Python爬虫编程13——cookie池
目录
如何查看网站的cookie
cookie的作用
1.登录账号可以降低被封禁的概率;
2.解决单个账号受访问限制;
3.避免复杂的模拟登录验证码;
4.爬取登录之后才能爬取的数据;
cookie池的部署
cookie池的部署重点在于模拟登录服务和cookie的检测。
cookie的优势
1.服务分离;
2.组件也可以实现分离;
3.服务能够分开部署;
cookie的属性
name = value 键和值 具体的cookie名称和内容
domain 作用域
path /表示根路径
expire 有效期
如何查看网站的cookie
1.

点击网址前的:
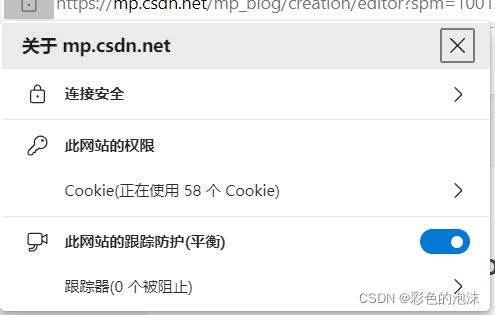
查看cookie:

2.
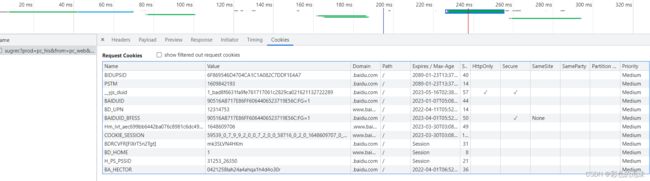
3.直接查看拼接好的cookie
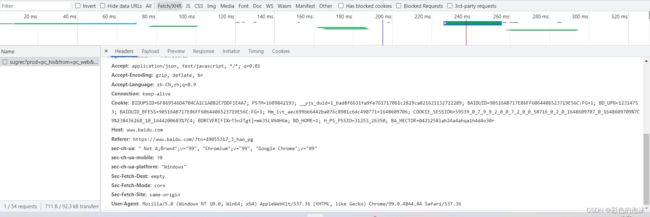
cookie的保存使用(案例)
网址:http://shanzhi.spbeen.com/login/
这里JS反爬登录函数封装在了tools中的get_js里,如有需要可以查看主页中的JS反爬文章。
import requests
from lxml import etree
from tools import get_js
import json
def save_cookie(cookie_dict):
"""
把cookie存入cookie池中
Parameters
----------
cookie_dict 待存储的cookie
Returns
-------
"""
with open('cookies.txt', 'a', encoding='utf-8') as file_obj:
# json.dumps 把字典转换成字符串
file_obj.write(json.dumps(cookie_dict) + '\n')
# 传入账号和密码 实现模拟登陆
def login(username, password):
# 请求的url和请求头
url = 'http://shanzhi.spbeen.com/login/'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'Cookie': 'csrftoken=3U8bCQmmBjGjuZYIWpkZsAr9nHBgnk93Va1lyPz542u4bfKo4toe1o6Rh8QIVmKo'
}
# 获取源码中的csrfmiddlewaretoken和pk
res = requests.get(url, headers=header).text
html = etree.HTML(res)
csrfmiddlewaretoken = html.xpath('//input[@name="csrfmiddlewaretoken"]/@value')[0]
pk = html.xpath('//input[@id="pk"]/@value')[0]
# new_password为加密之后的密码
# 使用js环境进行的加密处理
new_password = get_js('./shanzhi.js', 'doLogin', password, pk)
postdata = {
'username': username,
'password': new_password,
'csrfmiddlewaretoken': csrfmiddlewaretoken
}
cresponse = requests.post(url=url, headers=header, data=postdata)
# print(cresponse.history[0].cookies.get_dict())
# 确定模拟登录成功之后 想办法从响应对象中提取出cookie 然后存入cookie池中
# 对于网页有可能不是把cookie的信息存放在history的第一个元素里面的情况 我们需要优化代码
cookie_dict = cresponse.history[0].cookies.get_dict()
# 存入cookie池
save_cookie(cookie_dict)
if __name__ == '__main__':
test_list = [
{"username": "logic_00", "password": "logic_00"},
{"username": "logic_01", "password": "logic_01"},
{"username": "logic_10", "password": "logic_10"},
{"username": "logic_11", "password": "logic_11"}
]
for t in test_list:
username = t.get("username")
password = t.get("password")
# print(username, password)
login(username, password)对于网页有可能不是把cookie的信息存放在history的第一个元素里面的情况,我们需要优化代码。
session 会话对象 跨请求保持某一些参数。
import requests
from lxml import etree
from tools import get_js
import json
from requests import utils
def save_cookie(cookie_dict):
"""
把cookie存入cookie池中
Parameters
----------
cookie_dict 待存储的cookie
Returns
-------
"""
with open('cookies2.txt', 'a', encoding='utf-8') as file_obj:
# json.dumps 把字典转换成字符串
file_obj.write(json.dumps(cookie_dict) + '\n')
# 传入账号和密码 实现模拟登陆
def login(username, password):
# 请求的url和请求头
url = 'http://shanzhi.spbeen.com/login/'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'Cookie': 'csrftoken=3U8bCQmmBjGjuZYIWpkZsAr9nHBgnk93Va1lyPz542u4bfKo4toe1o6Rh8QIVmKo'
}
# Session 维持会话 在跨请求的时候可以保留某一些参数
session = requests.Session()
# 获取源码中的csrfmiddlewaretoken和pk
res = session.get(url, headers=header).text
html = etree.HTML(res)
csrfmiddlewaretoken = html.xpath('//input[@name="csrfmiddlewaretoken"]/@value')[0]
pk = html.xpath('//input[@id="pk"]/@value')[0]
# new_password为加密之后的密码
# 使用js环境进行的加密处理
new_password = get_js('./shanzhi.js', 'doLogin', password, pk)
postdata = {
'username': username,
'password': new_password,
'csrfmiddlewaretoken': csrfmiddlewaretoken
}
cresponse = session.post(url=url, headers=header, data=postdata)
# print(cresponse)
# 打断点之后 找到session 通过session再找到cookie
# 通过session获取cookie的方式一共有两种
# 第一种
# cookie_dict = session.cookies.get_dict()
# print(cookie_dict)
# 第二种
cookie_dict = utils.dict_from_cookiejar(session.cookies)
print(cookie_dict)
# 存入cookie池
save_cookie(cookie_dict)
if __name__ == '__main__':
test_list = [
{"username": "logic_00", "password": "logic_00"},
{"username": "logic_01", "password": "logic_01"},
{"username": "logic_10", "password": "logic_10"},
{"username": "logic_11", "password": "logic_11"}
]
for t in test_list:
username = t.get("username")
password = t.get("password")
# print(username, password)
login(username, password)利用爬取的cookie验证登录
import requests
from requests import utils
import json
# 从cookie池种获取cookie
with open('cookies.txt', 'r', encoding='utf-8') as file_obj:
# cookie = file_obj.read()
# readlines() 一次性从列表里面取出多行的
cookie_list = file_obj.readlines()
# print(type(cookie_list), cookie_list)
for cookie_str in cookie_list:
# print(cookie_str)
cookie_dict = json.loads(cookie_str)
# print(cookie_dict)
# 用session检测cookie 携带上cookie做模拟登录 如果能够模拟登录成功 就证明cookie是有效的
# url = 'http://shanzhi.spbeen.com/index/'
# # 会话对象
# session = requests.Session()
# # 把cookie放到session对象种
# session.cookies = utils.cookiejar_from_dict(cookie_dict)
#
# # 通过会话发送请求
# response_obj = session.get(url)
# print(response_obj.text, response_obj.status_code)
# 用requests检测cookie
cookie_turn = ['{}={}'.format(k, v) for k, v in cookie_dict.items()]
# print(cookie_turn)
cookie = '; '.join(cookie_turn)
url = 'http://shanzhi.spbeen.com/index/'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36',
'Cookie': cookie
}
response_obj = requests.get(url, headers=header)
print(response_obj.text, response_obj.status_code)