论文阅读—— UniDetector(cvpr2023)
arxiv:https://arxiv.org/abs/2303.11749
github:https://github.com/zhenyuw16/UniDetector
一、介绍
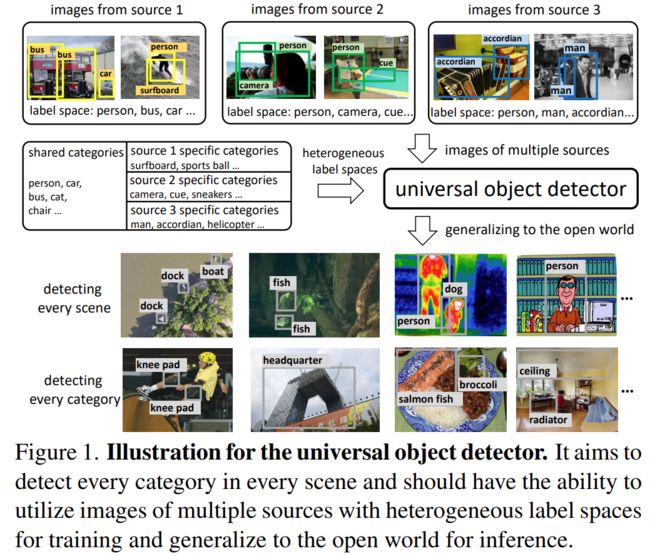
通用目标检测旨在检测场景那种的一切目标。现有的检测器依赖于大量数据集
通用的目标检测器应该有两个能力:1、可以利用多种来源的图片和标签训练2、可以很好的泛化到开放世界,对于没见过的类别也可以预测。
传统的目标检测,rcnn系列,只能在封闭数据集上,后来发展的开放词汇目标检测很大程度提升了性能,也能泛化到一些非常见类别,但是仍然只在一个数据集迁移,同时见过的类别比没见过的类别多,泛化能力受到限制。在多数据集上训练的问题是需要统一标签空间,为此提出了一些方法但是这些方法仍然关注于在封闭数据集上检测。
二、The UniDetector Framework
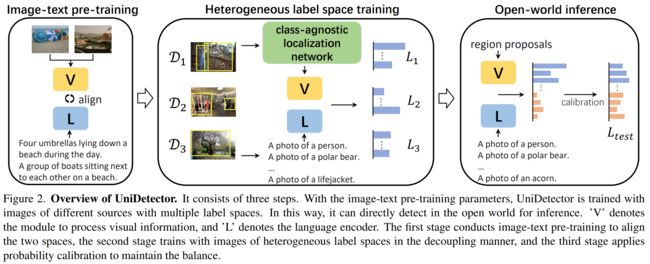
Step1: Large-scale image-text aligned pre-training.
采用RegionCLIP参数:We adopt RegionCLIP pre-trained parameters for our experiments.
Step2: Heterogeneous label space training.
1、对于处理不同来源的数据,考虑三个问题,架构、采样和损失函数选择
1)提出了三种处理不同来源标签的架构:
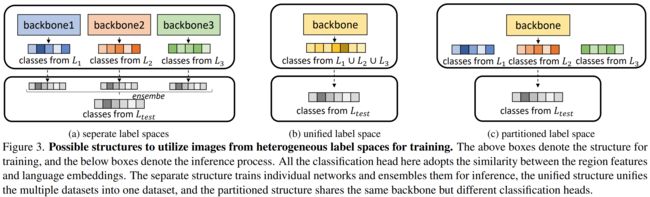
2)训练大规模数据集,一个不可避免的问题是长尾效应。之前用在封闭数据集上解决这个问题的方法不太管用因为通用检测器有没见过的类别。对于语言嵌入,长尾问题的不利影响可以忽略不计。因此,我们采用了随机采样器。(With language embeddings, the adverse effect of the long-tailed problem becomes negligible. We thus adopt the random sampler.)
3)损失函数
使用基于sigmoid的损失函数,同时当类别数量增加时,为了避免基于sigmoid的分类损失过大,随机抽取一定数量的类别作为负类别。
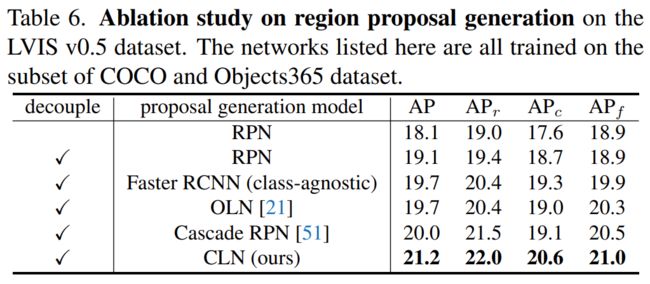
2、解耦RPN区域生成和ROI分类的训练
1)传统的两阶段目标检测器,包括backbone encoder, a RPN and a RoI classification module。RPN是类别无关的,使用与通用目标检测,但是特定类别的RoI分类模块依然不能用于罕见类别。所以作者解耦了这两个阶段,分别训练。也就是,用ImageNet预训练参数初始化RPN模块,类别不相关方式训练,训练完成后就会产生一系列region proposals。然后对于这些区域,ROI分类模块用Fast RCNN方式训练,这个阶段用imagetext预训练参数初始化来预测没见过的罕见类别。用到的这两种预训练参数包含互补信息,对通用检测提供了理解信息。
2)CLN模块:是在RPN模块后面ROIHead
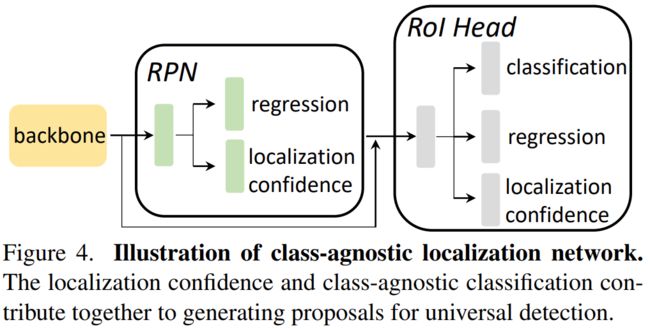
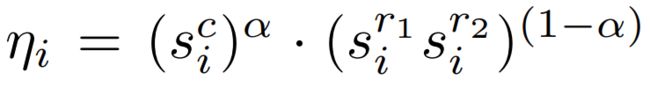
![]() 、
、![]() 、
、![]() 分别是RPN和ROI的localization confidence以及ROIHead的classification confidence。
分别是RPN和ROI的localization confidence以及ROIHead的classification confidence。
Step3: Open-world inference.
提出概率对准
开放世界推理阶段有个问题,训练集中出现的类别(基础类别)推理得出的分数会高于罕见类别,这样就会使检测器忽略大量的没见过的类别实例。于是作者在后处理阶段提出了概率对准,目的是降低基础类别概率增加没见过类别的概率,概率对准公式如下:
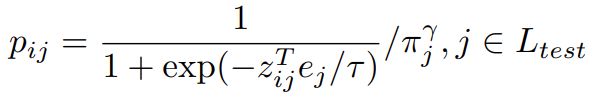
![]() 是类别的先验概率,值越大说明模型越偏向这个类别可以在测试集上推理一遍,根据得到的结果中每个类别的数量获得
是类别的先验概率,值越大说明模型越偏向这个类别可以在测试集上推理一遍,根据得到的结果中每个类别的数量获得![]() 的值,如果测试集太小,也可以使用训练集。
的值,如果测试集太小,也可以使用训练集。 是超参数。
是超参数。
最终的预测分数使用上面公式的![]() 和CLN模块的目标分数
和CLN模块的目标分数![]() 相乘,再引入超参数β得到:
相乘,再引入超参数β得到: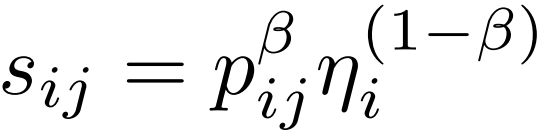
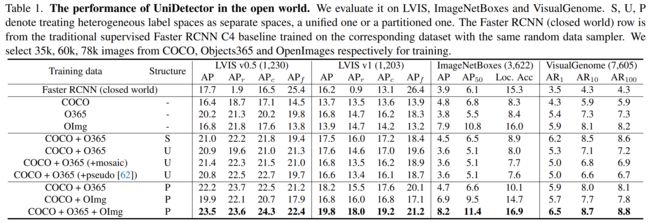
三、一些训练细节
训练数据集:
COCO:80类,稠密高质量人工标注,作者从中随机采样了35K训练
Objects365:365类,更大规模,作者从中随机采样了60K训练
OpenImages:500类别,许多标注稀疏并且是脏数据,作者从中随机采样了78K训练
推理数据集:
LVIS:LVIS v0.5有1230类别,LVIS v1有1203类别
ImageNetBoxes:3000多类别
VisualGenome:7605类别,相当一部分数据是机器标注,所以噪声非常多
实现细节:使用mmdetection实现,选择ResNet50-C4 based Faster RCNN as our detector, initialized with RegionCLIP pre-trained parameters。超参数设置, =0.01,=0.6,
=0.01,=0.6, =
= =0.3
=0.3
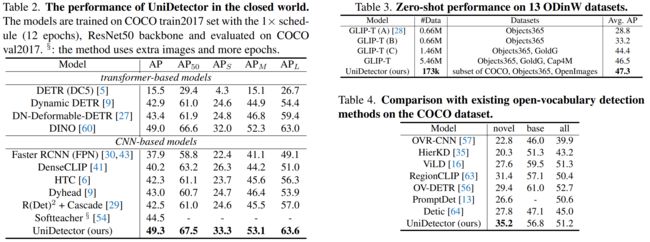
四、一些实验结果