探索数据库世界的奥秘:MySQL初学者必备指南!
数据库开发-MySQL
-
- 1. 数据库操作-DQL
-
- 1.1 介绍
- 1.2 语法
- 1.3 基本查询
- 1.4 条件查询
- 1.5 聚合函数
- 1.6 分组查询
- 1.7 排序查询
- 1.8 分页查询
- 1.9 案例
-
- 1.9.1 案例一
- 1.9.2 案例二
- 2. 多表设计
-
- 2.1 一对多
-
- 2.1.2 外键约束
- 2.2 一对一
- 2.3 多对多
1. 数据库操作-DQL
1.1 介绍
DQL英文全称是Data Query Language(数据查询语言),用来查询数据库表中的记录。
查询关键字:SELECT
查询操作是所有SQL语句当中最为常见,也是最为重要的操作。在一个正常的业务系统中,查询操作的使用频次是要远高于增删改操作的。当我们打开某个网站或APP所看到的展示信息,都是通过从数据库中查询得到的,而在这个查询过程中,还会涉及到条件、排序、分页等操作。

1.2 语法
DQL查询语句,语法结构如下:
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
ORDER BY
排序字段列表
LIMIT
分页参数
1.3 基本查询
在基本查询的DQL语句中,不带任何的查询条件,语法如下:
-
查询多个字段
select 字段1, 字段2, 字段3 from 表名; -
查询所有字段(通配符)
select * from 表名; -
设置别名
select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] from 表名; -
去除重复记录
select distinct 字段列表 from 表名;
案例1:查询指定字段 name,entrydate并返回

案例2:查询返回所有字段
*号代表查询所有字段,在实际开发中尽量少用(不直观、影响效率)
案例3:查询所有员工的 name,entrydate,并起别名(姓名、入职日期)

案例4:查询已有的员工关联了哪几种职位(不要重复)。

1.4 条件查询
语法:
select 字段列表 from 表名 where 条件列表 ; -- 条件列表:意味着可以有多个条件
学习条件查询就是学习条件的构建方式,而在SQL语句当中构造条件的运算符分为两类:
- 比较运算符
- 逻辑运算符
常用的比较运算符如下:
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| between … and … | 在某个范围之内(含最小、最大值) |
| in(…) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单个字符, %匹配任意个字符) |
| is null | 是null |
常用的逻辑运算符如下:
| 逻辑运算符 | 功能 |
|---|---|
| and 或 && | 并且 (多个条件同时成立) |
| or 或 || | 或者 (多个条件任意一个成立) |
| not 或 ! | 非 , 不是 |
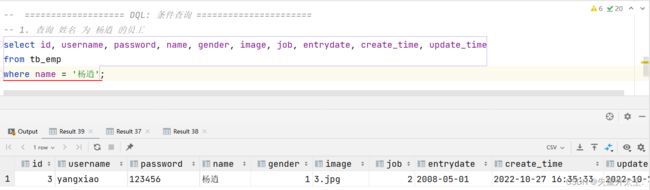
案例1:查询 姓名 为 杨逍 的员工
案例2:查询 id小于等于5 的员工信息

案例3:查询 没有分配职位 的员工信息

注意:查询为NULL的数据时,不能使用
= null

案例4:查询 有职位 的员工信息

案例5:查询 密码不等于 ‘123456’ 的员工信息

案例6:查询 入职日期 在 ‘2000-01-01’ (包含) 到 ‘2010-01-01’(包含) 之间的员工信息

案例7:查询 入职时间 在 ‘2000-01-01’ (包含) 到 ‘2010-01-01’(包含) 之间 且 性别为女 的员工信息

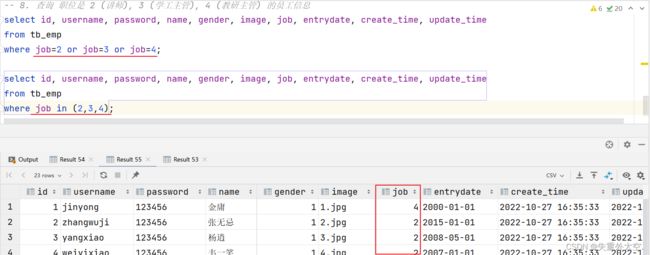
案例8:查询 职位是 2 (讲师), 3 (学工主管), 4 (教研主管) 的员工信息
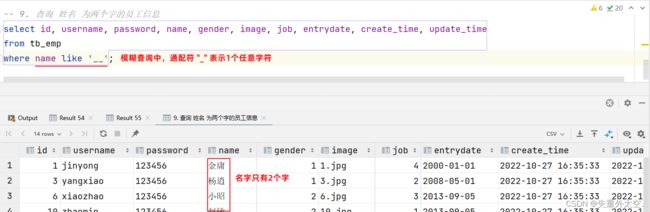
案例9:查询 姓名 为两个字的员工信息
案例10:查询 姓 ‘张’ 的员工信息

1.5 聚合函数
之前我们做的查询都是横向查询,就是根据条件一行一行的进行判断,而使用聚合函数查询就是纵向查询,它是对一列的值进行计算,然后返回一个结果值。(将一列数据作为一个整体,进行纵向计算)。
语法:
select 聚合函数(字段列表) from 表名 ;
注意 : 聚合函数会忽略空值,对NULL值不作为统计。
常用聚合函数:
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
count :按照列去统计有多少行数据。
- 在根据指定的列统计的时候,如果这一列中有null的行,该行不会被统计在其中。
sum :计算指定列的数值和,如果不是数值类型,那么计算结果为0
max :计算指定列的最大值
min :计算指定列的最小值
avg :计算指定列的平均值
案例1:统计该企业员工数量
# count(字段)
select count(id) from tb_emp;-- 结果:29
select count(job) from tb_emp;-- 结果:28 (聚合函数对NULL值不做计算)
# count(常量)
select count(0) from tb_emp;
select count('A') from tb_emp;
# count(*) 推荐此写法(MySQL底层进行了优化)
select count(*) from tb_emp;
案例2:统计该企业最早入职的员工

案例3:统计该企业最迟入职的员工

案例4:统计该企业员工 ID 的平均值

案例5:统计该企业员工的 ID 之和

1.6 分组查询
分组: 按照某一列或者某几列,把相同的数据进行合并输出。
分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。
分组查询通常会使用聚合函数进行计算。
语法:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];
案例1:根据性别分组 , 统计男性和女性员工的数量

案例2:查询入职时间在 ‘2015-01-01’ (包含) 以前的员工 , 并对结果根据职位分组 , 获取员工数量大于等于2的职位
select job, count(*)
from tb_emp
where entrydate <= '2015-01-01' -- 分组前条件
group by job -- 按照job字段分组
having count(*) >= 2; -- 分组后条件

注意事项:
• 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
• 执行顺序:where > 聚合函数 > having
where与having区别(面试题)
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
1.7 排序查询
排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。
语法:
select 字段列表
from 表名
[where 条件列表]
[group by 分组字段 ]
order by 字段1 排序方式1 , 字段2 排序方式2 … ;
-
排序方式:
-
ASC :升序(默认值)
-
DESC:降序
-
案例1:根据入职时间, 对员工进行升序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
order by entrydate ASC; -- 按照entrydate字段下的数据进行升序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
order by entrydate; -- 默认就是ASC(升序)

注意事项:如果是升序, 可以不指定排序方式ASC
案例2:根据入职时间,对员工进行降序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
order by entrydate DESC; -- 按照entrydate字段下的数据进行降序排序

案例3:根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
order by entrydate ASC , update_time DESC;
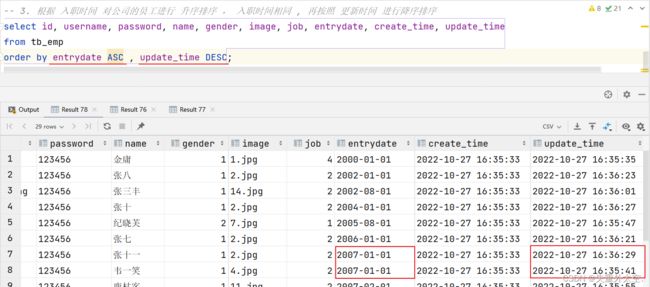
注意事项:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
1.8 分页查询
分页操作在业务系统开发时,也是非常常见的一个功能,日常我们在网站中看到的各种各样的分页条,后台也都需要借助于数据库的分页操作。
分页查询语法:
select 字段列表 from 表名 limit 起始索引, 查询记录数 ;
案例1:从起始索引0开始查询员工数据, 每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 0 , 5; -- 从索引0开始,向后取5条记录

案例2:查询 第1页 员工数据, 每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 5; -- 如果查询的是第1页数据,起始索引可以省略,直接简写为:limit 条数

案例3:查询 第2页 员工数据, 每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 5 , 5; -- 从索引5开始,向后取5条记录

案例4:查询 第3页 员工数据, 每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 10 , 5; -- 从索引10开始,向后取5条记录

注意事项:
起始索引从0开始。 计算公式 : 起始索引 = (查询页码 - 1)* 每页显示记录数
分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT
如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 条数
1.9 案例
1.9.1 案例一
案例:根据需求完成员工管理的条件分页查询

分析:根据输入的条件,查询第1页数据
在员工管理的列表上方有一些查询条件:员工姓名、员工性别,员工入职时间(开始时间~结束时间)
- 姓名:张
- 性别:男
- 入职时间:2000-01-01 ~ 2015-12-31
除了查询条件外,在列表的下面还有一个分页条,这就涉及到了分页查询
- 查询第1页数据(每页显示10条数据)
基于查询的结果,按照修改时间进行降序排序
结论:条件查询 + 分页查询 + 排序查询

1.9.2 案例二
案例:根据需求完成员工信息的统计

分析:以上信息统计在开发中也叫图形报表(将统计好的数据以可视化的形式展示出来)
- 员工性别统计:以饼状图的形式展示出企业男性员人数和女性员工人数
- 只要查询出男性员工和女性员工各自有多少人就可以了
- 员工职位统计:以柱状图的形式展示各职位的在岗人数
- 只要查询出各个职位有多少人就可以了
员工性别统计:
-- if(条件表达式, true取值 , false取值)
select if(gender=1,'男性员工','女性员工') AS 性别, count(*) AS 人数
from tb_emp
group by gender;

if(表达式, tvalue, fvalue) :当表达式为true时,取值tvalue;当表达式为false时,取值fvalue
员工职位统计:
-- case 表达式 when 值1 then 结果1 when 值2 then 结果2 ... else result end
select (case job
when 1 then '班主任'
when 2 then '讲师'
when 3 then '学工主管'
when 4 then '教研主管'
else '未分配职位'
end) AS 职位 ,
count(*) AS 人数
from tb_emp
group by job;

case 表达式 when 值1 then 结果1 [when 值2 then 结果2 …] [else result] end
2. 多表设计
关于单表的操作(单表的设计、单表的增删改查)我们就已经学习完了。接下来我们就要来学习多表的操作,首先来学习多表的设计。
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
-
一对多(多对一)
-
多对多
-
一对一
2.1 一对多
员工表 - 部门表之间的关系:

一对多关系实现:在数据库表中多的一方,添加字段,来关联属于一这方的主键。
2.1.2 外键约束
问题
- 表结构创建完毕后,我们看到两张表的数据分别为:

现在员工表中有五个员工都归属于1号部门(学工部),当删除了1号部门后,数据变为:

1号部门被删除了,但是依然还有5个员工是属于1号部门的。 此时:就出现数据的不完整、不一致了。
问题分析
目前上述的两张表(员工表、部门表),在数据库层面,并未建立关联,所以是无法保证数据的一致性和完整性的。
问题解决
想解决上述的问题呢,我们就可以通过数据库中的 外键约束 来解决。
外键约束:让两张表的数据建立连接,保证数据的一致性和完整性。
对应的关键字:foreign key
外键约束的语法:
-- 创建表时指定
create table 表名(
字段名 数据类型,
...
[constraint] [外键名称] foreign key (外键字段名) references 主表 (主表列名)
);
-- 建完表后,添加外键
alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(主表列名);
那接下来,我们就为员工表的dept_id 建立外键约束,来关联部门表的主键。
方式1:通过SQL语句操作
-- 修改表: 添加外键约束
alter table tb_emp
add constraint fk_dept_id foreign key (dept_id) references tb_dept(id);
方式2:图形化界面操作

当我们添加外键约束时,我们得保证当前数据库表中的数据是完整的。 所以,我们需要将之前删除掉的数据再添加回来。
当我们添加了外键之后,再删除ID为1的部门,就会发现,此时数据库报错了,不允许删除。

外键约束(foreign key):保证了数据的完整性和一致性。
物理外键和逻辑外键
-
物理外键
- 概念:使用foreign key定义外键关联另外一张表。
- 缺点:
- 影响增、删、改的效率(需要检查外键关系)。
- 仅用于单节点数据库,不适用与分布式、集群场景。
- 容易引发数据库的死锁问题,消耗性能。
-
逻辑外键
- 概念:在业务层逻辑中,解决外键关联。
- 通过逻辑外键,就可以很方便的解决上述问题。
在现在的企业开发中,很少会使用物理外键,都是使用逻辑外键。 甚至在一些数据库开发规范中,会明确指出禁止使用物理外键 foreign key
2.2 一对一
一对一关系表在实际开发中应用起来比较简单,通常是用来做单表的拆分,也就是将一张大表拆分成两张小表,将大表中的一些基础字段放在一张表当中,将其他的字段放在另外一张表当中,以此来提高数据的操作效率。
一对一的应用场景: 用户表(基本信息+身份信息)
- 基本信息:用户的ID、姓名、性别、手机号、学历
- 身份信息:民族、生日、身份证号、身份证签发机关,身份证的有效期(开始时间、结束时间)
如果在业务系统当中,对用户的基本信息查询频率特别的高,但是对于用户的身份信息查询频率很低,此时出于提高查询效率的考虑,我就可以将这张大表拆分成两张小表,第一张表存放的是用户的基本信息,而第二张表存放的就是用户的身份信息。他们两者之间一对一的关系,一个用户只能对应一个身份证,而一个身份证也只能关联一个用户。

那么在数据库层面怎么去体现上述两者之间是一对一的关系呢?
其实一对一我们可以看成一种特殊的一对多。一对多我们是怎么设计表关系的?是不是在多的一方添加外键。同样我们也可以通过外键来体现一对一之间的关系,我们只需要在任意一方来添加一个外键就可以了。

一对一 :在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
2.3 多对多
多对多的关系在开发中属于也比较常见的。比如:学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。在比如:学生和课程的关系,一个学生可以选修多门课程,一个课程也可以供多个学生选修。
案例:学生与课程的关系
-
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
-
实现关系:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键

后记
美好的一天,到此结束,下次继续努力!欲知后续,请看下回分解,写作不易,感谢大家的支持!!