Python爬虫技术系列-04Selenium库的使用
Python爬虫技术系列-04Selenium库的使用
- 1 Selenium库基本使用
-
- 1.1 Selenium库安装
- 1.2 Selenium库介绍
- 2 Selenium库的使用
-
- 2.1 各个版本的区别
-
- 2.1.1 Selenium IDE介绍与使用
- 2.1.2 Selenium Grid介绍与使用
- 2.1.3 Selenium RC介绍与使用
- 2.1.4 WebDriver介绍与使用
- 2.2 WebDriver常用API
-
- 2.2.1 浏览器的操作
-
- 2.2.1.1 加载驱动
- 2.2.1.2 打开,关闭浏览器,浏览器窗口设置
- 2.2.1.3 前进后退刷新
- 2.2.2 元素的定位
-
- 2.2.2.1 定位元素的API
- 2.2.2.2 下拉列表的定位
- 2.2.2.3 层级元素的定位
- 2.2.2.4 对定位元素的操作
- 2.3 等待时间
- 2.4 文件上传
- 2.5 窗口切换
-
- 2.5.1 确认对话框
- 2.5.2 新窗口的切换
- 2.5.3 frame切换
- 2.6 WebDriver截图
- 2.7 WebDriver 调用JavaScript
- 2.8 鼠标和键盘事件
-
- 2.8.1 鼠标事件
- 2.8.2 键盘事件
- 2.9 selenium如何防止被检测
1 Selenium库基本使用
1.1 Selenium库安装
- 安装Selenium:
pip install selenium==3.141.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
- 安装selenium库之后,还要安装浏览器,一般本地都已经安装完毕,本书采用chrome浏览器,打开浏览器,在地址栏输入Chrome://version,可以查看到浏览器的版本,如下图所示:
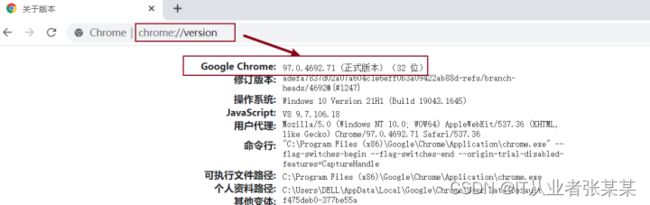
- 确定版本后,可以下载对应的驱动。
Selenium支持多种浏览器驱动,包括Chrome,opera,safari,firefox。为对应chrome浏览器,本例选用chrome驱动,
查看chrome驱动:
在浏览器的地址栏,输入chrome://version/,回车后即可查看到对应版本
chrome://version/
我电脑的版本为:
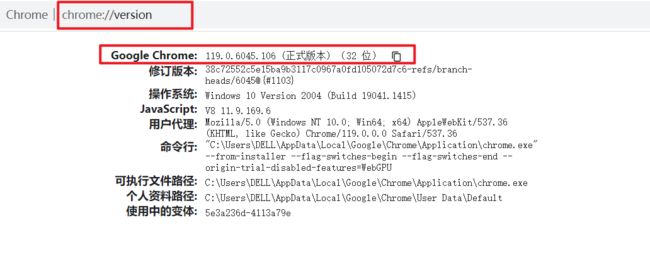
驱动的下载地址为
1.浏览器驱动官网:
http://chromedriver.storage.googleapis.com/index.html
2.淘宝镜像网站(推荐):
http://npm.taobao.org/mirrors/chromedriver/
在114版本前的驱动可以直接在上面的地址获取

针对119.0.x的版本驱动需要在
https://googlechromelabs.github.io/chrome-for-testing/
中下载
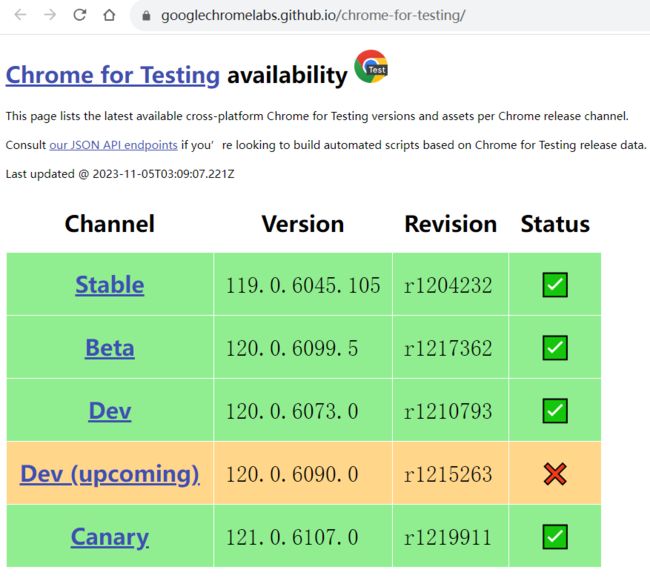
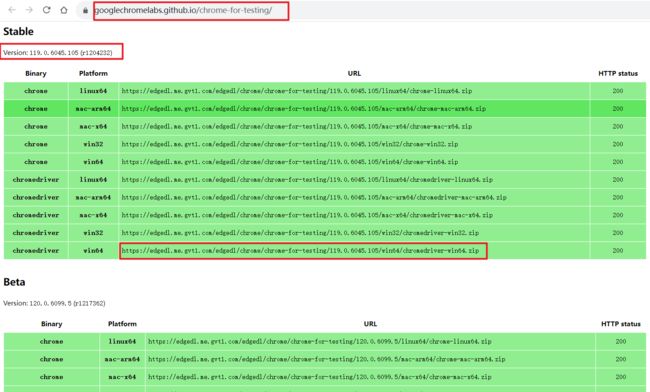
选择对应版本驱动chromedriver.exe,下载到本地,放在工程路径下即可。
1.2 Selenium库介绍
Selenium包含一系列工具和库,这些工具和库支持web浏览器的自动化。Selenium库最初用于自动化测试,但也可以应用数据爬取的场景。
有的网页中的信息需要执行js才能显现,动态网页中, 通常只会更新局部的Html元素, webdriver会很好的帮助用户快速定位这些元素,最终目的是通过提供精心设计的面向对象API来解决现代高级网页中的测试难题。动态网页的存在导致requests库爬取到的源代码与浏览器端看到的数据不一致,这种情况可以通过selenium进行爬取,Selenium会模拟浏览器,爬取执行 js 后的网页数据,实现“所见即所得”。尽管Selenium爬取数据的效率要低很多,但在一些不易爬取的网页中,有着神奇的效果。
2 Selenium库的使用
2.1 各个版本的区别

Selenium 1.0 = Selenium IDE + Selenium Grid + Selenium RC
Selenium 2.0 = Selenium 1.0 + WebDriver
Selenium 3.0 = Selenium 2.0 - Selenium RC(Remote Control)
2.1.1 Selenium IDE介绍与使用
Selenium IDE 是作为 Selenium 在浏览器 Firefox 和 Chrome 的插件,用于记录、重放测试脚本,并且脚本也可以导出到 C#,Java,Ruby 或 Python 等编程语言。github 地址:https://github.com/SeleniumHQ/selenium-ide
Selenium IDE 负责录制、回放脚本,模拟用户对页面的真实操作
使用的大致流程:
1.在firefox或chrome中按住拓展插件
以firefox浏览器为例
添加后,就可以使用Selenium IDE了
具体参考:浏览器自动化利器Selenium IDE使用指南
2.1.2 Selenium Grid介绍与使用
Selenium Grid 用于分布式自动化测试,通过控制多台机器、多个浏览器并行执行测试用例,在测试用例比较多的情况下比较实用。
① Selenium Grid 是Selenium套件的一部分,它专门用于并行运行多个测试用例在不同的浏览器、操作系统和机器上。
② Selenium Grid 主要使用 master-slaves 或者 hub-nodes 理念 :一个 master/hub 和多个基于 master/hub 注册的子节点 slaves/nodes 。
当我们在master上基于不同的浏览器/系统运行测试用例时,master将会将测试用例分发给适当的node运行。(当然也可以作为兼容性测试工具将测试用例运行在不同的web浏览器上)
③
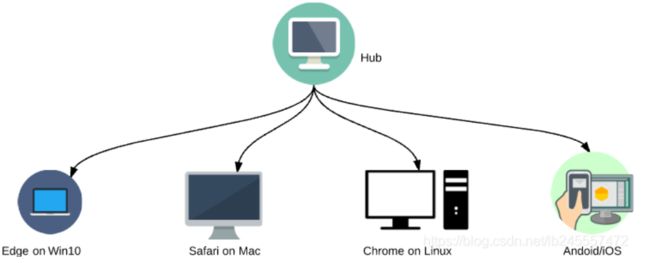
④ selenium Grid 主要的作用:实现分布式执行测试,解决浏览器兼容性问题。【通过 Selenium Grid 的可以控制多台机器多个浏览器执行测试用例,分布式上执行的环境在 Selenium Grid 中称为node节点。】
⑤举例:
当自动化测试用例达到一定数量的时候,比如上万,一台机器执行全部测试用例耗时5个小时(只是举例,真正的耗时是需要根据测试用例场景的复杂度决定的),而如果需要覆盖主流浏览器比如Chrome、Firefox,加起来就是10个小时;这时候领导跟你说有什么办法可以解决这个执行速度?当然最笨的办法就是另外拿台机器,然后部署环境,把测试用例分开去执行然后合并结果即可。而Selenium也想到了这点,所以有了Selenium Grid的出现,它就是解决分布式执行测试的痛点。
⑥总结:
Slenium Grid 分布式测试由hub主节点和node节点组成
Hub节点用来管理node节点注册信息。
脚本——》Hub节点——》node节点——》浏览器
具体参考:
selenium Grid详解
Selenium Grid 分布式 | 介绍与实战
2.1.3 Selenium RC介绍与使用
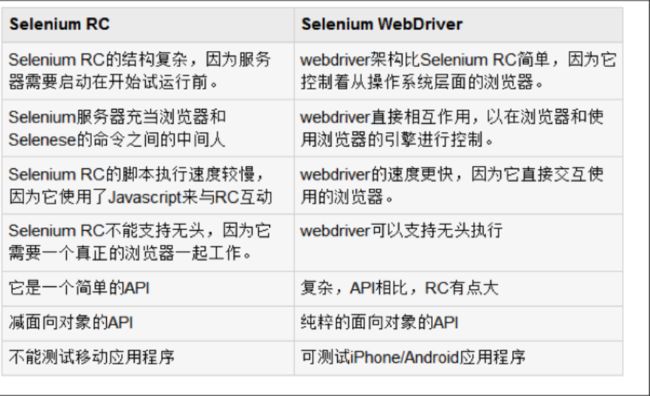
早期的Selenium使用的是Javascript注入技术与浏览器打交道,需要Selenium RC启动一个Server,将操作Web元素的API调用转化为一段段Javascript,在Selenium内核启动浏览器之后注入这段Javascript。
Javascript可以获取并调用页面的任何元素进行操作,实现了Selenium自动化Web操作的目的。这种Javascript注入技术的缺点是速度不理想,而且稳定性大大依赖于Selenium内核对API翻译成的Javascript质量高低。
2.1.4 WebDriver介绍与使用
Selenium2.x 提出了WebDriver的概念之后,它提供了完全另外的一种方式与浏览器交互。那就是利用浏览器原生的API,封装成一套更加面向对象的Selenium WebDriver API,直接操作浏览器页面里的元素,甚至操作浏览器本身(截屏,窗口大小,启动,关闭,安装插件,配置证书之类的)。由于使用的是浏览器原生的API,速度大大提高,而且调用的稳定性交给了浏览器厂商本身,显然是更加科学。然而带来的一些副作用就是,不同的浏览器厂商,对Web元素的操作和呈现多少会有一些差异,这就直接导致了Selenium WebDriver要分浏览器厂商不同,而提供不同的实现。例如Firefox就有专门的FirefoxDriver,Chrome就有专门的ChromeDriver等等。(甚至包括了AndroidDriver和iOS WebDriver)
2.2 WebDriver常用API
2.2.1 浏览器的操作
导入依赖
# #1.webdriver的使用
import time
from selenium import webdriver
from selenium.webdriver.support.select import Select
2.2.1.1 加载驱动
#使用方式1:放置环境变量路径
#例如将驱动文件直接放置到已配置好的python环境变量根路径。
dr = webdriver.Chrome()
dr = webdriver.Firefox()
dr = webdriver.Ie()
#使用方式2:指定绝对路径
dr = webdriver.Chrome(executable_path="C:\driver\chromedriver.exe")
dr = webdriver.Firefox(executable_path="C:\driver\geckodriver.exe")
dr = webdriver.Ie(executable_path="C:\driver\IEDriverServer.exe")
#注:可用于浏览器兼容性测试。
案例:
# firefox
wd = webdriver.Firefox(firefox_binary=r'C:\Program Files (x86)\Mozilla Firefox\firefox.exe',executable_path=r'F:\桌面文件\工具\geckodriver.exe')
# chrome
wd = webdriver.Chrome(executable_path='./chromedriver.exe')
2.2.1.2 打开,关闭浏览器,浏览器窗口设置
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.select import Select
wd = webdriver.Chrome(executable_path='./chromedriver.exe')
# 最大化窗口
wd.maximize_window()
# 设置窗口宽度和高度
wd.set_window_size(1400,1500)
# 设置窗口位置
wd.set_window_position(100,100)
wd.get('https://www.baidu.com/')
time.sleep(4)
# 关闭窗口
# wd.close()
wd.quit()
2.2.1.3 前进后退刷新
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 最大化窗口
driver.maximize_window()
# 设置窗口宽度和高度
driver.set_window_size(1400,1500)
# 设置窗口位置
driver.set_window_position(100,100)
driver.get('https://www.baidu.com/')
driver.get('https://www.zhihu.com/')
time.sleep(3)
driver.back() #后退
time.sleep(3)
driver.refresh() # 刷新
time.sleep(3)
driver.forward() # 前进
# 等待
time.sleep(4)
# 关闭窗口
# driver.close()
driver.quit()
2.2.2 元素的定位
2.2.2.1 定位元素的API
定位一个或多个:
driver.find_element_by_
driver.find_elements_by_
具体如下:
dr.find_element_by_id()
dr.find_element_by_name()
dr.find_element_by_tag_name()#标签名
dr.find_element_by_link_text()#完全匹配链接文本
dr.find_element_by_partial_link_text()# 模糊匹配链接文本
dr.find_element_by_class_name()
dr.find_element_by_css_selector()
dr.find_element_by_xpath()
注:
1.确保唯一属性的情况下,定位推荐使用顺序id-name-xpath-other;
2.定位一组具有相同属性的元素,例如:dr.find_elements_by_name();
3.有时即便有id也不能通过id定位,因为它可能是动态id;
4.由于selenium使用xpath定位时采用遍历页面的方式,在性能上采用CSS选择器的方式更优。xpath虽然性能指标较差,但是在浏览器中有比较好的插件支持,定位元素比较方便,对于性能要求严格的场景,可考虑通过xpath改写css的方式进行替换。
2.2.2.2 下拉列表的定位
div+li形成的下拉列表:
案例
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 最大化窗口
driver.maximize_window()
driver.get('https://www.lagou.com/zhaopin/')
# 等待
time.sleep(4)
# 选择排序方式
driver.find_element_by_xpath('//*[@id="order"]/li/div[1]/a[1]').click()
time.sleep(4)
# 单击工作性质后的下拉框
driver.find_element_by_xpath('//*[@id="order"]/li/div[3]/div').click()
time.sleep(4)
# 单击兼职选项
driver.find_element_by_link_text("兼职").click()
time.sleep(4)
# 关闭窗口
# driver.close()
driver.quit()
select元素的下拉列表
# 通过索引选择
Select(driver.find_element_by_xpath('//*[@id="order"]/li/div[3]/div')).select_by_index(2)
# 通过内容选择选项
Select(driver.find_element_by_xpath('//*[@id="order"]/li/div[3]/div')).select_by_visible_text('兼职')
# 通过value属性选择选项
Select(driver.find_element_by_xpath('//*[@id="order"]/li/div[3]/div')).select_by_value('兼职')
# 需要注意如果被选择的元素不是select元素,会抛出错误 Select only works on