第8章 中医证型关联规则挖掘
8.1 背景与挖掘目标
- 借助患者的病理信息,挖掘患者的症状与中医证型之间的关联关系
- 对截断治疗提供依据,挖掘潜性证素
8.2 分析方法与过程
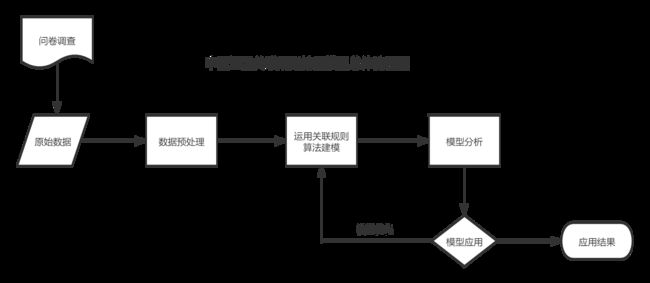
- 数据收集与整理,问卷调查、将问卷信息整理成原始数据
- 数据预处理,包括数据清洗、属性规约、数据变换
- 构建模型:关联规则算法,调整模型输入参数,获取各中医证素与乳腺癌TNM分期之间的关系
- 结合实际业务,对模型结果进行分析,且将模型结果应用到实际业务中,最后输出关联规则结果
流程图如下:
8.2.1 数据获取
- 拟定调查问卷表并形成原始指标表
- 定义纳入标准与排除标准
- 将收集回来的问卷整理成原始数据
8.2.2 数据预处理
1.数据清洗
在收回的问卷中,存在无效的问卷,为了便于模型分析,需要对其进行处理。在经过问卷有效性条件筛选后,总共得到有效问卷930份,并将其整理成原始数据。
2.属性规约
本案例收集到的数据共有73个属性,为了更有效,将其中冗余属性与挖掘任务不相关的属性剔除。因此选取其中6中证型得分、TNM分期的属性值构成数据集。
3.数据变换
- 属性构造,为了更好地反映分布的特征,采用证型系数代替具体单证型的证素得分,证型系数 = 该证型得分 / 该证型总分
- 数据离散化
数据离散化代码如下:
#导入相关库
from __future__ import print_function
import pandas as pd
from sklearn.cluster import KMeansM #导入k均值聚类算法
datafile = 'G:/Python数据分析与挖掘实战/chapter8/demo/data/data.xls'
processedfile = 'G:/Python数据分析与挖掘实战/chapter8/zl/data_processed.xlsx'
typelabel ={'肝气郁结证型系数':'A', '热毒蕴结证型系数':'B', '冲任失调证型系数':'C', '气血两虚证型系数':'D', '脾胃虚弱证型系数':'E', '肝肾阴虚证型系数':'F'}
k = 4
然后,读取数据并进行聚类分析:
#读取数据并进行聚类分析
data = pd.read_excel(datafile)
keys = list(typelabel.keys())
result = pd.DataFrame()
if __name__ == '__main__':
for i in range(len(keys)):
#调用算法,进行聚类离散化
print('正在进行"%s"的聚类。。。' % keys[i])
kmodel = KMeans(n_clusters=k, n_jobs=4)
kmodel.fit(data[[keys[i]]].values) #训练模型
r1 = pd.DataFrame(kmodel.cluster_centers_, columns=[typelabel[keys[i]]]) #聚类中心
r2 = pd.Series(kmodel.labels_).value_counts() #分类统计
r2 = pd.DataFrame(r2, columns=[typelabel[keys[i]] + 'n']) #转为DataFrame,记录给个类别的数目
r = pd.concat([r1, r2], axis=1).sort_values(typelabel[keys[i]]) #匹配聚类中心和类别数目
r.index = [1, 2, 3, 4]
r[typelabel[keys[i]]] = r[typelabel[keys[i]]].rolling(2).mean() #计算相邻两列的均值,以此作为边界点
r.loc[1, typelabel[keys[i]]] = 0.0 #将原来的聚类中心改为边界点
result = result.append(r.T)
result = result.sort_index()
result

数据整理:
# 建模数据,书中是自带的,这里自己建
# 转自 https://blog.csdn.net/qq_36890572/article/details/78714998
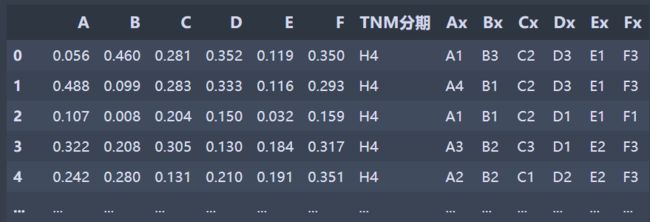
df = data[['肝气郁结证型系数', '热毒蕴结证型系数', '冲任失调证型系数', '气血两虚证型系数', '脾胃虚弱证型系数', '肝肾阴虚证型系数', 'TNM分期']].copy()
df.columns = ['A','B','C','D','E','F', 'TNM分期']
df.loc[(df.A > result.iloc[0, 0]) & (df.A < result.iloc[0, 1]), 'Ax'] = 'A1'
df.loc[(df.A > result.iloc[0, 1]) & (df.A < result.iloc[0, 2]), 'Ax'] = 'A2'
df.loc[(df.A > result.iloc[0, 2]) & (df.A < result.iloc[0, 3]), 'Ax'] = 'A3'
df.loc[(df.A > result.iloc[0, 3]), 'Ax']= 'A4'
df.loc[(df.B > result.iloc[2, 0]) & (df.B < result.iloc[2, 1]), 'Bx'] = 'B1'
df.loc[(df.B > result.iloc[2, 1]) & (df.B < result.iloc[2, 2]), 'Bx'] = 'B2'
df.loc[(df.B > result.iloc[2, 2]) & (df.B < result.iloc[2, 3]), 'Bx'] = 'B3'
df.loc[(df.B > result.iloc[2, 3]), 'Bx']= 'B4'
df.loc[(df.C > result.iloc[4, 0]) & (df.C < result.iloc[4, 1]), 'Cx'] = 'C1'
df.loc[(df.C > result.iloc[4, 1]) & (df.C < result.iloc[4, 2]), 'Cx'] = 'C2'
df.loc[(df.C > result.iloc[4, 2]) & (df.C < result.iloc[4, 3]), 'Cx'] = 'C3'
df.loc[(df.C > result.iloc[4, 3]), 'Cx']= 'C4'
df.loc[(df.D > result.iloc[6, 0]) & (df.D < result.iloc[6, 1]), 'Dx'] = 'D1'
df.loc[(df.D > result.iloc[6, 1]) & (df.D < result.iloc[6, 2]), 'Dx'] = 'D2'
df.loc[(df.D > result.iloc[6, 2]) & (df.D < result.iloc[6, 3]), 'Dx'] = 'D3'
df.loc[(df.D > result.iloc[6, 3]), 'Dx']= 'D4'
df.loc[(df.E > result.iloc[8, 0]) & (df.E < result.iloc[8, 1]), 'Ex'] = 'E1'
df.loc[(df.E > result.iloc[8, 1]) & (df.E < result.iloc[8, 2]), 'Ex'] = 'E2'
df.loc[(df.E > result.iloc[8, 2]) & (df.E < result.iloc[8, 3]), 'Ex'] = 'E3'
df.loc[(df.E > result.iloc[8, 3]), 'Ex']= 'E4'
df.loc[(df.F > result.iloc[10, 0]) & (df.F < result.iloc[10, 1]), 'Fx'] = 'F1'
df.loc[(df.F > result.iloc[10, 1]) & (df.F < result.iloc[10, 2]), 'Fx'] = 'F2'
df.loc[(df.F > result.iloc[10, 2]) & (df.F < result.iloc[10, 3]), 'Fx'] = 'F3'
df.loc[(df.F > result.iloc[10, 3]), 'Fx']= 'F4'
8.2.3 模型构建
关联规则算法主要用于寻找数据集中项之间的关联关系。它揭示了数据项间的未知关系,基于样本的统计规律,进行关联规则挖掘。根据所挖掘的关联关系,可以从一个属性的信息来推断另一个属性的信息。当置信度达到某一阈值时,就可以认为规则成立。
1.中医证型关联规则模型

经过多次调整并结合实际业务分析,选取模型的输入参数为:最小支持度为6%、最小置信度为75%
转换数据格式:
#Apriori关联规则算法
from __future__ import print_function
import pandas as pd
from apriori import *
import time #导入时间库用来计算用时
inputfile = 'G:/Python数据分析与挖掘实战/chapter8/demo/data/apriori.txt'
data = pd.read_csv(inputfile, header=None, dtype=object)
start = time.clock() #计时开始
print(u'\n转换原始数据之至0-1矩阵...')
ct = lambda x : pd.Series(1, index=x[pd.notnull(x)])
b = map(ct, data.values)
data = pd.DataFrame(b).fillna(0)
end = time.clock() #计时结束
print(u'\n转换完毕,用时:%0.2f秒' % (end-start))
del b
关联规则探索:
support = 0.06 #最小支持度
confidence = 0.75 #最小置信度
ms = '---' #连接符
start = time.clock()
print(u'\n开始搜索关联规则...')
find_rule(data, support, confidence, ms)
end = time.clock()
print(u'\n搜索完成,用时:%0.2f秒' % (end-start))
2.模型分析
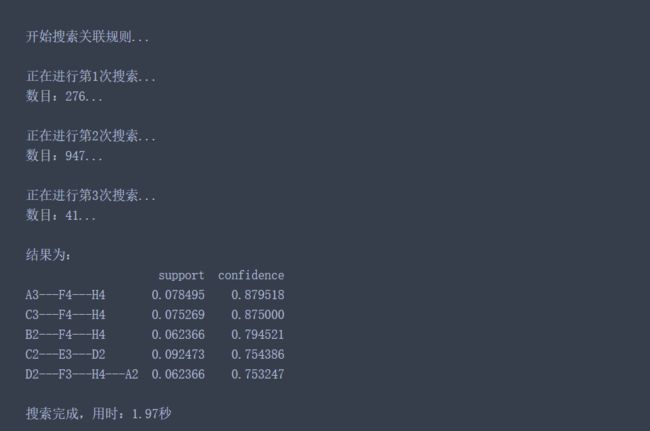
根据上述运行结果,我们得出了5个关联规则。但是,并非所有关联规则都有意义,我们只在乎那些以H为规则结果的规则,整理如下:

- A3、F4=>H4支持度最大,达到7.85%,置信度最大,达到87.96%,说明A3肝气郁结证型系数处于(0.258, 0.35],肝肾阴虚证型系数处于(0.353, 0.607]范围内,TNM分期诊断为H4期的可能性为87.96%,而这种情况发生的可能性为7.85%
- 其他情况类似
综合以上分析,TNM分期为H4期的患者证型主要为肝肾阴虚证F4、热毒蕴结证B、肝气郁结证和冲任失调,H4期患者肝肾阴虚证和肝气郁结证的临床表现较为突出,其置信度最大达到87.96%。