强化学习路线规划之深度强化学习代码
虽然说很多代码都有问题,但是不管它们,我不是为了去debug,紧盯住自己的目标,目标是整理出一条通常的强化学习之路,让自己以及看到这些博客的大家在学习的时候能够少走一些弯路。所以从q-learning和Sarsa开始,这些基础代码不需要借助框架,所以没什么太大问题。但是深度学习的话就要借助TensorFlow或者pytorch框架,而这两个框架都分别出了两个版本,就导致前后的兼容性较差,前人的经验工作无法得到有效的利用。
Deep-Reiforcement-Learning之debug旅程
我找了许多的学习代码,但是很多经常不能使用,但是我也花费了许多功夫,所以现在我想直接把对这些代码的debug过程记录下来。好了,话不多说,下面看着这么多的代码,又有几个能用的呢?测试一下吧
果不其然,运行code6-2
C:\Users\admin\AppData\Local\Programs\Python\Python37\lib\site-packages\gym\envs\registration.py:556: UserWarning: WARN: The environment CartPole-v0 is out of date. You should consider upgrading to version `v1`.
f"The environment {id} is out of date. You should consider "
C:\Users\admin\AppData\Local\Programs\Python\Python37\lib\site-packages\numpy\lib\shape_base.py:591: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
a = asanyarray(a)
Traceback (most recent call last):
File "C:/Python program/Deep-Reiforcement-Learning-main/code/Code6/code6-2 DQN-2015算法求解倒立摆问题代码.py", line 220, in <module>
agent.train() #训练智能体
File "C:/Python program/Deep-Reiforcement-Learning-main/code/Code6/code6-2 DQN-2015算法求解倒立摆问题代码.py", line 145, in train
action = self.egreedy_action(state)
File "C:/Python program/Deep-Reiforcement-Learning-main/code/Code6/code6-2 DQN-2015算法求解倒立摆问题代码.py", line 70, in egreedy_action
state = torch.from_numpy(np.expand_dims(state,0))
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.
大概就是环境不对,好,改成v1
再运行
C:\Users\admin\AppData\Local\Programs\Python\Python37\lib\site-packages\numpy\lib\shape_base.py:591: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
a = asanyarray(a)
Traceback (most recent call last):
File "C:/Python program/Deep-Reiforcement-Learning-main/code/Code6/code6-2 DQN-2015算法求解倒立摆问题代码.py", line 220, in <module>
agent.train() #训练智能体
File "C:/Python program/Deep-Reiforcement-Learning-main/code/Code6/code6-2 DQN-2015算法求解倒立摆问题代码.py", line 145, in train
action = self.egreedy_action(state)
File "C:/Python program/Deep-Reiforcement-Learning-main/code/Code6/code6-2 DQN-2015算法求解倒立摆问题代码.py", line 70, in egreedy_action
state = torch.from_numpy(np.expand_dims(state,0))
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, complex64, complex128, int64, int32, int16, int8, uint8, and bool.
Process finished with exit code 1
依然错误,好我再修改
state = torch.from_numpy(np.expand_dims(state, 0)).float()
然后运行,还是错误
然后运行其他的代码,也没有一个能跑的,算了
Reinforcement-learning-with-tensorflow代码debug之旅
差点忘了,这个前几天刚debug过,里面深度强化学习的代码基本上都由于版本问题无法跑起来,放弃
pytorch-tutorial代码debug之旅,这个代码看起来也挺全的,但是就不知道能不能跑
太好了,终于遇见一个能打的了,也感恩pytorch,TensorFlow实在是非常坑,我是一百个不愿意用它
作图,matplotlib的使用
import torch
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
x=torch.linspace(-5,5,200)
x=Variable(x)
x_np=x.data.numpy()
y_relu=torch.relu(x).data.numpy()
y_sigmoid=torch.sigmoid(x).data.numpy()
y_tanh=torch.tanh(x).data.numpy()
y_softplus=F.softplus(x).data.numpy()
#画图
plt.figure(1,figsize=(8,6))
plt.subplot(221)
plt.plot(x_np,y_relu,c='red',label='relu')
plt.ylim((-1,5))
plt.legend(loc='best')
plt.subplot(222)
plt.plot(x_np,y_sigmoid,c='red',label='relu')
plt.ylim((-0.2,1.2))
plt.legend(loc='best')
plt.subplot(223)
plt.plot(x_np,y_tanh,c='red',label='tanh')
plt.ylim((-1.2,1.2))
plt.legend(loc='best')
plt.subplot(224)
plt.plot(x_np,y_softplus,c='red',label='softmax')
plt.ylim((-0.2,6))
plt.legend(loc='best')
plt.show()
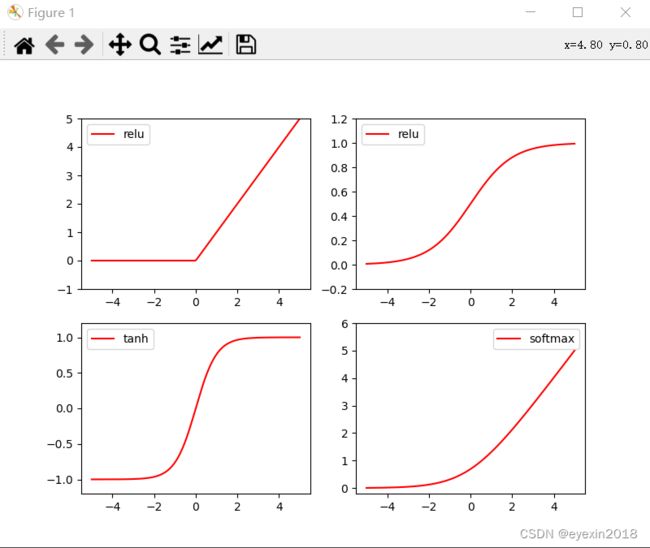
神经网络还必须得GPU才能跑
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
import os
log_dirs="logs/regre"
writer=SummaryWriter(log_dir=log_dirs)
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
self.predict = torch.nn.Linear(n_hidden, n_output) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x
net = Net(n_feature=1, n_hidden=10, n_output=1) # define the network
print(net) # net architecture
optimizer = torch.optim.SGD(net.parameters(), lr=0.2)
loss_func = torch.nn.MSELoss() # this is for regression mean squared loss
plt.ion() # something about plotting
for t in range(200):
prediction = net(x) # input x and predict based on x
loss = loss_func(prediction, y) # must be (1. nn output, 2. target)
optimizer.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
writer.add_scalar("Loss",loss)
if t % 5 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
writer.close()
plt.ioff()
plt.show()
上面是一个用神经网络的回归代码,我又添加了tensorboard查看网络的代码,结果如下:
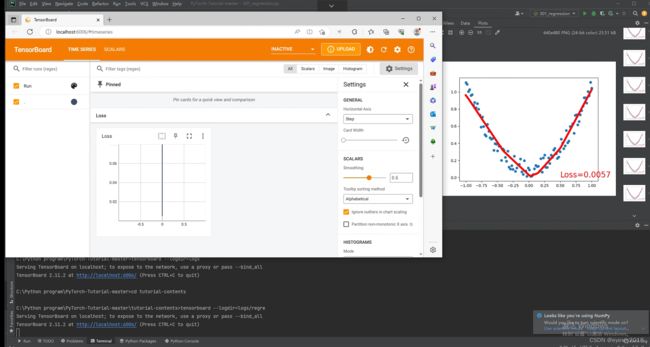
pytorch中使用tensorboard的方法
1.导入所需的库:
from torch.utils.tensorboard import SummaryWriter
2.创建一个SummaryWriter对象:
writer = SummaryWriter()
3.在训练过程中,将需要记录的指标(例如损失、准确率等)写入到SummaryWriter对象中:
# 在训练循环中,例如每个epoch或每个iteration
writer.add_scalar('Loss', loss, global_step)
writer.add_scalar('Accuracy', accuracy, global_step)
4.在训练完成后,关闭SummaryWriter对象:
writer.close()
5.启动TensorBoard服务器:
在终端中,使用以下命令在指定的目录中启动TensorBoard服务器:
tensorboard --logdir=logs
6.在浏览器中查看TensorBoard的可视化结果:
打开浏览器,访问TensorBoard服务器的地址(默认是http://localhost:6006),即可查看训练过程和模型性能的可视化结果。
logs是一个目录路径,你可以在你的代码中自行定义。它用于存储TensorBoard日志文件和事件文件,供TensorBoard服务器读取并进行可视化。
通常,你可以将logs目录定义为你项目的根目录下的一个子目录,或者在任意合适的位置创建一个新的目录。在定义logs路径时,你可以使用绝对路径或相对路径。
以下是一个示例,将logs目录定义为项目根目录下的子目录:
logs_dir = os.path.join(os.getcwd(), 'logs')
writer = SummaryWriter(log_dir=logs_dir)
OK了