node.js 教程(更新完毕)
一、安装
1、去官网下载下来点击安装即可
node -v
出现相关信息,即证明安装成功
2、在node中执行文件
新建一个web-server.js文件
var http = require('http');
var serv = http.createServer(function (req,res) {
res.writeHead(200,{'Content-Type':'text/html'});
res.end('');
});
serv.listen(3000)
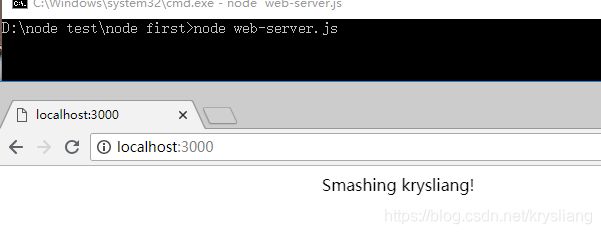
上面代码表示创建了一个http服务器托管一个简单的html文档。并且监听3000断开。
在命令行中执行该文件
node web-server.js
然后在浏览器中输入localhost:3000,就可以看到下面的页面。
二、node.js中的JavaScript基础知识
这个部分分为两个部分,一部分是JavaScript基础(这部分我只会记一些我不太懂的,很基础的麻烦大家自己另外学习),一部分是V8中的JavaScript。
1、什么是V8?
V8 是 Google 开发的开源的 JavaScript 引擎,用于 Google Chrome 及 Chromium 中。
也就是说V8中的JavaScript的某些特性并不是所有浏览器都会支持。
2、函数中有一个属性length,此字段用来记录函数参数的个数。比如
function a(b,c) {}
console.log(a.length)//2
一些node.js的框架就是通过此属性来根据不同的参数个数提供不同的功能的。
3、reduce方法
刚开始觉得这个方法就是一个累加器,将数组中的值全部加起来,比如下面的用法
let arr = [2098,6679,45687,2340]
let reducer = function (prev,next) {
return prev+next
}
let total = arr.reduce(reducer,0)//表示初始值为0
console.log(total)//56804
其中reduce接收两个参数,第二个参数为可选的。第一个参数为必须的。
其第一个参数为一个函数,这个函数拥有下面四个参数
-
previousValue上一次函数执行返回的结果
-
currentValue当前元素的值
-
index当前元素的索引值
-
array调用reduce的数组
4、_proto_指向创建该对象的构造函数的原型。
比如,这样Dog就继承了Animal了。
function Animal(){}
function Dog(){}
Dog.prototype._proto_ = Animal.prototype
let Arr = {}
console.log(Arr.__proto__ == Object.prototype)//true
三、阻塞和非阻塞IO
1、了解一个概念
node.js是单线程的,也就是说服务器中无论有多少个请求,也是由一个主线程去处理的,所以如果在某些时候改变了全局变量的值,那么会影响之后请求的处理结果的。所以一定要慎重!
2、阻塞与非阻塞
看下面的php的代码以及对应的js的代码
print('hello')
sleep(5)
print('world')
console.log('hello')
this.timer = setTimeout(funtion(){console.log('world)},5000)
console.log('hhh')
这两段代码中,php中遇到了sleep(5)阻塞了进程的执行,也就是说进程在这里暂停了后面的代码不会继续执行,除非过了5秒。
而第二段代码中,因为事件轮询,且setTimeout是非阻塞的,所以后面的代码也会执行的。
而什么是事件轮询呢?从本质上来说,node会先注册事件,随后不停的去询问内核这些事件是否已经分发。当事件分发时,对应的回调函数就会被触发,然后继续执行下去。如果事件没有触发,则会继续执行其他代码,直到有新事件时再去执行对应的回调函数。
也就是说setTimeout仅仅只是注册了一个事件,而程序继续执行。所以这是异步的。相反,php的sleep是 同步的。
node的并发实现也采用了事件轮询,与timeout一样,所有像http、net这样的原声模块中的IO部分也都采用了事件轮询技术。node使用事件轮询,触发一个和文件描述符相关的通知。
文件描述符是抽象的句柄、存有对打开的文件、socket、管道等的引用。本质上说。当node接收到从浏览器发送的http请求的时候,底层的tcp连接会分配一个文件描述符。随后,如果客户端向服务器发送数据,node就会收到该文件描述符上的通知,然后触发JavaScript的回调函数。
3、刚刚说过,node.js是单线程的。所以在引入事件轮询的时候,对应的事件触发不一定会准时执行。
比如
var start = new Date()
setTimeout(function () {
console.log(new Date() - start)
for (var i = 0;i<1000000000;i++){}
},1000)
setTimeout(function () {
console.log(new Date() - start)
},2000)
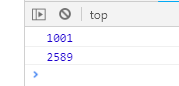
可以看到这两个timeout事件都不是准时的,这是因为这两个事件都是在执行完主事件之后才去执行的,而第一个timeout,因为有一个很大的for循环,故会影响后一个timeout事件触发的时间。因此,JavaScript的timeout并不能严格遵守时钟设置。
所以很多优秀的node模块都不会采取类似于这样阻塞的方式(很大的for),执行任务也都采取了异步的方式。
四、node中的JavaScript
(一)global对象
在浏览器中,全局对象指的就是window对象。在window对象上定义的任何内容都可以被全局访问到。比如,setTimeout其实就是window.setTimeout,document其实是window的document。
而node中的有两个类似的代表着全局的的对象,
-
global:跟window类似,任何global对象的属性都可以被全局访问到。
-
process,所有全局执行上下文中的内容都在process对象。在node中,只有一个process对象。进程的名字是process.title。
1、process.nextTick,这个函数可以将一个函数的执行时间规划到下一个事件循环中:
console.log(1);
process.nextTick(function(){
console.log(3)
});
console.log(2);
可以把它看做,在执行完当前的其它代码,然后再执行指定的函数。
其实就等于下面这样的代码
console.log(1);
setTimeout(function(){
console.log(3)
},0);
console.log(2);
通过异步的方法在最近的将来调用指定的函数。
(二)、模块系统(这里不懂可以看我的另外一篇文章从模块化开始到webpack入门)
node引入了一种模块系统,该模块系统有三个核心的全局对象:require、module、exports
1、绝对和相对模块
绝对模块是只在node内部的node_modules这里查找的模块,或者是node内置的http这样的模块,绝对模块可以直接通过名字来require这个模块,无须添加路径名。
var http = require('http');
相对模块就是自定义的文件,比如同目录下的modulea.js文件就要像这样引入
require('./modulea.js')
2、暴露API
在模块内部使用exports来暴露模块内部的内容,将需要暴露的内容,赋给exports对象。
exports其实就是对module.exports的引用,默认情况下是一个对象。
比如modulea.js内部
exports.name = 'krysliang'
var age = 22
exports.getAge = () =>{
return age
}
或者像下面这样,将整个对象赋给module.exports
module .exports = {
name:'krysliang',
age:'22',
getAge:()=>{
return this.age
}
}
那么在index.js中就可以像下面这样使用
var modulea =require('./modulea.js')
console.log(modulea.name)
console.log(modulea.getAge())
还可以像下面这样
//module_a.js
function krysliang() {
this.name = 'krysliang'
}
krysliang.prototype.getAge = function () {
console.log('我的年龄是',22)
}
krysliang.prototype.getName = function () {
console.log('我的名字是',this.name)
}
module.exports = krys
//index.js
var Krysliang =require('./module_a.js')
var lwl = new Krysliang()
lwl.getName()
lwl.getAge()
![]()
这就是典型的OOP写法了。
(三)、事件
node.js中基础的API之一就是EventEmitter,也就是事件分发器,用它来分发事件处理,就是相当于一个监听器。node暴露了 Event EmitterAPI,在该API中定义了on、emit以及removeListener方法。它以process.EventEmitter形式暴露出来
var EventEmitter = require('events').EventEmitter,a = new EventEmitter();
a.on('event',()=>{console.log('事件被触发啦')})
a.emit('event')
事件是Node非阻塞设计的重要体现。node通常不会直接返回数据(因为这样可能会在等待某个资源的时候发生线程阻塞),而是采用分发事件来传递数据。
比如像HTTP服务,当请求到达的时候,Node会调用一个回调函数,这个时候数据有可能还没有完全到达
http.Server(funtion(req,res){
var buf = '';
req.on('data',funtion(){buf+=data })
req.on('end'.funtion(){ console.log('数据接收完毕')})
})
将请求数据内容进行缓存(data事件),等到所有数据都接收完毕后(end事件)在对数据进行处理。不管是否所有的数据都已经到达,node为了让你尽快知道请求已经到达服务器,都需要分发事件出来。
有些API会分发error事件。
不管某事件在将来会被触发多少次,我都希望只调用一次回调函数,这样的分发方法叫做once,比如
a.once('某个事件',function(){
})
(四)buffer
buffer是一个表示固定内存分配的全局对象(也就是说,要放到缓冲区中的字节数需要提前定下),可以有效在JavaScript中表示二进制数据。
该功能的一部分中功能就是可以对数据进行编码转换。
比如
var myBuffer = new Buffer('==iiij2i3h1i23h','base64');
将第一个数据作为base编码方式进行缓存
五、Node中重要的API。
node通过回调和事件机制来实现并发。
构建一个简单的命令行文件浏览器,其功能是允许用户读取和创建文件。
需求:
(1)程序需要在命令行运行,也就是程序要么通过node命令来执行或者是直接执行后通过终端提供交互给用户进行输入输出。
(2)程序启动后,需要显示当前目录下列表
(3)选择某个文件时,程序需要显示该文件内容。
(4)选择一个目录时,程序需要显示该目录下的信息
(5)运行结束后,程序退出。
步骤
(1)创建模块
(2)决定采用同步的fs还是异步的fs
(3)理解什么是流(stream)
(4)实现输入输出
(5)重构
(6)使用fs进行文件交互
(7)完成
1、创建模块
在文件目录下面创建一个package.json的文件,然后执行npm install
{
"name": "file-explorer",
"version": "0.0.1",
"description": "a command-file file explorer"
}

2、fs模块
需要注意的是,在node中,唯一一个提供同步和异步Api的模块就是fs模块。
比如,获取当前目录的文件列表中,同步的方法是readdirSync,异步的方法是readdir
//同步
console.log(require('fs').readdirSync(__dirname))
//异步
require('fs').readdor('.',async)
首先在node.js中, 标准的输入/输出管理模块stdioApi是全局对象process的一部分,所以在这里我们唯一的依赖就是fs模块,
//引入fs模块
var fs = require('fs')
为了获取文件列表,采用fs.readdir(此处采用异步)
fs.readdir(__dirname,function (err,files) {
//回调函数中的files是一个数组,用来显示当前目录下的文件列表
console.log(files)
})
然后执行文件,可以看到,当前目录下的文件名被打印出来。

3、理解什么是流
console.log会输出到控制台,事实上,console.log内部做了这样的事情:它在指定的字符串后面加上\n换行符,并将其写到stdout流中。
console.log可以使用process.stdout.write来替代,但是需要注意的是。process.stdout.write是不会在原来的字符串后面加上换行符的。
process全局对象中包含了三个流对象,分别对应三个UNIX标准流
-
stdin标准输入(可读流)
-
stdout标准输出(可写流)
-
stderr标准错误(可写流)
stdin流默认的状态是paused(暂停的。
此外,流的另一个属性是它默认的编码,如果在流上面设置了编码,那么就会得到编码后的字符串而不是原始的Buffer作为事件参数。
在node中,会接触到各种类型的流,比如TCP套接字、http请求等。简而言之,当涉及持续不断地对数据进行读写的时候,流就出现了。
4、输入和输出
这里用到的输入输出函数有如下几个
stdout.write(' \033[33mEnter your choice: \033[39m');//输出
stdin.resume();//等待命令行输入
stdin.setEncoding('utf8');//设置编码
stdin.on('data',option);//监听数据的输入,然后会调用回调函数
stdin.pause();//退出输入
//引入fs模块
var fs = require('fs'),stdin = process.stdin,stdout=process.stdout;
fs.readdir(process.cwd(),function (err,files) {
//回调函数中的files是一个数组,用来显示当前目录下的文件列表
// console.log(files)
if (!files.length){
//如果当前目录下面没有文件,则返回并告知没有文件可以选择
return console.log(' \033[31m No files to show!\033[39m\n');
}
console.log(' Select which file or directory you want to see \n');
var stats = [];
function file(i) {
var filename = files[i];
//fs.stat会给出文件或者目录的元数据
fs.stat(__dirname+'/'+filename,function (err,stat) {
stats[i] = stat;
if (stat.isDirectory()){
console.log(' '+i+' \033[36m]'+filename+'/\033[39m');
}else {
console.log(' '+i+' \033[90m'+filename+'\033[39m');
}
if (++i == files.length){
read();
}else {
file(i);
}
});
}
function read() {
console.log('');
stdout.write(' \033[33mEnter your choice: \033[39m');//输出
stdin.resume();//等待命令行输入
stdin.setEncoding('utf8');//设置编码
stdin.on('data',option);//监听数据的输入,然后会调用回调函数
}
function option(data) {
var filename = files[Number(data)];
if (!filename){
stdout.write(' \033[33mEnter your choice: \033[39m');
}else {
stdin.pause();//退出输入
//如果是目录则读出目录下面的文件,如果是文件则输出文件内容
if (stats[Number(data)].isDirectory()){
fs.readdir(__dirname+'/'+filename,function (err,files) {
console.log('');
console.log(' ('+files.length+')'+files);
files.forEach(function (file) {
console.log(' - '+file);
});
console.log('');
})
}else {
fs.readFile(__dirname+'/'+filename,'utf8',function (err,data) {
console.log('');
console.log('\033[90m'+data.replace(/(.*)/g,' $1')+'\033[93m');
})
}
}
}
file(0)
});
5、一些命令行常用的变量
(1)argv,process.argv包含了所有node程序运行时的参数值。
(2)工作目录
使用__dirname来获取当前文件在文件系统下的路径,而使用process.cwd来获取程序运行时的当前工作目录,还可以使用process.chdir('路径')来改变当前工作的目录。
(3)环境变量
node允许通过proces.env变量来轻松访问shell环境下的变量。使用NODE_ENV来控制程序是运行在开发模式下还是产品模式下。
(4)让应用退出使用process.exit()并提供一个错误信息,比如
当发生错误的时候,要退出程序,这个时候最好是使用退出代码1
console.error('an error occurred');
process.exit(1)
(5)信号,进程和操作系统进行通信的其中一种方式就是通过信号。比如,要让进程终止,可以发送SIGKILL信号。
node是通过在process对象上以时间分发的形式来发送信号的
process.on('SIGKILL',function(){
//进程杀掉的信息已收到
})
(6)ANSII转义码
要在文本终端下控制格式、颜色以及其他输出选项,可以使用ANSI转义码。
在文本周围添加的明显不用于输出的字符,成为非打印字符。
console.log('\033[90m'+data+'\033[39m);
在这里,\033代表转义序列的开始,[表示开始颜色设置,90表示前景色为亮灰色,m表示颜色设置结束,最后使用39表示将颜色再设置回去。
6、stream
使用fs.readFile这个函数的时候,回调函数必须要等到整个文件读取完毕,载入到RAM中、可用的情况下才会触发。
而使用stream,每次会读取可变大小的内容块,并且每次读取完毕后会触发回调函数。比如
var stream = fs.createReadStream('file.txt');
stream.on('data',function(chunk){
// c处理一部分的文件
})
stream.on('end',function(){
//读取完毕
})
7、监视
node允许监视文件或者目录是否发生变化。监视意味着,当文件系统中的文件(或则目录)发生变化的时候,会分发一个事件,然后触发指定的回调函数。
六、TCP(稍后会开一个详解TCP的系列再仔细了解TCP)
TCP是一个面向连接的协议,它保证了两台计算机之间数据传输的可靠性和顺序,换句话说,TCP是一种传输层协议,它可以让你将数据从一台计算机完整有序地传输到另一台计算机。
Node HTTP服务器是构建于Node TCP服务器之上的,也就是说Node中的http.Server继承自net.Server(net是TCP模块)
TCP有如下几个特征
(1)面向字节:TCP对字符以及字符编码是完全无知的,所以TCP会允许数据以ASCII字符(一个字符一个字节)或者是Unicode(每个字符四个字节)进行传输,这使得TCP有很好的灵活性
(2)可靠性,TCP有一些列确认和超时实现的机制来实现可靠性的要求。
当数据发送出去,发送方就会等到一个确认消息(表示数据包已经收到的简短的确认消息),如果在指定的窗口时间还没有收到确认消息,发送方就会对数据进行重发。这种机制有效的解决了很多不可预测的网络出错的情况。
(3)流控制:TCP通过一种叫做流控制的方式来确保两点之间传输数据的平衡。
(4)拥堵控制:TCP有一种内置的机制能够控制数据包的延迟率以及丢包率不会太高,以此来确保服务的质量。举例来说,和流控制能够避免发送方压垮接收方一样,TCP会通过控制数据包的传输速率来避免拥堵的情况。
1、套接字Socket=ip:端口、
2、基于TCP的聊天程序
下面来创建一个基本的TCP服务器,任何人都可以连接到该服务器,无须实现任何协议或者指令:
-
成功连接到服务器后,服务器会显示欢迎信息,并要求输入用户名。同时还会告诉你当前还有多少其他客户端也连接到了该服务器。
-
输入用户名,按下回车键,就认为成功连接上了。
-
连接后就可以通过输入信息再按下回车键,来向客户端进行消息的收发。
按下回车键是因为Telnet中输入的任何信息都会立刻发送到服务器。按下回车键是为了输入\n字符。在node服务器端中,通过\n来判断消息是否已完全到达。所以,这其实是作为一个分隔符在使用。
var net = require('net');
var count = 0;//连接数
var user = [];//连接的用户
/**
* 创建tcp服务器,每次有新的链接建立的时候都会执行后面的回调函数.createServer回调函数会接收一个对象,该对象是node中很常见的实例:流,在
* 这里,它传递的是net.stream。
*/
var server = net.createServer(function (conn) {
conn.write(
'\n>Welcome to krys-node-chat'+ '\n > '+count +'other people are connected at this time'+ '\n> please write your name and press enter'
)
var nickname;//当前连接的用户名
count++;
conn.on('data',function (data) {
//获取到的数据是Buffer数据,也就对应了TCP是面向字节的协议。可以调用BUffer对象上的toString('utf8')来转换成utf8编码的字符串
//也可以通过conn.setEncoding('utf8‘)来进行编码
data = data.replace('\r\n','');//将回车键清除
console.log(data);
//接收到的第一份数据应当是用户输入的昵称
if (!nickname){
if (user[data]){
conn.write('\033[93m>nikename is already in use\033[39m');
}else {
nickname = data;
user[nickname] = conn;
broadcast('\033[90m> '+nickname+'join in the room\033[39m\n');
}
}else {
//用户输入的聊天信息
broadcast('\033[90m> '+nickname+':\033[39m'+data+'\n',true);
}
})
function broadcast(msg,exceptMyself) {
for (var i in user){
if (!exceptMyself || i != nickname){
user[i].write(msg)
}
}
}
conn.on('close',function () {
//有人断开连接的时候就需要清除users数组中对应的元素,并且通知其他用户
count--;//有连接关闭的时候就减少一个
delete user[nickname];
broadcast('\033[90m> '+nickname+':left the room\033[39m'+'\n')
})
conn.setEncoding('utf8');
});
/**
* 监听
*/
server.listen(3000,function () {
console.log('\033[96m SERVER LISTEN ON 3000 \033[90m');
})

七、http
1、在node.js中,使用http.ServerRequest来创建请求,使用http.ServerResponse来创建响应。
2、创建一个http服务器的例子如下
3、node天生是异步机制,所以所有的http响应头中都会带有Transfer-Encoding头的值是chunked,这样响应就可以逐步产生了。
4、在调用res.end方法之前,我们可以多次调用write方法来发送数据。为了尽可能快地响应客户端,在首次调用write的时候,node就能把所有的响应头信息以及第一块数据发送出去。当遇到end方法的时候,node就不再允许网响应中发送数据了。
var http = require('http');
http.createServer(function (req,res) {
res.writeHead(200,{'Content-Type':'text/html'});//向响应头中注入文件类型
res.end('hello'+'world')//返回文档
}).listen(3000);
var http = require('http');
http.createServer(function (req,res) {
res.writeHead(200,{'Content-Type':'image/png'});//向响应头中注入文件类型
var steam = require('fs').createReadStream('image.png');//创建文件流
stream.on('data',function (data) {//一旦有数据读到了就传给response返回
res.write(data)
})
stream.on('end',function () {
res.end()
})
// 另一种写法
require('fs').createReadStream('image.png').pipe(res);
}).listen(3000);
5、连接
在net中,回调函数中对象的类型是一个连接对象,而在http中,是请求和响应对象。这样的区分是因为
-
node在内部做了很多的事情,它拿到了浏览器发送的数据后,对其进行分析,然后构造了一个JavaScript对象方便我们在脚本中使用,
-
浏览器在访问站点的时候不会就只用一个连接,很多主流的浏览器为了更快加载网站内容,能向一个主机打开八个不同的链接并发送请求。
var http = require('http');
var qs = require('querystring');
http.createServer(function (req,res) {
if (req.url == '/'){
res.writeHead(200,{'Content-Type':'text/html'});//向响应头中注入文件类型
res.end([
'
'My form
' +
+'
'' +
' what s your name
''+
''+
''+
''
].join(''))
}else if (req.url == '/url' && req.method == "POST"){
var body = '';
req.on('data',function (chunk) {
body +=chunk
})
req.on('end',function () {
res.writeHead(200,{'Content-Type':'text/html'});
res.end(' your name is
})
}else {
//没有匹配任何其他的数据就返回404
res.writeHead(404);
res.end('Not Found');
}
}).listen(3000);
八、connect
connect是一个基于HTTP服务器的工具集,它提供了一种新的组织代码的方式来与请求、响应对象进行交互,称为中间件。
假如我们有一个站点,其目录结构如下所示
$ls website/
index.html images/
然后再images目录下面有四个图片文件
1.png 2.png 3.png 4.png
index中的内容如下
krys website




那么我们的服务器端要怎么写呢?
// 模块依赖
var http = require('http'),
fs = require('fs');
//创建服务器
var server = http.createServer(function(req, res) {
//检查url是否和服务器目录下的文件匹配,如果匹配,则读取该文件并展示出来。
if (req.method == 'GET' && req.url.substr(0, 7) == '/images' && req.url.substr(-4) == '.png') {
fs.stat(__dirname + req.url, function(err, stat) {
//检查文件是否存在
if (err || !stat.isFile()) {
//如果发生错误,则终止进程并返回404
res.writeHead(404);
res.end('Not Found');
return;
}
})
server(__dirname + req.url, 'application/png');
} else if (req.method == 'GET' && req.url.substr(0, 7) == '/') {
server(__dirname + '/index.html', 'text/html');
} else {
res.writeHead(404);
res.end('Not Found');
}
function server(path, type) {
//根据文件路径来获取文件内容,并添加content-type头信息
res.writeHead(200, { 'Content-Type': type });
res.createReadStream(path).pipe(res)
}
});
//监听
server.listen(3000);
那如果是通过connect来实现呢?
创建网站时一些常见的任务
-
托管静态文件
-
处理错误以及损坏或者不存在的URL
-
处理不同类型的请求
基于http模块API之上的connect,提供了一些工具方法能够让这些重复性的处理便于实现,以至于让开发者能够更加专注在应用本身。
如果要使用connect的话,就要在package.json文件中写明对其的依赖
{
"name": "test",
"version": "0.0.1",
"dependencies": {
"connect": "1.8.7"
}
}

中间件其实就是一个简单的JavaScript函数。使用use方法来添加static中间件。在这里,我们这样配置static中间间-通过传递一些参数connect.static方法,该方法本身会返回一个方法
server.user(connect.static(__dirname+'/website))
将index.html以及Image目录放在/website下。确保没有将不想托管的文件放进去。
然后调用listen方法。
//模块依赖
var connect = require('connect');
//创建服务器
var server = connect.createServer();
//处理静态文件
server.use(connect.static(__dirname + '/website'));
//监听
server.listen(3000);
那么,什么是中间件呢?
简单的来说,中间件由函数组成,它除了处理req和res对象之外,还接收一个next函数来做流控制,也就是相当于一个过滤器。
connect中自带的中间件
1、static中间件
static中间件是使用node开发web的时候最常用的中间件之一了。
它有如下几种功能
-
挂载,挂载的意思就是相关联,比如static允许将任意一个URL匹配到文件系统中的任意一个目录
举例说,假设要让/my-imagesURL和名为/images的目录对应起来,可以通过以下的写法
server.use('images',connect.static('/path/to/myimages'));
-
设置文件缓存时间maxAge
static 中间件接收一个名为maxAge的选项,这个选项代表一个资源在客户端缓存的时间。
server.use('/js',connect.static('/path/to/bundles',{maxAge:1000000}))
-
隐藏在UNIX文件系统中被认为·是·隐藏的文件(以.开始的文件)
server.use(connect.static('path/to/resource',{hidden:true}))
2、query中间件
有时要发送给服务器的数据会以查询字符串的形式,作为URL的一部分。比如url/bl;og-posts?page=5。当在浏览器中访问改URL的时候,node会以字符串的形式将该URL存储在req.url的变量中
server.use(function(req){
//req.url == '/blog-posts?page=5'
})
而大部分的时候,我们都是需要获取查询字符串这部分的数据,使用query中间件,就能通过req.query对象自动获取这些数据
server.use(connect.query)
server.use(function(req,res){
//req.query.page == 5
})
3、logger中间件
logger中间件是一个对web应用非常有用的诊断工具,它将发送进来的请求消息和发送出去的响应消息打印在终端。
它提供了以下四种日志格式
-
default
-
dev
-
short
-
tiny
4、body parse中间件
在一个使用http模块的例子,如果有post的请求发送过来的时候,我们可以使用这个中间件来获取
server.use(connect.bodyParse());
server.use(function(req,res){
req.body.input
})
此外,这个中间件还可以用来使用formidable模块,用来处理用户上传的文件。
5、cookie
当浏览器发送cookie数据的时候,会将其写到cookie头信息中,其数据格式和URL的查询字符串类似。
那么·如果想使用这些值,就可以使用cookieParse中间件。
server.use(connect.cookieParse())
server.use(function(req,res){
//req.cookirs.select == 'value'
})
6、session
在绝大多数数的web应用中,多个请求间共享“用户会话”的概念是非常必要的。“登录”一个网站的时候,多多少少会使用某种形式的会话系统,它主要通过在浏览器中设置cookie来实现,该cookie信息会在随后所有的请求头信息中被带回到服务器中。
connect为此也提供了简单的实现方式。
7、redis session
session默认的存储方式是在内存,这也就意味着session数据都是存储在内存中的,当进程退出后,session数据自然也就丢失了。
redis是一个既小又快的数据库,有一个connect-redis模块使用redis来持久化session数据,这样就让session驻扎到了node进程之外。
首先要先安装好redis
vart connect = require('connect'),
RedisStore = require('connect-redis')(connect);
然后将其作为store选项的值传递给session中间件
server.use(connect.session({store:new RedisStore,secret:'my-secrect'}))
九、Express
connect是基于http模块提供了开发web常用的功能,而Express是基于connect为构建整个网站以及web应用提供了更为方便的API。
在Express中有一个很重要的概念,就是路由,它是有URL和Method组成的,
Express基于connect构建而成,因此,它保持了重用中间件来完成基础任务的想法。这就意味着,通过Expres的API方便地构建web用用的同时,又不失构建于http模块之上的高可用中间件的生态系统。
一个小型的Express应用
package.json
{
"name": "test9",
"version": "0.0.1",
"description": "my first tcp client",
"dependencies": {
"express": "^2.5.9",
"ejs": "^0.4.2",
"superagent": "^0.3.0"
}
}
创建HTML模板
为了避免将HTML代码嵌入到应用逻辑中,这次我们要使用一个简单的模板语言来处理。模板语言的名字叫EJS(内嵌的js),跟在html中内嵌php类似。
index.ejs
提供一个入口给用户提交搜索的关键字:
krys app
please enter youe search term:
search.ejs
用来显示搜索结果
results for <%=search%>
<%if (results.length){%>
- <%= results[i].text%> - <%=results[i].from_user%>
<% for (var i = 0; i< results.length; i++){%>
<% }%>
<% } else {%>
NO resultes
<%}%>
server.js
var express = require('express');
var search = require('./search')
var app = express.createServer();
//配置
app.set('view engine','ejs');//指定使用的模板引擎
app.set('views',__dirname+'/views');//指定视图文件所在的目录
app.set('view options',{layout:false});//指定在渲染视图的时候传递给每个模板
//定义首页的路由,处理get方法的请求
/**
* express为response对象提供了render方法,该方法完成如下三件事
* 初始化模块引擎
* 读取视图文件并将其传递给模板引擎
* 获取解析后的HTML文件页面并作为响应发送给客户端
*/
app.get('/',function (req,res) {
res.render('index');
})
app.get('/search',function (req,res,next) {
search(req.query.q,function (err,twwets) {
if (err) return next(err);
res.render('search',{results:twwets,search:req.query.q})
});
})
app.listen(3000)
search.js
var request = require('superagent')
module.exports = function search(query,fn) {
request.get('http://search.twitter.com/search.json?q='+query)
.end(function (res) {
console.log(res.body)
if (res.body && Array.isArray(res.body.results)){
return fn(null,res.body.results);
}
fn(new Error('Bad response'));
})
}
运行,查看3000端口

对express进行设置
1、让express对模板进行缓存
app.configure('production',function(){
app.enable('view cache')
})
//或者这样写
app.set('view cache',true);
2、开启大小写严格
当开启这个选项之后,就会变成严格的路由,就是匹配到的路由必须一模一样。
3、模板引擎
要使用模板引擎,必须要在npm安装ejs模块,并且生命view engine 为ejs
4、错误处理
绝大多数的web应用都会自定义错误页面,或者自建一套后台的错误处理机制。我们可以通过app.error方法定义一个特殊的错误处理器作为错误处理的中间件
app.error(function(err,req,res,next){
if(err.messag == 'Bad response'){
res.render('error-page')
}else{
next()
}
})
十、WebSocket
(一)ajax
ajax的弊端
当执行代码发出请求时,浏览器会使用可用的socket来进行数据发送,为了提高心梗,浏览器会和服务器之间建立多个socket通道。举例来说,在下载图片的时候,还是可以发送ajax请求。要是浏览器只有一个socket通道,那么网站渲染和使用都会非常慢。若三个请求分别通过三个不同的socket通道发送,就无法抱枕服务器端接收的顺序了,所以我们需要在服务器接受到一个请求之后再接着发送第二个请求,这样就能保证接收的顺序了。
var sending = false;
$(docement),mosemove(function(env){
if(sending) return;
sending = true;
$.Post('/position',{x:ev.clientX,y:ev.clientY},function(){
sending = false
})
})
如果是这样的话,就会发送大量的请求以及接受大量的响应,但是这里的响应式我们不需要的。这样就造成了资源的浪费了。
(二)WebSocket
websocket是web下的TCP,它是双向的socket。websocket有两部分,一部分是浏览器实现的websocket API,另一部分是服务器端实现的websocket协议。这两部分是随着HTML5的推动一起被设计和开发的。
在浏览器中实现的代码如下
latency
服务器端
package.json
{
"name": "test10",
"version": "0.0.1",
"description": "my first ws",
"dependencies": {
"express": "^2.5.9",
"nodejs-websocket": "^1.7.2"
}
}
//创建服务器
// 引入WebSocket模块
var ws = require('nodejs-websocket')
var PORT = 3000
// on就是addListener,添加一个监听事件调用回调函数
// Scream server example:"hi"->"HI!!!",服务器把字母大写
var server = ws.createServer(function(conn){
console.log('New connection')
conn.on("text",function(str){
console.log("Server Received "+str)
conn.sendText("Server Received "+str) //大写收到的数据
//conn.sendText(str) //收到直接发回去
})
conn.on("close",function(code,reason){
console.log("connection closed")
})
conn.on("error",function(err){
console.log("handle err")
console.log(err)
})
}).listen(PORT)
十一、另一种实现websocket的方法--Socket.IO
因为websocket是新出的标准,所以会有一些浏览器不支持。而Socke.IO的传递是基于传输的,也就是说Socket.IO可以在绝大部分的浏览器和设备上运行,从IE6和IOS都支持。
1、Socket.IO提供了可靠的事件机制,如果客户端停止传输数据,但在一定的时间内又没有正常的关闭连接,Socket.IO就认为它是断开连接了。而当连接丢失的时候,会自动重连。
2、在实时web世界中,都是基于事件传输的。Socket.IO仍然允许你想websocket那样传输简单文本信息,除此之外,它还支持通过分发、和监听事件来进行Json数据的收发。
io.sockets.on('connection',function(socket){
socket.send('a');
socket.on('message',function(msg){
console.log(msg)
})
})
3、Socket.IO还提供了另一个强大的特性,它允许在单个连接中利用命名空间来将消息彼此区分开来。
有的时候,应用程序需要进行逻辑拆分,但考虑到性能、速度之类的原因,使用同一个连接还是可以接受的。因此,Socket.IO允许监听多个命名空间中的Connection事件。
io.sockets.on('connection');
io.of('/some/namespace').on('connection')
io.of('/some/other/namespace').on('connection')
尽管这样可以获取到不同的连接对象,但是通常只会使用一个传输通道。
4、Socket.IO 总会尝试U型安泽对用户来说速度最快、对服务器性能来说最好的方法来建立连接,要是条件达不到,那么首先会保证连接正常。
一、MongoDB
1、MangoDB 是一个面向文档,schema-less的数据库,它可以将任意类型的文档数据存储到集合中(与schema无关)。
//package.json
{
"name": "user-auth-example",
"version": "0.0.1",
"dependencies": {
"express": "2.5.8",
"mongodb": "^2.2.26",
"jade": "0.20.3"
}
}
//server.js
//模块依赖
var express = require('express'),
mongodb = require('mongodb');
/**
* 创建数据库
* 提供ip和端口来初始化服务器
*/
var server = new mongodb.Server('127.0.0.1', 27017);
/**
* 告诉驱动器去连接数据库,比如取一个叫krys的数据库名字,在这里如果指定名字的数据库不存在,就会创建一个数据库
*/
var db = new mongodb.Db('krys', server);
db.open(function(err, client) {
//要是连接数据库失败,就终止进程
if (err) throw err;
//要是连接成功,则打印成功的消息
console.log('connected to mongodb!');
//让Express服务器监听端口准备操作集合
//创建app
var app = express.createServer();
app.use(express.bodyParser());
app.use(express.cookieParser());
app.use(express.session({
secret: 'my secret'
}));
//设置模板引擎
app.set('view engine', 'jade');
app.set('view options', { layout: false });
//定义路由
app.get('/', function(req, res) {
//默认路由
res.render('index', {
authenticated: false
})
});
app.get('/login', function(req, res) {
//登录路由
res.render('login');
});
app.get('/signup', function(req, res) {
//注册路由
res.render('signup');
});
app.get("/login/:signupEmail", function(req, res) {
//处理登录路由
console.log(req.params.signupEmail)
res.render('login');
})
//MongoDB有一个ensureIndex命令,调用这个命令来确保在查询前建立了索引
client.ensureIndex('user', 'email', function(err) {
if (err) throw err;
client.ensureIndex('user', 'password', function(err) {
if (err) throw err;
console.log('ensure index');
//监听
app.listen(3000, function() {
console.log('app listen on 3000');
});
})
})
//处理路由
app.post("/signup", function(req, res, next) {
//处理注册路由
//插入文档,参数是需要插入的数据以及一个回调函数,回调函数中的的参数,第一个是错误对象,第二个是插入的文档数组。
client.collection('user', function(err, collection) {
collection.insert(req.body.user, function(err, doc) {
if (err) return next();
console.log(doc)
res.redirect('/login/' + doc.ops[0].email);
})
})
})
app.post('/login', function(req, res) {
client.collection('user', function(err, collection) {
collection.findOne({ email: req.body.user.email, password: req.body.user.password }, function(err, doc) {
if (err) return next(err);
console.log(doc)
if (!doc) return res.send(' user not found
res.redirect('/')
})
})
})
})
//layout.jade
doctype 5
html
head
title Mongodb example
body
h1 my first mongodb
hr
block body
//index.jade
if(authenticated)
p welcome back #{me.first}
a(href="/logout") Logout
else
p welcome new vistor!
a(href='login') Login
a(href='signup') Signup
//signup.jade
form(action="/signup",method="POST")
fieldset
legend Sign up
p
label First
input(name="user[first]",type='text')
p
label Last
input(name="user[last]",type='text')
p
label Email
input(name="user[email]",type='text')
p
label Password
input(name="user[password]",type='text')
p
button Submit
p
a(href="/") Go Back
//login.jade
form(action="/login",method="POST")
fieldset
legend Log in
P
label Email
input(name="user[email]",type='text')
p
label Password
input(name="user[password]",type='text')
p
button Submit
p
a(href="/") Go Back
1、原子性
假设我们基于Express和MongoDB写了一个博客。有两个人,用户A想要编辑文档标题,与此同时用户B想要添加一个标签。如果两个用户都传递了一份完整的万当拷贝来进行更新操作,那么只会有一个胜出。另外一个将无法成功完成对文档的修改。
要确保某个操作的原子性,MongoDB提供了$set 和$push这样不同的操作符。
collection.updat({_id:id},{$set:{title:'my title'}})
collection.updat({_id:id},{tag:{$push:'my tag'}})
2、安全模式
在操作文档的时候提供了一个可短的option参数。其中一个选项叫safe,它会在对数据库进行修改的时候启动安全模式。
3、Mongoose
相比于原生的驱动器,Mongoos做的第一个简化的事情就是它会假定绝大部分的应用程序都是用一个数据库,这大大简化了使用方式。要连接数据库,只需要调用mongoose.connect并提供mongodb://URI即可。
另外,使用mongoose就无须关心连接是否真的已经建立了,因为,它会先把数据库操作指令缓存起来,在连接上数据库后就会把这些操作发送给MongoDB。这就意味着,我们无须监听Connection的回调函数。
5、定义嵌套的键
var BlogPost = new Schema ({
author: ObjectId,
title: String,
body: String,
meta: {
votes: Number,
favs: NUmber
}
})
像上面这样的文档是被允许的,那么如果要查找拥有指定投票数的博文,可以通过如下方式来实现
db.blogposts.find({'mets.votes':5})
6、定义嵌套文档,在MongoDB中,文档可以很大,也可以层次很深,也就是说,如果博文有留言的话,可以直接将留言定义在博文中,而不需要将其定义为单独的集合。
var Comments = new Schema({
title: String,
body: String,
date: Date
})
var BlogPost = new Schema({
author: ObjectId,
title: String,
body: String,
buf: Buffer,
meta: {
votes: Number,
favs: NUmber
},
commets: [Comments]
})
7、构建索引
索引是在MongoDB数据库中确保快速查询的重要因素。要对指定的键做索引,需要传递一个index选项,并将值设置为true。
比如,要对title键做索引,并将uid键设置为唯一,可以这样
var BlogPost = new Schema({
author: ObjectId,
title:{type:String,index:true},
uid:{type:String,unique:true}
body: String,
buf: Buffer,
meta: {
votes: Number,
favs: NUmber
},
commets: [Comments]
})
如果要设置更浮渣的索引(如组合索引),可以使用静态的index方法
BlogPost.index({ket:-1,otherKey:1});
8、中间件
在相当一部分应用中,有的时候会在不同的地方以不同的方式对同样的数据进行修改。通过模型接口将这部分对数据库的交互集中处理是避免代码重复很有效的方法。Mongoose通过引入中间件来实现。Mongoose中间件的工作方式和Express中间件非常相似。定义一些方法,在某些特定动作前执行:save和remove
比如,要在博文删除的时候,发送电子邮件给作者:
BlogPost.pre('remove', function(next) {
emailAuthor(this.email, 'Blog Post removed!');
next();
})
9、扩展查询
如果对某个查询不提供回调函数,那么知道调用run它才会执行:
Post.find({
author: '12345600'
}).where('title', 'my title').sort('content', -1).limit(5).run(function(err, post) {
})
如果查询的文档很大,而想要的知识部分指定的键,那么就可以调用select方法
Post.find().select('field','field2');
如果要跳过指定数量的文档数据,可以通过如下方式
query.skip(10);
这个功能结合Model#count对做分页非常有用
Post.count(funtion(err,totalPosts){
var numPages = Math.ceil(totalPosts/10)
})
10、转换
因为Mongoose提前知道需要什么样的数据类型,所以它总是会尝试做类型转换。
//模块依赖
var express = require('express'),
mongoose = require('mongoose');
var app = express.createServer();
app.use(express.bodyParser());
app.use(express.cookieParser());
app.use(express.session({
secret: 'my secret'
}));
//设置模板引擎
app.set('view engine', 'jade');
app.set('view options', {
layout: false
});
//定义路由
app.get('/', function(req, res) {
//默认路由
res.render('index', {
authenticated: false
})
});
app.get('/login', function(req, res) {
//登录路由
res.render('login');
});
app.get('/signup', function(req, res) {
//注册路由
res.render('signup');
});
app.get("/login/:signupEmail", function(req, res) {
//处理登录路由
console.log(req.params.signupEmail)
res.render('login');
})
/**
* 创建数据库
* 提供ip和端口来初始化服务器
*/
// var server = new mongodb.Server('127.0.0.1', 27017);
//连接数据库
mongoose.connect('mongodb://127.0.0.1/my-website');
app.listen(3000, function() {
console.log('app listen on 3000');
})
/**
* 定义模型
*/
var Schema = mongoose.Schema;
var User = mongoose.model('User', new Schema({
first: String,
last: String,
email: {
type: String,
unique: true
},
password: {
type: String,
index: true
}
}))
//身份认证中间件
app.use(function(req, res, next) {
if (req.session.loggedIn) {
res.local('authenticated', true);
User.findById(req.session.loggedIn, function(err, doc) {
if (err) return next(err);
res.local('me', doc);
next();
})
} else {
res.local('authenticated', false);
next();
}
})
//处理登录路由
app.post('/login', function(req, res) {
User.findOne({
email: req.body.user.email,
password: req.body.user.password
}, function(err, doc) {
if (err) return next(err);
if (!doc) return res.send(' user not found.go back and try agin
req.session.loggedIn = doc._id.toString();
res.redirect('/');
})
})
//处理注册路由
app.post('/signup', function(req, res) {
var user = new User(req.body.user).save(function(err) {
if (err) return next(err);
res.redirect('/login/' + user.email)
})
})
二、MySQL
node-mysql
1、创建数据库
//添加对node-mysql的依赖
var mysql = require('mysql');
//连接mysql
var db = mysql.createClient(config);
2、表操作,使用mysql.createClient创建了数据库后,使用db.query()来执行sql语句,值得注意的是,如果sql语句中的值用?号来代替,那么query中第二个参数是一个数组,分别对应其值。第三个才是回调函数
/创建数据库
db.query('CREATE DATABASE IF NOT EXITS `car-example`');
db.query('USE `car-example`');
//创建表
db.query('DROP TABLE IF EXITS item');
db.query('CREATE TABLE item(id INT(11) AUTO_INCREMENT,title VARCHAT(255),description TEXT,PRIMARY KEY(id))');
db.query('DROP TABLE IF EXITS review');
db.query('CREATE TABLE review(id INT(11) AUTO_INCREMENT,item_id INT(11),text TEXT,stars INT(1),created DATETIME,PRIMARY KEY(id))');
//关闭客户端
db.end(function() {
process.exit();
});
3、当执行的命令是select的时候,回调函数会接收一个包含查询结果对象的数组。数组中的对象包含了指定返回的字段。
db.query('SELECT id,title,description FROM item', function(err, results) {
});
三、Redis
1、redis中的查询
KEYS接收一个匹配键的模式,并返回匹配到的键。*表示匹配所有键
KEYS *
使用SET来设置一个键值对,第一个是键,第二个是值
SET my.key test
使用GET来获取
GET my.key
2、哈希
设置一个值
HSET profile.1 name krys
获取一个指定哈希中所有的键值
HSETALL profile.1
删除一个键(删除哈希 profile1中的name键值)
HDEL profile1. name
检查指定的字段是否存在
HEXISTS profile1. name
3、列表
redis中的列表等同于JavaScript中的字符串数组。
对于列表,redis也有两个基本的操作命令是RPUSH(push到右边,也就是列表的尾端)和LPUSH(push到左边,也就是列表的顶端)
RPUSH profile.1.jobs "job1"
RPUSH profile.1.jobs "job2"
获取指定返回的数组(后面是范围,0 -1 表示返回所有)
LRANGE profile.1 jobs 0 -1
4、数据集
数据集处于列表和哈希之间。
它拥有哈希的属性,即数据集的每一项(或者说哈希中的键)都是唯一不重复的。既然是等同于哈希中的键,操作数据集中的元素都只需要固定时长(也就是说,无论数据集多大,删除、添加、查找数据集中的元素都只需同等的时间。)
类似列表的是,数据集保存的是单个值,没有键。不过数据集还有它专属的有意思的特性。Redis允许在数据集、联合、获取到的随机元素等之间做交集操作。
添加一个元素到数据集中,使用SADD
SADD myset "a member"
获取数据集中的所有元素,可以使用SMEMBERS:
SMEMBERS myset
移除数据集中的某个元素,可以使用SREM
SERM myset "a member"