Yolo框架优化:黑夜中也可以实时目标检测,
点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院

公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
Column of Computer Vision Institute
目前的目标检测模型在许多基准数据集上都取得了良好的效果,在夜晚或者黑暗条件下检测目标仍然是一个巨大的挑战。

01
简介
为了解决这个问题,有研究者提出了一个金字塔增强网络(pyramid enhanced network,PENet),并将其与YOLOv3结合起来,构建了一个名为PE-YOLO的暗目标检测框架。首先,PENet使用拉普拉斯金字塔将图像分解为不同分辨率的四个分量。
具体来说,提出了一个细节处理模块( detail processing module,DPM)来增强图像的细节,该模块由上下文分支和边缘分支组成。此外,还提出了一种低频增强滤波器(LEF)来捕获低频语义并防止高频噪声。PE-YOLO采用端到端联合训练方法,仅使用正常检测损失来简化训练过程。在弱光物体检测数据集ExDark上进行了实验,以证明新框架的有效性。结果表明,与其他暗探测器和弱光增强模型相比,PE-YOLO的mAP和FPS分别达到78.0%和53.6%,能够适应不同弱光条件下的物体检测。

02
背景
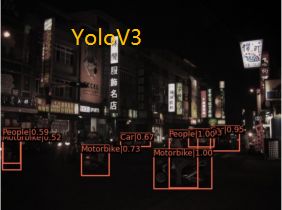
近年来,卷积神经网络的出现促进了目标检测的发展。已经提出了大量的检测器,并且基准数据集的性能得到了较好的结果。然而,大多数现有的探测器都是在正常条件下在高质量图像中进行研究的。在真实环境中,经常存在许多恶劣的照明条件,如夜间、暗光和曝光,因此图像质量的降低影响了检测器的性能。视觉感知模型使自动系统能够理解环境,并为后续任务(如轨迹规划)奠定基础,这需要稳健的目标检测或语义分割模型。下图是暗物体检测的示例。可以发现,如果对图像进行适当的增强,并根据环境条件恢复更多原始模糊目标的潜在信息,则目标检测模型能够适应不同的弱光条件,这在模型的实际应用中也是一个巨大的挑战。
目前,已经提出了许多方法来解决暗场景中的鲁棒性问题。已经提出了许多微光增强模型来恢复图像细节并减少不良照明条件的影响。然而,微光增强模型结构复杂,不利于检测器在图像增强后的实时性能。这些方法中的大多数不能用检测器进行端到端训练,并且需要对成对的微光图像和正常图像进行监督学习。弱光条件下的物体检测也可以被视为一个领域自适应问题。
一些研究人员使用对抗性学习将模型从正常光转换为暗光。但他们专注于匹配数据分布,忽略了低光图像中包含的潜在信息。在过去的几年里,一些研究人员提出了使用可微分图像处理(DIP)模块来增强图像并以端到端的方式训练检测器的方法。然而,DIP是传统的方法,如白平衡,对图像的增强效果有限。
弱光增强
微光增强任务的目标是通过恢复图像细节和校正颜色失真来改善人类视觉感知,并为诸如物体检测之类的高级视觉任务提供高质量的图像。[Kindling the darkness: A practical low-light image enhancer]提出了Kind,它可以通过具有不同照明水平的成对图像进行训练,而不需要地面实况。[Zero-reference deep curve estimation for low-light image enhancement]提出了Zero DCE,它将微光增强任务转化为图像特定的曲线估计问题。[Low-light image/video enhancement using cnns]提出了一种多分支微光增强网络(MBLLEN),该网络提取不同层次的特征,并通过多分支融合生成输出图像。[You only need 90k parameters to adapt light: a light weight transformer for image enhancement and exposure correction]提出了一种照明自适应变换器(IAT),通过动态查询学习构建端到端变换器。在弱光增强模型恢复图像细节后,检测器的效果得到了改善。然而,大多数微光增强模型都很复杂,对探测器的实时性能有很大影响。
不利条件下的目标检测
不利条件下的目标检测对于机器人的鲁棒感知至关重要,针对一些不利条件出现了鲁棒目标检测模型。有些人通过无监督的域自适应将检测器从源域转移到目标域,使模型适应恶劣的环境。[Image-adaptive yolo for object detection in adverse weather conditions]提出了IA-YOLO,它自适应地增强每个图像以提高检测性能。他们提出了一种适用于恶劣天气的可微分图像处理(DIP)模块,并使用小型卷积神经网络(CNN-P)来调整DIP的参数。在IA-YOLO的基础上,[Gdip: Gated differentiable image processing for object-detection in adverse conditions]提出了GDIP-YOLO。GDIP提出了一种门控机制,允许多个DIP并行操作。[Denet: Detection-driven enhancement network for object detection under adverse weather conditions]提出将检测驱动增强网络(DENet)用于恶劣天气条件下的目标检测。[Multitask aet with orthogonal tangent regularity for dark object detection]提出了一种用于暗物体检测的多任务自动编码变换(MAET),探索了光照转换背后的潜在空间。

03
新框架详解
由于低光干扰,暗图像的可见性较差,这影响了检测器的性能。为了解决这个问题,提出了一种金字塔增强网络(PENet)和联合YOLOv3来构建暗对象检测框架PE-YOLO。PE-YOLO的框架概述如下图所示。
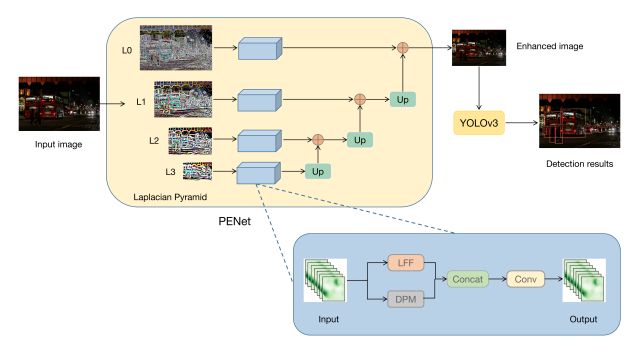
通过拉普拉斯金字塔获得了四个不同尺度的分量,如下图所示。

发现拉普拉斯金字塔自下而上更关注全局信息,而相反,它更关注局部细节。它们都是在图像下采样过程中丢失的信息,这也是PENet增强的对象。通过细节处理模块(DPM)和低频增强滤波器(LEF)来增强组件,并且DPM和LEF的操作是并行的。通过对拉普拉斯金字塔进行分解和重构,可以使PENet变得轻便有效,这有助于提高PE-YOLO的性能。
细节增强
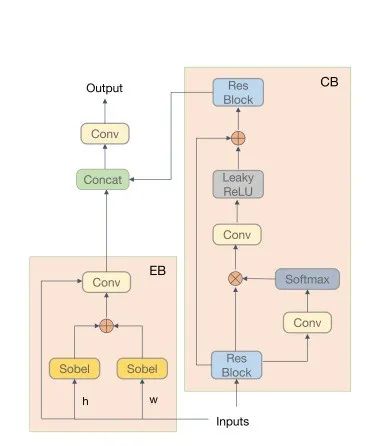
提出了一个细节处理模块(DPM)来增强拉普拉斯金字塔中的组件,该模块分为上下文分支和边缘分支。DPM的详细信息如下图所示。上下文分支通过捕获远程依赖关系来获取上下文信息,并对组件进行全局增强。边缘分支使用两个不同方向的Sobel算子来计算图像梯度,以获得边缘并增强组件的纹理。
低频增强滤波器
在每个尺度分量中,低频分量具有图像中的大部分语义信息,它们是检测器预测的关键信息。为了丰富重构图像的语义,提出了低频增强滤波器(LEF)来捕获分量中的低频信息。LEF的细节如下图所示。
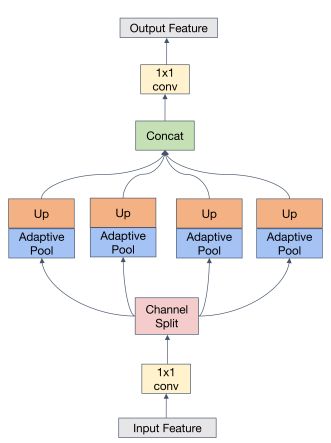
假设分量f∈Rh×w×3,首先通过卷积层将其变换为f ∈ Rh×w×32。使用动态低通滤波器来捕获低频信息,并使用平均池进行特征滤波,这只允许低于截止频率的信息通过。不同语义的低频阈值是不同的。考虑到Inception的多尺度结构,使用了大小为1×1、2×2、3×3、6×6的自适应平均池化,并在每个尺度的末尾使用上采样来恢复特征的原始大小。在不同内核大小的平均池化下形成低通滤波器。通过通道分离将fin分为四个部分,即{f1,f2,f3,f4}。

04
实验及可视化
PE-YOLO和微光增强型之间的性能比较。它显示了每个类别中的mAP和AP。粗体数字在每列中得分最高。


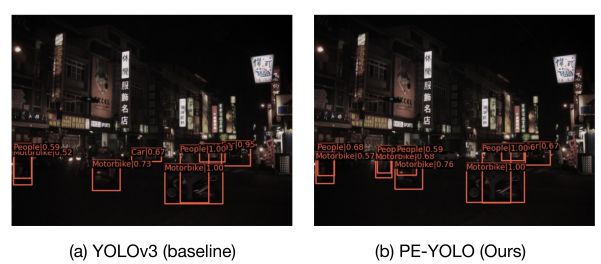
可视化了不同弱光增强模型的检测结果,如上图所示。我们发现,尽管MBLLEN和Zero DCE可以显著提高图像的亮度,但它们也会放大图像中的噪声。PE-YOLO主要捕捉低光图像中物体的潜在信息,同时抑制高频成分中的噪声,因此PE-YOLO具有更好的检测性能。

将PE-YOLO的性能与其他暗探测器进行了比较。此外,可视化了暗探测器和PE-YOLO的检测结果,如上图所示。这清楚地表明PE-YOLO在物体检测中更准确。与使用LOL数据集预训练的DENet和IAT-YOLO相比,PE-YOLO在mAP中分别高0.7%和0.2%,并且PE-YOLO在FPS上几乎也是最高的。上述数据表明,PE-YOLO更适合在黑暗条件下检测物体。
© THE END
转载请联系本公众号获得授权
![]()
计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

往期推荐
YOLO-S:小目标检测的轻量级、精确的类YOLO网络
InternImage:探索具有可变形卷积的大规模视觉基础模型
首个全量化Vision Transformer的方法FQ-ViT,AI大模型落地不远了!
YoloV8与ChatGPT互通,这功能是真的强大!
GPT理解的CV:基于Yolov5的半监督目标检测
Consistent-Teacher:半监督目标检测超强SOTA
Sparse R-CNN:稀疏框架,端到端的目标检测(附源码)
RestoreDet:低分辨率图像中目标检测
中国提出的分割天花板 | 精度相当,速度提升50倍!
All Things ViTs:在视觉中理解和解释注意力
基于LangChain+GLM搭建知识本地库
OVO:在线蒸馏一次视觉Transformer搜索
最近几篇较好论文实现代码(附源代码下载)
AI大模型落地不远了!首个全量化Vision Transformer的方法FQ-ViT(附源代码)