基于KubeEdge实现中国移动10086客服云边协同平台
在华为开发者大会(Cloud)2021上,中国移动容器云平台架构师刘志磊发表了《基于KubeEdge实现中国移动10086客服云边协同平台》主题演讲,分享了中国移动使用边缘计算平台KubeEdge的落地实践过程。

演讲主要包含五方面的内容:
1)公司基础架构变更历程
2)云边协同方案具体选型
3)落地阶段问题以及解决方案介绍
4)KubeEdge社区贡献
5)总结&未来演进方向
公司基础架构变更历程
中国移动在线营销服务中心介绍
在线营销服务中心是中国移动通信集团二级专业机构,负责全网在线服务资源和线上渠道运营管理,拥有全球最大的呼叫中心 ,自有坐席4.4万,服务用户9亿,53个客服中心,是客服技术和客服业务的时代引领者。

云原生路线
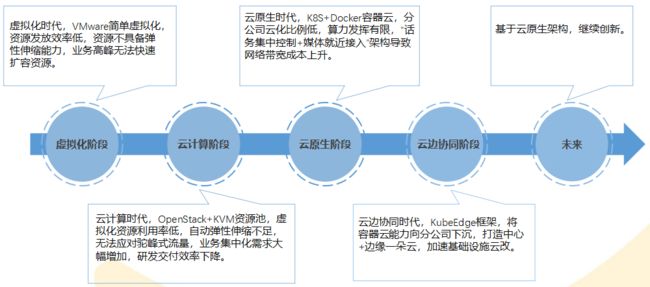
云边协同方案具体选型
需求
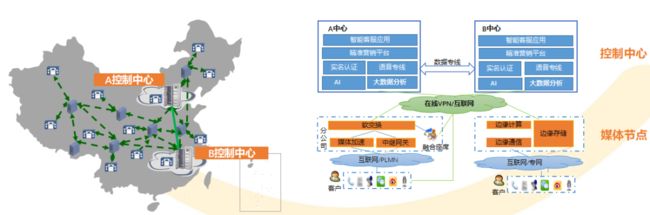
公司核心的融合客服系统具有“话务集中控制、媒体就近接入”的架构特性,需在各省分公司机房部署少量的服务器设备,所以全网服务器资源形成以双中心+31省分公司为接入点的星状拓扑结构。
另外为解决网络时延、音视频数据传输等瓶颈,满足营销服务业务高标准的用户体验要求,公司视频客服、全语音门户等多媒体业务系统向分公司下沉部署。分公司资源池暴露出以下问题:
问题1:业务支撑响应慢。分公司业务系统存在独立资源池的“烟囱式”问题,系统间的服务器资源无法共享,敏捷性较差,无法实现系统快速弹性扩缩容,影响营销服务业务的客户体验和系统稳定性;
问题2:业务运维效率低。分公司部署的业务模块均为人工手动维护,人工操作易出错、效率低、故障率高;
问题3:资源利用率低。目前分公司服务器以传统虚拟化技术为主要支撑形态,导致算力无法聚合,资源利用不充分,低效、冗余资源亟需整合利旧。
云边协同选型分析(一)
当时我们面临分公司的节点该如何管理的问题?边缘存在形态主要有两种:边缘集群、边缘节点。

边缘集群作为一个存在,意味着它有一个全量的管理资源,必然在生产上还要满足高性能高可用,因此在管理层面的一些资源其实对于物理机的开销也是比较大的。
相对来说,边缘节点的整体形态,可以复用云端管理能力,也就是k8s的master节点,同时它具备天然优势云边协同,可以再从云端直接控制到边缘的一些服务。在这种情况下,它面临着给这种平台的建设提出两点挑战:第一点是离线自治,离线自治是指在分公司云边端网或在弱网络环境下,让其能够完整的 Kubelet,或者边缘的组件能够正常拉起来我们的一些Pod,或者是在弱网环路下,整个主机的重启,必须确保业务Pod能够正常被拉起来。如此我们必须得在边缘节点具备离线自治的能力。同时如果是以边缘节点形式存在,最主要的核心因素是要全面兼容k8s API。
在综合分析和对比之后,因为我们在分公司边缘节点的服务器数量是有限的,如果采用全量集群的方式,会导致大量资源的浪费。因此我们决定以边缘节点为主导形式,然后去进行技术选型。
云边协同选型分析(二)
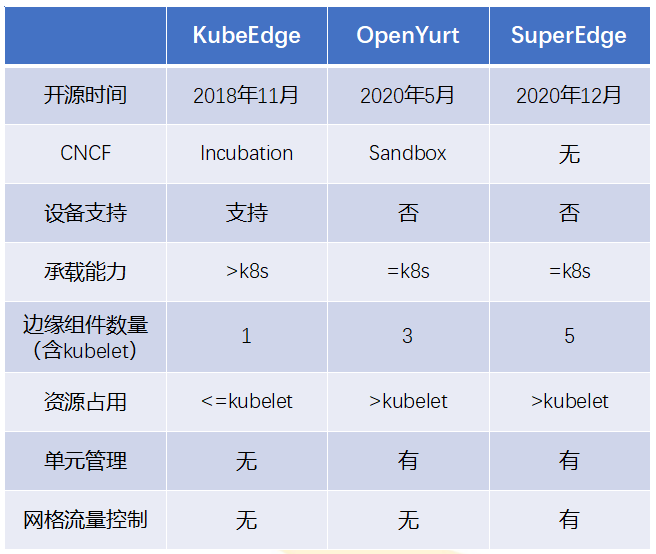
边缘节点形态下,当前主流的开源项目有:KubeEdge、OpenYurt和SuperEdge。我们主要关注3个方面:
1)技术成熟度
在CNCF基金会,项目的成熟度是可以通过它的级别表现的。KubeEdge已经是孵化级别,OpenYurt是沙箱级别的项目,而SuperEdge目前还未捐献给CNCF。
2)集群承载能力
KubeEdge已经做了层级的拆分,云端有CloudCore组件,边端有Edge core,它其实把原生的K8s listWatch机制进行了比较深入的定制,在云端请求收缩,可以放大在边缘节点上的数量。在我们的场景下会随着业务不断扩增,在边缘节点规模也会不断放大。因此在这个基础上,这两个特性其实是最吸引我们的。
另外还有一个特性边缘组件的数量,这些组件数量增加会带来整个管理或运维上复杂的情况。在边缘,将包含Kubelet的组件分析和对比之后,其实KubeEdge只有一个节点。OpenYurt会在边缘存在三个组件,但 SuperEdge是在五个组件左右。在这些基础上,我们整体是确定选型KubeEdge。
3)开源技术的活跃度
活跃度的话,可以用Github上的一些指标判断。比如star数、PR、Issue等,可以看到KubeEdge整体都是领先的,而且具备比较大的优势。

云边协同框架
基于轻量级容器编排框架KubeEdge的云边协同技术,打造“中心+边缘”的云边协同架构,实现以本部双中心服务器为中心节点,分公司为边缘节点的“计算拉伸方案”落地,将容器云计算能力下沉至边缘节点,实现统一的资源调度和纳管能力。

集中管理:通过统一容器管理平台进行集群的管理
边缘纳管:基于KubeEdge框架完成边缘节点的纳管
离线自治:EdgeCore基础上增加边缘代理,提升离线自治能力
CI/CD:复用管理平台CICD构建能力,提升服务发布效率
云边协同:构建数据协同、管理协同、运维协同的平台
落地阶段问题以及解决方案介绍
边缘网络
边缘节点网络可选模型较多,综合分析对比,确定落地网络方案,实现分公司内流量闭环。

边缘资源管理
常规的租户分区模式有资源配额限制,资源碎片化较为严重,不能有效的支撑容器云弹性伸缩的特性,不适合企业级大规模应用。
我们基于 k8s的污点技术,设计了资源池的一种模式如图所示,通过建立几个池子来部署业务资源,业务的pod就可以直接指定这个业务资源,和物理机绑定之后,就会消除上述问题。

资源池技术:
污点技术:通过污点标签技术,将集群划分多个资源池;
调度能力:通过多污点容忍方式,按污点优先级不同,定义资源池调度优先级。
资源池优势:
提升资源利用率:不需要租户分区保留冗余资源,减少资源碎片化;
资源应急支撑能力:急资源池集中冗余资源算力,可大幅增强紧急状态下的资源支撑能力。
边缘服务访问 | 能力下沉
KubeEdge框架自身主要提供容器云计算能力的下沉,EdgeMesh模块提供了简单的服务暴露能力,但不能友好支撑七层的负载均衡,因此决定将云端的能力下沉。
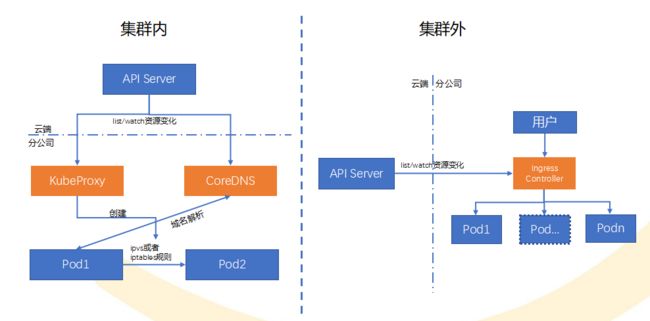
在集群内,它会存在两种流量,一种是东西向集群的流量,另外一个是集群对外的一个出口南北向流量。东西向流量我们决定将云端的KubeProxy整体以及CoreDNS进行下沉,这样在整体访问时,比如说有两个业务pod1和pod2的访问,pod1会通过每个分公司自己的专属域名后缀解析到自己的CoreDNS上面去。拿到Class IP后,再根据KubeProxy生成的iptables或ipvs策略,将流量在业务2上进行转发。
对于集群外的流量,我们是采用k8s内部的ingress部署定制后的ingress Controller完成完整的服务暴露。
边缘服务访问&服务分组分流
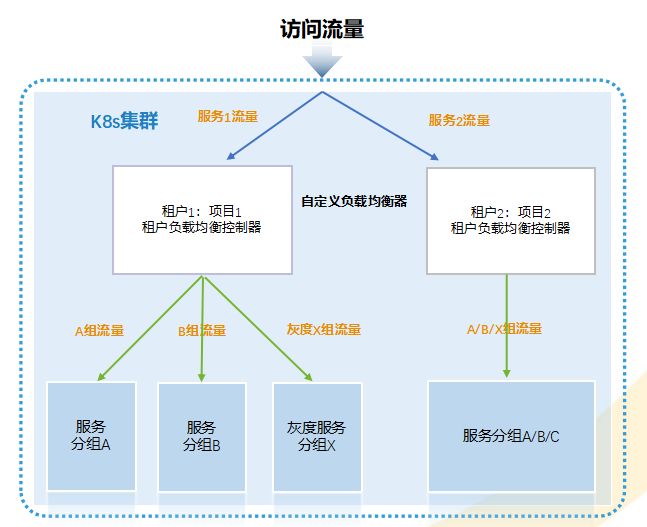
流量隔离:为应对超大规模流量接入,实现流量隔离,定义多IngressController并分配给一个或多个租户
分组部署:支持分组部署,满足应用系统的故障隔离,并缩小故障影响范围
灰度发布:为及早获得用户反馈,降低新应用升级的影响,将特定用户的请求分发到灰度服务,从而控制风险,并对产品特性的发布有一个循序渐进的迭代过程
无感知发布:采用主备服务模式,在发布过程中按照流量比例进行实例自动伸缩,从而达到业务无中断、用户无感知
接下来,为我们优化的优化内容:
分级镜像仓库
云边网络质量较差,采用统一的云端镜像仓库,镜像拉取可对网络带来较大的冲击,设计分级镜像仓库,降低镜像拉取对网络的冲击。

中心
主备双仓:主仓库对接OSS,备用仓库非高可用部署使用本地磁盘
高可用:主仓库通过keepalived +vip方式提供服务
边缘
独立部署:分公司部署独立镜像仓库,边缘节点就近拉取镜像
高可用:采用非高可用方式部署,但与中心仓库形成主备模式
管理
集中构建:利用管理平台CI能力实现镜像的集中构建
统一推送:分公司业务镜像实现对中心和边缘仓库的统一推送
联邦监控
采用Prometheus+AlertManager+Grafana的形式监控,打造“中心+边缘”联邦式监控。

联邦监控:分公司部署非高可用Prometheus,与云端Prometheus构建集群联邦
统一展示:数据集中汇总到总部Prometheus集群,统一对接Grafana面板进行数据展示
集中告警:数据在总部Prometheus进行分析,接入AlterManager进行数据告警
个性采集:边缘侧Prmetheus可根据业务监控需求,灵活对业务进行统一的监控数据采集
离线IP保持
原生CNI组件基本上依赖云端能力(APIServer/ETCD),离线时无法完成IP分配,建设IP快照能力,实现Pod IP在离线重启保持不变。
原有模式问题:IP分配由CNI进行控制,如何在离线情况下,Pod重启依旧保持原有IP?
解决方式:对CNI返回结果增加IP快照信息,在网络正常时,调用ipam组件进行IP分配;离线时使用本地磁盘
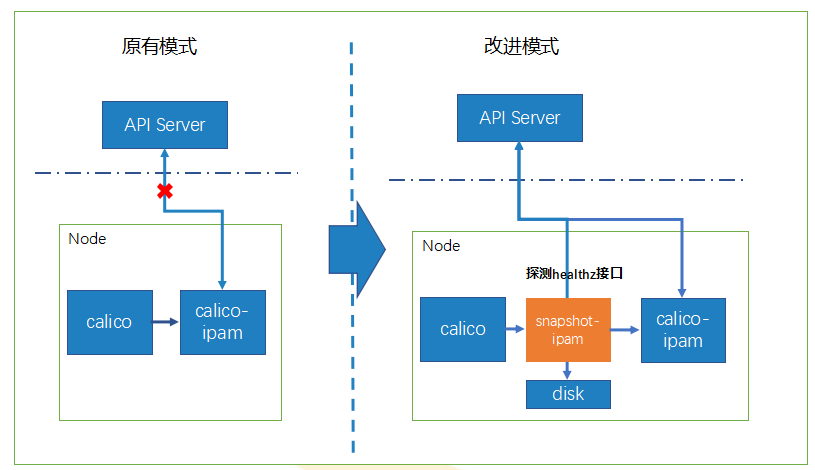
无侵入:对整体CNI的设计没有太多的侵入性的设计,可灵活对接其他CNI的实现
易部署:通过DaemonSet进行分发二进制即可
易使用:简单调整已有的CNI配置文件即可完成使用
边缘代理
大边缘场景下,下沉较多的云端能力,构建边缘代理,提升系统组件离线自治能力,全面建设节点级别离线自治能力。

问题:网络断链之后,系统组件如何提供离线自治能力?
解决方式:增加边缘代理模块,通过http代理方式,代理系统组件请求,拦截请求数据,缓存在本地,在离线时,使用缓存数据对系统组件提供服务
Tips:该模式无法解决relist/rewatch的问题,可以尝试使用KubeEdge 1.6版本的边缘list-watch功能
边缘故障隔离
采用两级隔离架构,实现自动监测、自动隔离等功能,全面覆盖集群关键组件及Node故障等场景,有效降低业务故障时间,保障业务持续稳定运行。
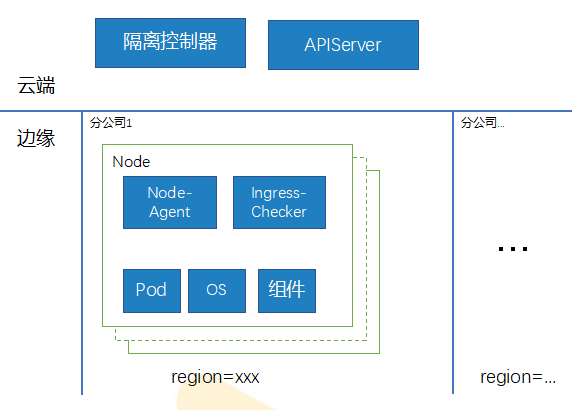
精确识别问题:细粒度组件运行状态监控,叠加故障场景
秒级故障诊断:Pod流量秒级切断,降低故障对业务影响
双向心跳探测:提升故障判断的准确率,避免node-agent启动引起问题
区域级别探测:精准识别单节点问题或者区域故障,避免边缘弱网环境下误判
KubeEdge社区贡献
主要包含4个方面的内容,部分是基于KubeEdge定制改造:
1)keadm debug工具套件
丰富边缘节点故障时排查手段,简化边缘问题排查方式。主要包含keadm debug get/check/diagnose/collect命令
已贡献给KubeEdge社区
2)CloudCore内存占用优化
优化CloudCore内部 informer、client的使用方式,精简LocationCache缓存数据,整体内存占用降低40%左右
已贡献给KubeEdge社区
3)节点默认标签和污点
边缘节点启动时默认增加指定的label和taint,简化边缘节点添加特定属性的操作流程
已贡献给KubeEdge社区
4)主机资源预留
边缘节点预留系统资源,允许设置节点最大Pod数,避免整体资源被Pod全部占用,提升边缘节点的稳定性
待社区审核
总结&未来演进方向
总结
社区出发:基于KubeEdge云边协同框架,提升了对边缘的纳管能力以及服务发布效率
深入业务:满足业务是第一优先级,提供合理的网络方案以及负载均衡方案
完善周边:构建分级镜像仓库,联邦监控等不断完善日常使用环节
场景驱动:细化故障场景,打造全面的故障隔离方案,缩小故障影响范围
回馈社区:从落地出发,完善KubeEdge能力,做社区贡献
未来演进方向
1)统一负载架构
在整个云边架构,我们完成了 pod也就是容器的整体资源计算能力下沉,但往往因为一些历史原因或一些系统业务比较老旧,它必须得在虚拟上运行而无法在容器里运行。如果单独为这些业务维护一个资源池,业务量比较庞大。在这个基础上,我们发现开源社区的Kubevirt,它是用k8s去管理虚拟机,未来我们计划基于K8s、KubeEdge、Kubevirt完成边缘虚拟机的管理演进。

2)边缘中间件服务纳管
在我们的场景里,边缘分公司是有若干个服务器,它有自己的业务、数据库、中间件,在云上可以通过operator这种模式进行很好的管理。但在边缘这种弱网络环境下,listwatch请求并非完全可靠。那在边缘怎么去完成中间件的服务纳管?目前我们也在讨论中,尽可能的去打造K8s+KubeEdge+中间件服务的解决方式。

附:KubeEdge社区贡献和技术交流地址

End
网站: https://kubeedge.io
Github地址: https://github.com/kubeedge/kubeedge
Slack地址: https://kubeedge.slack.com
邮件列表: https://groups.google.com/forum/#!forum/kubeedge
每周社区例会: https://zoom.us/j/4167237304
Twitter: https://twitter.com/KubeEdge
文档地址: https://docs.kubeedge.io/en/latest/
扫描下方二维码
观看演讲视频

来源:容器魔方,关注KubeEdge可以搜索关注一下容器魔方公众号!
感谢阅读,欢迎扩散传播!感谢!
边缘计算社区:促进边缘计算领域知识传播,中立,客观,如果您对边缘计算、5G、物联网、云原生等领域感兴趣请关注我们。对边缘计算、5G、工业互联网感兴趣的同学可以加微信7950420进边缘计算社区交流群!