windows 平台上使用 pyarrow 连接 hdfs 详细教程
Index
- windows 平台上使用 pyarrow 连接 hdfs 详细教程
-
- 连接教程
- 踩坑记录
-
- 进入支线:编译 hdfs.dll
-
- 进入支线的支线:编译 OpenSSL
-
- 多个 OpenSSL 的设置问题
- 意想不到的大坑
- 回到支线,编译 hdfs.dll
- 回到主线
- 最后的一个小波澜,缺失 winutils
windows 平台上使用 pyarrow 连接 hdfs 详细教程
因篇幅太长,因此先直接说结论,若有兴趣知道这个结论是怎么来的,可以跳到章节:踩坑记录,中进行细节上的阅览。
转载请注明出处,蟹蟹。
连接教程
- 使用
pip安装pyarrow。 - 下载
JDK,解压后设置环境变量JAVA_HOME和JDK_HOME指向解压后的路径。 - 下载
hadoop的预发布压缩包,并解压。解压后设置环境变量HADOOP_HOME指向解压后的路径。 - 下载与步骤 3 对应的
hadoop源码包,准备编译 windows 平台上的hdfs.dll文件。 - 在解压后的
hadoop源码hadoop-2.9.2-src\hadoop-hdfs-project\hadoop-hdfs-native-client\src下,存在CMakeLists.txt文件,使用该CMake文件进行编译,以此编译出sln文件。- 若在编译过程中出现报错:
JVM_ARCH_DATA_MODEL未定义,则可在编译命令中加入以下参数-DJVM_ARCH_DATA_MODEL=64(指定java的平台版本,存疑)。 - 若在编译过程中出现报错:
OpenSSL_ROOT_DIR not defined (missing: OpenSSL_include_dir),则需进行第六步。
- 若在编译过程中出现报错:
- (若步骤 5 出现了报错 ,则进行该步骤,否则可跳过)根据
OpenSSL的官方编译文档,在本机上编译,以此得到include文件夹。 - 使用
Visual Studio打开CMake编译出的sln文件。打开后设置为Release和对应的平台版本(x64/x32)后,在解决方案中选中hdfs,右键后点击生成;即可在当前目录下的bin文件夹中得到编译后的dll文件。(举个例子:./bin/Release/hdfs.dll) - 将生成的
hdfs.dll, hdfs.exp, hdfs.lib三个文件放置在一个新的文件夹中,并设置环境变量ARROW_LIBHDFS_DIR指向该路径。 - 在winutils上下载对应版本的
hadoop文件夹,将bin文件夹里面的文件拷贝覆盖到原有hadoop\bin文件夹。 - 每次连接前使用
set_hadoop_classpath函数设置环境变量后即可使用。import os import subprocess from pyarrow import fs # Thanks to: https://stackoverflow.com/a/66651006 def set_hadoop_classpath(): if 'hadoop' in os.environ.get('CLASSPATH', ''): return if 'HADOOP_HOME' in os.environ: hadoop_bin = os.path.normpath(os.environ['HADOOP_HOME']) + "/bin/" # '{0}/bin/hadoop'.format(os.environ['HADOOP_HOME']) else: hadoop_bin = 'hadoop' os.chdir(hadoop_bin) hadoop_bin_exe = os.path.join(hadoop_bin, 'hadoop.cmd') print(hadoop_bin_exe) classpath = subprocess.check_output([hadoop_bin_exe, 'classpath', '--glob']) os.environ['CLASSPATH'] = classpath.decode('utf-8') set_hadoop_classpath() hdfs = fs.HadoopFileSystem('xxx.xxx.xxx.xxx', 12345)
踩坑记录
踩坑踩得头破血流 _(:з」∠)_
安装 pyarrow ,尝试运行模板代码时,首先爆了 unload jvm 的错误。
from pyarrow import fs
hdfs = fs.HadoopFileSystem('xxx.xxx.xxx.xxx', 12345)
查阅源码,发现其运行时会去查找 jvm.dll 或者 libjvm.so 这两个文件,且其搜索依赖于环境变量。于是下载 java 并设置 JAVA_HOME 和 JDK_HOME 为 jdk 所在路径后即可解决问题。
hdfs_internal.cc

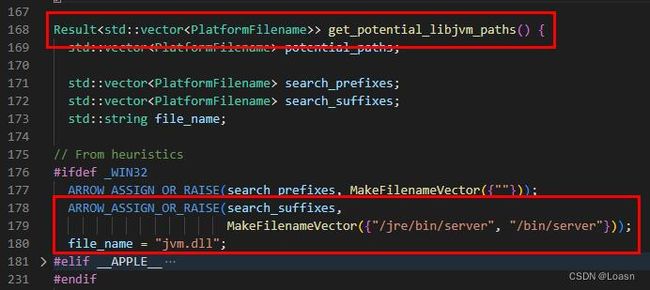
再次运行,这次爆 unload libhdfs.dll 错误,翻阅源码,确认 hdfs.dll 存在于 Path 路径下。
经反复设置和重启,确认路径无误,遂开始怀疑是 hdfs.dll 的问题。
查阅源码,发现其使用 C++ 代码调用 LoadLibraryW 这个 windows api 进行 DLL 的加载
hdfs_internal.cc

遂编写 C++ 程序尝试手动加载 DLL 以验证是否为 DLL 的问题。
#include 经多次测试后(不同的版本,不同的路径,不同的编译平台(x64 or x32)),发现 winutils 中的 hdfs.dll 皆无法正常加载。
查看加载 DLL 失败时的错误代码:126
经查阅资料发现,126 错误可能有多个原因: https://blog.csdn.net/FlushHip/article/details/96167157
使用 ProcessMonitor 去监控 Visual Studio 编译出来的程序加载时的操作。

发现其尝试加载 MSVCR100.dll 失败。然而搜索文件时却发现 msvcr100.dll 确实存在于 system32 ,且该路径确实存在于 Path 变量中。
再次搜索发现一个关于 system32 的版本设定 https://stackoverflow.com/questions/21283863/msvcp100-dll-not-found-error-even-when-it-is-installed
遂判断其要加载的可能是 32 位的 DLL ,于是将路径 C:\Windows\SysWOW64 加入到环境变量 Path 下,得以解决。
再次运行 Test.exe 发现,其仍无法正常加载 DLL ,这时候返回的错误码为 193 ,查阅得知其含义为:不是有效的 win32 应用程序。
通过反复生成不同平台和调整路径后发现仍然无法正常加载 DLL ,开始怀疑是不是 DLL 有问题,于是开始尝试自己编译 hadoop 或者 hdfs.dll 。

进入支线:编译 hdfs.dll
查阅 Hadoop 的官方 wiki 得知,hdfs 的相关 dll 可以单独编译,便从官网上下载 hadoop-2.9.2 的源码开始尝试编译。
下载后查看文件,目录 hadoop-hdfs-project/hadoop-hdfs-native-client/src 下存在 CmakeLists.txt 和 sln 文件,说明其需要使用 Cmake 进行编译,于是下载安装 CMake 去尝试编译。

开始编译后首个遇到的问题就是报错,JVM_ARCH_DATA_MODEL 未定义。翻阅完整个网上都无法找到关于这个变量的说明,询问朋友后得知这个参数好像是用来指定平台版本的;遂尝试填入参数 -DJVM_ARCH_DATA_MODEL=64 ,顺利解决(编译时所使用的电脑为 x64 )。
然后又遇到了第二个报错: OpenSSL_ROOT_DIR not defined (missing: OpenSSL_include_dir)
搜索文件后发现,虽然在安装 git 时自动安装了 openssl 的一些 bin 文件,但是却没有对应的头文件;所以需要自己去编译。
进入支线的支线:编译 OpenSSL
翻阅 OpenSSL 的官方编译文章: https://github.com/openssl/openssl/blob/master/NOTES-WINDOWS.md 进行软件的下载和编译。
编译的过程没什么难度,将编译软件都下载下来,安装并设置好对应的环境变量即可顺利安装。
唯一值得稍微一提的是,使用 VS+Perl+NASM 编译时的最后一步需要以管理员权限启动 VS 的编译命令行。
多个 OpenSSL 的设置问题
编译完后,在 Path 中设定 OpenSSL 的根路径后,再次开始尝试使用 CMake 编译 hdfs 。依旧报错:OpenSSL_ROOT_DIR not defined (missing: OpenSSL_include_dir)
开始的时候怀疑是不是编译过程中出了什么问题,又重新编译了好几次进行确认,但都没发现问题。
这时候开始怀疑是不是版本的问题,抱着试一试的心态敲下了 where openssl ,竟发现存在有四个路径指向 OpenSSL 。
第一个是刚编译后手动指定的路径,第二个是安装 Perl 时,安装过程中自动设定的路径。第三个是很久之前安装 Git 时,git 安装并设定的路径。第四个是 MinGW64 的 bin 目录下路径。
然后问题来到了,如何确定现在生效的是哪一个 OpenSSL 。一顿 Google 后,发现可以使用 win+r ,然后输入 openssl 运行 OpenSSL ,在新生成的窗口上会显示 OpenSSL 的运行路径,以此确认现在生效的是哪个路径下的 OpenSSL 。
意想不到的大坑
在环境变量中调整 Path 里各个搜索路径的优先级后;现在第一个查找到的 OpenSSL 路径为我们最新编译好的路径。
这时候再次去编译,结果仍是熟悉的报错:OpenSSL_ROOT_DIR not defined (missing: OpenSSL_include_dir)
再次去网上搜索线索,无果后尝试着在命令中手动指定 OpenSSL 的路径;依旧无效,报错。
尝试使用 GUI 去设定 OpenSSL 的路径,防止手动输入命令时对空格进行的转义出错,无效,仍然报错。
一点点阅读 Cmake 的 FindOpenSSL 函数源码,一点点去检查 CMakeCache.txt ,还是没有得到任何能解决问题的有效信息。
因为在这里折腾了快一天,这时候的心态已经是快崩溃了的;本着最后的一点希望,怀疑是 OpnSSL 在 windows 上编译的默认路径存在空格,无论会不会转义都会出错。于是重新编译了 OpenSSL,并手动设置生成路径,防止其出空格。
结果就是这个破罐子破摔似的想法,居然还真是正确答案。
在 OpenSSL 的路径上没有空格时,CMake 才能正常编译。
回到支线,编译 hdfs.dll
经 CMake 编译后,会在 CMakeLists.txt 文件所在目录下生成后缀为 sln 的 Visual Studio 解决方案文件,使用 Visual Studio 打开后,直接在项目上右键点击生成即可。


回到主线
根据文档 https://arrow.apache.org/docs/python/filesystems.html#filesystem-hdfs
将刚刚生成的 hdfs.dll, lib, exp 文件放置在一个新的文件夹中,并新建名为 ARROW_LIBHDFS_DIR 的环境变量指向这个值。
因为觉得 winutils 给出的 dll 可能有问题,所以又将 hadoop 换成了官网上下载的预发布二进制包。
再次运行代码,结果又弹出了新的错误。
$ python Desktop/go.py
Environment variable CLASSPATH not set!
getJNIEnv: getGlobalJNIEnv failed
Environment variable CLASSPATH not set!
getJNIEnv: getGlobalJNIEnv failed
C:/arrow/cpp/src/arrow/status.cc:137: Failed to disconnect hdfs client: IOError: HDFS hdfsFS::Disconnect failed. Detail: [errno 255] Unknown error
Traceback (most recent call last):
File "C:\Users\xxx\Desktop\go.py", line 26, in
hdfs = fs.HadoopFileSystem('10.10.10.101', 9000)
File "pyarrow\_hdfs.pyx", line 96, in pyarrow._hdfs.HadoopFileSystem.__init__
File "pyarrow\error.pxi", line 144, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow\error.pxi", line 115, in pyarrow.lib.check_status
OSError: HDFS connection failed
根据错误语句 Environment variable CLASSPATH not set! 得知,是 pyarrow 文档中提到的 CLASSPATH 未设置。使用文档中提到的命令
Linux: export CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath --glob`
Windows: %HADOOP_HOME%/bin/hadoop classpath --glob > %CLASSPATH%
进行设置后发现命令无效,遂手动复制 hadoop classpath --glob 命令输出的结果至环境变量中。
再次运行后发现 CLASSPATH not set 的错误消失了,但却又出现了新的错误。
loadFileSystems error:
(unable to get stack trace for java.lang.NoClassDefFoundError exception: ExceptionUtils::getStackTrace error.)
hdfsBuilderConnect(forceNewInstance=0, nn=172.25.40.171, port=9001, kerbTicketCachePath=(NULL), userName=(NULL)) error:
(unable to get stack trace for java.lang.NoClassDefFoundError exception: ExceptionUtils::getStackTrace error.)
一番搜索后发现,这个答案中提到的错误代码和刚刚出现的非常相像
https://developer.aliyun.com/article/497425
文中提到的 FileSystem 类在 share\lib\command-configure.jar 中,将 jar 路径添加至 CLASSPATH 就可以解决问题。
但是上面的操作中已经将 hadoop 输出的 jar 包路径全都添加至 CLASSAPTH 中了,这个路径理应也是存在于 CLASSPATH 中的。
抱着怀疑的心态去检查了 CLASSPATH 的路径列表,发现 CLASSPATH 的字符串被截断了,字符串中只有前面的十几个包的路径。
又是一番艰苦的搜索后发现,在 Windows 上,单个环境变量的长度限制为 2047 个字符,全部环境变量的总长度为 32767 个字符。
尝试用路径引用,即使用 %VARNAME% 来代替大多数变量中的共同路径,发现其长度即使缩减了,但仍远远超出 2047 个字符。
本以为系统的限制是没法绕过的,这几天的努力痛苦只能付诸东流,却在无意间想起了这个回答
https://stackoverflow.com/a/66651006
第一次看见这回答时,心想的是。pyarrow 的源码中,连接 HDFS 时使用的是编译后的 C++ 动态链接库,这些类库应该是直接从系统中读取的环境变量;用的这个代码修改 Python 的环境变量字典有什么用。
然后回想起到时候却突然想到了另一种可能;如果,如果 C++ 载入的环境变量不是通过 Windows API ,而是通过更为方便的 Python 获取,然后传入 C++ 中这种方式呢?如果是这样的话,
那么修改环境变量字典可能会真的有用?!!
结果的话~ 如果不成功这篇文章也不会发出来了是吧 XD
PS: 其实这里对环境变量的传递环节依旧存在一些疑问,但是没有多余的闲暇时间去查阅相关资料和源码了。
若有人能在评论区分享些相关的文章笔记的话,感激不尽。
最后的一个小波澜,缺失 winutils
因为之前换成了 hadoop 的预发布二进制包的缘故,其预发布时的编译平台是 Linux ,所以是无法在 Windows 上运行的,会提示缺失 winutils.exe
这时候直接将 winutils 中下载下来的 bin 文件夹覆盖到 hadoop 目录下就好了。
winutils: https://github.com/cdarlint/winutils
看到代码正常运行跑通的那一刻,整个人都泪目了,感觉能踩的坑都踩了,终于是跑通了啊 T▽T