MySQL锁的类型及加锁范围
概述
MySQL 锁简述
MySQL 中的锁按不同维度划分,可分为不同的锁类型。
按读写权限划分:
- 共享锁(S):其他事务可以读,但不能写。
- 排他锁(X) :其他事务不能读取,也不能写。
按加锁粒度划分:
- 全局锁:对整个数据库实例加锁,典型使用场景是做全库逻辑备份。
- 表级锁主要有:
- 表锁。会对整张表加锁,lock tables 语法除了会限制别的线程的读写外,也限定了本线程接下来的操作对象;
- 元数据锁(meta data lock,MDL)。MDL不需要显式使用,在访问一个表的时候会被自动加上,主要作用是保证读写的正确性。例如一个查询正在遍历一个表中的数据,而执行期间另一个线程对这个表结构做变更删了一列,那么会导致查询线程拿到的结果跟表结构对不上。
- 行锁。行锁就是针对数据表中行记录的锁,MySQL 的行锁是在引擎层由各个引擎自己实现的,有些也没有行锁(例如MyISAM)。
InnoDB 锁简述
InnoDB 是目前较为常用的存储引擎,InnoDB 通过不同粒度的锁和不同读写权限的锁相互组合,共同实现并发控制。除 S 锁和 X 锁外,还主要包含以下类型的锁:
表级锁:
- IS(意向共享锁):事务有意向对表中的某些行加共享锁(S)。事务要获取某些行的 S 锁,必须先获得表的 IS 锁。
- IX(意向排他锁):事务有意向对表中的某些行加排他锁(X)。事务要获取某些行的 X 锁,必须先获得表的 IX 锁。
意向锁的好处就是当我们准备加表锁的时候,不需要在表中的每一行去判断是否有行锁,只需要判断一下表上是否有意向锁,节约了时间去遍历整张表。
记录级锁:
- Gap Lock:只锁间隙,前开后开区间(a,b),对索引的间隙加锁,防止其他事务插入数据。
- Record Lock:只锁记录,特定几行记录。
- Next-Key Lock:同时锁住记录和间隙,前开后闭区间(a,b]。
锁的兼容性

Gap Lock 之间是兼容的,即使范围有重叠,这种情况下很容易造成死锁。
Eg from知乎的一个例子
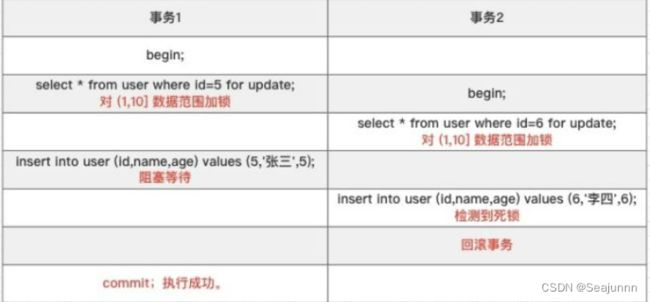
Select For Update/Share 加锁分析
InnoDB 在不同隔离模式下加锁方式、加锁类型、加锁范围等都可能不同,本文只讨论 InnoDB 在 RR(可重复读) 隔离级别下,执行 select … for update/share 时的加锁情况。此外,不同的 MySQL 版本加锁规则也可能不同,本文限定版本为 MySQL 8.0.25。
加锁原则
参考《MySQL实战45讲》
- 原则1:加锁的基本单位是 next-key lock,前开后闭区间 (];
- 原则2:查找过程中访问到的对象才会加锁;
- 优化1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁;
- 优化2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 优化为间隙锁;
这里提出几点疑问:
- 在等值查询下,加锁的类型和范围是什么?
- 等值查询数据存在和不存在时,加锁有什么区别?
- 在范围查询下,加锁的类型和范围是什么?
- 查询条件是主键、唯一索引、普通索引、非索引字段时,加锁有什么不同?
- for share 和 for update 有什么不同?有什么特殊案例?
下面将带着疑问通过实验来探究 InnoDB 在 RR 模式下执行 select … for update/share 的加锁情况。
预备知识
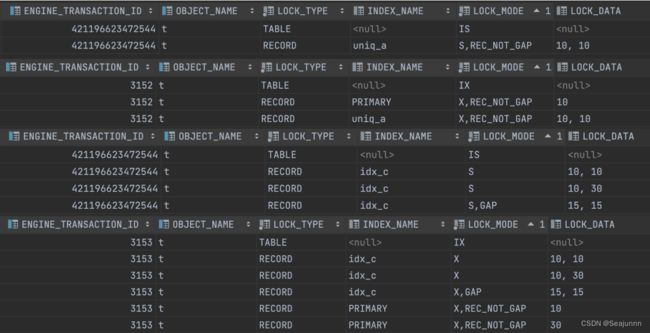
要分析加锁情况,首先需要确定如何查看当前表的加锁情况。MySQL 8.0.25 版本 performance_schema.data_locks 表保存了当前事务的加锁情况,因此,通过分析这个表中的数据可以获得当前表的加锁情况,表中的主要字段包括:
- ENGINE:存储引擎,这里只考虑 InnoDB
- OBJECT_SCHEMA:当前表所在的数据库
- ENGINE_TRANSACTION_ID:事务 ID
- OBJECT_NAME:表名
- LOCK_TYPE:
- TABLE(表级锁)
- RECORD(记录级锁)
- INDEX_NAME:索引
- LOCK_MODE:IX/X/REC_NOT_GAP/GAP 等
- IX:意向锁,值为 IX 时 LOCK_TYPE 通常为 TABLE
- X:next-key lock,前开后闭区间
- REC_NOT_GAP:行锁
- GAP:间隙锁
- LOCK_DATA:加锁的记录
下面通过例子说明表加锁的具体含义。假设当前有一个表 t,表中有6条数据,具体见下文实验环境准备部分。
| LOCK_MODE | LOCK_DATA | INDEX_NAME | 加锁区间 |
|---|---|---|---|
| X | 5 | PRIMARY | (0, 5] |
| X,REC_NOT_GAP | 5 | PRIMARY | [5] |
| X,GAP | 5 | PRIMARY | (0,5) |
mysql的blog上才看到一个锁的准确描述. 如下:
https://dev.mysql.com/blog-archive/innodb-data-locking-part-2-locks/
- S,REC_NOT_GAP → shared access to the record itself (行共享锁,或者行读锁)
- X,REC_NOT_GAP → exclusive access to the record itself (行排他锁,或者行写锁)
- S,GAP → right to prevent anyone from inserting anything into the gap before the row (共享gap锁)
- X,GAP → same as above. Yes, “S” and “X” are short for “shared” and “exclusive”, but given that the semantic of this access right is to “prevent insert from happening” several threads can all agree to prevent the same thing without any conflict, thus currently InnoDB treats S,GAP and X,GAP (or *,GAP locks, for short) the same way: as conflicting just with *,INSERT_INTENTION (共享gap锁, 虽然名字叫"排他",实际上和上面的一样.)
- S → is like a combination of S,REC_NOT_GAP and S,GAP at the same time. So it is a shared access right to the row, and prevents insert before it. (共享邻键锁)
- X → is like a combination of X,REC_NOT_GAP and X,GAP at the same time. So it is an exclusive access right to the row, and prevents insert before it. (排他邻键锁)
- X,GAP,INSERT_INTENTION → right to insert a new row into the gap before this row. Despite “X” in its name it is actually compatible with others threads trying to insert at the same time. (插入检查唯一约束会使用这个锁, 但是只要不违反唯一约束, 每个线程都可以获取这个锁. 但是和上面的S,GAP排斥)
- X,INSERT_INTENTION → conceptually same as above, but only happens for the “supremum pseudo-record” which is imaginary record “larger than any other record on the page” so that the gap “before” “it” is actually “gap after the last record”.
实验环境准备
MySQL 版本
8.0.25
表结构:
CREATE TABLE `t` (
`id` int NOT NULL AUTO_INCREMENT,
`a` int DEFAULT NULL COMMENT '唯一索引',
`c` int DEFAULT NULL COMMENT '普通索引',
`d` int DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_a` (`a`),
KEY `idx_c` (`c`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
insert into t values (0, 0, 0, 0), (5, 5, 5, 5), (10, 10, 10, 10), (15, 15, 15, 15), (20, 20, 20, 20), (25, 25, 25, 25), (30, 30, 30, 30);
简而言之
id主键索引 a唯一索引 c普通索引 d没有索引
表数据:

等值查询 — 数据存在
首先执行几组查询,并查看加锁情况:
- Q1:
mysql> begin; select * from t where id = 10 for update; - Q2:
mysql> begin; select * from t where a = 10 for update; - Q3:
mysql> begin; select * from t where c = 10 for update; - Q4:
mysql> begin; select * from t where d = 10 for update;
结果:

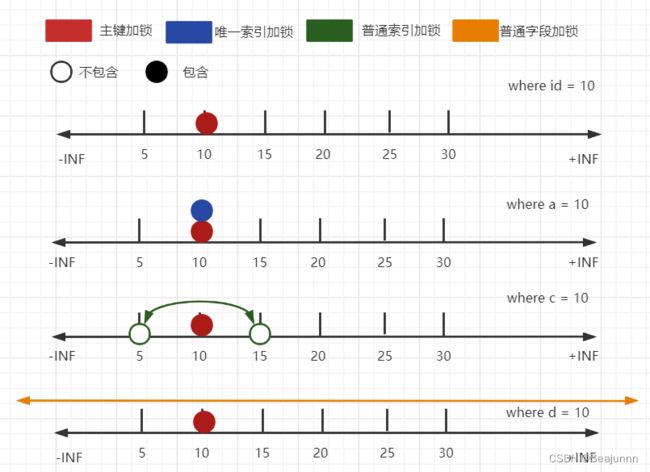
上图仅为了方便作图,在数轴上将加锁区间进行了合并展示(下同),实际是分多段加锁。
分析:
- 表都加了 IX 锁;
- 主键等值查询,理论加锁区间为
(5, 10],但根据优化1,最终只对主键加行锁; - 唯一索引等值查询,同样根据优化1,只对索引字段加行锁,同时给主键加行锁(for share 且索引覆盖时结果不同);
- 普通索引等值查询,理论区间为
(5,10], (10,15],但根据优化2,(10,15] next-key lock退化为gap lock (10,15),最终合并区间为(5,15),同时给对应的主键加行锁; - 无索引字段对表主键所有范围加锁(supremum pseudo-record 可以理解为正无穷);
结论:
- 主键只加行锁;
- 唯一索引会加行锁,并给对应的主键加行锁(未考虑S锁和覆盖索引);
- 普通索引会加 next-key lock,并应用优化2;
- 表都加了意向锁;
- for update 改为 for share 时锁类型会由 X/IX 变为 S/IS,加锁区间相同;
- 无索引字段会对主键所有区间加锁,数据量大时会影响性能;
等值查询 — 覆盖索引
下面考虑覆盖索引的情况,将select * ...改为select id ...,执行几组查询并查看加锁情况:
- Q1:
mysql> begin; select id from t where a = 10 for share; - Q2:
mysql> begin; select id from t where a = 10 for update; - Q3:
mysql> begin; select id from t where c = 10 for share; - Q4:
mysql> begin; select id from t where c = 10 for update;
结论:
- 通过唯一索引或普通索引做等值查询 id 字段时,
for share都不会对主键加锁(MySQL索引覆盖优化),但是for update都会对主键加锁; - 普通字段查询时,
for share/update都会对主键所有区间加锁(结果未展示);
等值查询 — 数据不存在
下面测试数据不存在时,加锁范围情况。
- Q1:
mysql> begin; select * from t where id = 11 for update; - Q2:
mysql> begin; select * from t where a = 11 for update; - Q3:
mysql> begin; select * from t where c = 11 for update;

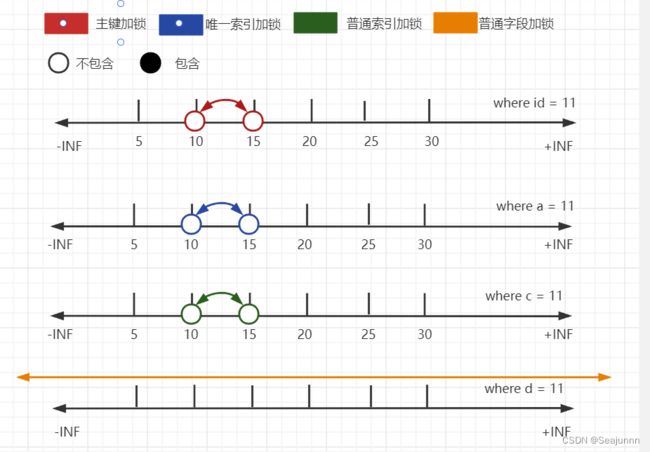
分析:
- 使用主键查询时,理论范围为
(10,15],实际范围为(10, 15),符合优化2; - 使用唯一索引和普通索引查询时结果同上;
- 使用非索引字段查询时,给主键所有范围加锁(未展示结果);
对 id=11 查询做验证,在新 session 中执行以下操作:
![]()

为防止 update 对后面实验造成影响,事务最后均回滚,记录值实际未更新。
结果显示,插入 id=12 的行是不允许的,而修改 id=15 的行是允许的,这也验证了锁的间隙是(10,15)。
结论:
- 基于主键/唯一索引/普通索引字段,会锁住对应索引查询条件所在的间隙,并根据优化2将
(]区间优化为()区间; - 基于无索引字段查询时,会锁住主键所有区间;
- for share 加锁区间相同;
gap lock的兼容性
两个事务执行:
transaction1:
select * from t where id = 11 for update;
transaction2:
select * from t where id = 12 for update;
事务t1先执行第一条,事务t2再执行第二条是不会阻塞的
也应证了一开始说的锁的兼容性
Gap Lock 之间是兼容的,即使范围有重叠,这种情况下很容易造成死锁。
范围查询
范围查询情况较多,下面分别举例。
例1:> 17
- Q1:
mysql> begin; select * from t where id>17 for update; - Q2:
mysql> begin; select * from t where a>17 for update; - Q3:
mysql> begin; select * from t where c>17 for update;

q1:主键id(15,+INF)
q2:唯一索引a(15,+INF) 主键id(20,25,30)
q3:普通索引c(15,+INF) 主键(20,25,30)
例2:<15
- Q1:
mysql> begin; select * from t where id<15 for update; - Q2:
mysql> begin; select * from t where a<15 for update; - Q3:
mysql> begin; select * from t where c<15 for update;

q1: 主键id(-INF,15)
q2: 唯一索引a(-INF,15] 主键id(0,5, 10)
q3: 普通索引c(-INF,15] 主键id(0,5, 10)
结论:
- 基于主键查询时,右侧值不相等,会将 next-key lock 优化为 gap lock,基于唯一索引和普通索引查询时不会进行优化;
- 基于唯一索引和普通索引查询时还会对范围内的主键加行锁;
- 使用非索引字段做范围查询时,会给主键所有区间加锁(未展示);
- for share 加锁区间相同;
例3:≥ 15
-
Q1:
mysql> begin; select * from t where id>=15 for update; -
Q2:
mysql> begin; select * from t where a>=15 for update; -
Q3:
mysql> begin; select * from t where c>=15 for update;

分析: -
基于主键查询时,理论加锁范围为
(10, +INF),实际加锁范围为[15, +INF),可见MySQL id=15 时的范围优化为了行锁; -
基于唯一索引和普通索引查询时,加锁范围为
(10, +INF),并没有优化。此外还对范围内对应的主键加了行锁;
结论:
- 做范围查询时,左侧相等,则会对主键做范围优化,next-key lock 优化为行锁;
- 基于唯一索引和普通索引查询时,还对范围内对应的主键加了行锁;
- 使用非索引字段做范围查询时,会给主键所有区间加锁(未展示);
- for share 加锁区间相同;
例4:≤15
- Q1:
mysql> begin; select * from t where id<=15 for update; - Q2:
mysql> begin; select * from t where a<=15 for update; - Q3:
mysql> begin; select * from t where c<=15 for update;
结论:
- 主键查询时,右侧相等,则会少加一个 next-key lock;
- 唯一索引查询时,加锁范围为
(-INF, 20],并没有像主键那样做优化。此外还对范围内对应的主键加了行锁; - 普通索引查询时,加锁范围为
(-INF, 20],此外还对范围内对应的主键加了行锁; - for share 加锁区间相同;
结论:
- 主键查询时,右侧相等,则会将 next-key lock 优化为行锁;
- 唯一索引查询时,加锁范围为
(-INF, 20],并没有像主键那样做优化。此外还对范围内对应的主键加了行锁; - 普通索引查询时,加锁范围为
(-INF, 20],此外还对范围内对应的主键加了行锁; - for share 加锁区间相同;
总结
前面总结的加锁原则覆盖了绝大多数场景,此外还有行为:
- 加锁时,会先给表添加意向锁,IX 或 IS;
- for share 时,基于索引等值查询且存在覆盖索引情况下会优化加锁,取消对主键的加锁;
- 如果是多个范围,是分开加了多个锁,每个范围都有锁;
- 非主键唯一索引/普通索引除了在各自的索引字段加锁外,还会给范围内的主键加行锁;
- 非主键唯一索引上的范围查询会访问到不满足条件的第一个值为止,不会像主键那样进行优化;
- 非索引字段时,会对所有间隙加锁,开销较大;
- 加 next-key lock 实际上是分成了两步,先加间隙锁,再加行锁。间隙锁之间无冲突,这种情况下很容易造成死锁;
启发
- select for update/share 时,要尽量缩小查询范围,否则加锁较多时会导致性能下降;
- delete 时尽量加 limit,减少加锁范围,同时防止数据误删;
- 尽量不要在非索引字段做 for update/share 操作;
参考
- 《MySQL锁分类》
- 《MySQL锁总结》
- 《MySQL实战45讲》
- 《Innodb中的事务隔离级别和锁的关系》
- 《MySQL next-key lock 加锁范围是什么?》