Monarch Mixer:一种性能比Transformer更强的网络架构
六年前,谷歌团队在arXiv上发表了革命性的论文《Attention is all you need》。作为一种优势的机器学习网络架构,Transformer技术迅速席卷全球。Transformer一直是现代基础模型背后的主力架构,并且在不同的应用程序中取得了令人印象深刻的成功:包括像BERT、ChatGPT和Flan-T5这样的预训练语言模型,到像SAM和stable diffusion这样的图像模型。
尽管如此,Transformer架构中的自注意力机制和MLP在处理长度很长的序列或者维数很大的模型的时候,速度和效率会打折扣。这主要是因为tranformer构架的时空复杂性随序列的长度和训练模型的维数按平方的依赖关系生长,即所谓“二次元”(quadratic)。
最近,斯坦福大学和纽约州立大学布法罗分校的一个研究团队,在arXiv上发表题为《Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture》论文。该论文提出了一种新的transformer的替代技术:Monarch Mixer(M2)。该方法去掉了 Transformer 中高成本的自注意力和 MLP,代之以富有表现力的 Monarch 矩阵,使之在语言和图像实验中以更低的成本取得了更优的表现。其复杂度随序列长度和模型维度的增长是低于二次元,即所谓次二次元的(sub-quadratic)。

斯坦福大学和布法罗大学在axXiv上发表论文截图
该论文已入选 NeurIPS 2023 并获得 Oral Presentation 资格。
算法与原理
该论文的研究灵感来自 MLP-mixer 和 ConvMixer;这两项研究观察到:许多机器学习模型的运作方式都是沿序列和模型维度轴对信息进行混合,并且它们往往对两个轴使用了单个算子。
寻找表现力强、次二次元且硬件效率高的混合算子的难度很大。举个例子,MLP-mixer 中的 MLP 和 ConvMixer 中的卷积都颇具表现力,但它们都会随输入维度二次扩展。近期有一些研究提出了一些次二次元的序列混合方法,这些方法使用了较长的卷积或状态空间模型,而且它们都会用到快速傅里叶变换( FFT),但这些模型的 FLOP 利用率很低并且在模型维度方面依然是二次扩展。与此同时,不损质量的稀疏密集 MLP 层方面也有一些颇具潜力的进展,但由于硬件利用率较低,某些模型实际上可能还比密集模型更慢。
基于这些灵感,该论文研究团队提出了 Monarch Mixer (M2),其使用到了一类富有表现力的次二次结构化矩阵:Monarch 矩阵。

Monarch矩阵
Monarch 矩阵是一类泛化了FFT的结构化矩阵,并且研究表明其涵盖了范围广泛的线性变换,包括哈达玛变换、托普利兹矩阵、AFDF 矩阵和卷积。它们可通过分块对角矩阵的积进行参数化,这些参数被称为 Monarch 因子,与排列交织。
它们的计算是次二次扩展的:如果将因子的数量设为 p,则当输入长度为 N 时,计算复杂度为O(pN^(p+1)/p),从而让计算复杂度可以位于 p = log N 时的 O (N log N) 与 p = 2 时的 O(N^3/2)之间。
M2 使用了 Monarch 矩阵来沿序列和模型维度轴混合信息。这种方法不仅易于实现,而且硬件效率也很高:使用支持 GEMM(广义矩阵乘法算法)的现代硬件就能高效地计算分块对角 Monarch 因子。
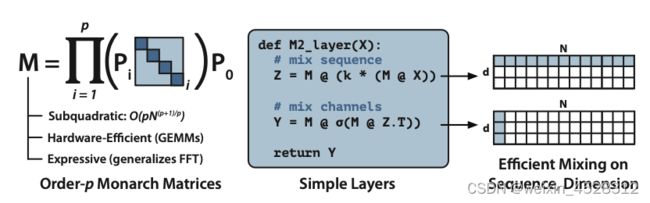
图1:Monarch 矩阵是一种简单、富有表现力且硬件效率高的次二次结构矩阵。Monarch Mixer (M2)使用Monarch=矩阵来混合输入:首先沿着序列维度,然后沿着模型维度。

图 2:Monarch 乘法可以解释为多项式求值和插值。
该论文研究团队实现了一个 M2 层来进行概念验证。代码完全使用 PyTorch 来编写,代码行数不到 40(包括 import 软件包),而且其只需依赖矩阵乘法、转置、改造和逐元素乘积(见图 1 中部的伪代码)。结果,对于大小为 64k 的输入,这些代码在一台 A100 GPU 上实现了 25.6% 的 FLOP 利用率。在 RTX 4090 等更新的架构上,对于同样大小的输入,一个简单的 CUDA 实现就能实现 41.4% 的 FLOP 利用率。
表1:RTX 4090 上各种混频器层的 FLOP 成本和利用率(输入维数64K)

实验测试结果
该研究团队在 Transformer 已占主导地位的三个任务上对 Monarch Mixer 和 Transformer 进行了比较:(1)BERT 风格的非因果掩码语言建模任务;(2)ViT 风格的图像分类任务;(3)GPT 风格的因果语言建模任务。
在每个任务上,实验结果表明新提出的方法在不使用注意力和 MLP 的前提下均能达到与 Transformer 相媲美的水平。他们还在 BERT 设置中评估了新方法相较于强大 Transformer 基准模型的加速情况。
(1)非因果语言建模
对于非因果语言建模任务,论文作者构建了一种基于 M2 的架构:M2-BERT。M2-BERT 可以直接替代 BERT 风格的语言模型,而 BERT 是 Transformer 架构的一大主力应用。对于 M2-BERT 的训练,使用了在 C4 上的掩码语言建模,token 化器则是 bert-base-uncased。
M2-BERT 基于 Transformer 骨干,但其中的注意力层和 MLP 被 M2 层替换,如图 3 所示。

图 3:M2-BERT 使用 Monarch 矩阵在序列混合器中创建双向门控长卷积,并使用 Monarch 矩阵替换维度混合器中的线性层。
在序列混合器中,注意力被带残差卷积的双向门控卷积替代(见图 3 左侧)。为了恢复卷积,论文作者将 Monarch 矩阵设置为 DFT 和逆 DFT 矩阵。他们还在投射步骤之后添加了逐深度的卷积。
在维度混合器中,MLP 中两个密集矩阵被替换成了学习得到的分块对角矩阵(1 阶 Monarch 矩阵,b = 4)。
作者预训练了 4 个 M2-BERT 模型:其中两个是大小分别为 80M 和 110M 的 M2-BERT-base 模型,另外两个是大小分别为 260M 和 341M 的 M2-BERT-large 模型。它们分别相当于 BERT-base 和 BERT-large。
表 3 给出了相当于 BERT-base 的模型的性能表现。
表 3:M2-BERT-base 与 BERT-base相比的平均 GLUE 分数,以及参数和 GLUE 分数的变化

表 4 给出了相当于 BERT-large 的模型的性能表现。
表 4:M2-BERT-large 与 BERT-large 相比的平均 GLUE 得分,以及变化参数和 GLUE 分数

从这些表中结果可以看到,在 GLUE 基准上,M2-BERT-base 的表现可以媲美 BERT-base,同时参数还少了 27%;而当两者参数数量相当时,M2-BERT-base 胜过 BERT-base 1.3 分。类似地,参数少 24% 的 M2-BERT-large 与 BERT-large 表现相当,而参数数量一样时,M2-BERT-large 有 0.7 分的优势。
表 5 给出了相当于 BERT-base 的模型的前向吞吐量情况。其中报告的是在 A100-40GB GPU 上每毫秒处理的 token 数,这能反映推理时间。
表 5:M2-BERT-base (80M) 吞吐量与 BERT-base 比较结果(以token/毫秒为单位)

可以看到,M2-BERT-base 的吞吐量甚至超过了经过高度优化的 BERT 模型;相较于在 4k 序列长度上的标准 HuggingFace 实现,M2-BERT-base 的吞吐量可达其 9.1 倍!
表 6 则报告了 M2-BERT-base (80M) 和 BERT-base 的 CPU 推理时间 —— 结果是直接运行这两个模型的 PyTorch 实现得到的。
表 6:在不同输入序列长度下批量大小为 1 的 CPU 推理延迟(以毫秒为单位)。 在运行 Intel Cascade Lake 处理器的 GCP n2-standard-48 系列的 48 vCPU、96 GB RAM 实例上对 10 多个示例进行了平均测量

当序列较短时,数据局部性的影响依然主导着 FLOP 的减少情况,而过滤器生成(BERT 中没有)等操作的成本更高。而当序列长度超过 1K 时,M2-BERT-base 的加速优势就渐渐起来了,当序列长度达 8K 时,速度优势可达 6.5 倍。
(2) ViT风格的图像分类
在非因果建模方面,为了验证新方法在图像上也有在语言上一样的优势,该团队还评估了 M2 在图像分类任务上的表现。
表 7 给出了 Monarch Mixer、ViT-b、HyenaViT-b 和 ViT-b-Monarch(用 Monarch 矩阵替换了标准 ViT-b 中的 MLP 模块)在 ImageNet-1k 上的性能表现。
表 7:ImageNet-1k 上的准确性。 ResNet-152 提供供参考。

Monarch Mixer 优势非常明显:只需一半的参数量,其表现就能胜过原始 ViT-b 模型。而更让人惊讶的是,参数更少的 Monarch Mixer 很能胜过 ResNet-152;要知道,ResNet-152 可是专门针对 ImageNet 任务设计的。
(3)GPT风格因果语言建模
GPT 风格的因果语言建模是 Transformer 的一大关键应用。该团队为因果语言建模构建了一个基于 M2 的架构:M2-GPT。
对于序列混合器,M2-GPT 组合使用了来自 Hyena 的卷积过滤器、当前最佳的无注意力语言模型以及来自 H3 的跨多头参数共享。他们使用因果参数化替换了这些架构中的 FFT,并完全移除了 MLP 层。所得到的架构完全没有注意力,也完全没有 MLP。
他们在因果语言建模的标准数据集 PILE 上对 M2-GPT 进行了预训练。结果见表 8。
表 8:针对不同数量的标记进行训练时,PILE 上的困惑度。

可以看到,尽管基于新架构的模型完全没有注意力和 MLP,但其在预训练的困惑度指标上依然胜过 Transformer 和 Hyena。这些结果表明,与 Transformer 大不相同的模型也可能在因果语言建模取得出色表现。
下一步研究计划
在最近的博客中(hazyresearch.stanford.edu/blog/2023-07-25-m2-bert),作者列出了他们的下一步研究计划:
- 我们今天发布了 BERT 代码以及 80M 和 110M 模型的检查点代码,使用序列长度 128 的标准配方进行了预训练 - 请继续关注更长的序列! 查看我们的代码和检查点(80M、110M)。
- 在接下来的几周内,请留意进一步的发布,因为我们将训练长序列 BERT 并开始追溯 Transformers 的历史 - 在 ImageNet、因果语言建模、T5 风格模型以及对长序列功能的探索。
- 作为此版本的一部分,您将找到一些用于 M2 层前向传递的优化 CUDA 代码(我们将其用于基准测试)——我们将在未来几周内继续优化并发布更新。 当我们探索计算权衡空间时,期待有关这些的另一系列博客和材料!
- 当然,更完整的论文将在 arXiv 中推出!
小结
该论文的研究工作为机器学习领域带来了新的思路,挑战了传统Transformer模型的优越性。他们的研究不仅探索了Monarch Mixer的理论基础,还进行了一系列实验来验证其性能。这篇文章的发表为机器学习社区提供了一个全新的研究方向,也让人们重新思考了在自然语言处理和计算机视觉任务中的模型选择。
总的来说,Monarch Mixer(M2)是一种具有次二次复杂度的新型模型架构,能够在不使用传统Transformer中的注意力和MLP的情况下,在自然语言处理和计算机视觉任务中表现出色。它的硬件效率和参数效率使其成为一个有望取代传统Transformer的新选择,为深度学习研究领域带来了新的思考。
参考文献:
Daniel Y. Fu, Simran Arora, Jessica Grogan, Isys Johnson, Sabri Eyuboglu, Armin W. Thomas, Benjamin Spector, Michael Poli, Atri Rudra, Christopher Ré. “Monarch Mixer: A Simple Sub-Quadratic GEMM-Based Architecture”,Oct 18, 2023, https://arxiv.org/abs/2310.12109