C++面试题汇总
目录
1、C++三大特性
1.1 封装
1.2 继承
1.3 多态
2、 C++中map与unordered_map的区别
3、 unordered系列关联式容器
4、 STL常用函数,容器和使用容器的方法
5、map的底层实现,存储的是什么,实现的时间复杂度
6、虚函数
6.1 什么是虚函数
6.2 虚函数和纯虚函数的区别
7、C++ set和map的区别
8、C++(面试题):给40亿个不重复的无符号整数,没排过序,如何快速判断一个数是否在这40亿个数中
9、C++一行代码实现xxx
9.1 一行代码实现strlen,求字符串长度
9.2 一行代码求平方根
10、C++线程互斥锁
11、指针和引用的区别
12、TCP/IP四层协议分别是什么
13、堆和栈的区别
14、C++智能指针
15、TCP三次握手
16、进程线程区别
17、C++三大特性
18.1 为什么使用动态内存?
18.2 动态内存在哪里?
18.3 自由存储区和堆
18.4 动态内存和智能指针
18.5 在哪里经常用到unique_ptr?
19. 普通指针如何实现一块内存只能有一个指针指向这种功能
20. C++深拷贝和浅拷贝
20.1 什么时候需要进行深拷贝?
21. 重建二叉树
21.1 剑指offer第4题
21.2 普通的数组重建二叉树
22. 实现一个稀疏矩阵的数据结构,并实现稀疏矩阵的加法。
23. 数组和链表的区别?
24. 数组和vector的比较?
24.1 数组和vector的对比
24.2 数组相关知识汇总
24.3 vector相关知识汇总
25. C++分配内存的4种方式
26. 构造函数可以为虚函数吗?父类的析构函数为什么是虚函数?
27. 你了解的锁机制?
28. C++什么情况下必须用初始化列表?
29. C++ new和malloc的区别
1、C++三大特性
C++为了更好的实现面向对象的编程思想,于是引入了新的数据类型——类。由此衍生出三大特性:(1)封装。(2)继承。(3)多态。
1.1 封装
C++类将类中成员分为三种属性:private、protected、public
(1)私有成员(变量和函数)只限于类成员访问,由private限定;
(2)公有成员(变量和函数)允许类成员和类外的任何访问,由public限定;
(3)受保护成员(变量和函数)允许类成员和派生类成员访问,不允许类外的任何访问。所以protected对外封闭,对派生类开放。
C++这样做都是有道理的,实现了很好的封装,这就是C++的第一个重要特性:封装。
1.2 继承
面向对象程序设计中最重要的一个概念是继承。继承允许我们依据另一个类来定义一个类,这使得创建和维护一个应用程序变得更容易。这样做,也达到了重用代码功能和提高执行效率的效果。
当创建一个类时,不需要重新编写新的数据成员和成员函数,只需指定新建的类继承了一个已有的类的成员即可。这个已有的类称为基类,新建的类称为派生类。
1.3 多态
基类指针可以按照基类的方式来做事,也可以按照派生类的方式来做事,它有多种形态,或者说有多种表现方式,我们将这种现象称为多态(Polymorphism)。多态的实现机制为虚函数。
虚函数的作用是允许在派生类中重新定义与基类同名的函数,并且可以通过基类指针或引用来访问基类和派生类的同名函数。
方法是在基类中为同名函数添加关键字virtual
1.3.1 多态的实现原理,虚函数是怎么实现的
多态的实现机制为虚函数。
C++实现虚函数的原理是虚函数表+虚表指针。
当一个类里存在虚函数时,编译器会为类创建一个虚函数表,虚函数表是一个数组,数组的元素存放的是类中虚函数的地址。
同时为每个类的对象添加一个隐藏成员,该隐藏成员保存了指向该虚函数表的指针。该隐藏成员占据该对象的内存布局的最前端。
所以虚函数表只有一份,而有多少个对象,就对应多少个虚函数表指针。
2、 C++中map与unordered_map的区别
(1)头文件
map: #include < map >
unordered_map: #include < unordered_map >(2)内部实现机理
- map: map内部实现了一个红黑树,该结构具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素,因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行这样的操作,故红黑树的效率决定了map的效率。
- unordered_map: unordered_map内部实现了一个哈希表,因此其元素的排列顺序是杂乱的,无序的。
(3)优缺点以及适用处
map
优点:
- 有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作
- 红黑树,内部实现一个红黑书使得map的很多操作在lgnlgn的时间复杂度下就可以实现,因此效率非常的高。
缺点:
- 空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点,孩子节点以及红/黑性质,使得每一个节点都占用大量的空间。
- 适用处,对于那些有顺序要求的问题,用map会更高效一些。
unordered_map
- 优点:
- 因为内部实现了哈希表,因此其查找速度非常的快。
- 缺点:
- 哈希表的建立比较耗费时间。
- 适用处,对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map。
(4)note
对于unordered_map或者unordered_set容器,其遍历顺序与创建该容器时输入元素的顺序是不一定一致的,遍历是按照哈希表从前往后依次遍历的。
3、 unordered系列关联式容器
unordered系列容器是C++11中,新增加的4个关联式容器,这四个关联式容器与红黑树结构的关联式容器使用方式基本相同,只是在底层实现的结构不同。
unordered_map
1.unordered_map是存储
2.在unordered_map中,键值通常用于唯一的标记元素,而映射值是一个对象,其内容与键值关联,键值和映射值的类型可能不同。
3.在内部unordered_map中的键值对是无序的。
4.unordered_map容器通过key访问单个元素要比map快,但它在遍历元素子集的范围迭代方面效率比较低。
5.unordered_map实现了直接访问符(operator[]),它允许使用key作为参数直接访问value。
3.1 容器用过哪些,底层是什么
-
vector:底层数组
-
list:底层链表
-
unordered_map:底层哈希表
-
map:底层红黑树
4、 STL常用函数,容器和使用容器的方法
5、map的底层实现,存储的是什么,实现的时间复杂度
红黑树。
键值对。
6、虚函数
虚函数的使用方法是:
- 在基类用virtual声明成员函数为虚函数。
这样就可以在派生类中重新定义此函数,为它赋予新的功能,并能方便地被调用。在类外定义虚函数时,不必再加virtual。
2. 在派生类中重新定义此函数,要求函数名、函数类型、函数参数个数和类型全部与基类的虚函数相同,并根据派生类的需要重新定义函数体。
C++规定,当一个成员函数被声明为虚函数后,其派生类中的同名函数都自动成为虚函数。因此在派生类重新声明该虚函数时,可以加virtual,也可以不加,但习惯上一般在每一层声明该函数时都加virtual,使程序更加清晰。如果在派生类中没有对基类的虚函数重新定义,则派生类简单地继承其直接基类的虚函数。
3.定义一个指向基类对象的指针变量,并使它指向同一类族中需要调用该函数的对象。
4. 通过该指针变量调用此虚函数,此时调用的就是指针变量指向的对象的同名函数。
通过虚函数与指向基类对象的指针变量的配合使用,就能方便地调用同一类族中不同类的同名函数,只要先用基类指针指向即可。如果指针不断地指向同一类族中不同类的对象,就能不断地调用这些对象中的同名函数。这就如同前面说的,不断地告诉出租车司机要去的目的地,然后司机把你送到你要去的地方。
6.1 什么是虚函数
虚函数是指一个类中你希望重载的成员函数 ,当你用一个 基类指针或引用 指向一个继承类对象的时候,调用一个虚函数时, 实际调用的是继承类的版本。
6.2 虚函数和纯虚函数的区别
定义一个函数为虚函数,不代表函数为不被实现的函数。
定义他为虚函数是为了允许用基类的指针来调用子类的这个函数。
定义一个函数为纯虚函数,才代表函数没有被实现。
定义纯虚函数是为了实现一个接口,起到一个规范的作用,规范继承这个类的程序员必须实现这个函数。
7、C++ set和map的区别
set是一种关联式容器,其特性如下:
- set以RBTree作为底层容器
- 所得元素的只有key没有value,value就是key
- 不允许出现键值重复
- 所有的元素都会被自动排序
- 不能通过迭代器来改变set的值,因为set的值就是键
map和set一样是关联式容器,它们的底层容器都是红黑树,区别就在于map的值不作为键,键和值是分开的。它的特性如下:
- map以RBTree作为底层容器
- 所有元素都是键+值存在
- 不允许键重复
- 所有元素是通过键进行自动排序的
- map的键是不能修改的,但是其键对应的值是可以修改的
代码中map的应用,在获取参数配置文件值时,常用到map。在rgb-d slam中,从.txt文件中获取参数,就使用map进行存储和查找,代码如下:
// 参数读取类
class ParameterReader
{
public:
ParameterReader(string filename="/home/zlc/WorkCode/rgbd-slam/parameters.txt")
{
ifstream fin(filename.c_str());
if (!fin)
{
cerr << "parameter file does not exist." << endl;
return;
}
while(!fin.eof())
{
string str;
getline(fin, str); // 一次读一行,存入str
if (str[0] == '#')
{
// 以’#’开头的是注释
continue;
}
int pos = str.find("="); // “=”为分界线
if (pos == -1) // 行中没有“=”,默认无效
continue;
string key = str.substr(0, pos); // 分界线以前是关键字
string value = str.substr(pos+1, str.length()); // 分界线以后是关键字的值
data[key] = value;
if (!fin.good())
break;
}
}
string getData(string key)
{
map::iterator iter = data.find(key);
if (iter == data.end())
{
cerr << "Parameter name " << key << " not found!" << endl;
return string("NOT_FOUND");
}
return iter->second;
}
public:
map data;
};
8、C++(面试题):给40亿个不重复的无符号整数,没排过序,如何快速判断一个数是否在这40亿个数中
首先看到这个题第一个想到的就是遍历一遍,看这个数在不在。但是这样的时间复杂度太高了O(N),数据量太大,因此该方法不行。
其次我们想到排序,利用二分查找,时间复杂度是O(logN),但是排序本身就有很大的消耗,并且40亿个数据内存一次也存不下。
那么就采用位图!位图就是用来判断一个数据在不在的最好方法了!
- 位图是一种直接定址法的哈希,因此效率很高,用O(1)就可以探测到对应位是0还是1,效率非常高,因此可以快速判断。
- 40亿个数据,我们可以大概计算一下,一个数据4字节,那么40亿数据就是160亿字节。我们都知道4G大概是42亿九千万字节,那么1G大概也就是10亿字节,所以160亿字节大约就是16G,因此要把40亿个数据存放到内存中需要16G的内存空间。数据量还是非常大的,如果我们采用位图的话,一个数据就占一个比特位,42亿九千万个字节需要512M就可以存下,因此用位图存的话也节省了空间。【但是这里我们开空间的话需要注意要开42亿九千万字节,有人可能会有疑问?为什么不是40亿,题目不就是40亿个数据吗?但是我们要注意,位图开的是一个范围,因为难免这40亿个数据中会有大于40亿的数据出现,万一出现一个大小为41亿的数据呢,那我们把这个数据映射到哪里呢,所以开的范围是就是42亿九千万字节,一个位置对应一个数】
- 使用位图,先将这些数遍历一般进行set(把每个出现的数据的对应位图的位置为1),然后要查找某个数在不在时,直接test这个数即可,返回真就是存在,返回假就是不存在。
9、C++一行代码实现xxx
这里总结以下几个一行代码实现某功能的代码,从中找出规律,以后再遇到这种题就知道如何处理了。
一般的步骤是:
1. 想一下是否需要判空,使用assert断言操作;
2. 思考函数或者任务的判断逻辑,将问题进行划分;
3. 分情况具体处理。
9.1 一行代码实现strlen,求字符串长度
#include
#include
int strlen(const char* s)
{
// assert(NULL);
return assert(s), ( *s? strlen(s+1) + 1 : 0 ); // 0+1+1+1
} // 这里要在注意空指针NULL和空串" "
// 空指针表示内存中没有这个东西,而空字符串也是字符串
int main(int argc, char* *argv)
{
printf("%d\n", strlen("jacob2359"));
printf("%d\n", strlen(NULL));
return 0;
} 输出结果:
9
a.out: 2.c:6: strlen: Assertion `s' failed.
已放弃9.2 一行代码求平方根
首先思考是否需要判空操作,如果指针表示待求平方根数据,那么肯定需要判空操作;
接下来就是处理逻辑,因为负数在实数内没有平方根,所以以此为判断条件。
#include
#include
int main(){
double root;
double data = 200;
// root = sqrt(200);
data >= 0? root=sqrt(data) : root=0;
printf("answer is %f\n", root);
return 0;
}
/*
输出:answer is 14.142136
*/ 负数没有平方根。只有正数和0有平方根,正数的平方根互为相反数,0的平方根是0,算数平方根也只有正数和0有,那么一个数的算术平方根就是那个数平方根中的正数。负数在实数系内没有平方根,只有在复数系内,负数有一对平方根。负数的平方根为一对共轭纯虚数。例如:-1的平方根为±i,-9的平方根为±3i,其中i为虚数单位。
平方根,是指自乘结果等于的实数,表示为±(√x),读作正负根号下x或x的平方根。其中的非负数的平方根称为算术平方根。正整数的平方根通常是无理数。
PS:这里可能答得不对,可能就是想让我们实现sqrt这个函数,具体参见:https://blog.csdn.net/Riverhope/article/details/78866861
代码如下:
import math
if __name__ == "__main__":
learning_rate = 0.01
for a in range(1,100):
cur = 0
for i in range(1000):
cur -= learning_rate*(cur**2 - a)
print(' %d的平方根(近似)为:%.8f,真实值是:%.8f' % (a, cur, math.sqrt(a)))
10、C++线程互斥锁
mutex多线程互斥锁 m_buf。std::unique_lock
condition_variable 条件变量 con
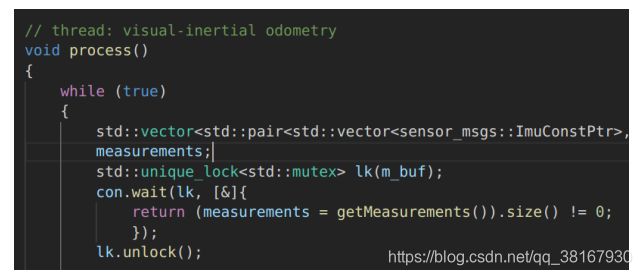
- IMU、图像、后端三个线程共用一个m__buf,后端process()线程调用wait(),自动调用m_buf.lock()来加锁;
- 若getMeasurements未得到图像和两帧之间的IMU,则返回false,线程被阻塞,此时,wait(0会自动调用m_buf.unlock()来释放锁,使得IMU和feature的回调线程继续push。
- imu和feature的回调线程,每拿到数据,都会调用con.notify_one唤醒process()线程,使其继续尝试getMeasurements。
11、指针和引用的区别
(1)指针是实体,占用内存空间;引用是别名,与变量共享内存空间;
(2)指针不用初始化或初始化为NULL;引用定义时必须初始化;
(3)指针中途可以修改指向;引用不可以;
(4)指针可以为NULL;引用不能为空;
(5)sizeof(指针)计算的是指针本身的大小;而sizeof(引用)计算的是它引用对象的大小;
(6)如果返回的是动态分配的内存或对象,必须使用指针,使用引用会产生内存泄露;
(7)指针使用时需要解引用;引用使用时不需要解引用;
(8)有二级指针;没有二级引用。
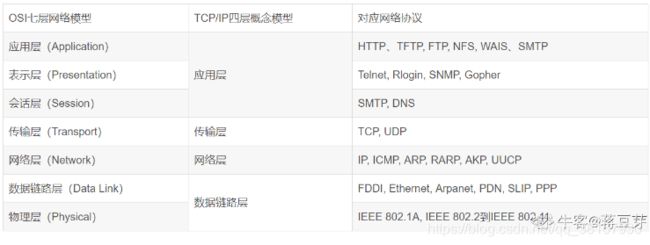
12、TCP/IP四层协议分别是什么
13、堆和栈的区别
1、申请方式的不同。栈由系统自动分配,而堆是人为申请开辟;
2、申请大小的不同。栈获得的空间较小,而堆获得的空间较大;
3、申请效率的不同。栈由系统自动分配,速度较快,而堆一般速度比较慢;
4、存储内容的不同。栈在函数调用时,函数调用语句的下一条可执行语句的地址第一个进栈,然后函数的各个参数进栈,其中静态变量是不入栈的。而堆一般是在头部用一个字节存放堆的大小,堆中的具体内容是人为安排;
5、底层不同。栈是连续的空间,而堆是不连续的空间。
14、C++智能指针
1.智能指针的由来--- 内存泄露
- 动态申请堆空间,用完后不归还
- C++ 语言中没有垃圾回收机制
- 指针无法控制所指堆空间的生命周期
2.智能指针示例:当代C++ 软件平台中的智能指针:
- 指针声明周期结束时 主动释放堆空间
- 一片堆空间 最多 只能由一个指针标识
- 杜绝 指针运算和指针比较
智能指针的使用军规:只能用来指向堆空间中的单个对象或者变量。
#ifndef _SMARTPOINTER_H_
#define _SMARTPOINTER_H_
using namespace std;
namespace JMLib
{
template // 使用模板技术
class SmartPointer
{
protected:
T* m_pointer;
public:
SmartPointer(T* p = NULL) // 默认为空
{
m_pointer = p;
}
// 完成堆空间最多只能由一个指针标识
SmartPointer(const SmartPointer& obj)
{
m_pointer = obj.m_pointer;
const_cast&>(obj).m_pointer = NULL;
// 强制类型转换,去掉const属性
}
SmartPointer& operator = (const SmartPointer& obj) // 使用引用见解析
{
if( this != &obj ) // 确保不是自赋值
{
delete m_pointer;
m_pointer = obj.m_pointer;
const_cast&>(obj).m_pointer = NULL;
}
return *this;
}
T* operator -> ()
{
return m_pointer;
}
T& operator * () // 使用引用,使结果可以当左值连续使用
{
return *m_pointer;
}
bool isNull() // 指针m_pointer 是空, 则返回 1; 非空返回 0
{
cout << "isNull:";
return (m_pointer == NULL);
}
T* get()
{
return m_pointer;
}
~SmartPointer()
{
delete m_pointer;
}
};
}
#endif // _SMARTPOINTER_H_ 15、TCP三次握手
tcp三次握手。进程线程区别。
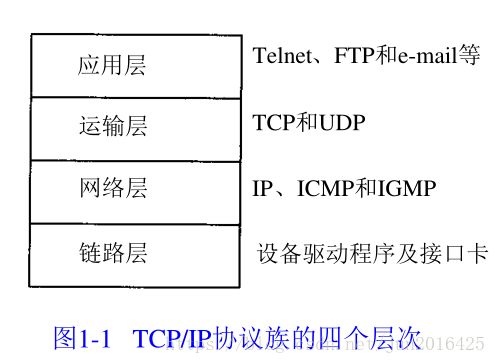
TCP是属于网络分层中的传输层,因为OSI分为7层,感觉太麻烦了,所以分为四层就好了,简单。
分层以及每层的协议,TCP是属于传输层,如下两张图:
TCP三次握手如图:
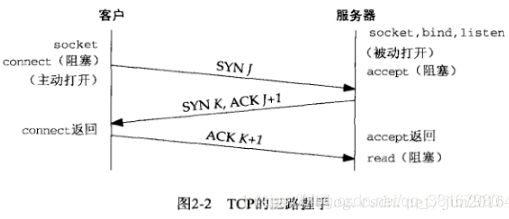
第一次握手:
客户主动(active open)去connect服务器,并且发送SYN 假设序列号为J,服务器是被动打开(passive open)。
第二次握手:
服务器在收到SYN后,它会发送一个SYN以及一个ACK(应答)给客户,ACK的序列号是 J+1表示是给SYN J的应答,新发送的SYN K 序列号是K。
第三次握手:
客户在收到新SYN K, ACK J+1 后,也回应ACK K+1 以表示收到了,然后两边就可以开始数据发送数据了。
符号含义:位码即tcp标志位,有6种标示:SYN(synchronous建立联机) ACK(acknowledgement 确认) PSH(push传送) FIN(finish结束) RST(reset重置) URG(urgent紧急)Sequence number(顺序号码) Acknowledge number(确认号码)
16、进程线程区别
进程是资源分配的最小单位,线程是CPU调度的最小单位。
做个简单的比喻:进程=火车,线程=车厢
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-"互斥锁"
- 进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
进程 是系统分配资源的最小单位。
线程 是系统调度的最小单位。
线程是程序最基本的运行单位,而进程是不能运行的,运行的是进程中的线程。创建进程时,系统会自动创建一个主线程来运行进程中的数据信息。
我们运行main()函数的时候,就会创建一个主进程和一个主线程,当我们在主线程中创建更多的子线程后:
调用exit()函数:主进程和主线程都退出,子线程自然也要退出。
调用pthread_exit()函数:主线程退出,但是主进程依旧存在,所以进程中的子线程可以继续运行。
在程序中使用多进程多线程时,曾经出现ctrl c强制退出程序后,仍然有线程在后台执行,要手动kill掉。是因为父进程死亡后,主进程中的线程跟随主进程一起退出了,而子进程由系统1号进程进行管理,所以子进程中的线程还可以继续运行。这就导致我在调试运行程序的时候经常会出现报错,原因是因为后台中的子进程还在运行导致的。所以在处理进程和线程时,要几时对线程和进程资源进行回收,避免出错。
17、C++三大特性
封装:把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。封装是面向对象的特征之一,是对象和类概念的主要特性。简单地说,一个类就是一个封装了数据以及操作这些数据的代码的逻辑实体。在一个对象内部,某些代码或某些数据是可以私有的,不能被外界访问。通过这种方式,对象对内部数据提供了不同级别的保护,以防止程序中无关的部分意外地改变或错误的使用了对象的私有部分。
C++类中成员分为三种属性:private、protected、public
(1)私有成员(变量和函数)只限于类成员访问,由private限定;
(2)公有成员(变量和函数)允许类成员和类外的任何访问,由public限定;
(3)受保护成员(变量和函数)允许类成员和派生类成员访问,不允许类外的任何访问。所以protected对外封闭,对派生类开放。
继承:指可以让某个类型的对象获得另一个类型的对象的属性的方法。它支持按级分类的概念。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。 通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”。继承的过程,就是从一般到特殊的过程。要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。继承概念的实现方式有二类:实现继承与接口继承。实现继承是指直接使用基类的属性和方法而无需额外编码的能力;接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力;
面向对象程序设计中最重要的一个概念是继承。继承允许我们依据另一个类来定义一个类,这使得创建和维护一个应用程序变得更容易。这样做,也达到了重用代码功能和提高执行效率的效果。当创建一个类时,不需要重新编写新的数据成员和成员函数,只需指定新建的类继承了一个已有的类的成员即可。这个已有的类称为基类,新建的类称为派生类。
多态:指一个类实例的相同方法在不同情形有不同表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。
基类指针可以按照基类的方式来做事,也可以按照派生类的方式来做事,它有多种形态,或者说有多种表现方式,我们将这种现象称为多态(Polymorphism)。多态的实现机制为虚函数。虚函数的作用是允许在派生类中重新定义与基类同名的函数,并且可以通过基类指针或引用来访问基类和派生类的同名函数。方法是在基类中为同名函数添加关键字virtual。
18. 说一下智能指针,shared_ptr与unique_ptr
unique_ptr:拥有管理内存的所有权,没有拷贝构造函数,只有移动构造函数,不能多个unique_ptr对象共享一片内存,可以自定义delete函数,从而支持delete[]。
share_ptr:通过计数方式,多个share_ptr可以共享一段内存,当前计数为0的时候,所管理的内存会被删除,可以自定义delete函数,从而支持delete[]。
智能指针的由来——内存泄露,包含以下三种情况:
- 动态申请堆空间,用完后不归还
- C++语言中没有垃圾回收机制
- 指针无法控制所指堆空间的生命周期
当代C++软件平台中的智能指针:
- 指针声明周期结束时,主动释放堆空间
- 一片堆空间最多只能有一个指针标识
- 杜绝指针运算与指针比较
智能指针的使用军规:只能用来指向堆空间中的单个对象或者变量。
智能指针的最大意义在于最大程度地避免内存问题。
18.1 为什么使用动态内存?
程序不知道自己需要多少对象;
程序不知道对象的准确类型;
程序需要在多个对象之间共享数据。
18.2 动态内存在哪里?
程序有静态内存、栈内存。
一、静态内存用来保存①局部static对象、②类static数据成员以及③定义在任何函数之外的变量。
二、栈内存用来保存定义在函数内的非static对象。分配在静态或者栈内存中的对象由编译器自动创建或销毁。对于栈对象,仅在其定义的程序块运行时才存在;static对象在使用之前分配,在程序结束时销毁。
三、除了静态内存和栈内存,每个程序还拥有一个内存池。这部分内存被称作自由空间或堆。程序用堆来存储动态分配的对象——即,那些在程序运行时分配的对象。动态对象的生存周期由程序来控制,也就是说,当动态对象不再使用时,我们的代码必须显示地销毁它们。
18.3 自由存储区和堆
自由存储是C++中通过new和delete动态分配和释放对象的抽象概念,通过new来申请的内存区域可称为自由存储区。
堆是操作系统维护的一块内存。
虽然C++编译器默认使用堆来实现自由存储,但二者不能等价。
18.4 动态内存和智能指针
我们知道C++需要注意的地方之一就是对内存的管理,动态内存的使用经常会出现内存泄露,或者产生引用非法内存的指针。新的标准库提供了两种智能指针类型来管理动态对象:
(1)shared_ptr允许多个指针指向同一个对象;
(2)unique_ptr独占所指向的对象。
定义在memory头文件中,它们的作用在于会自动释放所指向的对象。
18.5 在哪里经常用到unique_ptr?
在使用新版g2o时,定义BlockSolver以及总求解器solver时会用到std::unique_ptr指针,代码如下:
void bundleAdjustment (
const vector< Point3f > points_3d,
const vector< Point2f > points_2d,
const Mat& K,
Mat& R, Mat& t )
{
// 第0步:初始化g2o
typedef g2o::BlockSolver< g2o::BlockSolverTraits<6,3> > Block; // pose维度为6,landmark维度为3
// 第1步:创建一个线性求解器LinearSolver
Block::LinearSolverType* linearSolver = new g2o::LinearSolverCSparse(); // 线性方程求解器
// 第2步:创建BlockSolver,并用上面定义的线性求解器初始化
Block* solver_ptr = new Block( std::unique_ptr(linearSolver) );
// Block* solver_ptr = new Block ( linearSolver ); // 矩阵块求解器
// 第3步:创建总求解器solver,并从GN,LM,Dogleg中选一个,再用上述块求解器BlockSolver初始化
g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg(std::unique_ptr(solver_ptr));
// g2o::OptimizationAlgorithmLevenberg* solver = new g2o::OptimizationAlgorithmLevenberg(solver_ptr);
// 第4步:创建稀疏优化器
g2o::SparseOptimizer optimizer;
optimizer.setAlgorithm( solver ); // ☆☆☆ 设置优化算法,使用那种方法定义非线性优化的下降策略 △△△
// 第5步:添加顶点和边
// vertex
g2o::VertexSE3Expmap* pose = new g2o::VertexSE3Expmap(); // camera pose,g2o原生李代数位姿节点
Eigen::Matrix3d R_mat; // 注意CV中的矩阵与Eigen中的矩阵相互转换
R_mat <<
R.at (0,0), R.at (0,1), R.at (0,2),
R.at (1,0), R.at (1,1), R.at (1,2),
R.at (2,0), R.at (2,1), R.at (2,2);
pose->setId(0);
pose->setEstimate( g2o::SE3Quat(
R_mat,
Eigen::Vector3d( t.at(0,0), t.at(1,0), t.at(2,0) )
) ); // 定义相机位姿使用SE3Quat,这个类内部使用四元数加位移向量来存储位姿
optimizer.addVertex( pose );
int index = 1;
for ( const Point3f p:points_3d ) // landmarks,第一幅图坐标系下的三维空间点
{
g2o::VertexSBAPointXYZ* point = new g2o::VertexSBAPointXYZ();
point->setId( index ++ );
point->setEstimate( Eigen::Vector3d( p.x, p.y, p.z ) );
point->setMarginalized( true ); // g2o中必须设置marg参见第10讲内容
optimizer.addVertex( point );
}
// parameter: camera intrinsics 相机内参
g2o::CameraParameters* camera = new g2o::CameraParameters(
K.at (0,0), Eigen::Vector2d(K.at(0,2), K.at(1,2)), 0
);
camera->setId( 0 );
optimizer.addParameter( camera );
// edges
index = 1;
for ( const Point2f p:points_2d )
{
g2o::EdgeProjectXYZ2UV* edge = new g2o::EdgeProjectXYZ2UV();
edge->setId( index );
edge->setVertex ( 0, dynamic_cast ( optimizer.vertex(index) ) ); // 边的一个顶点是第一帧照片相机坐标系下的 空间点位置
edge->setVertex ( 1, pose ); // 边的一个固定顶点是相机位姿
edge->setMeasurement( Eigen::Vector2d(p.x, p.y) ); // 测量点(u,v)
edge->setParameterId( 0,0 );
edge->setInformation( Eigen::Matrix2d::Identity() );
optimizer.addEdge( edge );
index ++;
}
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
optimizer.setVerbose(true);
optimizer.initializeOptimization(); //
optimizer.optimize( 100 ); // 开始优化
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration time_used = chrono::duration_cast> ( t2-t1 );
cout << "optimization costs time: " << time_used.count() << " seconds." << endl;
cout << endl << "after optimization: " << endl;
cout << "T = " << Eigen::Isometry3d ( pose->estimate() ).matrix() << endl;
} 19. 普通指针如何实现一块内存只能有一个指针指向这种功能
我们可以重载指针的拷贝构造函数和赋值函数。代码如下:
T* m_pointer;
// 完成堆空间最多只能有一个指针标识
SmartPointer(const SmartPointer& obj)
{
m_pointer = obj.m_pointer; // 新指针指向原指针的堆空间
const_cast&>(obj).m_pointer = NULL; // 原指针清空
// 强制类型转换,去掉const属性
}
SmartPointer& operator = (const SmartPointer& obj)
{
// 确保不是自赋值
if (this != &obj)
{
delete m_pointer;
m_pointer = obj.m_pointer;
const_cast&>(obj).m_pointer = NULL;
}
return *this;
} 完整的smartpointer.h文件如下,参见《狄泰软件学院智能指针》一节:
#ifndef _SMARTPOINTER_H_
#define _SMARTPOINTER_H_
using namespace std;
namespace JMLib
{
template // 使用模板技术
class SmartPointer
{
protected:
T* m_pointer;
public:
SmartPointer(T* p = NULL) // 默认为空
{
m_pointer = p;
}
// 完成堆空间最多只能由一个指针标识
SmartPointer(const SmartPointer& obj)
{
m_pointer = obj.m_pointer;
const_cast&>(obj).m_pointer = NULL;
// 强制类型转换,去掉const属性
}
SmartPointer& operator = (const SmartPointer& obj) // 使用引用见解析
{
if( this != &obj ) // 确保不是自赋值
{
delete m_pointer;
m_pointer = obj.m_pointer;
const_cast&>(obj).m_pointer = NULL;
}
return *this;
}
T* operator -> ()
{
return m_pointer;
}
T& operator * () // 使用引用,使结果可以当左值连续使用
{
return *m_pointer;
}
bool isNull() // 指针m_pointer 是空, 则返回 1; 非空返回 0
{
cout << "isNull:";
return (m_pointer == NULL);
}
T* get()
{
return m_pointer;
}
~SmartPointer()
{
delete m_pointer;
}
};
}
#endif // _SMARTPOINTER_H_ 20. C++深拷贝和浅拷贝
总结: 浅拷贝会把指针变量的地址复制; 深拷贝会重新开辟内存空间。释放一个对象,浅拷贝的对象再释放会出错。
class Test
{
private:
int* p;
public:
Test(int x)
{
this->p=new int(x);
cout << "对象被创建" << endl;
}
~Test()
{
if (p != NULL)
{
delete p;
}
cout << "对象被释放" << endl;
}
int getX() { return *p; }
//深拷贝(拷贝构造函数)
Test(const Test& a)
{
this->p = new int(*a.p);
cout << "对象被创建" << endl;
}
//浅拷贝(拷贝构造函数)
//Test(const Test& a)
//{
// this->p = a.p;
// cout << "对象被创建" << endl;
//}
};
int main()
{
Test a(10);
//我们手动的写拷贝构造函数,C++编译器会调用我们手动写的
Test b = a;
return 0;
}我们首先要知道默认拷贝构造函数可以完成对象的数据成员简单的复制,这也称为浅拷贝。当对象的数据资源是由指针指向的堆时,默认的拷贝构造函数只是将指针复制。
我们画一个示意图分析:
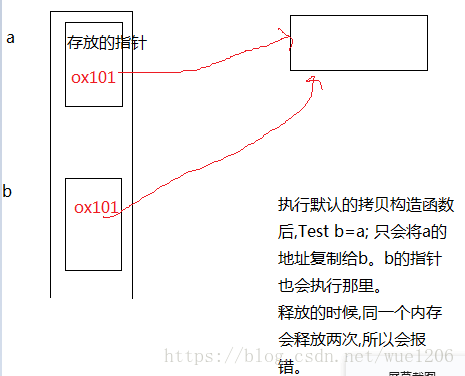
图片来自:https://blog.csdn.net/wue1206/article/details/81138097
20.1 什么时候需要进行深拷贝?
- 当对象成员有指针时
- 当对象成员需要打开文件时
- 需要链接数据库时
21. 重建二叉树
21.1 剑指offer第4题
这里的答案来自剑指offer中的第4个题,给定某二叉树的前序遍历和后序遍历,重建出二叉树并返回它的头结点。
/**
* Definition for binary tree
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* reConstructBinaryTree(vector pre,vector vin)
{
// 第一步:判空
if (0==pre.size() || 0==vin.size())
return nullptr;
return build_tree(pre, 0, pre.size()-1, vin, 0, vin.size()-1);
}
TreeNode*build_tree(vector pre, int pstart, int pend, vector inorder, int istart, int iend)
{
TreeNode* root = new TreeNode(pre[pstart]); // 根结点
// 找到先序遍历中根结点在中序遍历中的位置
int root_index_inorder = istart; // 中序遍历中根结点的位置
while (inorder[root_index_inorder] != pre[pstart])
root_index_inorder ++;
// 找到根结点在中序遍历中的位置之后,计算左右子树传长度
int left_len = root_index_inorder - istart;
int right_len = iend - root_index_inorder;
if (left_len > 0)
root->left = build_tree(pre, pstart+1, pstart+left_len, inorder, istart, root_index_inorder-1);
if (right_len > 0)
root->right = build_tree(pre, pstart+left_len+1, pend, inorder, root_index_inorder+1, iend);
return root;
}
}; 21.2 普通的数组重建二叉树
// 根据数组生成二叉树,如果数值为-1则表示空位
TreeNode* TreeHandler::createTree(vector& nums)
{
TreeNode* root = NULL;
if (nums.empty()) // 首先进行判空
{
return root;
}
root = new TreeNode(nums[0]);
queue q; // 建立队列 =============》 使用队列
q.push(root); // 存入根结点
for (unsigned int i=1; ileft_child = l;
q.push(l);
i ++;
}
else
i ++;
// 右子树
if (i < nums.size() && nums[i] != -1) // 不为空
{
TreeNode* r = new TreeNode(nums[i]);
p->right_child = r;
q.push(r);
i ++;
}
else
i ++;
q.pop();
}
return root;
} 22. 实现一个稀疏矩阵的数据结构,并实现稀疏矩阵的加法。
网上有一个答案,使用三元组实现了系数矩阵的加法,关键点除了系数矩阵加法C=A+B,还有三元组结构体的定义:
typedef int ElemType; // 抽象数据类型定义
typedef int Status; // 函数返回值
#define MAXSIZE 20 // 非零元个数的最大值
typedef struct
{
int i, j; // 行下标,列下标
ElemType e; // 非零元素值
} Triple;
typedef struct
{
Triple data[MAXSIZE + 1]; // 非零元三元组表,从data[1]开始使用
int mu, nu, tu; // 矩阵的行数、列数和非零元个数
} TSMatrix;整体代码如下:
#include
#include
#include
//常量定义
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int ElemType;//抽象数据类型定义
typedef int Status;//函数返回值
#define MAXSIZE 20 // 非零元个数的最大值
typedef struct {
int i, j; // 行下标,列下标
ElemType e; // 非零元素值
}Triple;
typedef struct {
Triple data[MAXSIZE + 1]; // 非零元三元组表,从data[1]开始使用
int mu, nu, tu; // 矩阵的行数、列数和非零元个数
}TSMatrix;
void AtoT(int num[][MAXSIZE],TSMatrix *T)//二维数组转三元组
{
T->tu = 1;
for(int i=1;i<=T->mu;i++)
{
for(int j=1;j<=T->nu;j++)
{
if(num[i][j]!=0)
{
T->data[T->tu].i = i;
T->data[T->tu].j = j;
T->data[T->tu].e = num[i][j];
T->tu++;
}
}
}
T->tu--;
}
void TtoA(TSMatrix T,int num[][MAXSIZE])//三元组转二维数组
{
for(int i=1;i<=T.tu;i++)
{
num[T.data[i].i][T.data[i].j] = T.data[i].e;
}
}
Status Create_Matrix(TSMatrix *T)
{
int num[MAXSIZE][MAXSIZE]={0};
printf("请输入稀疏矩阵的行数和列数\n");
scanf("%d %d", &T->mu, &T->nu);
printf("请输入稀疏矩阵的元素\n");
for (int i = 1; i <= T->mu; i++)
{
for (int j = 1; j <= T->nu; j++)
{
scanf("%d", &num[i][j]);
}
}
AtoT(num, T);//数组转三元组
}
// 输出稀疏矩阵M
void PrintSMatrix(TSMatrix M)
{
int i,num[MAXSIZE][MAXSIZE]={0};
printf(" %d 行, %d 列, %d 个非零元素。\n", M.mu, M.nu, M.tu);
printf("三元组为:\n");
printf("======================\n");
printf("%4s %4s %4s\n", "i", "j", "e");
printf("======================\n");
for (i = 1; i <= M.tu; i++)
printf("%4d %4d %4d\n", M.data[i].i, M.data[i].j, M.data[i].e);
printf("======================\n");
TtoA(M, num);
printf("矩阵为:\n");
printf("======================\n");
for (int i = 1; i <= M.mu; i++)
{
for (int j = 1; j <= M.nu; j++)
{
printf("%4d", num[i][j]);
}
printf("\n");
}
printf("======================\n");
}
// 三元组表示的稀疏矩阵加法: C=A+B
Status Matrix_Addition(TSMatrix A, TSMatrix B, TSMatrix *C)
{
int row_a, row_b,col_a, col_b, index_a, index_b, index_c;
//A元素的行号,B元素的行号,A元素的列号,B元素的列号,ABC矩阵三元组的地址
//因为同类型矩阵才能相加,所以相加后的矩阵行和列和原来来两个矩阵的行列一样
C->mu = A.mu;
C->nu = A.nu;
//行,列不相同的矩阵不能相加,返回ERROR
if (A.mu != B.mu || A.nu != B.nu) {
return ERROR;
}
//同时遍历两个三元组,开始都为1,因为0位置未存元素,当A或者B中其一元素取完循环终止
for(index_a=1,index_b=1,index_c=1;index_a<=A.tu&&index_b<=B.tu;)
{
row_a = A.data[index_a].i;//A矩阵元素的行号
row_b = B.data[index_b].i;//B矩阵元素的行号
col_a = A.data[index_a].j;//A矩阵元素的列号
col_b = B.data[index_b].j;//B矩阵元素的列号
//因为三元组是按行和列排好序的所以比较行数先判断是否来自同一行
if(row_a>row_b)//B的行号小于A直接将B中元素加入C矩阵
{
//复制B到C
C->data[index_c].i = B.data[index_b].i;
C->data[index_c].j = B.data[index_b].j;
C->data[index_c].e = B.data[index_b].e;
index_b++;//B矩阵地址加一表示向后取一个元素
index_c++;//C矩阵地址加一表示下一元素存放的地址
}
else if(row_adata[index_c].i = A.data[index_a].i;
C->data[index_c].j = A.data[index_a].j;
C->data[index_c].e = A.data[index_a].e;
index_a++;//A矩阵地址加一表示向后取一个元素
index_c++;//C矩阵地址加一表示下一元素存放的地址
}
else//行号相同时
{
//在判断列好号是否来自同一行
if(col_a>col_b)//B的列号小于A直接将B中元素加入C矩阵
{
//复制B到C
C->data[index_c].i = B.data[index_b].i;
C->data[index_c].j = B.data[index_b].j;
C->data[index_c].e = B.data[index_b].e;
index_b++;//B矩阵地址加一表示向后取一个元素
index_c++;//C矩阵地址加一表示下一元素存放的地址
}
else if(col_adata[index_c].i = A.data[index_a].i;
C->data[index_c].j = A.data[index_a].j;
C->data[index_c].e = A.data[index_a].e;
index_a++;//A矩阵地址加一表示向后取一个元素
index_c++;//C矩阵地址加一表示下一元素存放的地址
}
else//相等
{
//判断元素相加是否为零
if((A.data[index_a].e+B.data[index_b].e))//相加不为零
{
C->data[index_c].i = A.data[index_a].i;//赋值行号给C
C->data[index_c].j = A.data[index_a].j;//赋值列号给C
C->data[index_c].e = A.data[index_a].e + B.data[index_b].e;//赋值元素相加结果给C
index_c++;C矩阵地址加一表示下一元素存放的地址
}
//无论相加是否为零都执行
index_a++;//A矩阵地址加一表示向后取一个元素
index_b++;//B矩阵地址加一表示向后取一个元素
}
}
}
while (index_a <= A.tu)//B取完A未取完
{
//将A中所剩元素依次加入到C中
C->data[index_c].i = A.data[index_a].i;
C->data[index_c].j = A.data[index_a].j;
C->data[index_c].e = A.data[index_a].e;
index_a++;
index_c++;
}
while (index_b <= B.tu)//A取完B未取完
{
//将A中所剩元素依次加入到C中
C->data[index_c].i = B.data[index_b].i;
C->data[index_c].j = B.data[index_b].j;
C->data[index_c].e = B.data[index_b].e;
index_b++;
index_c++;
}
C->tu = index_c - 1;//index_c是在执行完逻辑后加一的所以比实际上多1,因此C中元素的真实个数为index_c-1
return OK;
}
int main()
{
TSMatrix A,B,C;
printf("创建矩阵A\n");
Create_Matrix(&A);
printf("矩阵A:\n");
PrintSMatrix(A);
printf("创建矩阵B\n");
Create_Matrix(&B);
printf("矩阵B:\n");
PrintSMatrix(B);
Matrix_Addition(A, B, &C);
printf("矩阵A加加矩阵B后\n");
PrintSMatrix(C);
} 23. 数组和链表的区别?
(1)数组是将元素在内存中连续存放,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素。但是如果要在数组中增加一个元素,需要移动大量元素,在内存中空出一个元素的空间,然后将要增加的元素放在其中。同样的道理,如果想要删除一个元素,同样需要移动大量元素去填掉被移动的元素,如果应用需要快速访问数据,很少或不插入和删除元素,就应该用数组。
(2)链表恰好相反,链表中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起。比如:上一个元素有个指针指到下一个元素,以此类推,直到最后一个元素。如果要访问链表中的一个元素,需要从第一个元素开始遍历,一直找到需要的元素位置。但是增加和删除一个元素对于链表数据结构就非常简单,只要删除元素中的指针就可以了。如果应用需要经常插入和删除元素,就需要用链表数据结构了。
从逻辑角度看:
(1)数组必须事先定义固定的长度(元素个数),不能适应数据动态的增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费。
(2)链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其他数据项)。
从内存角度看:
(1)(静态)数组从栈中分配空间,对于程序员方便快速,但自由度小;
(2)链表从堆中分配空间,自由度大,但申请管理比较麻烦。
24. 数组和vector的比较?
24.1 数组和vector的对比
1、内存中的位置
C++中数组为内置的数据类型,存放在栈中,其内存的分配和释放完全由系统自动完成;vector,存放在堆中,由STL库中程序负责内存的分配和释放,使用方便。
2、大小能否变化
数组的大小在初始化后就固定不变,而vector可以通过push_back或pop等操作进行变化。
3、初始化
数组不能将数组的内容拷贝给其他数组作为初始值,也不能用数组为其他数组赋值;而向量可以。
4、执行效率
数组>vector向量。主要原因是vector的扩容过程要消耗大量的时间。
24.2 数组相关知识汇总
C++中数组是一种内置的数据类型。数组是存放类型相同的对象的容器,数组的大小确定不变,不能随意向数组中增加元素。
1、定义和初始化内置数组
(1)数组的大小不变,(a[d],d为数组的维度),数组的维度必须是一个常量表达式。定义数组的时,必须指定数组的类型和大小。
(2)初始化时,允许不指明数组的维度,不指明维度,则编译器根据数组初始值的大小推测出维度;若指定维度,则初始值的个数要小于等于维度,当小于时,不足的部分为0(其实还是等于维度)。
int a[]={1,2,3}; //数组a的大小为3;
int a[5]={1,2,3}; //等价于{1,2,3,0,0},大小为5
int a[5]={1,2,3,4,5,6}; //错误,初始值过多还有一种特殊的情况:字符数组。当用字符串字面值去初始化数组时,要注意字符串字面值的后面还有一个空字符。也就是说,数组的大小要等于字面值的大小加1。
特别注意:不允许拷贝和赋值------不能将数组的内容拷贝给其他数组作为初始值,也不能用数组为其他数组赋值。
int a[] = {1,2,3};
int a2[] = a; // 错误
a2 = a; // 错误2、访问数组元素
数组的索引是从0开始,如:包含10个元素的数组a,其索引是从0到9而非1到10,若是a[10]则下标越界。
另外,使用数组下标时,其类型是size_t,在头文件cstddef中。
24.3 vector相关知识汇总
C++中vector为类模板。vector是类型相同的对象的容器,vector的大小可以变化,可以向数组中增加元素。
1、定义和初始化vector对象
初始化的方式比较多,有如下几种:
vector v1; //v1为空,执行默认初始化
vector v2(v1); //v2中包含v1所有元素的副本
vector v2=v1; //等价于v2(v1)
vector v3(n,val); //v3中包含n个重复元素,每个元素的值都是val
vector v4(n); //v4包含n个重复执行了值初始化的对象
vector v5{a,b,c...}; //包含初始化元素个数,每个元素被对应的赋予相应的值
vector v5={a,b,c...}; //等价v5{a,b,c...} (1)vector
(2)注意vector
(3)不能使用包含着多个值的括号去初始化vector对象。注意和或括号的区别。
vector intV(1,2,3); //错误 2、向vector对象中添加对象
利用vector的成员函数push_back向其中添加对象:
vector v;
for(int i=0;i !=100;++i)
{
v.push_back(i);
} 注意:若是循环体内包含想vector对象添加元素的语句,则不能使用范围for循环。因为范围for语句不应改变其所遍历序列的额大小。原因如下:
vector v={1,2,3,4,5,6,7,8,9};
for(auto& r: v)
{
r *= 2;
}
等价于
for(auto beg=v.begin(),end=v.end(); beg!=end; ++ beg)
{
auto& r = *beg;
r *= 2;
} 即在范围for语句中,预存了end()的值,一旦在序列中添加(删除)元素,end函数的值就可能变的无效了。
3、vector的扩容、插入和删除
(1)扩容
vector的底层数据结构时数组。
当vector中的可用空间耗尽时,就要动态第扩大内部数组的容量。直接在原有物理空间的基础上追加空间?这不现实。数组特定的地址方式要求,物理空间必须地址连续,而我们无法保证其尾部总是预留了足够空间可供拓展。一种方法是,申请一个容量更打的数组,并将原数组中的成员都搬迁至新空间,再在其后方进行插入操作。新数组的地址由OS分配,与原数据区没有直接的关系。新数组的容量总是取作原数组的两倍。
(2)插入和删除
插入给定值的过程是,先找到要插入的位置,然后将这个位置(包括这个位置)的元素向后整体移动一位,然后将该位置的元素复制为给定值。删除过程则是将该位置以后的所有元素整体前移一位。
(3)vector的size和capacity
size指vector容器当前拥有的元素个数,capacity指容器在必须分配新存储空间之前可以存储的元素总数,capacity总是大于或等于size的。
25. C++分配内存的4种方式
1. calloc 函数: void *calloc(unsigned int num, unsigned int size)
按照所给的数据个数和数据类型所占字节数,分配一个 num * size 连续的空间。
calloc申请内存空间后,会自动初始化内存空间为 0,但是malloc不会进行初始化,其内存空间存储的是一些随机数据。
2. malloc 函数: void *malloc(unsigned int size)
在内存的动态分配区域中分配一个长度为size的连续空间,如果分配成功,则返回所分配内存空间的首地址,否则返回NULL,申请的内存不会进行初始化。
3. realloc 函数: void *realloc(void *ptr, unsigned int size)
动态分配一个长度为size的内存空间,并把内存空间的首地址赋值给ptr,把ptr内存空间调整为size。申请的内存空间不会进行初始化。
4. new是动态分配内存的运算符,自动计算需要分配的空间,在分配类类型的内存空间时,同时调用类的构造函数,对内存空间进行初始化,即完成类的初始化工作。动态分配内置类型是否自动初始化取决于变量定义的位置,在函数体外定义的变量都初始化为0,在函数体内定义的内置类型变量都不进行初始化。
26. 构造函数可以为虚函数吗?父类的析构函数为什么是虚函数?
构造函数不能为虚函数,当申明一个函数为虚函数时,会创建虚函数表,那么这个函数的调用方式是通过虚函数表来调用。若构造函数为虚函数,说明调用方式是通过虚函数调用,需要借助虚表指针,但是没有构造函数,哪里来的虚表指针?但是没有虚表指针,怎么访问虚函数从而调用构造函数呢?这就是一个先有鸡还是先有蛋的问题。
若存在继承关系,析构函数必须申明为虚函数,这样父类指针指向子类对象,释放基类指针时才会调用子类的析构函数释放资源,否则内存泄露。
27. 你了解的锁机制?
(1)互斥锁:mutex,保证在任何时刻,都只有一个线程访问该资源,当获取锁操作失败时,线程进入阻塞,等待锁释放。
(2)读写锁:rwlock,分为读锁和写锁,处于读操作时,可以运行多个线程同时读。但写操作同一时刻只有一个线程获得写锁。
互斥与读写锁的区别:
(a)读写锁区分读锁和写锁,而互斥锁不区分;
(b)互斥锁同一时间只允许一个线程访问,无论读写;读写锁同一时间只允许一个线程写,但可以多个线程同时读。
(3)自旋锁:spinlock,在任何时刻只能有一个线程访问资源。但获取锁操作失败时,不会进入睡眠,而是原地自旋,直到锁被释放。这样节省了线程从睡眠到被唤醒的时间消耗,提高效率。
(4)条件锁:就是所谓的条件变量,某一个线程因为某个条件未满足时可以使用条件变量使该程序处于阻塞状态。一旦条件满足了,即可唤醒该线程(常和互斥锁配合使用)。
(5)信号量。
28. C++什么情况下必须用初始化列表?
有的时候必须用带有初始化列表的构造函数:
(1)成员类型是没有默认构造函数的类。若没有提示显示初始化式,则编译器隐式使用成员类型的默认构造函数,若类没有默认构造函数,则编译器尝试使用默认构造函数将会失败。
(2)const成员或引用类型的成员,因为const对象或引用类型只能初始化,不能对它们赋值。
对于普通数据成员而言,其值的设定可以放在初始化阶段或者普通计算阶段完成。
对于const类型和&引用类型数据成员,其初始化必须在初始化阶段完成。若通过普通计算阶段来初始化该值,编译期会报错:该变量未初始化。
29. C++ new和malloc的区别
1.new是C++关键字,需要编译器支持;malloc是库函数,需要头文件支持。
2.使用new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算。而malloc则需要显式地指出所需内存的尺寸。
3.new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void * ,需要通过强制类型转换将void*指针转换成我们需要的类型。
4.new会先调用operator new函数,申请足够的内存(通常底层使用malloc实现)。然后调用类型的构造函数,初始化成员变量,最后返回自定义类型指针。delete先调用析构函数,然后调用operator delete函数释放内存(通常底层使用free实现)。而malloc是库函数,只能动态的申请和释放内存,无法强制要求其做自定义类型对象构造和析构工作。
5.C++允许自定义operator new 和 operator delete 函数控制动态内存的分配。
6.new做两件事,分别是分配内存和调用类的构造函数,而malloc只是分配和释放内存。new操作符从自由存储区上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。自由存储区是C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区。而堆是操作系统中的术语,是操作系统所维护的一块特殊内存,用于程序的内存动态分配,C语言使用malloc从堆上分配内存,使用free释放已分配的对应内存。自由存储区不等于堆,如上所述,布局new就可以不位于堆中。
7.new内存分配失败时,会抛出bac_alloc异常。malloc分配内存失败时返回NULL。
8.内存泄漏对于new和malloc都能检测出来,而new可以指明是哪个文件的哪一行,malloc不可以。