【动手学深度学习v2】--课后笔记(个人记录)
文章目录
- 前言
- 零:知识先导
- 一、二、三:安装和简介
- 四:数据相关
- 五:线性代数
- 六:矩阵计算
- 七:自动求导
- 八:线性回归
-
- 初始线性回归以及其简洁实现:
- 九:Softmax回归+损失函数+图片分类数据集
- 总结
-
- ==深度学习就是函数逼近器==
- 将任何事物 x --> f(x) --> y 中的f(x)都看成wx+b。并通过一层层的反向求导和迭代,找到最接近f(x)的w和b
前言
- 大二小白,看完吴恩达的深度学习后很感兴趣,但是理解很浅
- 打算刷完李沐的深度学习课程作为补充和强化
- 做此记录以监督自己的学习进度
- 欢迎大佬们对笔记内容的指正和对自己见解的分享
零:知识先导
jupyter使用方法:
- 命令行cd到本地的指定目录下,jupyter notebook 打开
- .ipnb:jupyter指定文件
- 全部运行:cell -> run all
- Folder:新建文件夹
- Terminal:打开命令行
- shift + 回车 == 运行这行
- 蓝:命令模式 回车跳入
- m:变为Markdown
- y:变成代码单元格
- b:下方创建新单元格
- a:上方
- d:删除
- l:标注行数
- 绿:编辑模式 esc返回
一、二、三:安装和简介
算力云链接: AutoDL算力云
- 选择pytorch镜像,进入JupyterLab,在终端下载解压《动手学深度学习》Jupyter后,可直接启动(需要下载d2l等包)
四:数据相关
- 访问元素
一列:[: , 1]
- 基本操作
- .arange(num, dtype = torch.float32):创建行向量(限定为小数,可不加)
- .reshape:重设大小
- .zeros((2, 3, 4)):初始化0的矩阵
- .randn(3, 4):0~1的高斯分布
- .tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]):自定创建
- 运算符
- 任意相同形状的张量可直接运算(** : 求幂)
- torch.exp(x):对输入input逐元素进行以自然数e为底指数运算
- torch. cat((X, Y), dim = 0) (dim = 0:上下连结 , dim = 1:左右连结)
- X == Y : 返回矩阵,元素为true、false
- X.sum( ) : 返回只有一个元素的张量
- 广播机制
- 前提:两矩阵的维度相同
- 矩阵形状不同时,会对小的那个维度自动复制(广播)
- 索引与切片
- X[-1]:取最后一行(和python一样,-1为最后)
- X[1 : 3]:取2~4行
- X[1, 2] = 9:更改指定位置的元素值
- X[0:2] = 12:对X的第一(维度)行到第二行(左闭右开)赋值为12
- 节省内存
- Z[:] = X + Y 或 X += Y都不会额外开销内存
五:线性代数
- 降维求和:利用指定张量延哪一个轴来求和,来降低维度
A_sum_axis0 = A.sum(axis=0)
# 求和所有的行元素来降维
A_sum_axis01 = A.sum(axis=[0,1])
# 对行和列进行求和
A.mean(axis=0)
# 相当于:(除法也可以降维)
A.sum(axis=0) / A.shape[0]
- 非降维求和
sum_A = A.sum(axis=1, keepdims=True)
# 意味着被求和的维度的大小变为1,总轴数不变
A / sum_A
# 利用广播机制,实现对元素求其在本行中的占比
A.cumsum(axis=0)
# 对axis轴逐轴累加,不影响轴数
- 点积
torch.dot(x, y)
# y为标量(相同位置的元素相乘再相加)
# 相当于:
torch.sum(x * y)
- 矩阵乘向量
torch.mv(A, x)
# A中axis=1的长度必须与x长度相等
- 矩阵乘矩阵
torch.mm(A, B)
# 矩阵乘法,行乘列···
- 范数
- 表示一个向量的大小
L 2 L_2 L2范数:向量元素平方和的平方根:
∥ x ∥ 2 = ∑ i = 1 n x i 2 , \|\mathbf{x}\|_2 = \sqrt{\sum_{i=1}^n x_i^2}, ∥x∥2=i=1∑nxi2,
torch.norm(u)
# 返回标量
L 1 L_1 L1范数:向量元素的绝对值之和:
∥ x ∥ 1 = ∑ i = 1 n ∣ x i ∣ . \|\mathbf{x}\|_1 = \sum_{i=1}^n \left|x_i \right|. ∥x∥1=i=1∑n∣xi∣.
torch.abs(u).sum()
# 与L2范数相比,受异常值的影响更小
F范数(Frobenius):把矩阵的所有元素拉成一条向量,再做其范数
∥ X ∥ F o r b = ∑ i = 1 m ∑ j = 1 n x i j 2 \|\mathbf{X}\|_{Forb} = \sqrt{\sum_{i=1}^m \sum_{j=1}^n x_{ij}^2} ∥X∥Forb=i=1∑mj=1∑nxij2
torch.norm(torch.ones((4, 9)))
# Frobenius范数满足向量范数的所有性质,它就像是矩阵形向量的范数。
补充:
- csv文件:人工数据集,逗号分割。使用pandas读取csv文件
- 对缺失数据的插值处理:
- 对于数值类型,取平均
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())# .mean:取平均
print(inputs)
- 对于字符串类型,将NaN视为一个特征,将所有不同特征的字符串转为索引、
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
- 将所有类型都转为数值类型后,转换为张量格式
import torch
X = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
X, y
- pytorch经常用32位浮点数
六:矩阵计算
- 略
七:自动求导
- 开辟空间来储存梯度
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 默认值是None
# x.grad 可访问梯度
- 反向传播
y.backward() # 反向传播
x.grad # 显示梯度
- 清除梯度
# 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
x.grad.zero_() # 清零梯度
y = x.sum()
y.backward()
x.grad
八:线性回归
- 线性回归是对n维输入的加权,外加偏差
- 使用平方损失来衡量预测值和真实值的差异
- 线性回归 <==> 单层神经网络
参数w,b由最小化损失决定
初始线性回归以及其简洁实现:
- 导包
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
from torch import nn
- 生成数据集
true_w = torch.tensor([2, -3.4])
true_b = 4.2
d2l.synthetic_data(true_w, true_b, 1000)
# 根据true_w,true_b,构造随机的1000大小的数据集
- 读取数据集
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
# data.TensorDataset:对数据进行封装;
return data.DataLoader(dataset, batch_size, shuffle=is_train)
# data.DataLoader:对数据进行加载
# 设定批量大小,开始迭代
batch_size = 10
data_iter = load_array((features, labels), batch_size)
# features:特征 labels:标签
next(iter(data_iter))
# 使用iter构造Python迭代器,并使用next从迭代器中获取第一项
- 定义模型
net = nn.Sequential(nn.Linear(2, 1))
# Linear:单层线性回归层(输入,输出)
# nn.Sequential():有序容器,一个个执行模块,可以允许将整个容器视为单个模块
- 初始化模型
net[0].weight.data.normal_(0, 0.01)
# 访问Sequential容器的第一层的权重数据 .normal_(均值,方差):使用正态分布来替换data的值
net[0].bias.data.fill_(0)
# 偏差设置
- 定义损失函数和优化算法
loss = nn.MSELoss()
# MSELoss:计算均方误差,平方范数
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
# SGD(stochastic gradient descent):随机梯度下降
# .parameters:包含所有w和b的字典
# lr:学习率
- 训练
num_epochs = 3 # 迭代三个周期
for epoch in range(num_epochs):
for X, y in data_iter:
# 在data_iter中一次次把X和y取出
l = loss(net(X) ,y)
# net(X):预测值
trainer.zero_grad()
# 优化器trainer把梯度清零,不然会累加
l.backward()
# 往回计算w,b
trainer.step()
# step()对模型进行更新
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
# 每迭代一次进行打印记录
查torch手册!
九:Softmax回归+损失函数+图片分类数据集
回归问题和分类问题的区别:
回归(多少?):估计一个连续值(例:房价预测,输入连续值,输出一个最佳的(与真实值的区别作为损失))
分类:(哪一个?)预测一个离散问题(例:识别猫狗,多输出,输出i是预测为第i类的置信度)
从回归到多分类–均方损失
- 独热码:对类别进行一维有效编码,[0,0,0,0,0,0,1,0,0,0]T
- 使用均方损失训练独热码
- 最大值作为预测
o 1 = x 1 w 11 + x 2 w 12 + x 3 w 13 + x 4 w 14 + b 1 , o 2 = x 1 w 21 + x 2 w 22 + x 3 w 23 + x 4 w 24 + b 2 , o 3 = x 1 w 31 + x 2 w 32 + x 3 w 33 + x 4 w 34 + b 3 . \begin{aligned} o_1 &= x_1 w_{11} + x_2 w_{12} + x_3 w_{13} + x_4 w_{14} + b_1,\\ o_2 &= x_1 w_{21} + x_2 w_{22} + x_3 w_{23} + x_4 w_{24} + b_2,\\ o_3 &= x_1 w_{31} + x_2 w_{32} + x_3 w_{33} + x_4 w_{34} + b_3. \end{aligned} o1o2o3=x1w11+x2w12+x3w13+x4w14+b1,=x1w21+x2w22+x3w23+x4w24+b2,=x1w31+x2w32+x3w33+x4w34+b3.
-
Softmax回归是分类问题
作用:将具体的值转换为相对的概率(非负,和为一)
y ^ = s o f t m a x ( o ) 其中 y ^ j = exp ( o j ) ∑ k exp ( o k ) \hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{o})\quad \text{其中}\quad \hat{y}_j = \frac{\exp(o_j)}{\sum_k \exp(o_k)} y^=softmax(o)其中y^j=∑kexp(ok)exp(oj) -
exp(x) == ex
-
损失函数(交叉熵损失):度量预测的效果
-
索引 i i i的样本由特征向量 x ( i ) \mathbf{x}^{(i)} x(i)和独热标签向量 y ( i ) \mathbf{y}^{(i)} y(i)组成
l ( y , y ^ ) = − ∑ j = 1 q y j log y ^ j . l(\mathbf{y}, \hat{\mathbf{y}}) = - \sum_{j=1}^q y_j \log \hat{y}_j. l(y,y^)=−j=1∑qyjlogy^j. -
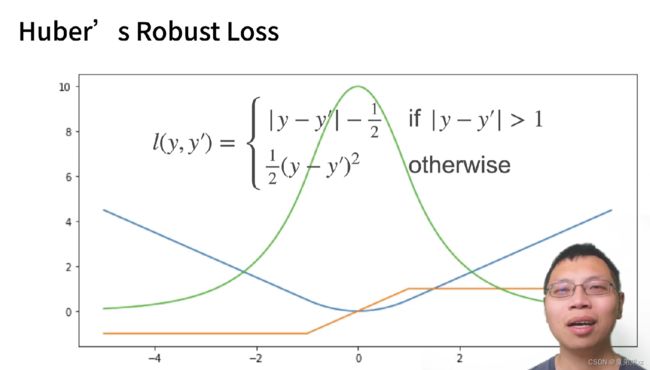
鲁棒损失