centos搭建hadoop伪分布式
一、环境准备
Centos7虚拟机一台
jdk1.8
hadoop-3.1.3
附华为开源镜像站下载地址:https://mirrors.huaweicloud.com/java/jdk/
二、java 环境安装
使用root用户登录并创建文件夹
cd /opt
mkdir app
mkdir soft
将下载好的jdk和hadoop安装包上传到虚拟机的/opt/soft目录下
1、创建hadoop用户和用户组
#创建用户组
groupadd hadoop
#创建用户
useradd hadoop
#hadoop用户设置密码
passwd hadoop
#将/opt目录的所有者修改为hadoop,否则没有权限操作
chown -R hadoop:hadoop /opt
2、编辑/etc/sudoers
#vim /etc/sudoers找到“root ALL=(ALL) ALL”一行,
#在下面插入新的一行,内容是“hadoop ALL=(ALL) ALL”
vim /etc/sudoers
#加入下面的内容
hadoop ALL=(ALL) ALL
使用:wq! 进行保存并退出编辑。必须加!否则编辑不成功。
#切换成hadoop用户
su hadoop
准备好的安装包及安装包位置

后续的环境搭建和操作均在hadoop用户下进行操作
3、解压jdk
tar -zxvf jdk-8u151-linux-x64.tar.gz -C ../app/
4、对解压后的jdk包进行重新命名。
cd ../app
#注意更换为自己jdk的包名称
mv jdk1.8.0_151/ java
5、配置java的环境变量
vim ~/.bashrc
#加入下面的内容
export JAVA_HOME=/opt/app/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#然后使配置生效
source ~/.bashrc
#验证java配置是否生效
java -version
出现下面图片表示安装成功。

三、hadoop伪分布式安装
1、解压hadoop安装包并配置hadoop环境变量
cd /opt/soft
tar -zxvf hadoop-2.7.7.tar.gz -C ../app/
#对解压后的包进行重新命名
cd ../app
mv hadoop-2.7.7/ hadoop
配置hadoop的环境变量
#编辑~/.bashrc
vim ~/.bashrc
#添加以下内容
export HADOOP_HOME=/opt/app/hadoop
export PATH=${HADOOP_HOME}/sbin:${HADOOP_HOME}/bin:$PATH
#使环境变量文件生效
source ~/.bashrc
验证环境变量是否设置成功。
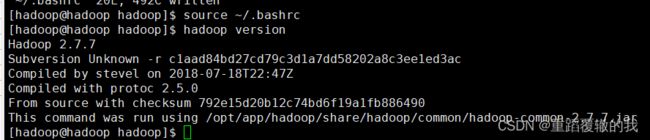
2、修改hosts文件并修改hostname
#修改虚拟机主机名称
sudo hostnamectl set-hostname hadoop
#查看当前虚拟机名称
hostname
#编辑hosts
sudo vim /etc/hosts

3、进行免密登录
# 执行该命令后遇到提示信息,一直按回车就可以
ssh-keygen -t rsa
# 将你的公共密钥填充到一个远程机器上的authorized_keys文件中
ssh-copy-id hadoop

测试ssh是否免密成功
ssh hadoop

4、配置hadoop-env.sh
cd ./hadoop/etc/hadoop
vim hadoop-env.sh
#在文件中添加或者修改,并保存
export JAVA_HOME=/opt/app/java
5、修改core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/opt/app/hadoop/tmpvalue>
property>
configuration>
#注意将ip和路径更换称自己的定义的
6、修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop:50090value>
property>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/opt/app/hadoop/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/opt/app/hadoop/tmp/dfs/datavalue>
property>
configuration>
#注意将ip和路径更换称自己的定义的
7、修改mapred-site.xml
#注意将ip和路径更换称自己的定义的
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop:19888value>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=/opt/app/hadoopvalue>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=/opt/app/hadoopvalue>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=/opt/app/hadoopvalue>
property>
configuration>
8、修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoopvalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
9、修改slaves
vim slaves
#修改为
hadoop
10、格式化namenode
hdfs namenode -format
以下表示格式化成功。

11、启动hadoop
start-all.sh
#或者分别启动hdfs和yarn
start-dfs.sh
start-yarn.sh
jps进行验证是否启动成功,出现以下5个进程表示启动成功。

12、访问hadoop的webui查看状态
ip:9870进行访问

yarn的访问
ip:8088
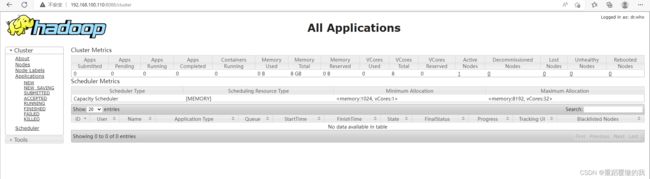
到此hadoop伪分布式就算搭建成功了。