、isp_log-20220109
rollover 索引别名的主要作用是"滚动写入",因此rollover索引别名只能指向一个具体的索引。
3.设置滚动策略。
# 指定rollover 的策略,这里为了测试最大文档数为2就可以滚动生成新索引了
POST /isp_log-write-alias/_rollover
{
"conditions": {
"max_docs": 2
}
}
## 执行结果
{
"acknowledged" : false,
"shards_acknowledged" : false,
"old_index" : "isp_log-20220107",
"new_index" : "isp_log-20220108",
"rolled_over" : false,
"dry_run" : false,
"conditions" : {
"[max_docs: 2]" : false
}
}
|
4.模拟日志生成,添加文档
# 写一点测试数据进去
PUT isp_log-write-alias/_doc/1
{
"uid" : "111",
"nick" : "test1"
}
PUT isp_log-write-alias/_doc/2
{
"uid" : "222",
"nick" : "test2"
}
PUT isp_log-write-alias/_doc/3
{
"uid" : "333",
"nick" : "test3"
} |
值得注意的是:index.refresh_interval 参数会影响滚动策略准确性。比如max_docs设置成2,受refresh_interval 影响,索引中包含的文档数量是有可能大于2个的。
Reindex
使用场景
es集群版本升级
同一大版本升级(如6.1.x->6.8.x或7.1.x->7.8.x),索引读写兼容,不需要重建索引
不同版本升级(如6.1.x->7.1.x),索引读写不兼容,需要重建索引
索引远程迁移
集群迁移,索引服务不停机,数据提前迁移
索引分片数量调整
分片数量由少变多,由多变少
索引文档结构变更
字段类型,字段属性变更、文档对象结构变更
索引碎片垃圾处理
索引频繁更新,产生很多内存碎片垃圾
举例
## poem_sentence迁移数据到new_poems
## size,可选,每次批量提交1000个,可以提高效率,建议每次提交5-15M的数据
POST _reindex
{
"source": {
"index": "poem_sentence",
"size": 1000
},
"dest": {
"index": "new_poems"
}
}
## 结果
{
"took" : 94,
"timed_out" : false,
"total" : 0,
"updated" : 0,
"created" : 0,
"deleted" : 0,
"batches" : 0,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
|
注意:新老索引的mapping映射建议一致,不然会出现其他写入或者查询问题。 |
4.1.2 集群状态相关
以下是集群状态相关。
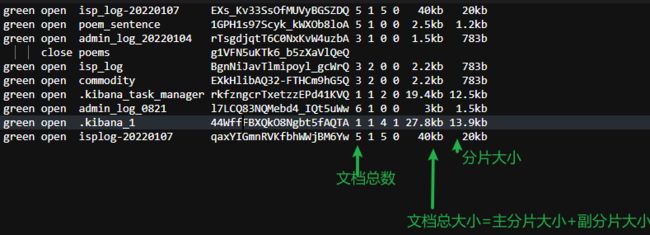
查询所有索引及容量 _cat/indices
## 执行指令 GET _cat/indices |
查询所有索引映射结构 _all
## 执行指令 GET _all ## 结果太长就不展示了 |
查询集群健康状态 _cluster/health
## 执行指令
GET _cluster/health
## 返回结果
{
"cluster_name" : "elasticsearch-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 32,
"active_shards" : 70,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
} |
查询所有节点 GET _cat/nodes
## 执行指令 GET _cat/nodes ## 返回结果 127.0.0.1 78 82 1 0.09 0.11 0.25 mdi * es-node2 127.0.0.1 86 82 1 0.09 0.11 0.25 mdi - es-node1 127.0.0.1 87 82 1 0.09 0.11 0.25 mdi - es-node2 |
查询索引及分片的分布 _cat/shards
## 执行指令 GET _cat/shards ## 执行结果 isp_log 1 p STARTED 0 261b 127.0.0.1 es-node2 isp_log 1 r STARTED 0 261b 127.0.0.1 es-node1 isp_log 1 r STARTED 0 261b 127.0.0.1 es-node2 isp_log 2 p STARTED 0 261b 127.0.0.1 es-node2 isp_log 2 r STARTED 0 261b 127.0.0.1 es-node1 isp_log 2 r STARTED 0 261b 127.0.0.1 es-node2 isp_log 0 p STARTED 0 261b 127.0.0.1 es-node2 isp_log 0 r STARTED 0 261b 127.0.0.1 es-node1 isp_log 0 r STARTED 0 261b 127.0.0.1 es-node2 |
查询所有插件 _cat/plugins
## 执行指令 GET _cat/plugins ## 插件结果 es-node2 analysis-ik 6.8.5 es-node1 analysis-ik 6.8.5 es-node2 analysis-ik 6.8.5 |
4.1.3 Elasticsearch_exporter 监控指标
github地址:https://github.com/justwatchcom/elasticsearch_exporter
| Name | Type | Cardinality | Help |
|---|---|---|---|
| elasticsearch_breakers_estimated_size_bytes | gauge | 4 | Estimated size in bytes of breaker breaker字节的估计大小 |
| elasticsearch_breakers_limit_size_bytes | gauge | 4 | Limit size in bytes for breaker breaker大小限制为字节 |
4.1.4 文档管理
对文档的管理。
新增文档
PUT test_mes/man/2
{
"msg_chinse":"天青色等烟雨"
} |
查询文档
GET test_mes/man/2
## 查询结果
{
"_index" : "test_mes",
"_type" : "man",
"_id" : "2",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"msg_chinse" : "天青色等烟雨"
}
} |
删除文档
delete test_mes/man/1
{
"_index" : "test_mes",
"_type" : "man",
"_id" : "1",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
} |
修改文档
## es中已经有id为2的数据
PUT test_mes/man/2
{
"msg_chinse":"天青色等烟雨,而我在等你"
}
## 执行结果
{
"_index" : "test_mes",
"_type" : "man",
"_id" : "2",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
} |
4.2 DSL
Elasticsearch提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。
DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。
4.2.1 记录查询
无条件查询 match_all
查询索引的全部信息。
GET poem_sentence/_search
{
"query": {
"match_all": {}
}
} |
有条件查询
含有条件的查询。
单条件模糊查询
match
模糊查询,分词更细。
get /mgn_menu/_search
{
"query" : {
"match" : { "menu_name": "menu_name22266739" }
}
} |
match_phrase
模糊查询,分词较为粗一些。
get /mgn_menu/_search
{
"query" : {
"match_phrase": { "menu_name": "menu_name2226623" }
}
} |
prefix
前缀匹配查询。
get /mgn_menu/_search
{
"query" : {
"match_phrase_prefix": { "menu_name": "menu_name2226623" }
}
} |
regexp
正则匹配表达式查询。
get /mgn_menu/_search
{
"query" : {
"regexp": { "menu_name": "menu_name[0-9].+" }
}
} |
单条件精确查询
term
精确单个条件查询。
get /mgn_menu/_search
{
"query" : {
"term": { "menu_name": "menu_name111" }
}
} |
terms
精确单个条件查询,一次可以查询多个值。
get /mgn_menu/_search
{
"query" : {
"terms": { "menu_name": ["menu_name1","menu_name2"] }
}
} |
range
查询menu_id的范围值。
GET /mgn_menu/_search
{
"query": {
"range": {
"menu_id": {
"gte": 1,
"lte": 3
}
}
}
} |
exists
是否存在某个字段field。
GET /mgn_menu/_search
{
"query": {
"exists": {
"field": "menu_name"
}
}
} |
ids
根据id查询多个值。
GET /mgn_menu/_search
{
"query": {
"ids": {
"values" : ["JaaeZX4B-dKJzrFVnoAw", "MqaeZX4B-dKJzrFVnoAw", "NaaeZX4B-dKJzrFVnoAw"]
}
}
} |
多条件组合查询
bool-must
相当于and条件。
GET /mgn_menu/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"menu_name": "menu_name2"
}
},
{
"match": {
"menu_url": "menu_url2"
}
}
]
}
}
} |
bool-filter
必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
GET /mgn_menu/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"menu_name": "menu_name2"
}
},
{
"match": {
"menu_url": "menu_url2"
}
}
]
}
}
} |
boot-must_not
不包含语句。
GET /mgn_menu/_search
{
"query": {
"bool": {
"must_not": [
{
"match_phrase_prefix": {
"menu_name": "menu_name1"
}
},
{
"range": {
"menu_id": {
"gte": 20
}
}
}
]
}
}
} |
bool-should
相当于或者条件查询。
GET /mgn_menu/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"menu_name": "menu_name2"
}
},
{
"match": {
"menu_url": "menu_url3"
}
}
]
}
}
} |
总结 1.must 文档 必须 匹配这些条件才能被包含进来。相当于sql中的 and 2.must_not 文档 必须不 匹配这些条件才能被包含进来。相当于sql中的 not 3.should 如果满足这些语句中的任意语句,将增加 _score ,否则,无任何影响。它们主要用于修正每个文档的相关性得分。相当于sql中的or 4.filter 必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档 |
4.2.2 结果聚合查询(aggs)
查询某个字段最大值
POST /mgn_menu/_search
{
"size": 0,
"aggs": {
"masssbalance": {
"max": {
"field": "menu_id"
}
}
}
} |
查询某个字段平均值
POST /mgn_menu/_search
{
"size": 0,
"aggs": {
"masssbalance": {
"avg": {
"field": "menu_id"
}
}
}
} |
4.3 批量操作
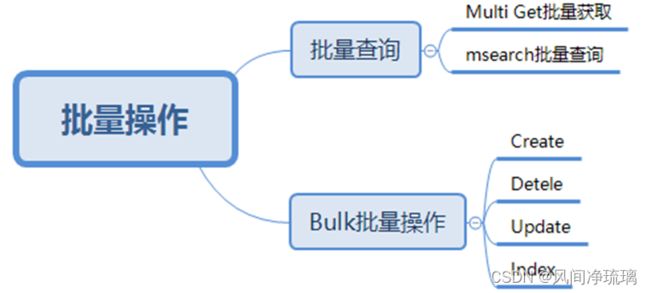
Bulk批量操作
•Create 文档,使用POST方法自动生成文档id,使用PUT指定的id如已存在,则报错。
•Index文档,用于创建文档,与create文档不同,如果文档不存在,直接创建新文档,否则删除原来的文档,新文档被索引,_version版本加1。
•Update文档, 不会删除原来文档,而是实现真正更新。
•Delete文档,该文档并没有从索引中物理删除,只是在其他文件中被标记删除,只要ElasticSerach 引擎执行段合并操作时,才会真正从物理上删除文档。
批量查询
•Mget,可以对不同索引的文档进行批量读取,只需要提供索引名称和 Id 就可以在一次 API 中全部读取,减少网络开销。
•Msearch可以对不同索引的文档进行批量读取,只需要提供索引名称和 查询条件 就可以一次 API 中全部读取,减少网络开销。
4.4 分页查询
Elasticsearch分页查询分为浅分页、scroll深分页、scorll_after深分页三大类。
4.4.1 from+size浅分页
GET /mgn_menu/_search
{
"from": 0,
"size": 2,
"query": {
"bool": {
"filter": {
"range": {
"menu_id": {
"gte": 10000000,
"lte": 20000000
}
}
}
}
},
"sort": [
{
"menu_id": {
"order": "desc"
}
}
]
}
{
"took" : 963,
"timed_out" : false,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 10000001,
"max_score" : null,
"hits" : [
{
"_index" : "mgn_menu",
"_type" : "_doc",
"_id" : "28TSZX4B-dKJzrFVqYIh",
"_score" : null,
"_source" : {
"menu_id" : 20000000,
"menu_name" : "menu_name20000000",
"menu_logo" : "menu_logo20000000",
"menu_url" : "menu_url20000000",
"menu_seq" : 1,
"rec_st" : "1",
"rec_crt_ts" : "1642385811825",
"rec_upd_ts" : "1642385811825"
},
"sort" : [
20000000
]
},
{
"_index" : "mgn_menu",
"_type" : "_doc",
"_id" : "2sTSZX4B-dKJzrFVqILO",
"_score" : null,
"_source" : {
"menu_id" : 19999999,
"menu_name" : "menu_name19999999",
"menu_logo" : "menu_logo19999999",
"menu_url" : "menu_url19999999",
"menu_seq" : 1,
"rec_st" : "1",
"rec_crt_ts" : "1642385811738",
"rec_upd_ts" : "1642385811738"
},
"sort" : [
19999999
]
}
]
}
} |
分页过程
Query阶段
(1) Client 发送一次搜索请求,node1 接收到请求,然后,node1 创建一个大小为 from + size 的优先级队列用来存结果,我们管 node1 叫 coordinating node。
(2)coordinating node将请求广播到涉及到的 shards,每个 shard 在内部执行搜索请求,然后,将结果存到内部的大小同样为 from + size 的优先级队列里,可以把优先级队列理解为一个包含 top N 结果的列表。
(3)每个 shard 把暂存在自身优先级队列里的数据返回给 coordinating node,coordinating node 拿到各个 shards 返回的结果后对结果进行一次合并,产生一个全局的优先级队列,存到自身的优先级队列里。在上面的过程中,coordinating node 拿到 (from + size) * 分片数目 条数据,然后合并并排序后选择前面的 from + size 条数据存到优先级队列,以便 fetch 阶段使用。另外,各个分片返回给 coordinating node 的数据用于选出前 from + size 条数据,所以,只需要返回唯一标记 doc 的 _id 以及用于排序的 _score 即可,这样也可以保证返回的数据量足够小。coordinating node 计算好自己的优先级队列后,query 阶段结束,进入 fetch 阶段。
fetch阶段
query 阶段知道了要取哪些数据,但是并没有取具体的数据,这就是 fetch 阶段要做的。(1)coordinating node 发送 GET 请求到相关shards。(2)shard 根据 doc 的 _id 取到数据详情,然后返回给 coordinating node。(3)coordinating node 返回数据给 Client。coordinating node 的优先级队列里有 from + size 个 _doc _id,但是,在 fetch 阶段,并不需要取回所有数据,在上面的例子中,前10条数据是不需要取的,只需要取优先级队列里的第11到15条数据即可。需要取的数据可能在不同分片,也可能在同一分片,coordinating node 使用 multi-get 来避免多次去同一分片取数据,从而提高性能。
缺点
from+size查询方式在10000-50000条数据(1000到5000页)以内的时候还是可以的,但是如果数据过多的话,就会出现深分页问题。
举例说明:Elasticsearch 的这种方式提供了分页的功能,同时,也有相应的限制。举个例子,一个索引,有10亿数据,分10个 shards,然后,一个搜索请求,from=1,000,000,size=100,这时候,会带来严重的性能问题,CPU,内存,IO,网络带宽。
4.4.2 scroll 深分页
rom+size查询在10000-50000条数据(1000到5000页)以内的时候还是可以的,但是如果数据过多的话,就会出现深分页问题。
为了解决上面的问题,elasticsearch提出了一个scroll滚动的方式。
scroll 类似于sql中的cursor,使用scroll,每次只能获取一页的内容,然后会返回一个scroll_id。根据返回的这个scroll_id可以不断地获取下一页的内容,所以scroll并不适用于有跳页的情景。
GET /mgn_menu/_search?scroll=5m
{
"query": {
"bool": {
"filter": {
"range": {
"menu_id": {
"gte": 10000000,
"lte": 20000000
}
}
}
}
},
"size": 10,
"from": 0,
"sort": [
{
"menu_id": {
"order": "desc"
}
}
]
}
{
"_scroll_id" : "DnF1ZXJ5VGhlbkZldGNoAwAAAAAABaooFkxZYkp6czRaVHRPdGhpQVphQWJTRkEAAAAAAAWqKRZMWWJKenM0WlR0T3RoaUFaYUFiU0ZBAAAAAAAFsQMWenUwNVlUMnRROE95Tkd6WlRPejljQQ==",
"took" : 206,
"timed_out" : false,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 10000001,
"max_score" : null,
"hits" : [
{
"_index" : "mgn_menu",
"_type" : "_doc",
"_id" : "28TSZX4B-dKJzrFVqYIh",
"_score" : null,
"_source" : {
"menu_id" : 20000000,
"menu_name" : "menu_name20000000",
"menu_logo" : "menu_logo20000000",
"menu_url" : "menu_url20000000",
"menu_seq" : 1,
"rec_st" : "1",
"rec_crt_ts" : "1642385811825",
"rec_upd_ts" : "1642385811825"
},
"sort" : [
20000000
]
},
{
"_index" : "mgn_menu",
"_type" : "_doc",
"_id" : "2sTSZX4B-dKJzrFVqILO",
"_score" : null,
"_source" : {
"menu_id" : 19999999,
"menu_name" : "menu_name19999999",
"menu_logo" : "menu_logo19999999",
"menu_url" : "menu_url19999999",
"menu_seq" : 1,
"rec_st" : "1",
"rec_crt_ts" : "1642385811738",
"rec_upd_ts" : "1642385811738"
},
"sort" : [
19999999
]
}
]
}
}
|
注意: 1. scroll=5m表示设置scroll_id保留5分钟可用。 2. 使用scroll必须要将from设置为0。 3. size决定后面每次调用_search搜索返回的数量 |
然后我们可以通过数据返回的_scroll_id读取下一页内容,每次请求将会读取下10条数据,直到数据读取完毕或者scroll_id保留时间截止:
GET _search/scroll
{
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoAwAAAAAABaooFkxZYkp6czRaVHRPdGhpQVphQWJTRkEAAAAAAAWqKRZMWWJKenM0WlR0T3RoaUFaYUFiU0ZBAAAAAAAFsQMWenUwNVlUMnRROE95Tkd6WlRPejljQQ==",
"scroll": "5m"
}
{
"_scroll_id" : "DnF1ZXJ5VGhlbkZldGNoAwAAAAAABaooFkxZYkp6czRaVHRPdGhpQVphQWJTRkEAAAAAAAWqKRZMWWJKenM0WlR0T3RoaUFaYUFiU0ZBAAAAAAAFsQMWenUwNVlUMnRROE95Tkd6WlRPejljQQ==",
"took" : 244,
"timed_out" : false,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 10000001,
"max_score" : null,
"hits" : [
{
"_index" : "mgn_menu",
"_type" : "_doc",
"_id" : "2cTSZX4B-dKJzrFVqILO",
"_score" : null,
"_source" : {
"menu_id" : 19999998,
"menu_name" : "menu_name19999998",
"menu_logo" : "menu_logo19999998",
"menu_url" : "menu_url19999998",
"menu_seq" : 1,
"rec_st" : "1",
"rec_crt_ts" : "1642385811738",
"rec_upd_ts" : "1642385811738"
},
"sort" : [
19999998
]
},
{
"_index" : "mgn_menu",
"_type" : "_doc",
"_id" : "2MTSZX4B-dKJzrFVqILO",
"_score" : null,
"_source" : {
"menu_id" : 19999997,
"menu_name" : "menu_name19999997",
"menu_logo" : "menu_logo19999997",
"menu_url" : "menu_url19999997",
"menu_seq" : 1,
"rec_st" : "1",
"rec_crt_ts" : "1642385811738",
"rec_upd_ts" : "1642385811738"
},
"sort" : [
19999997
]
}
]
}
} |
scroll删除
根据官方文档的说法,scroll的搜索上下文会在scroll的保留时间截止后自动清除,但是我们知道scroll是非常消耗资源的,所以一个建议就是当不需要了scroll数据的时候,尽可能快的把scroll_id显式删除掉。
清除指定的scroll_id
DELETE _search/scroll/DnF1ZXJ5VGhlbkZldGNoAwAAAAAABaooFkxZYkp6czRaVHRPdGhpQVphQWJTRkEAAAAAAAWqKRZMWWJKenM0WlR0T3RoaUFaYUFiU0ZBAAAAAAAFsQMWenUwNVlUMnRROE95Tkd6WlRPejljQQ== |
清除所有的scroll
DELETE _search/scroll/_all |
4.4.3 search_after 深分页
scroll 的方式,官方的建议不用于实时的请求(一般用于数据导出),因为每一个 scroll_id 不仅会占用大量的资源,而且会生成历史快照,对于数据的变更不会反映到快照上。
search_after 分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。但是需要注意,因为每一页的数据依赖于上一页最后一条数据,所以无法跳页请求。
为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,其实使用业务层的 id 也可以。
GET mgn_menu/_search
{
"query": {
"bool": {
"filter": {
"term": {
"menu_seq": 1
}
}
}
},
"size": 2,
"from": 0,
"sort": [
{
"menu_id": {
"order": "desc"
}
}
]
}
{
"took" : 388,
"timed_out" : false,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 35313000,
"max_score" : null,
"hits" : [
{
"_index" : "mgn_menu",
"_type" : "_doc",
"_id" : "Qq4BZn4B-dKJzrFVRity",
"_score" : null,
"_source" : {
"menu_id" : 35312999,
"menu_name" : "menu_name35312999",
"menu_logo" : "menu_logo35312999",
"menu_url" : "menu_url35312999",
"menu_seq" : 1,
"rec_st" : "1",
"rec_crt_ts" : "1642388866438",
"rec_upd_ts" : "1642388866438"
},
"sort" : [
35312999
]
},
{
"_index" : "mgn_menu",
"_type" : "_doc",
"_id" : "Qa4BZn4B-dKJzrFVRity",
"_score" : null,
"_source" : {
"menu_id" : 35312998,
"menu_name" : "menu_name35312998",
"menu_logo" : "menu_logo35312998",
"menu_url" : "menu_url35312998",
"menu_seq" : 1,
"rec_st" : "1",
"rec_crt_ts" : "1642388866438",
"rec_upd_ts" : "1642388866438"
},
"sort" : [
35312998
]
}
]
}
}
|
注意 1. 使用search_after必须要设置from=0。 2. 这里我使用timestamp和_id作为唯一值排序。 3. 我们在返回的最后一条数据里拿到sort属性的值传入到search_after。 |
GET mgn_menu/_search
{
"query": {
"bool": {
"filter": {
"term": {
"menu_seq": 1
}
}
}
},
"size": 2,
"from": 0,
"search_after": [
35312998
],
"sort": [
{
"menu_id": {
"order": "desc"
}
}
]
}
{
"took" : 429,
"timed_out" : false,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 35313000,
"max_score" : null,
"hits" : [
{
"_index" : "mgn_menu",
"_type" : "_doc",
"_id" : "Pq4BZn4B-dKJzrFVRity",
"_score" : null,
"_source" : {
"menu_id" : 35312995,
"menu_name" : "menu_name35312995",
"menu_logo" : "menu_logo35312995",
"menu_url" : "menu_url35312995",
"menu_seq" : 1,
"rec_st" : "1",
"rec_crt_ts" : "1642388866438",
"rec_upd_ts" : "1642388866438"
},
"sort" : [
35312995
]
},
{
"_index" : "mgn_menu",
"_type" : "_doc",
"_id" : "Pa4BZn4B-dKJzrFVRity",
"_score" : null,
"_source" : {
"menu_id" : 35312994,
"menu_name" : "menu_name35312994",
"menu_logo" : "menu_logo35312994",
"menu_url" : "menu_url35312994",
"menu_seq" : 1,
"rec_st" : "1",
"rec_crt_ts" : "1642388866438",
"rec_upd_ts" : "1642388866438"
},
"sort" : [
35312994
]
}
]
}
}
|
5 分词器
主要讲述分词器。
5.1 简介
将一段文本按照一定的逻辑,分析成多个词语,同时对这些词语进行常规化(normalization)的一种工具,例如:
"hello tom and jerry"可以分为"hello"、"tom"、"and"、"jerry"这4个单词
常规化是说,例如,"hello tom & jerry",那么把"&"这个字符转换为"and",对一个html标签进行分词时,先去掉标签"hello" -> "hello"
5.2 分词器构成
主要由character filters字符过滤器、tokenizers分词器、token filters token过滤器构成。
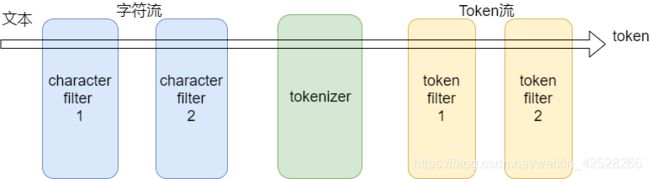
5.2.1 character filter 字符过滤器
在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(hello --> hello),& --> and(I&you --> I and you)
5.2.2 tokenizers 分词器
英文分词可以根据空格将单词分开,中文分词比较复杂,可以采用机器学习算法来分词。
5.2.3 Token filters Token过滤器
将切分的单词进行加工。大小写转换(例将“Quick”转为小写),去掉词(例如停用词像“a”、“and”、“the”等等),或者增加词(例如同义词像“jump”和“leap”)。
5.2.4 关联关系
三者个数:analyzer = CharFilters(0个或多个) + Tokenizer(恰好一个) + TokenFilters(0个或多个)
5.3 写时分词
5.3.1 实验中文分词器
创建好索引
文档中field带有两个字段,msg的字段类型为keyword,msg_chinse字段类型为text且有中文分词。
PUT sport_man { "settings": { "number_of_shards": 3, "number_of_replicas": 1 }, "mapping": { "man": { "properties": { "id": { "type": "long" }, "msg": { "type": "text" }, "msg_chinse": { "type": "text", "analyzer": "ik_max_word" } } } } } |
插入数据
PUT sport_man/man/1
{
"msg":"乔丹是篮球之神",
"msg_chinse":"乔丹是篮球之神"
}
## 插入结果{ "_index" : "sport_man", "_type" : "man", "_id" : "1", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 2, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1 } |
msg分词结果
## 分词查询
POST sport_man/_analyze
{
"field": "msg",
"text": "乔丹是篮球之神"
}由于没有指定分词器,使用默认分词器。
分词结果是,“乔”,“丹”,“是”,“篮”,“球”,“之”,“神”。 |
msg_chinse分词结果
## 分词查询
POST sport_man/_analyze
{
"field": "msg_chinese",
"text": "乔丹是篮球之神"
}由于没有指定分词器,使用默认分词器。
分词结果是,乔丹, 是, 篮球, 之神 |
⽂档写⼊的时候会根据字段设置的分词器类型进⾏分词,如果不指定就是默认的standard分词器。写时分词器需要在mapping中指定,⽽且⼀旦指定不能再修改,若要修改必须重建索引。 |
5.4 读时分词
读取数据时做的分词。
1.由于读时分词器默认与写时分词器默认保持⼀致,拿上⾯的例⼦,你搜索 msg 字段,那么读时分词器为 Standard ,搜索 msg_chinese 时分词器则为 ik_max_word。这种默认设定也是⾮常容易理解的,读写采⽤⼀致的分词器,才能尽最⼤可能保证分词的结果是可以匹配的。 2.允许读时分词器单独设置 3.⼀般来讲不需要特别指定读时分词器,如果读的时候不单独设置分词器,那么读时分词器的验证⽅法与写时⼀致。 |
5.5 常用内置分词器介绍
常用内置分词器有standard analyzer、simple analyzer、whitespace analyzer、stop analyzer、language analyzer、pattern analyzer
5.5.1 standard analyzer
默认分词器:按照非字母和非数字字符进行分隔,单词转为小写
测试文本:a*B!c d4e 5f 7-h
分词结果:a、b、c、d4e、5f、7、h
5.5.2 simple analyzer
分词效果:按照非字母字符进行分隔,单词转为小写
测试文本:a*B!c d4e 5f 7-h
分词结果:a、b、c、d、e、f、h
5.5.3 whitespace analyzer
分词效果:按照空白字符进行分隔
测试文本:a*B!c D d4e 5f 7-h
分词结果:a*B!c、D、d4e、5f、7-h
5.5.4 stop analyzer
分词效果:使用非字母字符进行分隔,单词转换为小写,并去掉停用词(默认为英语的停用词,例如the、a、an、this、of、at等)
测试文本:The apple is red
分词结果:apple、red
5.5.5 language analyzer
分词效果:使用指定的语言的语法进行分词,默认为english,没有内置中文分词器。
5.5.6 pattern analyzer
分词效果:使用指定的正则表达式进行分词,默认\\W+,即多个非数字非字母字符。
5.6 第三方插件分词器
第三方插件也很多,这里主要说明ik中文分词器。
IK分词器地址:https://github.com/medcl/elasticsearch-analysis-ik
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
5.6.1 ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
5.6.2 ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
5.6.3 最佳实践
两种分词器使用的最佳实践是:索引时用ik_max_word,在搜索时用ik_smart。
即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。
6 Java接入Elasticsearch-api
6.1 使用步骤
- 引入maven依赖,注意pom中Elasticsearch的版本需要与部署的Elasticsearch一致,避免后续版本不兼容问题
- 根据集群信息,构建链接客户端
- 进行api调用进行操作
6.2 Elasticsearch客户端
Java项目中操作ES可以用ES的客户端 TransportClient、RestClient。springboot项目可以用Spring Data Elasticsearch(内部也是封装了RestClient)。
6.2.1 TransportClient
TransportClient 是ElasticSearch(java)客户端封装对象,使用transport远程连接到Elasticsearch集群,默认用的TCP端口是9300,该transport node并不会加入集群,而是简单的向ElasticSearch集群上的节点发送请求。
6.2.2 Rest ClientJava REST客户端
•Java Low Level REST Client:elasticsearch client 低级别客户端。它允许通过http请求与Elasticsearch集群进行通信。API本身不负责数据的编码解码,由用户去编码解码。它与所有的ElasticSearch版本兼容。
•Java High Level REST Client:Elasticsearch client官方高级客户端。基于低级客户端,它定义的API,已经对请求与响应数据包进行编码解码。
建议 Elasticsearch计划在Elasticsearch 7.0中弃用TransportClient,在8.0中完全删除它。故在实际使用过程中建议使用Java高级REST client。Rest client执行HTTP请求来执行操作,无需再序列化的Java请求。 |
6.3 Java High Level REST Client 代码示例
Elasticsearch java-api官方文档地址:Document APIs | Java REST Client [6.8] | Elastic
6.3.1 创建客户端连接
@Configuration
public class ElasticsearchClient {
@Value("#{'${host.address.array}'.split(',')}")
private String[] hostAddressArray;
@Bean(name = "restHighLevelClient")
public RestHighLevelClient buildRestHighLevelClient() {
if (null == hostAddressArray || hostAddressArray.length == 0) {
throw new HostAddressArrayException(ResponseCode.HOST_ADDRESS_ARRAY_EMPTY);
}
int length = hostAddressArray.length;
HttpHost[] httpHosts = new HttpHost[length];
for (int i = 0; i < length; i++) {
String nodeConfig = hostAddressArray[i];
String[] split = nodeConfig.split(":");
if (split.length < 2) {
throw new HostAddressArrayException(ResponseCode.NODE_CONFIG_INVALID);
}
httpHosts[i] = new HttpHost(split[0], Integer.parseInt(split[1]), "http");
}
return new RestHighLevelClient(RestClient.builder(httpHosts));
}
} |
6.3.2 索引操作
该节时对索引的操作。
新增索引
@Slf4j
@Component
public class CreateIndex {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 创建索引
* @param indexName
* @param mapping
* @return
*/
public Boolean createIndex(String indexName, String mapping) {
if (StringUtils.isEmpty(indexName)) {
throw new IndexException(ResponseCode.INDEX_NAME_EMPTY);
}
CreateIndexRequest request = new CreateIndexRequest(indexName);
if (!mapping.isEmpty()) {
log.info("Mapping is Empty.");
request.mapping(mapping, XContentType.JSON);
}
try {
CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
return Optional.ofNullable(response).map(AcknowledgedResponse::isAcknowledged).orElse(false);
} catch (IOException e) {
log.error("create index error = {}",e);
throw new IndexException(ResponseCode.CREATE_INDEX_ERROR);
}
}
} |
删除索引
@Slf4j
@Component
public class DeleteIndex {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 删除索引
*
* @param index
* @return
*/
public Boolean deleteIndex(String index) {
DeleteIndexRequest request = new DeleteIndexRequest(index);
try {
AcknowledgedResponse response = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
return Optional.ofNullable(response).map(AcknowledgedResponse::isAcknowledged).orElse(false);
} catch (IOException e) {
log.error("Delete index error = {}",e);
throw new IndexException(ResponseCode.DELETE_INDEX_ERROR);
}
}
} |
判断索引是否存在
@Slf4j
@Component
public class HasExistIndex {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 是否存在index
*
* @return
*/
public Boolean hasExistIndex(String indexName) {
if (StringUtils.isEmpty(indexName)) {
throw new IndexException(ResponseCode.INDEX_NAME_EMPTY);
}
GetIndexRequest getIndexRequest = new GetIndexRequest().indices(indexName);
try {
return restHighLevelClient.indices().exists(getIndexRequest);
} catch (IOException e) {
log.error("Has exsit index error = {}",e);
throw new IndexException(ResponseCode.HAS_EXSIT_INDEX_ERROR);
}
}
}
|
6.3.3 文档操作
该节是对文档的相关操作。
新增文档
@Slf4j
@Component
public class PutDocument {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
*
* @param indexName
* @return
*/
public Boolean putDocument(String indexName,String typeName,String document){
if(StringUtils.isEmpty(indexName)){
throw new IndexException(ResponseCode.INDEX_NAME_EMPTY);
}
if(StringUtils.isEmpty(typeName)){
throw new IndexException(ResponseCode.TYPE_NAME_EMPTY);
}
IndexRequest request = new IndexRequest(indexName,typeName);
if(StringUtils.isEmpty(document)) {
throw new IndexException(ResponseCode.DOCUMENT_CONTENT_EMPTY);
}
request.source(document, XContentType.JSON);
try {
IndexResponse indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT);
RestStatus restStatus = Optional.ofNullable(indexResponse).map(IndexResponse::status).orElse(null);
if(null!=restStatus){
return restStatus==RestStatus.OK||restStatus==RestStatus.CREATED;
}
log.error("Rest Status is null.");
return false;
} catch (IOException e) {
log.error("Put document error = {}",e);
throw new IndexException(ResponseCode.PUT_DOCUMENT_ERROR);
}
}
} |
查询文档
@Slf4j
@Component
public class SearchDocument {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
*
* @param indexName
* @param key
* @param value
* @return
*/
public Long searchSingleTerm(String indexName, String key, String value) {
SearchRequest searchRequest = new SearchRequest(indexName);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termQuery(key, value));
sourceBuilder.from(0);
sourceBuilder.size(5);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
return searchResponse.getHits().getTotalHits();
} catch (IOException e) {
log.error("Search single term error = {}", e);
throw new IndexException(ResponseCode.SEARCH_SINGLE_TERM_ERROR);
}
}
} |
批量插入文档
@Slf4j
@Component
public class BulkPutDocument {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
*
* @param bulkPutDocumentRequest
* @return
*/
public Boolean bulkPutDocument( BulkPutDocumentRequest bulkPutDocumentRequest) {
String indexName = Optional.ofNullable(bulkPutDocumentRequest).map(BulkPutDocumentRequest::getIndexName).orElse(null);
if (StringUtils.isEmpty(indexName)) {
throw new IndexException(ResponseCode.INDEX_NAME_EMPTY);
}
List |
7 性能压测
esrally docker官方使用文档: https://esrally.readthedocs.io/en/2.3.0/docker.html#
7.1 esrally doker安装压测
7.1.1 局限性
当使用Docker镜像时,不支持以下Rally功能:
- 分配负载测试驱动程序以应用来自多台机器的负载。(分布式压测)
- 使用除了基准测试之外的其他管道。(只有基本测试功能)
7.1.2 快速开始
准备
你可以先通过一个简单的命令列出可用的轨道来测试Rally Docker图像:
$ docker run elastic/rally list tracks
____ ____
/ __ \____ _/ / /_ __
/ /_/ / __ `/ / / / / /
/ _, _/ /_/ / / / /_/ /
/_/ |_|\__,_/_/_/\__, /
/____/
Available tracks:
Name Description Documents Compressed Size Uncompressed Size Default Challenge All Challenges
------------- --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ----------- ----------------- ------------------- ----------------------- ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
eql EQL benchmarks based on endgame index of SIEM demo cluster 60,782,211 4.5 GB 109.2 GB default default
eventdata This benchmark indexes HTTP access logs generated based sample logs from the elastic.co website using the generator available in https://github.com/elastic/rally-eventdata-track 20,000,000 756.0 MB 15.3 GB append-no-conflicts append-no-conflicts,transform
geonames POIs from Geonames 11,396,503 252.9 MB 3.3 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,append-sorted-no-conflicts,append-fast-with-conflicts,significant-text
geopoint Point coordinates from PlanetOSM 60,844,404 482.1 MB 2.3 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,append-fast-with-conflicts
geopointshape Point coordinates from PlanetOSM indexed as geoshapes 60,844,404 470.8 MB 2.6 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,append-fast-with-conflicts
geoshape Shapes from PlanetOSM 60,523,283 13.4 GB 45.4 GB append-no-conflicts append-no-conflicts
http_logs HTTP server log data 247,249,096 1.2 GB 31.1 GB append-no-conflicts append-no-conflicts,runtime-fields,append-no-conflicts-index-only,append-sorted-no-conflicts,append-index-only-with-ingest-pipeline,update,append-no-conflicts-index-reindex-only
metricbeat Metricbeat data 1,079,600 87.7 MB 1.2 GB append-no-conflicts append-no-conflicts
nested StackOverflow Q&A stored as nested docs 11,203,029 663.3 MB 3.4 GB nested-search-challenge nested-search-challenge,index-only
noaa Global daily weather measurements from NOAA 33,659,481 949.4 MB 9.0 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,top_metrics,aggs
nyc_taxis Taxi rides in New York in 2021 165,346,692 4.5 GB 74.3 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,append-sorted-no-conflicts-index-only,update,append-ml,date-histogram,indexing-querying
percolator Percolator benchmark based on AOL queries 2,000,000 121.1 kB 104.9 MB append-no-conflicts append-no-conflicts
pmc Full text benchmark with academic papers from PMC 574,199 5.5 GB 21.7 GB append-no-conflicts append-no-conflicts,append-no-conflicts-index-only,append-sorted-no-conflicts,append-fast-with-conflicts,indexing-querying
so Indexing benchmark using up to questions and answers from StackOverflow 36,062,278 8.9 GB 33.1 GB append-no-conflicts append-no-conflicts
-------------------------------
[INFO] SUCCESS (took 3 seconds)
------------------------------- |
运行
srally race --distribution-version=7.6.2 --track=geopoint --challenge=append-fast-with-conflicts |
结果显示
| Metric | Task | Value | Unit | |--------------------------------:|-------------:|----------:|-------:| | Total indexing time | | 124.712 | min | | Total merge time | | 21.8604 | min | | Total refresh time | | 4.49527 | min | | Total merge throttle time | | 0.120433 | min | | Median CPU usage | | 546.5 | % | | Total Young Gen GC time | | 72.078 | s | | Total Young Gen GC count | | 43 | | | Total Old Gen GC time | | 3.426 | s | | Total Old Gen GC count | | 1 | | | Index size | | 2.26661 | GB | | Total written | | 30.083 | GB | | Heap used for segments | | 10.7148 | MB | | Heap used for doc values | | 0.0135536 | MB | | Heap used for terms | | 9.22965 | MB | | Heap used for points | | 0.78789 | MB | | Heap used for stored fields | | 0.683708 | MB | | Segment count | | 115 | | | Min Throughput | index-update | 59210.4 | docs/s | | Mean Throughput | index-update | 60110.3 | docs/s | | Median Throughput | index-update | 65276.2 | docs/s | | Max Throughput | index-update | 76516.6 | docs/s | | 50.0th percentile latency | index-update | 556.269 | ms | | 90.0th percentile latency | index-update | 852.779 | ms | | 99.0th percentile latency | index-update | 1854.31 | ms | | 99.9th percentile latency | index-update | 2972.96 | ms | | 99.99th percentile latency | index-update | 4106.91 | ms | | 100th percentile latency | index-update | 4542.84 | ms | | 50.0th percentile service time | index-update | 556.269 | ms | | 90.0th percentile service time | index-update | 852.779 | ms | | 99.0th percentile service time | index-update | 1854.31 | ms | | 99.9th percentile service time | index-update | 2972.96 | ms | | 99.99th percentile service time | index-update | 4106.91 | ms | | 100th percentile service time | index-update | 4542.84 | ms | | Min Throughput | force-merge | 0.221067 | ops/s | | Mean Throughput | force-merge | 0.221067 | ops/s | | Median Throughput | force-merge | 0.221067 | ops/s | | Max Throughput | force-merge | 0.221067 | ops/s | | 100th percentile latency | force-merge | 4523.52 | ms | | 100th percentile service time | force-merge | 4523.52 | ms | ---------------------------------- [INFO] SUCCESS (took 1624 seconds) ---------------------------------- |
8 使用调优

从使用者角度比较常用的: 1. 硬盘尽量选固态硬盘SSD 2. 设置合理的索引分片和副本数 3. 大量数据写入使用批量请求 4. 索引结构合理,该分词的字段就分词,不需要分词或者不需要建立索引的设置为index:false或者其他 5. 查询需要分页,避免深分页 6. 合理设置ES组件本身的连接池大小 7. 扩容 |
9 源码分析
9.1 Elasticsearch组件图
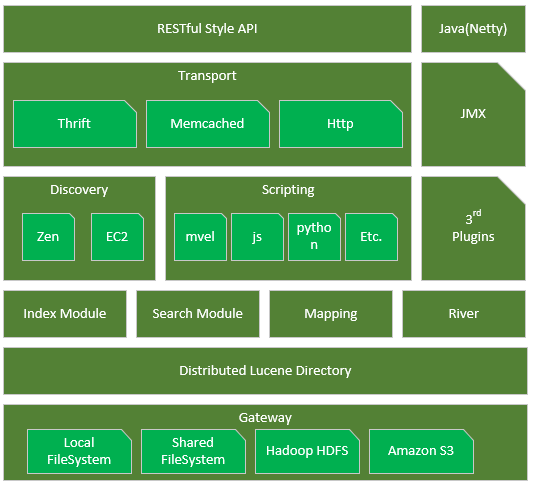
Gateway
代表ElasticSearch索引的持久化存储方式。
在Gateway中,ElasticSearch默认先把索引存储在内存中,然后当内存满的时候,再持久化到Gateway里。当ES集群关闭或重启的时候,它就会从Gateway里去读取索引数据。比如LocalFileSystem和HDFS、AS3等。
DistributedLucene Directory
它是Lucene里的一些列索引文件组成的目录。它负责管理这些索引文件。包括数据的读取、写入,以及索引的添加和合并等。
River
代表是数据源。是以插件的形式存在于ElasticSearch中。
Mapping
映射的意思,非常类似于静态语言中的数据类型。比如我们声明一个int类型的变量,那以后这个变量只能存储int类型的数据。
比如我们声明一个double类型的mapping字段,则只能存储double类型的数据。
Mapping不仅是告诉ElasticSearch,哪个字段是哪种类型。还能告诉ElasticSearch如何来索引数据,以及数据是否被索引到等。
Search Moudle
搜索模块
Index Moudle
索引模块
Disvcovery
主要是负责集群的master节点发现。比如某个节点突然离开或进来的情况,进行一个分片重新分片等。这里有个发现机制。
发现机制默认的实现方式是单播和多播的形式,即Zen,同时也支持点对点的实现。另外一种是以插件的形式,即EC2。
Scripting
即脚本语言。包括很多,这里不多赘述。如mvel、js、python等。
Transport
代表ElasticSearch内部节点,代表跟集群的客户端交互。包括 Thrift、Memcached、Http等协议
RESTful Style API
通过RESTful方式来实现API编程。
3rd plugins
代表第三方插件。
Java(Netty)
是开发框架。
JMX
监控相关
9.2 Disvcovery源码走读
Elasticsearch 的发现模块应该算是保证Elasticsearch启动并正常工作最基本的模块了,可以这么理解,如果启动一个实例后,它连最基本的加入一个“组织”都失败的话那么它将无法提供服务。
9.2.3 实现方式
Elasticsearch的Discovery Module有下面几种实现:
- Azure Classic Discovery
- EC2 Discovery
- Google Compute Engine Discovery
- Zen Discovery
默认实现是ZenDiscovery,也是该节重点介绍的逻辑。
ZenDiscovery.java
模块的主类,也是启动这个模块的入口,由Node.java调用并初始化,几乎涵盖了全部的发现协议的逻辑,是一个高度内聚了类。
UnicastZenPing.java
是一个ZenPing 实现类,主要是负责底层和其他Nodes建立并维护连接的任务。
PublishClusterStateAction.java
在ZenDiscovery中的变量名是publishClusterState,之前讲过,这些**Action 都是对**Service的封装,因此它主要是用来处理发送事件和处理事件的接口,比如发送一个clusterStateChangeEvent 和处理这个event,都是通过这个类调用。
MasterFaultDetection.java
构建完cluster后所有的node用来检测master存活状态的类
NodeFaultDetection.java
构建完cluster后master用来检测其他node存活状态的类
9.2.4 选举Master
findMaster()选主函数
/**
* 选举主节点
* @return
*/
private DiscoveryNode findMaster() {
logger.trace("starting to ping");
// 向除了local节点发送ping指令
List |
hasEnoughCandidates 确认选取有足够多的候选人
/** * 如果有足够多的候选人 * @param candidates * @return */ public boolean hasEnoughCandidates(Collection |
electMaster 从候选人列表中选取master节点
/** * 从候选人列表中选取master节点 */ public MasterCandidate electMaster(Collection |
compare 候选人比较算法
/**
* 候选人比较算法
*/
public static int compare(MasterCandidate c1, MasterCandidate c2) {
// 先比较集群状态版本,注意c2在前,c1在后(优先以集群版本最大的为准)
int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);
if (ret == 0) {
// 如果版本号相同,则比较节点id
ret = compareNodes(c1.getNode(), c2.getNode());
}
return ret;
}
/**
* 比较节点
*/
private static int compareNodes(DiscoveryNode o1, DiscoveryNode o2) {
if (o1.isMasterNode() && !o2.isMasterNode()) {
return -1;
}
if (!o1.isMasterNode() && o2.isMasterNode()) {
return 1;
}
return o1.getId().compareTo(o2.getId());
} |
从activeMasters中选主
/** selects the best active master to join, where multiple are discovered */ public DiscoveryNode tieBreakActiveMasters(Collection |
节点加入master
/** * processes or queues an incoming join request. * |
9.2.5 流程图
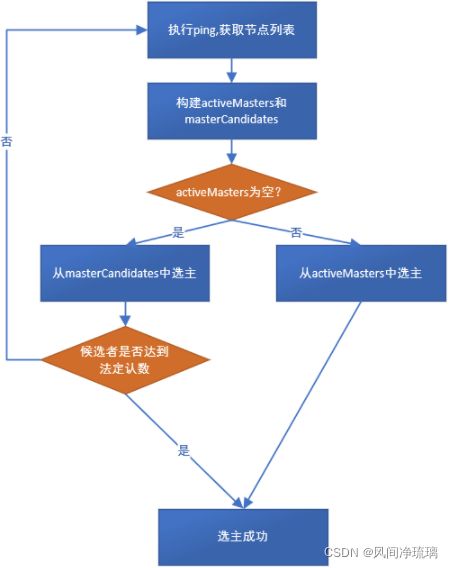
选举出的临时master有两种情况:该临时master是本节点或非本节点:
场景1:临时Master是本节点
-
等待足够多的具备master资格的节点加入本节点(投票达到法定人数),以完成选举。
- 超时(默认30S,可配置)后还没有满足数量的jion请求,则选举失败,需要进行新一轮选举。
- 成功后发布新的clusterState。
场景2:其他节点被选举为Master
- 不再接受其他节点的join请求
- 向master发送加入请求,并等待回复。超时时间默认1分钟(可配置),如果遇到异常,则默认重试3次(可配置)。这个步骤在joinElectedMaster中实现。
- 最终当选的master会选发布集群状态,才确认客户的join请求。因此joinElectMaster返回代表收到join请求的确认,并已经收到集群状态。本步骤检查收到的集群状态中的master节点如果为空,或者当选的master不是之前选择的节点,则重新选举。
10 中间件监控
elasticsearch的监控这里介绍两种,分别是用Elasticsearch_exporter + Prometheus + Grafana进行监控、用metricbeat+elasticsearch+kibana进行监控。
10.1 方案1:用Elasticsearch_exporter + Prometheus + Grafana进行监控
•安装elasticsearch_exporter,如elasticsearch_exporter-1.1.0.linux-amd64.tar.gz
•安装Prometheus,如prometheus-2.16.0.linux-amd64.tar.gz
•下载仪表盘配置,Grafana
•Prometheus监控告警连接钉钉、邮件、微信等工具,实时报警。
10.2 方案2:用metricbeat+elasticsearch+kibana进行监控
Metricbeat helps you monitor your servers and the services they host by collecting metrics from the operating system and services.
To get started with your own Metricbeat setup, install and configure these related products:
•Elasticsearch for storing and indexing the data.
•Kibana for the UI.
•Logstash (optional) for parsing and enhancing the data.
10.3 总结
- tp-link大量使用Prometheus + Grafana
- 使用一种监控方案,便于治理
- 本身不占用elasticseach资源存储监控指标
介于上面三种,建议选择第一种比较好。
11 轻量型数据采集器Beats
11.1 Beats定义
Beats 是一个免费且开放的平台,集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
11.2 常用Beats
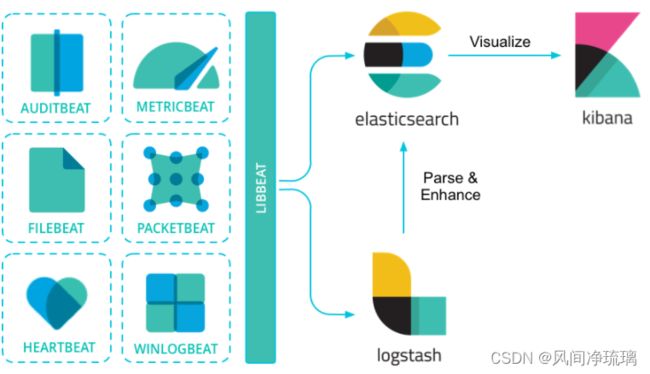
| 名称 |
含义 |
| AuditBeat | 审计数据 |
| FileBeat |
日志文件 |
| FuctionBeat | 云数据 |
| HeartBeat | 可用性数据 |
| JournalBeat |
系统日志 |
| MetricBeat | 指标数据 |
| PacketBeat |
网络流量数据 |
| Winlogbeat | Windows事件日志 |
11.3 logstash
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
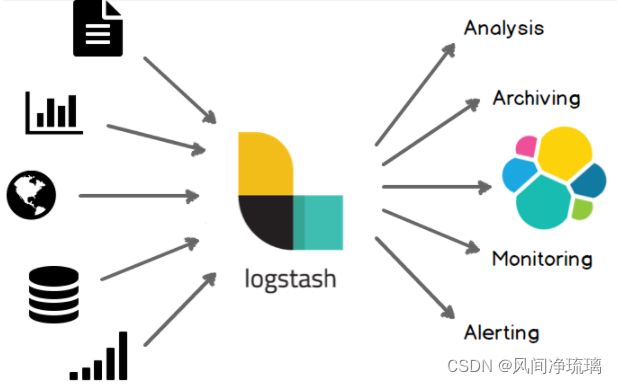
11.3.1 集中、转换和存储你的数据
Logstash是一个开源的服务器端数据处理管道,可以同时从多个数据源获取数据,并对其进行转换,然后将其发送到你最喜欢的“存储”。(当然,我们最喜欢的是Elasticsearch)
输入:采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
过滤器:实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 整体处理不受数据源、格式或架构的影响
输出:选择你的存储,导出你的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
12 常用方案说明
下面会讲解关于elasticsearch的常用方案。
12.1 ELK(Elasticsearch+Logstash+Kibana)
12.2 Elasticsearch结合Nebula Graph使用
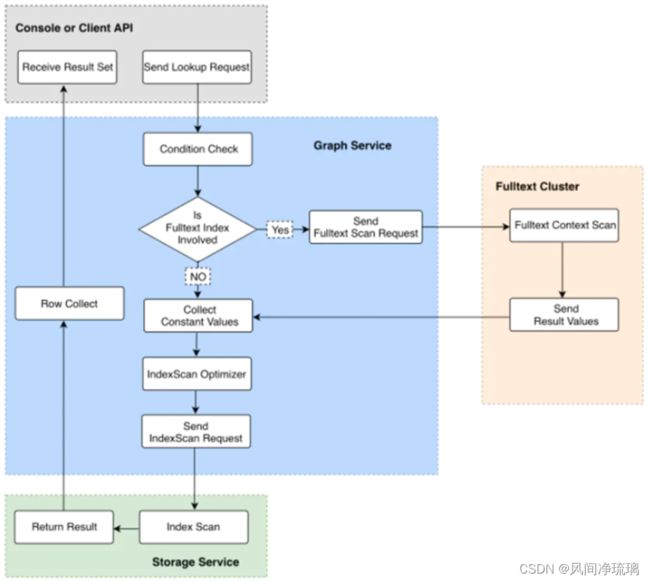
原因
Nebula Graph对某个prop 字段进行文本的模糊查询,都需要进行一个 full table scan 或 full index scan,然后逐行过滤,查询性能将会大幅下降。数据量大的情况下,很有可能还没扫描完毕就出现内存溢出的情况。
如果将 Nebula 索引的存储模型设计为适合文本搜索的倒排索引模型,那将背离 Nebula 索引初始的设计原则。术业有专攻,文本搜索的工作还是交给外部的第三方全文搜索引擎来做,在保证查询性能的基础上,同时也降低了 Nebula 内核的开发成本。
关键步骤
Send Fulltext Scan Request
根据查询条件、schema ID、Column ID 生成全文索引的查询请求(即封装成 ES 的 CURL 命令)
Fulltext Cluster
发送查询请求到 ES,并获取 ES 的查询结果。Collect Constant Values:将返回的查询结果作为常量值,生成 Nebula 内部的查询表达式。例如原始的查询请求是查询 C1 字段中以“A”开头的属性值,如果返回的结果中包含 “A1” 和 "A2"两条结果,那么在这一步,将会解析为 neubla 的表达式 C1 == "A1" OR C1 == "A2"。
IndexScan Optimizer
根据新生成的表达式,基于 RBO 找出最优的 Nebula 内部 Index,并生成最优的执行计划。在"Fulltext Cluster"这一步中,可能会有查询性能慢,或海量数据返回的情况,这里我们提供了 LIMIT 和 TIMEOUT 机制,实时中断 ES 端的查询。
12.3 Elasticsearch结合Mysql使用

Mysql保存原始数据,Elasticsearch做搜索引擎。
12.4 Elasticsearch结合Hbase使用
Elasticsearch+Hbase做海量数据检索。

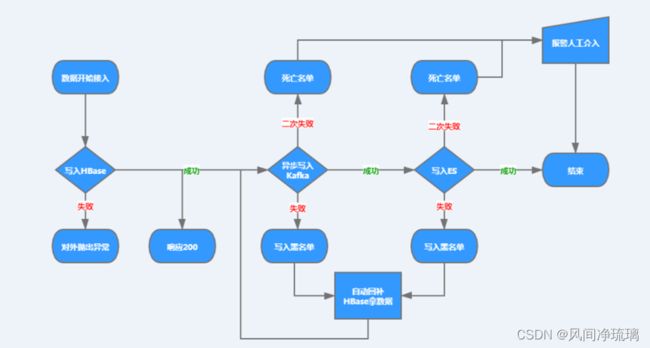
12.5 Elasticsearch在TAUC中业务日志使用
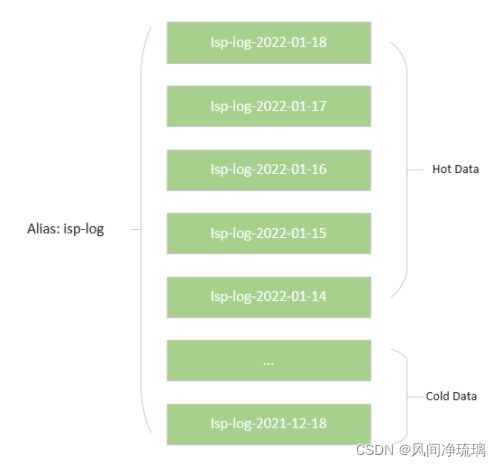
12.5.1 如何标记hot-cold节点?
elasticsearch节点配置文件打tag标记:
cold节点
- cold节点 [root@n3 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml cluster.name: elk node.master: false node.data: true node.name: 192.168.2.13 node.attr.box_type: cold path.data: /data/es network.host: 192.168.2.13 http.port: 9200 transport.tcp.port: 9300 transport.tcp.compress: true discovery.zen.ping.unicast.hosts: ["192.168.2.11"] cluster.routing.allocation.disk.watermark.low: 85% cluster.routing.allocation.disk.watermark.high: 90% indices.fielddata.cache.size: 10% indices.breaker.fielddata.limit: 30% http.cors.enabled: true http.cors.allow-origin: "*" |
hot节点
- hot节点 [root@n2 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml cluster.name: elk node.master: false node.data: true node.name: 192.168.2.12 node.attr.box_type: hot path.data: /data/es network.host: 192.168.2.12 http.port: 9200 transport.tcp.port: 9300 transport.tcp.compress: true discovery.zen.ping.unicast.hosts: ["192.168.2.11"] cluster.routing.allocation.disk.watermark.low: 85% cluster.routing.allocation.disk.watermark.high: 90% indices.fielddata.cache.size: 10% indices.breaker.fielddata.limit: 30% http.cors.enabled: true http.cors.allow-origin: "*" |
12.5.2 如何实现某索引数据写到指定的node?(根据节点tag即可)
创建一个template(这里我用kibana来操作es的api)
PUT _template/test
{
"index_patterns": "test-*",
"settings": {
"index.number_of_replicas": "0",
"index.routing.allocation.require.box_type": "hot"
}
} |
12.5.3 如何实现数据从hot节点迁移到老的cold节点?
kibana里操作:
PUT /test-2018.07.05/_settings
{
"settings": {
"index.routing.allocation.require.box_type": "cold"
}
} |
12.5.4 凌晨冷热数据批跑
每天晚上将过期的热数据转移到冷数据节点。
参考文献:
Elasticsearch Guide [7.16] | Elastic
Java REST Client [7.15] | Elastic