一个企业级数据挖掘实战项目|客户细分模型(上)
导读: 今天给大家带来了一个Python业务分析实战项目——客户细分模型的应用案例上篇,本文阐述比较详细,包括代码演示、可视化图形展示、以及文字详细分析。分析较浅,希望能够给大家带来些许帮助,欢迎交流学习!文章较长,建议收藏~
本文来源:数据STUDIO 作者:云朵君
客户细分模型是将整体会员划分为不同的细分群体或类别,然后基于细分群体做管理、营销和关怀。客户细分模型常用于整体会员的宏观性分析以及探索性分析,通过细分建立初步认知,为下一步的分析和应用提供基本认知。
常用方法包括:基于属性的方法、ABC分类法、聚类法
基于属性方法
客户地域 -- 如北京、上海
产品类别 -- 如家电、图书
客户类别 -- 大客户、普通客户、VIP客户
客户性别 -- 男、女
会员消费等级 -- 高、中、低价值会员
ABC分类法
Activity Based Classification 是根据事物的主要特征做分类排列,从而实现区别对待、区别管理的一种方法。ABC法则强调的是分清主次。
具体做法,先将目标数据列倒序排序,然后做累积百分比统计,最后将得到的累积百分比按照下面的比例划分为A、B、C三类。
A类因素:主要影响,累积频次为0%~80%
B类因素:次要影响,累积频次为80%~90%
C类因素:一般影响,累积频次为90%~100%
聚类法
常用的非监督方法,无须任何的先验知识,只需要指定要划分的群体数量即可。这里可以参见公号「数据STUDIO」总结的常用聚类模型kmeans聚类
本文客户细分方法
将使用电子商务用户购买商品数据集,并尝试开发一个模型,主要目的是完成以下两个部分。
对客户进行细分。
通过为新客户分配适当的簇群,预测下一年新客户将进行的购买行为。
本文主要内容
本次实战项目共分为上下两部分,上篇(本篇)包括探索性数据分析,产品类别分析两部分;下篇将包括客户细分和客户行为分析与预测。本篇主要结构与内容思维导图如下图所示。

探索性数据分析和预处理
数据准备
df_initial = pd.read_csv('./data.csv')
print('Dataframe维度:', df_initial.shape)
df_initial['InvoiceDate'] = pd.to_datetime(df_initial['InvoiceDate'])
df_initial.columns = ['订单编号', '库存代码', '描述', '数量',
'订单日期', '单价', '客户ID', '国家']
display(df_initial[:5])Dataframe维度: (284709, 8)
缺失值分析
缺失值分析与处理是指对原始数据中缺失的数据项进行预处理,以免影响模型精度和稳定性。数据缺失值处理方法有不少,这里可以参见之前总结的缺失值处理,你真的会了吗?
# 提供有关列类型和空值数量的一些信息
tab_info=pd.DataFrame(df_initial.dtypes).T.rename(index={0:'字段类型'})
tab_info=tab_info.append(pd.DataFrame(
df_initial.isnull().sum()
).T.rename(index={0:'空值量(nb)'}))
tab_info=tab_info.append(pd.DataFrame(
df_initial.isnull().sum()/df_initial.shape[0]*100
).T.rename(index={0:'空值率(%)'}))
print ('-' * 10 + " 显示有关列类型和空值数量的信息 " + '-' * 10 )
display(tab_info)------- 显示有关列类型和空值数量的信息 -------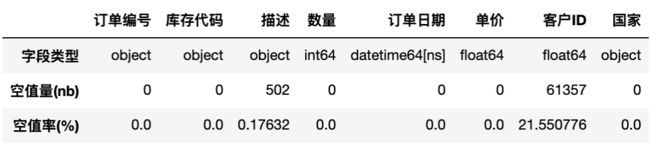
删除缺失值
从上面缺失值分析结果看到,客户ID 约22%的数据记录是空的,这意味着有约22%的数据记录没有分配给任何客户。而我们不可能把这些记录的值映射到任何客户。所以这些对于目前是没有用的,因此我们可以将其删除。
df_initial.dropna(axis = 0,
subset = ['客户ID'],
inplace = True)删除重复值
print('重复的数据条目: {}'.format(
df_initial.duplicated().sum()))
df_initial.drop_duplicates(inplace = True)重复的数据条目: 3175变量'国家'分析
temp = df_initial[['客户ID','订单编号', '国家']].groupby(
['客户ID','订单编号', '国家']).count()
temp = temp.reset_index(drop = False)
countries = temp['国家'].value_counts()统计下来,共有32个国家。并根据每个国家的订单量进行计数求和,排序后绘制国家--国家订单量柱状图,如下所示。

变量'客户和产品'分析
本数据包含约200,000条记录。这些记录中的用户和产品数量分别是多少呢?
pd.DataFrame([{'产品': len(df_initial['库存代码'].value_counts()),
'交易': len(df_initial['订单编号'].value_counts()),
'客户': len(df_initial['客户ID'].value_counts()),
}],
columns = ['产品', '交易', '客户'],
index = ['数量'])| 产品 | 交易 | 客户 | |
|---|---|---|---|
| 数量 | 3182 | 11068 | 3341 |
可以看到,该数据集包含3341个用户的记录,这些用户购买了3182种不同的商品。有约11000的交易被执行。
现在我们需要了解每笔交易中购买的产品数量。
temp = df_initial.groupby(by=['客户ID', '订单编号'],
as_index=False)['订单日期'].count()
nb_products_per_basket = temp.rename(
columns = {'订单日期':'产品数量'})
nb_products_per_basket[:10].sort_values('客户ID')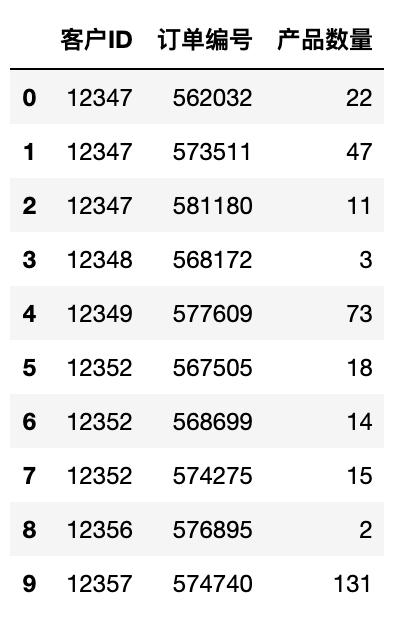
此处需注意的要点:
有一些用户在电子商务平台上只购买了一次,或只购买了一件商品。这类用户如客户ID为12371。
有一些用户经常在每个订单中购买大量商品。这类用户如客户ID为12347。
如果你仔细观察订单编号数据特征,那么你很容易就能发现有些订单编号有个前缀C。这个C表示该订单已经被取消。如下图中C560735。下面就来具体分析下取消的订单一些特征。

取消订单分析
这里统计被取消订单对应的交易数量。
nb_products_per_basket['取消订单量'] = nb_products_per_basket['订单编号'].apply(
lambda x:int('C' in x))
display(nb_products_per_basket.query("取消订单量 != 0")[:5])
# 计算取消订单量的比例
n1 = nb_products_per_basket['取消订单量'].sum()
n2 = nb_products_per_basket.shape[0]
percentage = (n1/n2)*100
print('取消订单数量: {}/{} ({:.2f}%) '.format(n1, n2, percentage))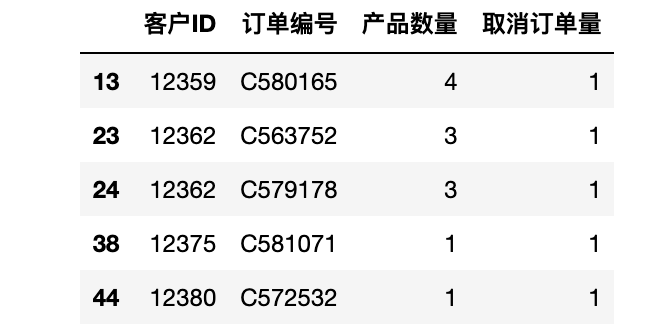
取消订单数量: 1686/11068 (15.23%)得到结果已取消的交易数目相当大(约占交易总数的15%)。
这里,仔细观察数据集,尤其是取消的订单,可以想到,当一个订单被取消时,在数据集中可能会存在另一条对应的记录,该记录除了数量和订单日期变量之外,其他变量内容基本相同。下面检查一下是否所有的记录都是这样的。
具体做法是:
先筛选出负数数量的记录,并在所有数据中检查是否有一个具有相同数量(但为正)的订单,其它属性都相同(客户ID, 描述和单价)
有些取消订单中,描述列会标注"Discount",因此将包含该特征的记录筛除后寻找。

df_check = df_initial[(df_initial['数量'] < 0
) & (df_initial['描述'] != 'Discount')][
['客户ID', '数量', '库存代码', '描述', '单价']]
for index, col in df_check.iterrows():
if df_initial[(df_initial['客户ID'] == col[0]
) & (df_initial['数量'] == -col[1])
& (df_initial['描述'] == col[2])].shape[0] == 0:
print(index, df_check.loc[index])
print(25*'-'+'>'+' 假设不成立')
break279 客户ID 14808.0
数量 -1
库存代码 22655
描述 VINTAGE RED KITCHEN CABINET
单价 125.0
Name: 279, dtype: object
-----------------------------> 假设不成立没有得到理想的结果,说明取消订单不一定与事先已下的订单相对应。
此时,可以在数据表中创建一个新变量,用于指示是否取消了部分订单。而对于其中没有对应购买订单的取消订单记录,可能是由于购买订单是在录入数据库之前执行的。
下面对取消的订单进行了一次普查,并检查是否有对应购买订单存在。
df_cleaned = df_initial.copy(deep = True)
df_cleaned['取消订单数量'] = 0
entry_to_remove = [] ; doubtfull_entry = []
for index, col in df_initial.iterrows(): # 全表扫描
if (col['数量'] > 0) or col['描述'] == 'Discount': continue
df_test = df_initial[(df_initial['客户ID'] == col['客户ID']) &
(df_initial['库存代码'] == col['库存代码']) &
(df_initial['订单日期'] < col['订单日期']) &
(df_initial['数量'] > 0)].copy()
# 没有对应项的取消订单
if (df_test.shape[0] == 0):
doubtfull_entry.append(index)
# 有对应项的取消订单
elif (df_test.shape[0] == 1):
index_order = df_test.index[0]
df_cleaned.loc[index_order, '取消订单数量'] = -col['数量']
entry_to_remove.append(index)
# 不同的对应项是按顺序存在的:我们删除最后一个
elif (df_test.shape[0] > 1):
df_test.sort_index(axis=0 ,ascending=False, inplace = True)
for ind, val in df_test.iterrows():
if val['数量'] < -col['数量']: continue
df_cleaned.loc[ind, '取消订单数量'] = -col['数量']
entry_to_remove.append(index)
break没有对应购买记录的取消订单和有对应购买记录的取消订单分别存储在'doubtfull_entry 和 entry_to_remove列表,他们的个数分别为1672和3435,而这部分数据我们也需要将其删除。
库存代码分析
从上面分析内容中看到,库存代码变量的一些值表示一个特定的交易(D代表Discount)。
下面通过正则表达式寻找只包含字母的代码集,统计出这个变量都有哪些值。
list_special_codes = df_cleaned[df_cleaned['库存代码'
].str.contains('^[a-zA-Z]+',
regex=True)]['库存代码'].unique()
# 并通过对应"描述"变量来寻找每个代码的具体解释。
for code in list_special_codes:
print("{:<15} -> {:<30}".format(
code, df_cleaned[df_cleaned['库存代码'] == code]['描述'].unique()[0]))M -> Manual
POST -> POSTAGE
C2 -> CARRIAGE
PADS -> PADS TO MATCH ALL CUSHIONS
DOT -> DOTCOM POSTAGE
BANK CHARGES -> Bank Charges我们看到有几种特殊的交易类型,如与港口费或银行费有关。
购物车价格分析
接下来是衍生变量:每次购买的总价 = 单价 * (订单数量 - 取消订单数量)
df_cleaned['总价'] = df_cleaned['单价'] * \
(df_cleaned['数量'] - df_cleaned['取消订单数量'])
df_cleaned.sort_values('客户ID')[:5]
数据集中的每一条记录都表示一种产品的价格。而一条订单可以被分成几条记录。因此需要将一条订单中所有价格汇总求和,得到每一个订单总价。
以客户ID和订单编号作为聚合对象,对总价进行求和。
订单日期处理,现将订单日期转换为整数类型,聚合后求平均值,在转换为日期型。
最后筛选出购物车价格大于0的重要记录。
# 购物车订单总价
temp = df_cleaned.groupby(by=['客户ID', '订单编号'],
as_index=False)['总价'].sum()
basket_price = temp.rename(columns = {'总价':'购物车价格'})
# 处理订单日期
df_cleaned['订单日期_int'] = df_cleaned['订单日期'].astype('int64')
temp = df_cleaned.groupby(by=['客户ID', '订单编号'],
as_index=False)['订单日期_int'].mean()
df_cleaned.drop('订单日期_int', axis = 1, inplace = True)
basket_price.loc[:, '订单日期'] = pd.to_datetime(temp['订单日期_int'])
# 重要记录选择
basket_price = basket_price[basket_price['购物车价格'] > 0]
basket_price.sort_values('客户ID')[:6]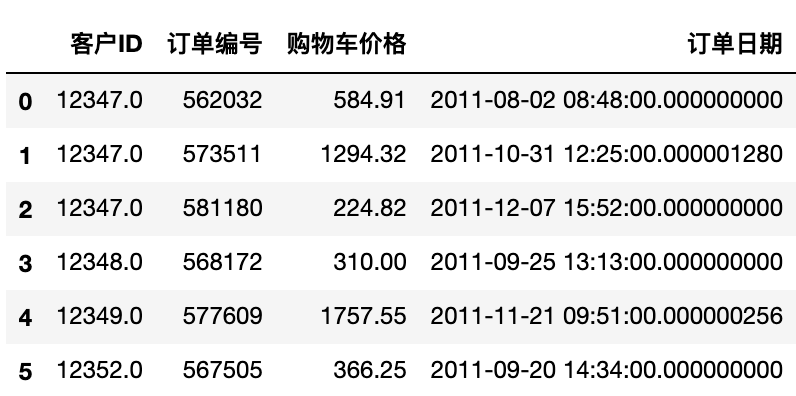
接下来将购物车总价进行离散化处理,并汇总可视化得到如下图所示的结果。
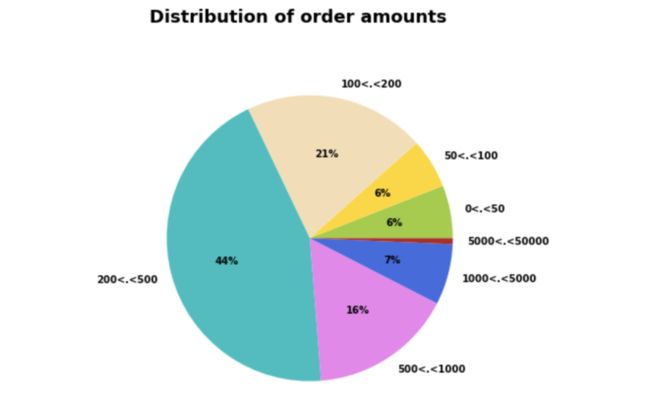
可以看出,绝大多数订单购买价格相对较大的,约有65%的采购超过了200英镑的价格。
产品类别分析
在数据集中,产品是通过变量库存代码唯一标识的。产品的简短描述在变量描述中给出。在这里计划使用后一个变量的内容,即变量描述,以便将产品分组到不同的类别中。
因此这里就涉及到自然语言处理,需要先将简短描述分词后再统计。由于数据集使用的是纯英文数据集,因此这里选用nltk库进行处理。
产品描述
首先从描述变量中提取有用的信息。因此这里定义了一个函数。
keywords_inventory(dataframe, colonne='描述')这个函数以dataframe作为输入,分析描述列的内容,执行如下操作:
提取产品描述中出现的名称(适当的,常见的)
对于每个名称,提取单词的根,并聚合与这个特定根相关的名称集
每个根出现在数据集中的次数计数
当几个单词被列出为同一个词根时,我认为与这个词根相关的关键字是最短的名字(当有单数/复数变体时,系统地选择单数)
这个函数的执行返回四个变量:
' keywords '
提取的关键字列表['lunch', 'bag', 'design', 'suki',]' keywords_roots '
一个字典,其中键是关键字的根,值是与这些根相关联的单词列表{'lunch': {'lunch'}, 'bag': {'bag', 'bags'}, 'design': {'design', 'designs'}, 'suki': {'suki'},}' count_keywords '
字典中列出每个单词使用的次数{'lunch': 24, 'bag': 136, 'design': 116, 'suki': 7,}'keywords_select'
字典中列出每个单词词根<->关键字间的关联关系{'lunch': 'lunch', 'bag': 'bag', 'design': 'design', 'suki': 'suki', 'regenc': 'regency'}
接下来先对所有产品描述进行去重处理,再运用上面定义的函数进行词根提取并统计.
df_produits = pd.DataFrame(df_initial['描述'].unique()
).rename(columns = {0:'描述'})
keywords, keywords_roots, keywords_select,
count_keywords = keywords_inventory(df_produits)从结果看,变量中关键字'描述'的数量共 1347个。此时,将其中一个结果' count_keywords '字典转换为一个列表,根据关键词的出现情况对它们进行排序。

因为字体有点小,不过不影响我们理解实操逻辑。你也可以通过绘制横向柱状图,调大轴标签大小,来自己探究每个词根。大家可以自己尝试。
定义产品类别
上面结果中,我们获得的列表中包含1400多个关键词,而最频繁的关键词出现在200多种产品中。
然而,在仔细检查列表中内容时发现,有很多名称是无用的,不携带任何有用的信息,比如颜色、标签等。因此,接下来需要将这些词从数据集中删除。
另外,为了更加便捷有效地分析数据,我决定只考虑那些出现超过13次的词。
list_products = []
for k,v in count_keywords.items():
word = keywords_select[k]
if word in ['pink', 'blue', 'tag', 'green', 'orange']: continue
if len(word) < 3 or v < 13: continue
if ('+' in word) or ('/' in word): continue
list_products.append([word, v])
list_products.sort(key = lambda x:x[1], reverse = True)
print('保留词:', len(list_products))从结果看,共保留了164个关键词。
分完词并处理后 ,还没有结束,还需要将文字转化为数字,这个过程就是数据编码过程。
数据编码
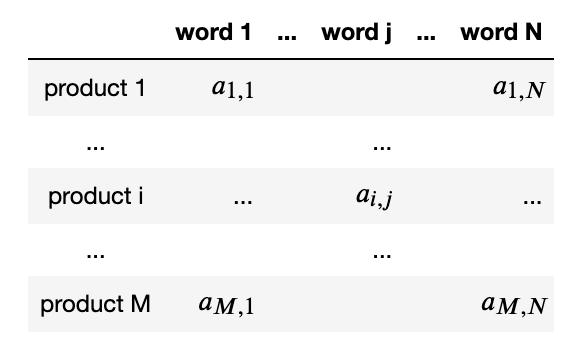
首先定义编码规则,将使用上面得到的关键字创建产品组。将矩阵定义如下,其中,如果产品的描述包含单词,则系数为1,否则为0。
liste_produits = df_cleaned['描述'].unique()
X = pd.DataFrame()
for key, occurence in list_products:
X.loc[:, key] = list(map(lambda x:int(key.upper() in x), liste_produits))
矩阵表示产品描述中包含的单词,使用独热编码原则。
这里使用的是逐条处理,还有
pd.get_dummies()函数直接处理,这里就不做详细介绍,有兴趣的小伙伴可以研究研究。在实践中发现,若使用价格范围来划分分组,这会使每个组中元素更加均衡。
因此,在这个矩阵上增加6列以表示产品的价格范围。
threshold = [0, 1, 2, 3, 5, 10]
label_col = []
# 首先定义labels
for i in range(len(threshold)):
if i == len(threshold)-1:
col = '.>{}'.format(threshold[i])
else:
col = '{}<.<{}'.format(threshold[i],threshold[i+1])
label_col.append(col)
X.loc[:, col] = 0 # 每个labels的初始值设为0
for i, prod in enumerate(liste_produits):
prix = df_cleaned[ df_cleaned['描述'] == prod]['单价'].mean()
j = 0
while prix > threshold[j]:
j+=1
if j == len(threshold): break
X.loc[i, label_col[j-1]] = 1为了选择合适的范围,我检查了不同组别的产品数量,如果组内数量严重不均衡,则需要调整边界点。下面是本次划分的范围,可见该边界范围还算均衡。
范围 产品数量
--------------------
0<.<1 890
1<.<2 817
2<.<3 553
3<.<5 520
5<.<10 395
.>10 123创建产品集群
将把产品分组到不同的类中。在二进制编码矩阵的情况下,计算距离最合适的度量是汉明度量。而我们本次使用的也是常用的sklearn的Kmeans方法使用的是欧几里德距离,但在分类变量的情况下,它不是最佳选择。其实可以使用kmodes包以使用汉明度量,小伙伴们可以自行研究。
matrix = X.values
for n_clusters in range(3,10):
kmeans = KMeans(init='k-means++', n_clusters = n_clusters, n_init=30)
kmeans.fit(matrix)
clusters = kmeans.predict(matrix)
silhouette_avg = silhouette_score(matrix, clusters)
print("For n_clusters =", n_clusters, "The average silhouette_score is :", silhouette_avg)For n_clusters = 3 The average silhouette_score is : 0.11062930220266365
For n_clusters = 4 The average silhouette_score is : 0.13680035318514175
For n_clusters = 5 The average silhouette_score is : 0.15722360950670058
For n_clusters = 6 The average silhouette_score is : 0.1593958217011667
For n_clusters = 7 The average silhouette_score is : 0.15524717712994918
For n_clusters = 8 The average silhouette_score is : 0.16532400447658901
For n_clusters = 9 The average silhouette_score is : 0.16082298271895967实际上,以上所得的分数可视为相等,因为根据运行情况,所有具有'n_clusters' 3的簇获得的分数约为 (第一个簇的分数略低)。另一方面,发现当超过5个簇时,有些簇所包含的元素非常少。
因此,最终选择将数据集划分为5个簇。为了确保每次运行notebook都能很好地进行分类,我反复迭代,直到我们获得可能的最佳轮廓系数,在目前的情况下,轮廓系数约为0.15。
n_clusters = 5
silhouette_avg = -1
while silhouette_avg < 0.145:
kmeans = KMeans(init='k-means++', n_clusters = n_clusters, n_init=30)
kmeans.fit(matrix)
clusters = kmeans.predict(matrix)
silhouette_avg = silhouette_score(matrix, clusters)
#使用kmodes模块进行聚类
#km = kmodes.KModes(n_clusters = n_clusters, init='Huang', n_init=2, verbose=0)
#clusters = km.fit_predict(matrix)
#silhouette_avg = silhouette_score(matrix, clusters)
print("For n_clusters =", n_clusters, "The average silhouette_score is :", silhouette_avg)For n_clusters = 5 The average silhouette_score is : 0.15722360950670058描述集群的内容
上面对所有订单数据进行了Kmeans聚类,并检查每个类中的元素数量。
pd.Series(clusters).value_counts()2 890
0 817
4 553
1 520
3 518
dtype: int64轮廓系数看聚类效果
为了深入了解聚类的效果,常用轮廓系数评价聚类算法模型效果。通过下图可视化地表现聚类效果,参考自sklearn documentation。
# 定义轮廓系数得分
sample_silhouette_values = silhouette_samples(matrix, clusters)
# 然后画个图
graph_component_silhouette(n_clusters, [-0.07, 0.33], len(X), sample_silhouette_values, clusters)
解读此图,不同颜色代表不同的簇,每个簇横坐标表示簇内样本点的轮廓系数,按照大小排序并绘制横向条形图,纵坐标表示样本量大小。
词云图看聚类结果
现在我们可以看看每个簇群代表的对象类型。为了获得其内容的全局视图,用每个关键词中最常见的关键词绘制词云图。
先统计关键词出现的频次。
liste = pd.DataFrame(liste_produits)
liste_words = [word for (word, occurence) in list_products]
occurence = [dict() for _ in range(n_clusters)]
for i in range(n_clusters):
liste_cluster = liste.loc[clusters == i]
for word in liste_words:
# 同之前的一样,筛选掉颜色等无用的词语
if word in ['art', 'set', 'heart', 'pink', 'blue', 'tag']: continue
occurence[i][word] = sum(liste_cluster.loc[:, 0].str.contains(word.upper()))定义绘制词云图函数,并绘制词云图。
fig = plt.figure(1, figsize=(14,14))
color = [0, 160, 130, 95, 280, 40, 330, 110, 25]
for i in range(n_clusters):
list_cluster_occurences = occurence[i]
tone = color[i] # 定义词的颜色
liste = []
for key, value in list_cluster_occurences.items():
liste.append([key, value])
liste.sort(key = lambda x:x[1], reverse = True)
make_wordcloud(liste, i+1)
从这个词云图结果中我们可以看到,其中一个簇群中包含与礼物相关的对象(关键字:圣诞节Christmas、包装packaging、卡片 card等)。
另一簇则倾向于包含奢侈品和珠宝(关键词:项链necklace、手镯bracelet、蕾丝lace、银silver)。但也可以观察到,许多词出现在不同的簇群中,因此很难清楚地区分它们。
PCA主成分分析
为了使得聚类后的结果能够真正做到有效区分,将含有大量变量的初始矩阵数据,我准备使用PCA主成分分析对其进行处理。
pca = PCA()
pca.fit(matrix)
pca_samples = pca.transform(matrix)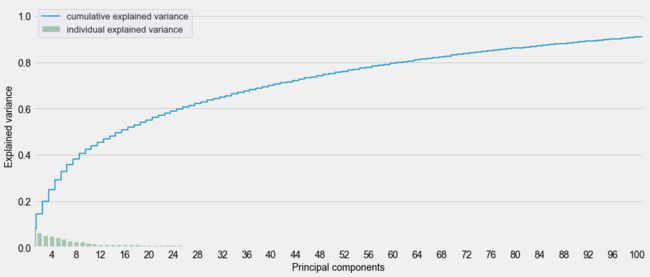
我们看到解释数据所需的维度数量是极其重要的:我们需要超过100个维度来解释数据的90%的方差。在实践中,我决定只保留有限数量的维度。我们以50个维度来做降维处理。
pca = PCA(n_components=50)
matrix_9D = pca.fit_transform(matrix)
mat = pd.DataFrame(matrix_9D)
mat['cluster'] = pd.Series(clusters)
为了更加直观地观察PCA降维度后效果,下面用带颜色的散点图可视化的方法展示,横纵轴分别代表不同的维度变量,颜色代表不同的簇,如下图所示,这里只绘制其中的部分维度数据。

由图可看出,第一主成分已经较好地将几个类别分开了,说明此次降维效果还算可以。
写在最后
到目前为止,已经将本次案例前半部分演示完毕,包括数据探索性数据分析,缺失值等处理。各个关键变量的分析。最后重要的是通过聚类方法,将产品进行聚类分类,并通过词云图和主成分分析各个类别聚类分离效果。
接下来,将是本案例后半部分,包括对客户进行分类,使用分类预测模型对客户进行预测分析。敬请期待!
成都CDA数据分析师
定期分享
数据分析的干货和岗位内推机会
