Elasticsearch的介绍和基本语法
1 、Elasticsearch介绍
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
2、基本概念
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
用Mysql这样的数据库存储就会容易想到建立一张User表,有balabala的字段等,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
3、 Elasticsearch的功能、使用场景以及特点
3.1、Elasticsearch的功能
(1)分布式的搜索引擎和数据分析引擎
搜索:百度,网站的站内搜索,IT系统的检索
数据分析:电商网站,最近7天牙膏这种商品销量排名前10的商家有哪些;新闻网站,最近1个月访问量排名前3的新闻版块是哪些
(2)全文检索,结构化检索,数据分析
全文检索:我想搜索商品名称包含牙膏的商品,select * from products where product_name like "%牙膏%"
结构化检索:我想搜索商品分类为日化用品的商品都有哪些,select * from products where category_id='日化用品'
部分匹配、自动完成、搜索纠错、搜索推荐
数据分析:我们分析每一个商品分类下有多少个商品,select category_id,count(*) from products group by category_id
(3)对海量数据进行近实时的处理
分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索
海量数据的处理:分布式以后,就可以采用大量的服务器去存储和检索数据,自然而然就可以实现海量数据的处理了
近实时:检索个数据要花费1小时(这就不要近实时,离线批处理,batch-processing);在秒级别对数据进行搜索和分析
跟分布式/海量数据相反的:lucene,单机应用,只能在单台服务器上使用,最多只能处理单台服务器可以处理的数据量
3.2、Elasticsearch的适用场景
国外
(1)维基百科,类似百度百科,牙膏,牙膏的维基百科,全文检索,高亮,搜索推荐
(2)The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
(3)Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
(4)GitHub(开源代码管理),搜索上千亿行代码
(5)电商网站,检索商品
(6)日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
(7)商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
(8)BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,**区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘,Kibana进行数据可视化国内
(9)国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景
2.3、Elasticsearch的特点
(1)可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上,服务小公司
(2)Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;lucene(全文检索),商用的数据分析软件(也是有的),分布式数据库(mycat)
(3)对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES,就可以作为生产环境的系统来使用了,数据量不大,操作不是太复杂
(4)数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);特殊的功能,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;Elasticsearch作为传统数据库的一个
4、 Elasticsearch下载安装及运行
4.1
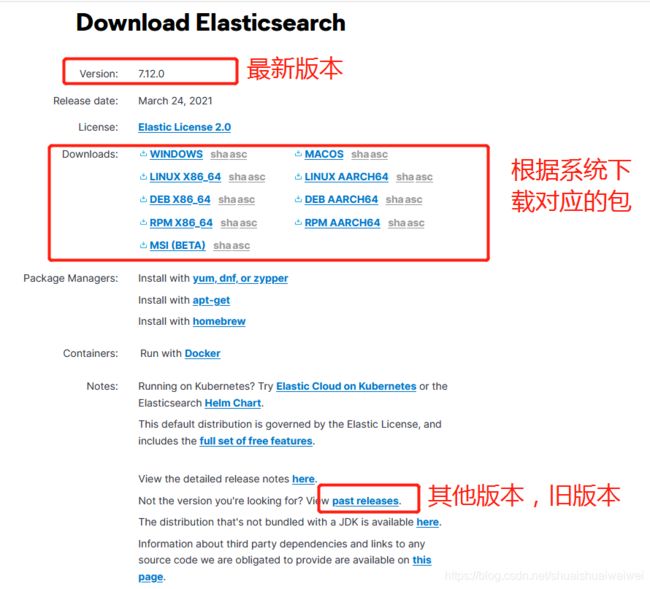
官网地址:https://www.elastic.co/cn/products/elasticsearch
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
4.2安装
Elasticsearch无需安装,解压即用。
4.3 运行
进入elasticsearch/bin目录,可以看到下面的执行文件:
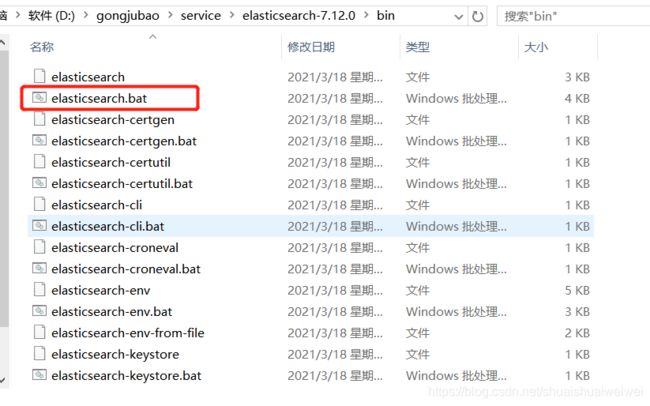
双击elasticsearch.bat文件运行

可以看到绑定了两个端口:
- 9300:Java程序访问的端口
- 9200:浏览器、postman访问的端口
我们在浏览器中访问:http://127.0.0.1:9200
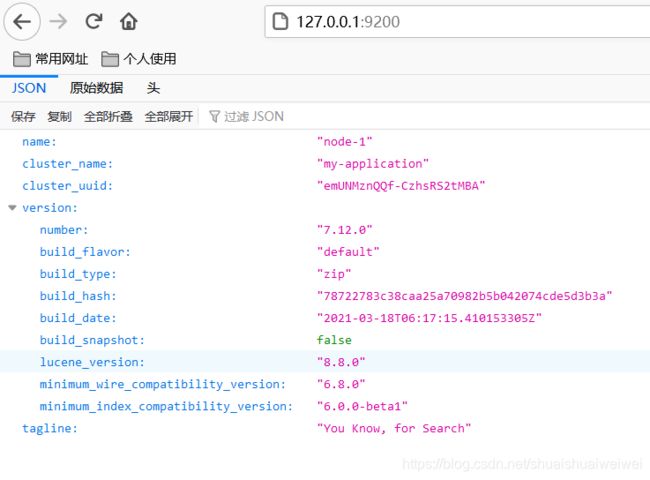
看到了上面的信息,说明你的Elasticsearch已经安装成功了。
5、 Elasticsearch的配置
Elasticsearch有三个配置文件,分别是elasticsearch.yml、jvm.options和log4j2.properties.分别用来配置elasticsearch,elasticsearch的jvm和日志。
5.1 elasticsearch.yml文件
基础配置,示例配置内容如下:
cluster.name: my-application #集群名称,相同集群名称的节点会自动加入到该集群
node.name: node-1 #节点名称
path.data: /data/es/data #节点数据存储路径
path.logs: /data/es/logs #节点日志存储路径
node.master: true #配置节点是否能成为master。默认所有节点都是true,建议只一台配置true,其他为False
node.data: true #配置该节点是否能存储数据,默认为true,推荐把主节点设置为false
network.host: 127.0.0.1 #修改为节点IP,建议配置为内网地址,一定不能配置0.0.0.0,会导致信息泄露
http.port: 9200 #ES端口
cluster.initial_master_nodes: ["node-1"]6、Elasticsearch集群部署
新增另一个es配置
cluster.name: my-application #集群名称,相同集群名称的节点会自动加入到该集群
node.name: node-2 #节点名称
path.data: /data/es/data2 #节点数据存储路径
path.logs: /data/es/logs #节点日志存储路径
node.master: true #配置节点是否能成为master。默认所有节点都是true,建议只一台配置true,其他为False
node.data: true #配置该节点是否能存储数据,默认为true,推荐把主节点设置为false
network.host: 127.0.0.1 #修改为节点IP,建议配置为内网地址,一定不能配置0.0.0.0,会导致信息泄露
http.port: 9201 #ES端口
cluster.initial_master_nodes: ["node-1","node_2"]需要修改http.port端口和node.name节点名称,不修改端口es会自己寻找可用的端口
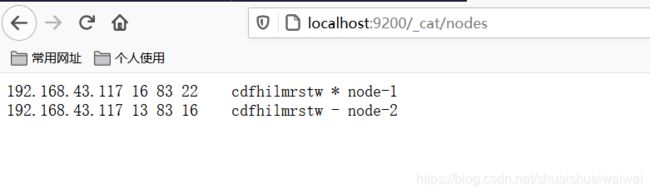
配置完成后同样双击bat启动es,启动成功后可通过一下api查看集群节点
7、Elasticsearch常用术语与CRUD实际操作
7.1、常用术语
Document 文档类型(理解为实体)
Index 索引 (理解为数据库)
Type 索引中的数据类型 (理解为数据库中的表)
Field 字段,文档的属性
Query DSL 查询语法
7.2 Elasticsearch CRUD(增删改查)
Create 创建文档
POST usertest/person/1?pretty=true
{
"name": "张三",
"age": "20",
"sex": "男",
"tel": "111"
}
Read 读取文档
GET usertest/person/1
Update 更新文档
POST usertest/person/1/_update
{
"doc":{
"name": "李四"
}
}Delete 删除文档
DELETE usertest/person/1
再次查询时返回:
{
"_index" : "usertest",
"_type" : "person",
"_id" : "1",
"found" : false
}found 值为true 代表找到数据了,为false代表找不到数据
7.3、Elasticsearch Query String
基本语法:
GET /test_index/test_type/_search?q=test_field:test
GET /test_index/test_type/_search?q=+test_field:test(必须包含)
GET /test_index/test_type/_search?q=-test_field:test(不包含)示例:所有字段中带有赵六的数据
GET usertest/person/_search?q=赵六
示例:name字段中带有赵六的数据
GET usertest/person/_search?q=name:赵六示例:name字段中不包含赵六的数据
GET usertest/person/_search?q=-name:赵六
7.4、Elasticsearch DSL
查询DSL
Elasticsearch提供了基于JSON的完整查询DSL(特定于域的语言)来定义查询。将查询DSL视为查询的AST(抽象语法树),它由两种子句组成:
叶子查询子句
叶查询子句中寻找一个特定的值在某一特定领域,如 match,term或 range查询。这些查询可以自己使用。
复合查询子句
复合查询子句包装其他叶查询或复合查询,并用于以逻辑方式组合多个查询(例如 bool或dis_max查询),或更改其行为(例如 constant_score查询)。
查询子句的行为有所不同,具体取决于它们是在 查询上下文中还是在过滤器上下文中使用。
查询与过滤
查询子句的行为取决于在查询上下文中还是在过滤器上下文中使用它:
DSL 查询根据使用目的的不同分为两种类型:
上下文查询(Query context),简称查询
上下文过滤(Filter context),简称过滤
使用频繁的过滤语句的结果集会被 Elasticsearch 自动缓存,以提高性能。
每当将查询子句传递到filter 参数(例如查询中的filter或must_not参数, bool查询中的filter参数 constant_score或filter聚合)时, 过滤器上下文即有效。
此查询将匹配满足以下所有条件的文档:
- 该
title字段包含单词search。 - 该
content字段包含单词elasticsearch。 - 该
status字段包含确切的单词published。 - 该
publish_date字段包含从2015年1月1日开始的日期。
GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}匹配所有查询
GET _search
{
"query": {
"match_all": {}
}
}不匹配查询
这是match_all查询的反函数,不匹配任何文档。
GET _search
{
"query": {
"match_none": {}
}
}匹配查询
注意,name是字段的名称,您可以替换任何字段的名称。
GET usertest/person/_search
{
"query":{
"match":{
"name":"赵六"
}
}
}
模糊性
name为需要查询的字段,query为查询条件,operator 值为 or代表或者,为and 代表并且
GET usertest/person/_search
{
"query":{
"match": {
"name":{
"query":"王五 赵六","operator":"or"
}
}
}
}多条件查询
搜索需求:name必须包含张三,tel可以包含12也可以不包含,age必须不为20
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "张三"
}
}
],
"should": [
{
"match": {
"tel": "12"
}
}
],
"must_not": [
{
"match": {
"age": 20
}
}
]
}
}
}
其他更多详细查询语法请查看官方文:https://www.elastic.co/guide/en/elasticsearch/reference/6.3/query-dsl.html