高并发系统设计
高并发系统通用设计方法
Scala-out
横向扩展,分散流量,分布式集群部署
缺点:引入复杂度,节点之间状态维护,节点扩展(上下线)
Scala-up
提升单机性能,比如增加内存,增加CPU核数
缺点:有上限,不能无限扩展
缓存
略
异步
同步调用代表调用方要阻塞等待被调用方法中的逻辑执行完成。这种方式下,当被调用方法响应时间较长时,会造成调用方长久的阻塞,在高并发下会造成整体系统性能下降甚至发生雪崩。
异步调用恰恰相反,调用方不需要等待方法逻辑执行完成就可以返回执行其他的逻辑,在被调用方法执行完毕后再通过回调、事件通知等方式将结果反馈给调用方。
采用异步的方式,后端处理时会把请求丢到消息队列中,同时快速响应用户,告诉用户我们正在排队处理,然后释放出资源来处理更多的请求。
处理逻辑后移到异步处理程序中,Web 服务的压力小了,资源占用的少了,自然就能接收更多的用户订票请求,系统承受高并发的能力也就提升了
架构分层
分层不仅可以简化系统设计,让不同的人专注在不同的层,提高复用性,还可以让我们更容易做 横向扩展:如果系统没有分层,当流量增加时我们需要针对整体系统来做扩展。但是,如果我们按照上面提到的三层架构将系统分层后,那么我们就可以针对具体的问题来做细致的扩展。
缺点:增加代码复杂度、层与层之间的通信会产生性能上的损耗
如何提升系统性能
性能度量指标
响应时间的平均值、最大值、90、95、99分位值
优化策略
提高CPU核数,但不能无限提高,因为随着并发进程数的增加,并行的任务对于系统资源的争抢也会愈发严重。在某一个临界点上继续增加并发进程数,反而会造成系统性能的下降,这就是性能测试中的拐点模型。
如果是CPU密集型任务,尝试优化执行算法流程
如果是IO密集型任务,尝试优化数据库索引和SQL语句,优化网络环境,增加网络带宽
怎样做到系统高可用
可用性衡量指标
MTBF(Mean Time Between Failure)是平均故障间隔的意思,代表两次故障的间隔时间,也就是系统正常运转的平均时间。这个时间越长,系统稳定性越高。
MTTR(Mean Time To Repair)表示故障的平均恢复时间,也可以理解为平均故障时间。这个值越小,故障对于用户的影响越小。
可用性与 MTBF 和 MTTR 的值息息相关,我们可以用下面的公式表示它们之间的关系:
Availability = MTBF / (MTBF + MTTR)
高可用系统设计思路
故障转移
- 节点之间对等:
在对等节点之间做 failover 相对来说简单些。在这类系统中所有节点都承担读写流量,并且节点中不保存状态,每个节点都可以作为另一个节点的镜像。在这种情况下,如果访问某一个节点失败,那么简单地随机访问另一个节点就好了。比如多个JVM实例 - 节点之间不对等
针对不对等节点的 failover 机制会复杂很多。比方说我们有一个主节点,有多台备用节点,这些备用节点可以是热备(同样在线提供服务的备用节点),也可以是冷备(只作为备份使用),那么我们就需要在代码中控制如何检测主备机器是否故障,以及如何做主备切
换。
使用最广泛的故障检测机制是“心跳”。你可以在客户端上定期地向主节点发送心跳包,也可以从备份节点上定期发送心跳包。当一段时间内未收到心跳包,就可以认为主节点已经发生故障,可以触发选主的操作。
选主的结果需要在多个备份节点上达成一致,所以会使用某一种分布式一致性算法,比方说Paxos,Raft。
超时控制
跨系统的调用最可怕的是延迟而非失败,因为失败通常是瞬时的,可以通过重试的方式解决。而一旦调用某一个模块或者服务发生比较大的延迟,调用方就会阻塞在这次调用上,它已经占用的资源得不到释放。当存在大量这种阻塞请求时,调用方就会因为用尽资源而挂掉。
所以RPC框架要配置好超时时间。建议通过收集系统之间的调用日志,统计比如说 99% 的响应时间是怎样的,然后依据这个时间来指定超时时间。超时控制实际上就是不让请求一直保持,而是在经过一定时间之后让请求失败,释放资源给接下来的请求使用。这对于用户来说是有损的,但是却是必要的,因为它牺牲了少量的请求却保证了整体系统的可用性
降级/限流
高流量时对非核心功能进行降级,以及对系统整体承接的流量进行限制
运维
运维上做好灰度发布和故障演练
如何让系统易于扩展
组件之间的扩展性存在瓶颈关系,比如当前瓶颈如果是数据库的话,再怎么扩展服务器也无济于事。如果是网络带宽的话,再怎么扩展数据库也无济于事。所以说,数据库、缓存、依赖的第三方、负载均衡、交换机带宽等等都是系统扩展时需要考虑的因素。我们要知道系统并发到了某一个量级之后,哪一个因素会成为我们的瓶颈点,从而针对性地进行扩展。
扩展核心思路:拆分
把庞杂的系统拆分成独立的,有单一职责的模块。相对于大系统来说,考虑一个一个小模块的扩展性当然会简单一些。
存储层面:竖直拆分/水平拆分
竖直拆分:将业务分为多个库,比如用户库,关系库,评论库等
水平拆分:给某个库增加节点,将以后的请求打散到不同节点
业务层面:业务纬度,重要性纬度和请求来源纬度
-
业务维度:把相同业务的服务拆分成单独的业务池,比方说上面的社区系统中,我们可以按照业务的维度拆分成用户池、内容池、关系池、评论池、点赞池和搜索池。每个业务依赖独自的数据库资源,不会依赖其它业务的数据库资源。这样当某一个业务的接口成为瓶颈时,我们只需要扩展业务的池子,以及确认上下游的依赖方就可以了,这样就大大减少了扩容的复杂度。
-
业务接口的重要程度:把业务分为核心池和非核心池。打个比方,就关系池而言,关注、取消关注接口相对重要一些,可以放在核心池里面;拉黑和取消拉黑的操作就相对不那么重要,可以放在非核心池里面。这样,我们可以优先保证核心池的性能,当整体流量上升时优先扩容核心池,降级部分非核心池的接口,从而保证整体系统的稳定性。
-
调用来源:服务于客户端接口的业务可以定义为外网池,服务于小程序或者 HTML5 页面的业务可以定义为 H5 池,服务于内部其它部门的业务可以定义为内网池,等等。
池化技术
数据库连接池
流量上来时,频繁的创建和销毁数据库连接的消耗会逐渐成为系统的性能瓶颈。数据库连接池可以达到连接复用的效果。
但是数据库连接池的大小不能太大,一般设置为CPU数目比较合适,否则会同时建立过多的连接,使得SQL的执行变得缓慢无比。正确的做法是指定合适数目的连接数,然后业务线程使用阻塞队列来获取数据库连接。
https://blog.csdn.net/weixin_35794878/article/details/90342263
数据库连接池有两个最重要的配置:最小连接数和最大连接数,它们控制着从连接池中获取连接的流程:
- 如果当前连接数小于最小连接数,则创建新的连接处理数据库请求;
- 如果连接池中有空闲连接则复用空闲连接;
- 如果空闲池中没有连接并且当前连接数小于最大连接数,则创建新的连接处理请求;
- 如果当前连接数已经大于等于最大连接数,则按照配置中设定的时间(C3P0 的连接池配置是 checkoutTimeout)等待旧的连接可用;
- 如果等待超过了这个设定时间则向用户抛出错误。
线程池
思想同数据库连接池一致。只不过jdk自带的线程池是对CPU密集型任务友好的
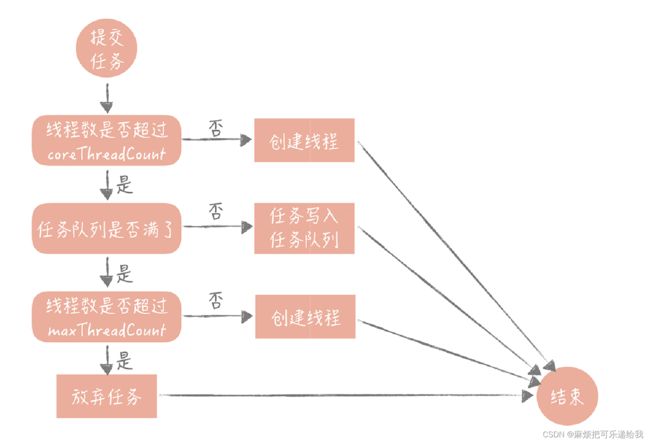
JDK 实现的这个线程池优先把任务放入队列暂存起来,而不是创建更多的线程,它比较适用于执行 CPU 密集型的任务,也就是需要执行大量 CPU 运算的任务。这是为什么
呢?因为执行 CPU 密集型的任务时 CPU 比较繁忙,因此只需要创建和 CPU 核数相当的线程就好了,多了反而会造成线程上下文切换,降低任务执行效率。所以当当前线程数超过核心线程数时,线程池不会增加线程,而是放在队列里等待核心线程空闲下来。
但是,我们平时开发的 Web 系统通常都有大量的 IO 操作,比方说查询数据库、查询缓存等等。任务在执行 IO 操作的时候 CPU 就空闲了下来,这时如果增加执行任务的线程数而不是把任务暂存在队列中,就可以在单位时间内执行更多的任务,大大提高了任务执行的吞吐量。所以你看 Tomcat 使用的线程池就不是 JDK 原生的线程池,而是做了一些改造,当线程数超过 coreThreadCount 之后会优先创建线程,直到线程数到达
需要提醒的是,不要使用无界队列,否则会大量线程阻塞,吃完内存造成fullGC
如何做主从分离
业务场景大部分情况下是读多写少,所以一般会做读写分离,并且读库的数量比写库要多。要求对开发人员无感知。
读写分离的两个技术关键点:
- 数据的拷贝,同步
- 对开发无感知
数据拷贝:binlog

读写分离的好处:
- 写请求就算锁表或者锁记录,也不会影响到读请求
- 多个读库,一主多从,承接大流量
- 从库可以作为备库,防止主库数据丢失
从库不是越多越好,因为主库需要起线程和从库同步数据,同步数据的线程数目太多会影响事务执行
容易出现的问题:主从同步延迟导致查不到数据
在发微博的过程中会有些同步的操作,像是更新数据库的操作,也有一些异步的操作,比如说将微博的信息同步给审核系统,所以我们在更新完主库之后,会将微博的 ID 写入消息队列,再由队列处理机依据 ID 在从库中获取微博信息再发送给审核系统。此时如果主从数据库存在延迟,会导致在从库中获取不到微博信息,整个流程会出现异常

解决思路
- 数据的冗余。你可以在发送消息队列时不仅仅发送微博 ID,而是发送队列处理机需要的所有微博信息,借此避免从数据库中重新查询数据。
- 使用缓存。我可以在同步写数据库的同时,也把微博的数据写入到
Memcached 缓存里面,这样队列处理机在获取微博信息的时候会优先查询缓存,这样也可以保证数据的一致性。 - 查询主库。我可以在队列处理机中不查询从库而改为查询主库。不过,这种方式使用起来要慎重,要明确查询的量级不会很大,是在主库的可承受范围之内,否则会对主库造成比较大的压力。
我觉得可以在查不到的情况下再查询主库,或者加几个重试,因为主从同步的延迟一般不超过几十ms
主从数据库访问问题
两种方式,一种嵌入在应用程序内部,另一种独立部署
- 淘宝的TDDL:以代码形式内嵌运行在应用程序内部。你可以把它看成是一种数据源的代理,它的配置管理着多个数据源,每个数据源对应一个数据库,可能是主库,可能是从库。当有一个数据库请求时,中间件将SQL 语句发给某一个指定的数据源来处理,然后将处理结果返回。
优点:简单,没有多余的部署成本,效率高
缺点:支持的语言有限(java),版本更新依赖使用方,不能独立更新部署 - 单独部署的:Mycat、Atlas等。比较方便进行维护升级,比较适合有一定运维能力的大中型团队使用。它的缺陷是所有的 SQL 语句都需要跨两次网络:从应用到代理层和从代理层到数据源,所以在性能上会有一些损耗。

分库分表
为什么要进行分库分表
- 随着数据量变大,索引结构也随之增大,此时索引无法缓存到内存中,而是需要从磁盘里面进行访问,访问性能急剧下降。同时磁盘空间可能会不足
- 每次备份恢复或者新增从库都需要写入大量数据,效率低
- 当写入的并发量上来之后,多个事务的写入造成锁冲突
解决办法:对数据进行 分片
垂直拆分:将数据库的表拆分到多个不同的数据库中。比如分为用户库和内容库,专门存储不同业务相关的表
水平拆分:将单一数据表按照某一种规则拆分到多个数据库和多个数据表中。主要方式有两种,一种是按照某一个字段的哈希值做拆分,一般按照这些实体表的 ID 字段来拆分。比如说我们想把用户表拆分成 16 个库,64 张表,那么可以先对用户 ID 做哈希,哈希的目的是将 ID 尽量打散,然后再对 16取余,这样就得到了分库后的索引值;对 64 取余,就得到了分表后的索引值。另一种比较常用的是按照某一个字段的区间来拆分,比较常用的是时间字段,比如2019年的存在一个库中,2020年的存在一个库中
水平拆分引入的问题:
- 分区键,每次查询都需要带上分库所用的键(id/时间)。如果需要根据昵称查询数据,该怎么办呢?可以建立一个昵称和 ID 的映射表,在查询的时候要先通过昵称查询到ID,再通过 ID 查询完整的数据,这个表也可以是分库分表的,也需要占用一定的存储空间,但是因为表中只有两个字段,所以相比重新做一次拆分还是会节省不少的空间的。
- join实现起来比较困难,最好放在业务代码中筛选了
- 主键唯一性
拆分建议
4. 如果在性能上没有瓶颈点那么就尽量不做分库分表;
5. 如果要做,就尽量一次到位,比如说 16 库 64 表就基本能够满足为了几年内你的业务的需求。
6. 很多的 NoSQL 数据库,例如 Hbase,MongoDB 都提供 auto sharding 的特性,可以考虑使用这些NoSQL 数据库替代传统的关系型数据库。
水平拆分主键唯一性解决策略
业务字段作为主键的劣势:大部分场景业务字段很难保证唯一性,即使保证了,也不能保证业务字段不会发生变更,一旦主键变更,使用到该主键作为外键的数据行也要跟着变。比如学生表主键为学生id,课程表主键为课程id,成绩表使用到了课程和学生的id作为外键。一旦学生的id变了,那成绩表中相应的记录也要变。同时业务字段可能透露着用户隐私。
所以一般使用自增主键作为主键id。但是分库分表场景下的自增又不能保证,所以只能依赖第三方id生成器
为什么不使用uuid呢?
- 自增id是有序的,uuid是无序的。而查询在很多种情况下都依赖顺序,比如,id就可以作为时间排序。id越大,创建的时间越大。如果id是无序的,那这种场景下还要多存一个时间字段
- 自增有序id可以提高磁盘写入性能。

如上图,插入30可以之间插进去,而插入13需要插入到中间,再把26进行移动。并且如果是有序的,多次插入是顺序写。如果是无序的,则每次还需要寻道。 - uuid没有业务含义。比如身份证可以推算出生日出生地等,手机号可以根据前三位推导出运营商,而uuid不具备任何业务含义
为了解决这类问题,twitter推出了Snowflake

NoSQL
NoSQL有着天生分布式的能力,能够提供优秀的读写性能,可以很好地补充传统关系型数据库的短板
NoSQL特点:不使用 SQL 作为查询语言,提供优秀的横向扩展能力和读写性能
NoSQL类型:
- KV存储,如Redis,LevelDB,极高的读写性能,一般对性能有比较高的要求的场景会使用。
- 列式存储,如Hbase、Cassandra ,不像传统数据库以行为单位来存储,而是以列来存储,适用于一些离线数据统计的场景。
- 文档型,如MongoDB、CouchDB,Schema Free(模式自由),数据表中的字段可以任意扩展,比如说电商系统中的商品有非常多的字段,并且不同品类的商品的字段也都不尽相同,使用关系型数据库就需要不断增加字段支持,而用文档型数据库就简单很多了。
NoSQL提升写入能力
NoSQL使用 LSM Tree,相对于传统的B+Tree,牺牲了读性能,但提供了极致的写(增,删,改)性能
https://zhuanlan.zhihu.com/p/415799237
NoSQL提供查询能力
电商场景,商品查询,使用Elasticsearch建立倒排索引
正常数据库存储

倒排索引

NoSQL提供扩展能力
MongoDB提供的天然分片能力

Replica,也叫做副本集,你可以理解为主从分离,也就是通过将数据拷贝成多份来保证当主挂掉后数据不会丢失。同时呢,Replica 还可以分担读请求。Replica 中有主节点来承担写请求,并且把对数据变动记录到 oplog 里(类似于 binlog);从节点接收到 oplog 后就会修改自身的数据以保持和主节点的一致。一旦主节点挂掉,MongoDB会从从节点中选取一个节点成为主节点,可以继续提供写数据服务
Shard,也叫做分片,你可以理解为分库分表,即将数据按照某种规则拆分成多份,存储在不同的机器上。MongoDB 的 Sharding 特性一般需要三个角色来支持,一个是 Shard Server,它是实际存储数据的节点,是一个独立的 Mongod 进程;二是Config Server,也是一组 Mongod 进程,主要存储一些元信息,比如说哪些分片存储了哪些数据等;最后是 Route Server,它不实际存储数据,仅仅作为路由使用,它从Config Server 中获取元信息后,将请求路由到正确的 Shard Server 中。
当 MongoDB 发现 Shard 之间数据分布不均匀,会启动 Balancer 进程对数据做重新的分配,最终让不同 Shard Server 的数据可以尽量的均衡。当我们的 Shard Server 存储空间不足需要扩容时,数据会自动被移动到新的 ShardServer 上,减少了数据迁移和验证的成本。
缓存
热点本地缓存:
遇到极端的热点数据查询的时候,可以使用热点本地缓存。热点本地缓存主要部署在应用服务器的代码中,用于阻挡热点查询对于分布式缓存节点或者数据库的压力。比如某一位明星在微博上有了热点话题,“吃瓜群众”会到他 (她) 的微博首页围观,这就会引发这个用户信息的热点查询。这些查询通常会命中某一个缓存节点或者某一个数据库分区,短时间内会形成极高的热点查询。那么我们会在代码中使用一些本地缓存方案,如 HashMap,Guava Cache 或者是Ehcache 等,它们和应用程序部署在同一个进程中,优势是不需要跨网络调度,速度极快,所以可以来阻挡短时间内的热点查询。如下为Guava 的 Loading Cache:
CacheBuilder<String, List<Product>> cacheBuilder = CacheBuilder.newBuilder().maximumSize
cacheBuilder = cacheBuilder.refreshAfterWrite(30, TimeUnit.Seconds); // 设置刷新间隔
LoadingCache<String, List<Product>> cache = cacheBuilder.build(new CacheLoader<String,
@Override
public List<Product> load(String k) throws Exception {
return productService.loadAll(); // 获取所有商品
}
});
这样,你在获取所有商品信息的时候可以调用 Loading Cache 的 get 方法,就可以优先从本地缓存中获取商品信息,如果本地缓存不存在,会使用 CacheLoader 中的逻辑从数据库中加载所有的商品。
由于本地缓存是部署在应用服务器中,而我们应用服务器通常会部署多台,当数据更新时,我们不能确定哪台服务器本地中了缓存,更新或者删除所有服务器的缓存不是一个好的选择,所以我们通常会等待缓存过期。因此,这种缓存的有效期很短,通常为分钟或者秒级别,以避免返回前端脏数据。
缓存不足:
- 适合于读多写少的业务场景,并且数据最好带有一定的热点属性。写多读少的场景就不适合
- 缓存会给整体系统带来复杂度,并且会有数据不一致的风险。
- 缓存通常使用内存作为存储介质,但是内存并不是无限的
- 缓存会给运维也带来一定的成本,运维需要对缓存组件有一定的了解,在排查问题的时候也多了一个组件需要考虑在内。
缓存读写策略
Cache Aside(旁路缓存策略)
当需要更新数据时,如果先更新数据库后更新缓存或者先更新缓存后更新数据库会造成缓存和数据库之间的不一致问题。所以业务中常用的做法是,更新数据时把缓存失效掉。等后续读数据时再写入缓存。
这种依然会有不一致的情况,假如某个用户数据在缓存中不存在,请求 A 读取数据时从数据库中查询到年龄为 20,在未写入缓存中时另一个请求 B 更新数据。它更新数据库中的年龄为 21,并且清空缓存。这时请求 A 把从数据库中读到的年龄为 20 的数据写入到缓存中,造成缓存和数据库数据不一致。不过这种问题出现的几率并不高,原因是缓存的写入通常远远快于数据库的写入,所以在实际中很难出现请求 B 已经更新了数据库并且清空了缓存,请求 A 才更新完缓存的情况。
这种策略当数据的写入比较频繁时,需要不断进行缓存数据的删除操作和读取时的重新写入操作,所以适用于读多写少的场景
Read/Write Through(读穿 / 写穿)策略
核心思想是只跟缓存打交道。读/写都直接看缓存。读的话就直接读缓存的或者由缓存帮我们从数据库中加载进来。写的话如果缓存中有直接写,然后再由缓存层帮我们同步写入数据库。没有的话从数据库中加载入缓存。感觉这种跟上面的先写缓存后写数据库一样,会存在不一致的情况。此时就依赖缓存层帮我们加锁解决。,如Guava Cache。其实就算加锁,本地缓存依然逃不了不一致的问题。所以缓存不一致是一个常态,只能通过过期时间来解决。否则过度纠结这个会让缓存性能优势丧失。
Write Back(写回)策略
这个策略的核心思想是在写入数据时只写入缓存,并且把缓存块儿标记为“脏”的。而脏块儿只有被再次使用时才会将其中的数据写入到后端存储中。我们在读取缓存时如果发现缓存命中则直接返回缓存数据。如果缓存不命中则寻找一个可用的缓存块儿,如果这个缓存块儿是“脏”的,就把缓存块儿中之前的数据写入到后端存储中,并且从后端存储加载数据到缓存块儿,如果不是脏的,则由缓存组件将后端存储中的数据加载到缓存中,最后我们将缓存设置为不是脏的,返回数据就好了。计算机体系结构中用的比较多。
缓存高可用策略
高可用方案:客户端方案、中间件方案、服务端方案
客户端方案:自己做分片,如使用hash或者一致性hash
hash缺点:增加或下线节点时,会造成大量缓存失效。用一致性 Hash 算法可以很好地解决增加和删减节点时,命中率下降的问题。这样如果下线节点,只会影响到顺时针的第一个节点。在增加和删除节点时,只有少量的Key 会“漂移”到其它节点上,而大部分的 Key 命中的节点还是会保持不变,从而可以保证命中率不会大幅下降。
一致性hash缺点: 1. 节点在hash环上分布不均时容易造成一个节点承接大量key。2. 脏数据问题
解决办法:虚拟节点 + 过期时间。
中间件方案:请求打到中间件,中间层帮我们做负载均衡。所有缓存的读写请求都是经过代理层完成的。代理层是无状态的,主要负责读写请求的路由功能,并且在其中内置了一些高可用的逻辑,不同的开源中间代理层方案中使用的高可用策略各有不同。比如在 Twemproxy 中,Proxy 保证在某一个Redis 节点挂掉之后会把它从集群中移除,后续的请求将由其他节点来完成;而 Codis 的实现略复杂,它提供了一个叫 Codis Ha 的工具来实现自动从节点提主节点,在 3.2 版本之后换做了 Redis Sentinel 方式,从而实现 Redis 节点的高可用。
服务端方案:redis Sentinel。Redis Sentinel 也是集群部署的,这样可以避免 Sentinel 节点挂掉造成无法自动故障恢复的问题,每一个 Sentinel 节点都是无状态的。在 Sentinel 中会配置 Master 的地址,Sentinel 会时刻监控 Master 的状态,当发现 Master 在配置的时间间隔内无响应,就认为Master 已经挂了,Sentinel 会从从节点中选取一个提升为主节点,并且把所有其他的从节点作为新主的从节点。Sentinel 集群内部在仲裁的时候,会根据配置的值来决定当有几个Sentinel 节点认为主挂掉可以做主从切换的操作,也就是集群内部需要对缓存节点的状态达成一致才行。
缓存穿透问题
解决办法:空值/bloom过滤器/分布式锁
空值缺点:无效key占用大量内存,降低缓存命中率
bloom缺点:
- 它在判断元素是否在集合中时是有一定错误几率的,比如它会把不是集合中的元素判断为处在集合中;
- 不支持删除元素。
解决思路:
- 使用多个 Hash 算法为元素计算出多个 Hash 值,只有所有 Hash 值对应的数组中的值都为1 时,才会认为这个元素在集合中
- 数组中不再只有 0 和 1 两个值,而是存储一个计数。比如如果 A 和 B 同时命中了一个数组的索引,那么这个位置的值就是 2,如果 A 被删除了就把这个值从 2 改为 1。这个方案中的数组不再存储 bit 位,而是存储数值,也就会增加空间的消耗
消息队列
前面提到的大多数应对高并发的策略(缓存,数据库分库分表等)都是针对读多写少的场景,而应对大的写流量,我们可以使用消息队列。
典型的大流量写场景:秒杀,亿级流量并发写,直接用数据库肯定会被打垮
引入消息队列:存储数据的一个容器,是一个平衡低速系统和高速系统处理任务时间差的工具。
削峰填谷
消息队列应对秒杀场景:
将秒杀请求暂存在消息队列中,然后业务服务器会响应用户“秒杀结果正在计算中”,释放了系统资源之后再处理其它用户的请求。
我们会在后台启动若干个队列处理程序,消费消息队列中的消息,再执行校验库存、下单等逻辑。因为只有有限个队列处理线程在执行,所以落入后端数据库上的并发请求是有限的。而请求是可以在消息队列中被短暂地堆积,当库存被消耗完之后,消息队列中堆积的请求就可以被丢弃了。

异步处理
秒杀里面会有主要的业务逻辑,也会有次要的业务逻辑:比如说,主要的流程是生成订单、扣减库存;次要的流程可能是我们在下单购买成功之后会给用户发放优惠券,会增加用户的积分。
次要业务逻辑异步,比如秒杀付款过后的发红包等,这样可以缩短秒杀接口的响应时间

解耦合
比如数据团队对你说,在秒杀活动之后想要统计活动的数据,借此来分析活动商品的受欢迎程度、购买者人群的特点以及用户对于秒杀互动的满意程度等等指标。而我们需要将大量的数据发送给数据团队,那么要怎么做呢?
一个思路是:可以使用 HTTP 或者 RPC 的方式来同步地调用,也就是数据团队这边提供一个接口,我们实时将秒杀的数据推送给它,但是这样调用会有两个问题:
这时,我们可以考虑使用消息队列降低业务系统和数据系统的直接耦合度。
整体系统的耦合性比较强,当数据团队的接口发生故障时,会影响到秒杀系统的可用性。
当数据系统需要新的字段,就要变更接口的参数,那么秒杀系统也要随着一起变更。

如何让消息被消费且仅被消费一次
防止消息丢失
生产端
重传机制,但容易出现重复发送消息的问题
消息队列
同步刷盘策略,只有pagecache刷入磁盘才返回成果;或者异步刷盘 + 集群部署,只有集群大多数服务器收到消息才返回成功
消费者端
消息消费成功后,上报消费进度。
消息只被消费一次
核心思想是消息幂等化。
生产者端
生产消息时带一个全局唯一的id
消息队列
维护生产者id - 最后一个消息id的map,收到消息时先判断和最后一个消息id是不是一样,如果是一样的说明是生产者重复生产。
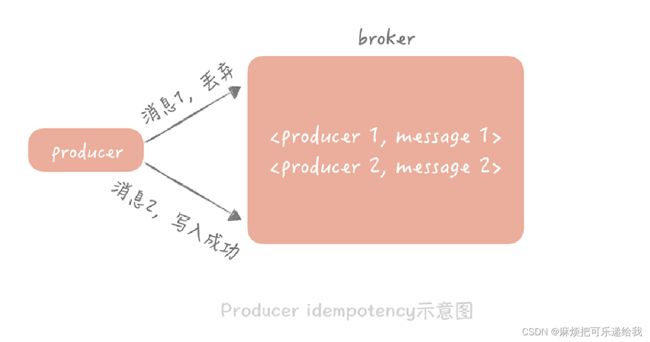
消费者端
消费之前先判断消息是否已经被消费过了。比如利用id判断消费唯一性。
降低消息队列中消息的延迟
消息延迟:消费进度和消息条数的差值。比方说,生产者向队列中一共生产了 1000 条消息,某一个消费者消费进度是 900 条,那么这个消费者的消费延迟就是 100 条消息。
降低延迟的策略:消费端、消息队列端两手抓。
消费端:优化消费代码提升性能;增加消费者数量。可以预先创建一个或者多个线程池,在接收到消息之后,把消息丢到线程池中来异步地处理,这样,原本串行的消费消息的流程就变成了并行的消费,可以提高消息消费的吞吐量,在并行处理的前提下,我们就可以在一次和消息队列的交互中多拉取几条数据,然后分配给多个线程来处理。

消息队列端:消息的存储 + 零拷贝技术
消息的存储:直接将消息存入本地磁盘(堆外内存)
零拷贝技术:sendfile
高级语言中对于 Sendfile 函数有封装,比如说在
Java 里面的 java.nio.channels.FileChannel 类就提供了 transferTo 方法提供了 Sendfile的功能。
通用思想:队列的任务的堆积是一个不可忽视的问题。
为什么要做微服务的划分?
一体式架构的优点:开发直接,只用维护一个应用,排查问题只用关心一个进程。
当开发规模扩大之后,一体式架构的痛点:
不够敏捷,缩扩容需要面向所有应用模块
合作开发比较困难
项目过大,变更重新构建很困难
微服务解决思路:把每个模块独立拆分出来部署,单独进行缩扩容等运维部署,将多个应用划分给不同的小团队进行开发。但也会遇到多个应用之间如何协作等一系列问题。
微服务拆分的注意事项
- 注意扩展性,比如不要传多个参数,这样一旦参数的数量变了,调用方感知不到就会出故障。最好是传一个结构体。
- 多个服务之间有着错综复杂的依赖关系。一个服务会依赖多个其它服务,也会被多个服务所依赖,那么一旦被依赖的服务的性能出现问题,产生大量的慢请求,就会导致依赖服务的工作线程池中的线程被占满,那么依赖的服务也会出现性能问题。接下来,问题就会沿着依赖网,逐步向上蔓延,直到整个系统出现故障为止。
为了避免这种情况的发生,我们需要引入服务治理体系,针对出问题的服务,采用熔断、降级、限流、超时控制的方法,使得问题被限制在单一服务中,保护服务网络中的其它服务不受影响。 - 服务拆分到多个进程后,一条请求的调用链路上,涉及多个服务,那么一旦这个请求的响应时间增长,或者是出现错误,我们就很难知道,是哪一个服务出现的问题。另外,整体系统一旦出现故障,很可能外在的表现是所有服务在同一时间都出现了问题,你在问题定位时,很难确认哪一个服务是源头,这就需要引入分布式追踪工具,以及更细致的服务端监控报表。
降低微服务调用延迟
主要考虑两点
- 网络传输性能
- 序列化/反序列化方式
网络传输方面,可以使用多路复用的IO模型。一个优化点:开启tcp_nodelay
tcp 协议的包头有 20 字节,ip 协议的包头也有 20 字节,如果仅仅传输 1 字节的数据,在网络上传输的就有 20 + 20 + 1 = 41 字节,其中真正有用的数据只有 1 个字节,这对效率和带宽是极大的浪费。所以在 1984 年的时候,John Nagle 提出了以他的名字命名的
Nagles 算法,他期望:
如果是连续的小数据包,大小没有一个 MSS(Maximum Segment Size,最大分段大小),并且还没有收到之前发送的数据包的 Ack 信息,那么这些小数据包就会在发送端暂存起来,直到小数据包累积到一个 MSS,或者收到一个 Ack 为止。
这原本是为了减少不必要的网络传输,但是如果接收端开启了 DelayedACK(延迟 ACK 的发送,这样可以合并多个 ACK,提升网络传输效率),那就会发生,发送端发送第一个数据包后,接收端没有返回 ACK,这时发送端发送了第二个数据包,因为 Nagles 算法的存在,并且第一个发送包的 ACK 还没有返回,所以第二个包会暂存起来。而 DelayedACK的超时时间,默认是 40ms,所以一旦到了40ms,接收端回给发送端 ACK,那么发送端才会发送第二个包,这样就增加了延迟。
解决的方式非常简单:只要在 socket 上开启 tcp_nodelay 就好了,这个参数关闭了Nagle`s 算法,这样发送端就不需要等到上一个发送包的 ACK 返回,直接发送新的数据包就好了。这对于强网络交互的场景来说非常的适用
序列化方式方面,需要考虑的点有,序列化和反序列化的耗时,二进制串的大小(影响内存和网络传输),跨语言通用性。常用的有JSON,Thrift,Protobuf(后两者需要生成IDL文件)
注册中心
核心作用:服务发现和注册,能够存储服务的地址并将地址变更通知给调用方。
服务状态管理:注册中心主动探活:需要RPC服务单独打开一个端口。容易出现端口号被占用的情况。或者是RPC服务发送心跳。
状态管理坑点:一次性不能摘除太多服务,如果突然出现大量服务(40%)不可用,那就可以考虑是注册中心本身出了问题,需要停止摘除服务并发出告警
分布式Trace
单体应用
以日志打印耗时为例,在单体应用下,为了区分当前日志属于哪个请求,一般会在每次请求的线程中设置一个requestId。
同时,为了方便在每个接口上都加上耗时打印,可以使用切面编程思想。一类是静态代理,典型的代表是 AspectJ,它的特点是在编译期做切面代码注入;另一类是动态代理,典型的代表是 Spring AOP,它的特点是在运行期做切面代码注入。这两者有什么差别呢?以 Java 为例,源代码 Java 文件先被 Java 编译器,编译成 Class 文件,然后 Java 虚拟机将 Class 装载进来之后,进行必要的验证和初始化后就可以运行了。静态代理是在编译期插入代码,增加了编译的时间,给你的直观感觉就是启动的时间变长了,但是一旦在编译期插入代码完毕之后,在运行期就基本对于性能没有影响。
而动态代理不会去修改生成的 Class 文件,而是会在运行期生成一个代理对象,这个代理对象对源对象做了字节码增强,来完成切面所要执行的操作。由于在运行期需要生成代理对象,所以动态代理的性能要比静态代理要差。这里可以使用静态代理,减少运行时日志打印的耗时。
@Aspect
public class Tracer {
@Around(value = "execution(public methodsig)", argNames = "pjp") //executio
public Object trace(ProceedingJoinPoint pjp) throws Throwable {
TraceContext traceCtx = TraceContext.get(); // 获取追踪上下文,上下文的初始
String requestId = reqCtx.getRequestId(); // 获取 requestId
String sig = pjp.getSignature().toShortString(); // 获取方法签名
boolean isSuccessful = false;
String errorMsg = "";
Object result = null;
long start = System.currentTimeMillis();
try {
result = pjp.proceed();
isSuccessful = true;
return result;
} catch (Throwable t) {
isSuccessful = false;
errorMsg = t.getMessage();
return result;
} finally {
long elapseTime = System.currentTimeMillis() - start;
Logs.info("rid : " + requestId + ", start time: " + start + ", elap
}
}
}
如果存储压力过大,可以减少日志的数量,比如做日志采样(%10 > 5)
由于现在应用一般是多机部署,如果要去每台机器上搜索日志会比较麻烦。因此日志不会直接存储在服务器上,而是通过mq等运输到elasticsearch等搜索引擎进行存储,方便索引的建立和日志的检索。
分布式应用
分布式应用一次请求横跨多个应用,所以这多个应用的请求处理线程的requestId需要保持一致,一般称之为traceId。同时,为了展示出调用和被调用的关系,一般还会使用spanId

首先,A 服务在发起 RPC 请求服务 B 前,先从线程上下文中获取当前的 traceId 和spanId,然后,依据上面的逻辑生成本次 RPC 调用的 spanId,再将 spanId 和 traceId 序列化后,装配到请求体中,发送给服务方 B。
服务方 B 获取请求后,从请求体中反序列化出 spanId 和 traceId,同时设置到线程上下文中,以便给下次 RPC 调用使用。在服务 B 调用完成返回响应前,计算出服务 B 的执行时间发送给消息队列。当然,在服务 B 中,你依然可以使用切面编程的方式,得到所有调用的数据库、缓存、HTTP 服务的响应时间,只是在发送给消息队列的时候,要加上当前线程上下文中的spanId 和 traceId。
这样,无论是数据库等资源的响应时间,还是 RPC 服务的响应时间就都汇总到了消息队列中,在经过一些处理之后,最终被写入到 Elasticsearch 中以便给开发和运维同学查询使用。
负载均衡
代理层的负载均衡和客户端层的负载均衡。
代理层:Nginx,LVS
客户端层:Dubbo等RPC框架在远程调用时进行的负载均衡。
代理层适用于web服务,客户端层适用于微服务。
负载均衡策略:静态负载均衡,动态负载均衡。
静态:轮询、带权重的轮询
动态:根据响应时间、空闲线程数动态调整权重
Nginx是工作在应用层的,而LVS是工作在传输层的。
LVS如何在传输层工作?根据目的ip和端口号进行服务器的选择,那会不会导致同一个请求的不同tcp报文被分散到不同的服务器中?
根据实验可以看出,即使是同一个客户端,请求多次,也会被分配到不同的服务器上。那这种传输层的负载均衡是怎么做的呢?传输层是怎么知道,这几个包属于一个应用层请求,那几个包属于另一个应用层请求的呢?
难道是,只有SYN的时候做了负载均衡?之后一旦建立了连接,就都分发给建立了连接的那台机器上了?一个客户端多次请求,会建立多次tcp连接,建立的时候做了负载均衡?
所以,LVS不会和客户端之间建立tcp连接,而是将tcp连接建立的流量进行转发。而nginx会直接和客户端建立tcp连接,接收客户端的请求流量。
应用层和传输层的区别在于,目的ip的更改时机不同。
一般在流量特别大的情况下,会部署一个LVS挡在最外层,分发给多个nginx。nginx再进行反向代理过程。
网关层
部署在负载均衡和应用服务器之间,网关将一些服务共有的功能整合在一起,独立部署为单独的一层,用来解决一些服务治理的问题。你可以把它看作系统的边界,它可以对出入系统的流量做统一的管控。
API 网关可以分为两类:一类叫做入口网关,一类叫做出口网关。
- 它提供客户端一个统一的接入地址,API 网关可以将用户的请求动态路由到不同的业务服务上,并且做一些必要的协议转换工作。API 网关可以对客户端屏蔽微服务的部署地址,以及协议的细节,给客户端的调用带来很大的便捷。
- 在 API 网关中,我们可以植入一些服务治理的策略,比如服务的熔断、降级,流量控制和分流等等
- 客户端的认证和授权的实现,黑白名单,也可以放在 API 网关中,应用服务不需要了解认证的细节。
网关的核心要义:性能和扩展性。因为网关要承接所有客户端流量,接收到客户端的流量之后,要路由并请求服务端,最后返回给客户端结果。所以网关采用的IO模型是影响性能的关键。这里一般使用Netty作为网络IO的框架,建立netty server和netty client
扩展性方面,采用职责链模式,支持用户自定义职责链节点进行热插拔。
为了提升网关对于请求的并行处理能力,我们一般会使用线程池来并行的执行请求。不过,这就带来一个问题:如果商品服务出现问题,造成响应缓慢,那么调用商品服务的线程就会被阻塞无法释放,久而久之,线程池中的线程就会被商品服务所占据,那么其他服务也会受到级联的影响。因此,我们需要针对不同的服务做线程隔离,或者保护。在我看来有两种思路:
- 如果你后端的服务拆分得不多,可以针对不同的服务,采用不同的线程池,这样商品服务的故障就不会影响到支付服务和用户服务了;
- 在线程池内部可以针对不同的服务,甚至不同的接口做线程的保护。比如说,线程池的最大线程数是 1000,那么可以给每个服务设置一个最多可以使用的配额。
多机房部署
跨机房传输的延迟。
小规模业务场景一般使用同城多活。此时延迟可以控制在1-3ms
异地多活的延迟会大很多,北京到广州有50ms,此时对于缓存,数据库的读取要保证是在同城机房的。并且对不同区域的用户做分片,对于RPC服务的调用尽量选择离得近的机房。
同城多活一般是一个机房部署主库,其他机房部署从库,利用数据库的主从同步进行数据一致性的保证。

同城多活的这种部署方式虽然存在跨机房写的问题,但是延迟可以接受。
异地多活就要避免跨机房的同步读/写了。一般读都是在同城机房做的。写的话也是同机房写,然后通过binlog或者消息队列异步传输写操作给其他地区的库。
(mysql多主?)
ServiceMesh
解决跨语言RPC的服务治理问题,使用sidecar独立部署一层,将服务治理逻辑从语言中抽离出来

业界中使用的比较多的是istio
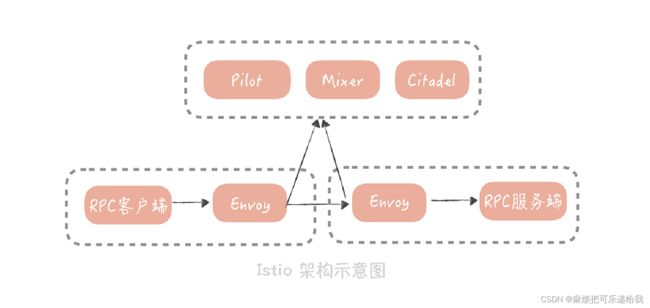
它将组件分为数据平面和控制平面,数据平面就是我提到的 Sidecar(Istio 使用Envoy作为 Sidecar 的实现)。控制平面主要负责服务治理策略的执行,在 Istio 中,主要分为Mixer、Pilot 和 Istio-auth 三部分。
流量可以通过iptable转发到sidecar中,进行流量劫持。实现调用方的无感知


或者使用轻量客户端

服务监控
监控的四个黄金指标
- 延迟
请求的响应时间,比如,接口的响应时间、访问数据库和缓存的响应时间。 - 通信量
吞吐量,也就是单位时间内,请求量的大小。比如,访问第三方服务
的请求量,访问消息队列的请求量。 - 错误
表示当前系统发生的错误数量。 - 饱和度
服务或者资源到达上限的程度(也可以说是服务或者资源的利用率),比如说 CPU 的使用率,内存 使用率,磁盘使用率,缓存数据库的连接数等等。
监控数据的采集
Agent:比如发送stats命令到Memcached服务器,获取服务器的统计信息并挑选,然后发送给监控服务器。或者是监控JMX
代码埋点:直接计算调用资源或者服务的耗时、调用量、慢请求数,并且发送给监控服务器
日志: Tomcat 和 Nginx 的访问日志,都是重要的监控日志。你可以通过开源的日志采集工具,将这些日志中的数据发送给监控服务器。目前,常用的日志采集工具有很多,比如,Apache Flume、Fluentd和Filebeat,
监控数据的处理和存储
一般会先用消息队列来承接数据,主要的作用是削峰填谷,防止写入过多的监控数据,让监控服务产生影响。
一般会部署两个队列处理程序,来消费消息队列中的数据
一个处理程序接收到数据后,把数据写入到 Elasticsearch,然后通过 Kibana 展示数据,这份数据主要是用来做原始数据的查询;
另一个处理程序是一些流式处理的中间件,比如,Spark、Storm。它们从消息队列里,接收数据后会做一些处理,
- 解析数据格式,尤其是日志格式。从里面提取诸如请求量、响应时间、请求 URL 等数据;
- 对数据做一些聚合运算。 比如,针对 Tomcat 访问日志,可以计算同一个 URL 一段时间之内的请求量、响应时间分位值、非 200 请求量的大小等等。
- 将数据存储在时间序列数据库中。这类数据库的特点是,可以对带有时间标签的数据,做更有效的存储,而我们的监控数据恰恰带有时间标签,并且按照时间递增,非常适合存储在时间序列数据库中。目前业界比较常用的时序数据库有 InfluxDB、OpenTSDB、
Graphite,各大厂的选择均有不同,你可以选择一种熟悉的来使用。 - 最后, 你就可以通过 Grafana 来连接时序数据库,将监控数据绘制成报表,呈现给开发和运维的同学了

除了这些服务端的监控指标之外,客户端的请求响应时间以及影响用户使用体验的地方也需要埋点监控。
- 从客户端采集到的数据可以用通用的消息格式,上传到 APM 服务端,服务端将数据存入到 Elasticsearch 中,以提供原始日志的查询,也可以依据这些数据形成客户端的监控报表;
- 用户网络数据是我们排查客户端,和服务端交互过程的重要数据,你可以通过代码的植入,来获取到这些数据;
- 无论是网络数据,还是异常数据,亦或是卡顿、崩溃、流量、耗电量等数据,你都可以通过把它们封装成 APM 消息格式,上传到 APM 服务端,这些用户在客户端上留下的踪迹可以帮助你更好地优化用户的使用体验。
总而言之,监测和优化用户的使用体验是应用性能管理的最终目标。然而,服务端的开发人员往往会陷入一个误区,认为我们将服务端的监控做好,保证接口性能和可用性足够好就好了。事实上,接口的响应时间只是我们监控系统中很小的一部分,搭建一套端到端的全链路的监控体系,才是你的监控系统的最终形态。
压力测试
压测的几个踩坑点:
- 做压力测试时,最好使用线上的数据和线上的环境
- 压力测试时不能使用模拟的请求,而是要使用线上的流量
- 不要从一台服务器发起流量,可以放在不同的机房中,这样可以尽量保证压力测试结果的真实性。
搭建一套自动化的全链路压测平台,来降低成本和风险。
压测的两个关键点:
- 流量的隔离。由于压力测试是在正式环境进行,所以需要区分压力测试流量和正式流量,这样可以针对压力测试的流量做单独的处理。
- 风险的控制。尽量避免压力测试对于正常访问用户的影响

压测数据的产生
一般来说,我们系统的入口流量是来自于客户端的 HTTP 请求,所以,我们会考虑在系统高峰期时,将这些入口流量拷贝一份,在经过一些流量清洗的工作之后(比如过滤一些无效的请求),将数据存储在像是 HBase、MongoDB 这些 NoSQL 存储组件,或者亚马逊 S3这些云存储服务中,我们称之为流量数据工厂。
这样,当我们要压测的时候,就可以从这个工厂中获取数据,将数据切分多份后下发到多个压测节点上了
需要对压测流量染色,也就是增加压测标记。在实际项目中,我会在 HTTP的请求头中增加一个标记项,比如说叫做 is stress test,在流量拷贝之后,批量在请求中增加这个标记项,再写入到数据流量工厂中
根据染色标记分辨压测流量,然后针对某些不能压测的服务或者组件进行Mock,比如浏览历史、推荐记录等数据不能写入,而是使用Mock服务直接返回成功。
对于写入数据的请求,一般会把压测流量产生的数据写入到影子库,也就是和线上数据存储,完全隔离的一份存储系统中
- 如果数据存储在 MySQL 中,我们可以在同一个 MySQL 实例,不同的 Schema 中创建一套和线上相同的库表结构,并且把线上的数据也导入进来。
- 如果数据是放在 Redis 中,我们对压测流量产生的数据,增加一个统一的前缀,存储在同一份存储中。
- 如果数据会存储在 Elasticsearch 中,针对这部分数据,我们可以放在另外一个单独的索引表中。
压测核心:流量的拷贝,染色隔离,Mock和影子库
配置中心
配置项管理的方法:使用配置文件、使用配置中心。
配置文件
- 写死在代码中 -> 每次更改需要重新编译
- 将配置项独立成单独的文件(properties、xml、yaml) -> 更改后不需要编译,但需要重新打包部署
- 将配置项写到单独的目录中 -> 更改后不需要重新打包,但需要重启服务。
通常会把配置文件存储的目录,标准化为特定的目录。比如,都配置成 /data/confs 目录,然后把配置项使用 Git 等代码仓库管理起来。这样,在增加新的机器时,在机器初始化脚本中,只需要创建这个目录,再从 Git 中拉取配置就可以了,是一个标准化的过程,这样可以避免在启动应用时忘记部署配置文件。
配置中心
微服务架构中的标准组件,常用的有Apollo、Disconf、Spring Cloud Config等等
配置中心的核心功能:配置项的存储和读取,存储可以选择多种组件,比如MySQL、ZooKeeper、Redis、Etcd等。
配置的优先级:支持存储全局配置、机房配置和节点配置。其中,节点配置优先级高于机房配置,机房配置优先级高于全局配置。也就是说,我们会优先读取节点的配置,如果节点配置不存在,再读取机房配置,最后读取全局配置
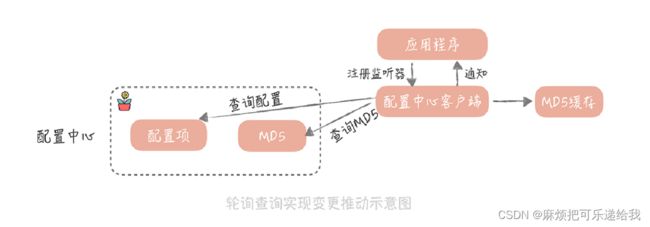
变更推送:一种是轮询查询的方式(pull);一种是长连推送的方式(push)。
pull
配置中心的客户端,定期地(比如 1 分钟)查询所需要的配置是否有变化,如果有变化则通知触发监听器,让应用程序得到变更通知。
如果有很多应用服务器都去轮询拉取配置,由于返回的配置项可能会很大,那么配置中心服务的带宽就会成为瓶颈。为了解决这个问题,我们会给配置中心的每一个配置项,多存储一个根据配置项计算出来的 MD5 值。配置项一旦变化,这个 MD5 值也会随之改变。配置中心客户端在获取到配置的同时,也会获取到配置的 MD5 值,并且存储起来。那么在轮询查询的时候,需要先确认存储的 MD5值,和配置中心的 MD5 是不是一致的。如果不一致,这就说明配置中心中,存储的配置项有变化,然后才会从配置中心拉取最新的配置。
由于配置中心里存储的配置项变化的几率不大,所以使用这种方式后,每次轮询请求就只是返回一个 MD5 值,可以大大地减少配置中心服务器的带宽。
push
配置中心服务端保存每个连接关注的配置项列表。这样,当配置中心感知到配置变化后,就可以通过这个连接,把变更的配置推送给客户端。这种方式需要保持长连,也需要保存连接和配置的对应关系,实现上要比轮询的方式复杂一些,但是相比轮询方式来说,能够更加实时地获取配置变更的消息
配置中心的高可用
配置中心对可用性的要求高,如果配置中心宕机导致我们无法获取数据库的地址,那么自然应用程序就会启动失败。因此,关键是配置中心的旁路化,也就是说,即使配置中心宕机,或者配置中心依赖的存储宕机,我们仍然能够保证应用程序是可以启动的。
做法是,我们一般会在配置中心的客户端上,增加两级缓存:第一级缓存是内存的缓存;另外一级缓存是文件的缓存。配置中心客户端在获取到配置信息后,会同时把配置信息同步地写入到内存缓存,并且异步地写入到文件缓存中。内存缓存的作用是降低客户端和配置中心的交互频率,提升配置获取的性能;而文件的缓存的作用就是灾备,当应用程序重启时,一旦配置中心发生故障,那么应用程序就会优先使用文件中的配置,这样虽然无法得到配置的变更消息(因为配置中心已经宕机了),但是应用程序还是可以启动起来的,算是一种降级的方案。
降级熔断
雪崩
服务调用方等待服务提供方的响应时间过长,它的线程资源被耗尽,引发了级联反应,发生雪崩。
比如大流量场景下,一些非核心服务没有及时扩容导致请求处理缓慢,影响了上游服务。
解决的思路就是在检测到某一个服务的响应时间出现异常时,切断调用它的服务与它之间的联系,让服务的调用快速返回失败,从而释放这次请求持有的资源
熔断机制
在发起服务调用的时候,如果返回错误或者超时的次数超过一定阈值,则后续的请求不再发向远程服务而是暂时返回错误。
服务调用方为每一个调用的服务维护一个有限状态机,在这个状态机中会有三种状态:关闭(调用远程服务)、半打开(尝试调用远程服务)和打开(返回错误)
当调用失败的次数累积到一定的阈值时,熔断状态从关闭态切换到打开态。一般在实现时,如果调用成功一次,就会重置调用失败次数。
当熔断处于打开状态时,我们会启动一个超时计时器,当计时器超时后,状态切换到半打开态。你也可以通过设置一个定时器,定期地探测服务是否恢复。
在熔断处于半打开状态时,请求可以达到后端服务,如果累计一定的成功次数后,状态切换到关闭态;如果出现调用失败的情况,则切换到打开态。

redis降级示例
if (breaker.isOpen()) {
return null; // 断路器打开则直接返回空值
}
K value = null;
Jedis jedis = null;
try {
jedis = connPool.getResource();
value = callback.call(jedis);
if(breaker.isHalfOpen()) { // 如果是半打开状态
if(successCount.incrementAndGet() >= SUCCESS_THRESHOLD) {// 成功次数超
failCount.set(0); // 清空失败数
breaker.setClose(); // 设置为关闭态
}
}
return value;
} catch (JedisException je) {
if(breaker.isClose()){ // 如果是关闭态
if(failCount.incrementAndGet() >= FAILS_THRESHOLD){ // 失败次数超过阈值
breaker.setOpen(); // 设置为打开态
}
} else if(breaker.isHalfOpen()) { // 如果是半打开态
breaker.setOpen(); // 直接设置为打开态
}
throw je;
} finally {
if (jedis != null) {
jedis.close();
}
}
降级机制
降级是一个宏观的概念,是站在整体系统负载的角度上,放弃部分非核心功能或者服务,保证整体的可用性的方法,是一种有损的系统容错方式。这样看来,熔断也是降级的一种,除此之外还有限流降级、开关降级等等
限流
常见的限流算法:固定窗口算法、滑动窗口算法、漏桶算法、令牌桶算法
固定窗口算法
启动定时器,定期清空计数。如果计数超过阈值则拒绝请求。
缺陷:无法限制短时间之内的集中流量。假如我们需要限制每秒钟只能处理 10 次请求,如果前一秒钟产生了 10 次请求,这 10次请求全部集中在最后的 10 毫秒中,而下一秒钟的前 10 毫秒也产生了 10 次请求,那么在这 20 毫秒中就产生了 20 次请求,超过了限流的阈值。但是因为这 20 次请求分布在两个时间窗口内,所以没有触发限流,这就造成了限流的策略并没有生效。

滑动窗口算法
固定窗口的缺陷在于,没有时间起点和时间重点的概念,只有区间的概念。而滑动窗口是,收到请求后判断当前的小区间(比如100ms),然后往前1秒钟的小区间一共的请求个数有没有突破限制,没有的话把当前请求记录在小区间内。

解决了窗口边界大流量问题, 但是空间复杂度有所提升。
漏桶算法
流量产生端和接收端之间增加一个漏桶,流量会进入和暂存到漏桶里面,而漏桶的出口处会按照一个固定的速率将流量漏出到接收端。如果流入的流量在某一段时间内大增,超过了漏桶的承受极限,那么多余的流量就会触发限流策略,被拒绝服务

一般会使用消息队列作为漏桶的实现,流量首先被放入到消息队列中排队,由固定的几个队列处理程序来消费流量,如果消息队列中的流量溢出,那么后续的流量就会被拒绝
令牌桶算法
以固定速率往桶中放令牌(有最大令牌数量限制),请求时需要从桶中获取令牌,如果桶中没有令牌,则拒绝服务。
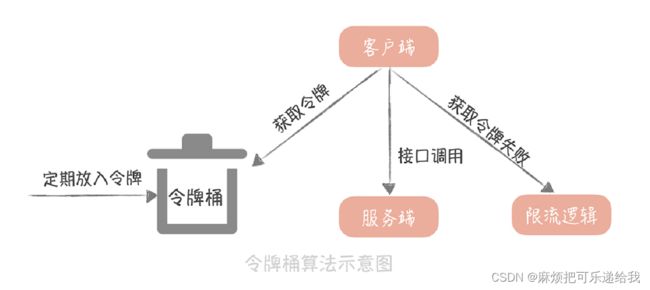
一般会使用 Redis 来存储这个令牌的数量。这样的话,每次请求的时候都需要请求一次 Redis 来获取一个令牌,会增加几毫秒的延迟,性能上会有一些损耗。因此,一个折中的思路是: 我们可以在每次取令牌的时候,不再只获取一个令牌,而是获取一批令牌,这样可以尽量减少请求 Redis 的次数
漏桶和令牌桶的对比
漏桶算法在面对突发流量的时候,采用的解决方式是缓存在漏桶中, 这样流量的响应时间就会增长,这就与互联网业务低延迟的要求不符;而令牌桶算法可以在令牌中暂存一定量的令牌,能够应对一定的突发流量,所以一般我会使用令牌桶算法来实现限流方案
实战篇:计数系统设计
MySQL一行记录存储:以微博 ID 为主键,转发数、评论数、点赞数和浏览数分别为单独一列,这样在获取计数时用一个 SQL 语句就搞定了。
数据量越来越大, MySQL单表数据达到千万级别,会导致性能上的损耗。
使用id作为分区键,进行分库分表:选择一种哈希算法对 weibo_id 计算哈希值,然后依据这个哈希值计算出需要存储到哪一个库哪一张表中

随着访问量的上升,读越来越多,MySQL不堪重负
抛弃MySQL,使用 Redis 来加速读请求,通过部署多个从节点来提升可用性和性能,并且通过 Hash 的方式对数据做分片,也基本上可以保证计数的读取性能

热门微薄的计数频率变化太快,为了提升写入性能和降低写入压力,引入消息队列
计数数据的存储压力如何降低,因为Redis是在内存中进行存储的。
可以对原生 Redis 做一些改造,采用新的数据结构和数据类型来存储计数数据:
一是原生的 Redis 在存储 Key 时是按照字符串类型来存储的,比如一个 8 字节的 Long类型的数据,需要 8(sdshdr 数据结构长度)+ 19(8 字节数字的长度)+1(’\0’)=28 个字节,如果我们使用 Long 类型来存储就只需要 8 个字节,会节省 20 个字节的空间;
二是去除了原生 Redis 中多余的指针,如果要存储一个 KV 信息就只需要
8(weibo_id)+4(转发数)=12 个字节,相比之前有很大的改进
最近的微博访问频率高,需要冷热分离:
给计数服务增加 SSD磁盘,然后将时间上比较久远的数据 dump 到磁盘上,内存中只保留最近的数据。当我们要读取冷数据的时候,使用单独的 I/O 线程异步地将冷数据从 SSD 磁盘中加载到一块儿单独的 Cold Cache 中。

系统通知未读数的设计:不要遍历每个用户去增加未读数,而是记录下来所有的系统通知和每个用户读到的位置,来算出未读数
