LangChain案例-根据自己的知识库,构建聊天机器人
1.Document Loading文档加载器
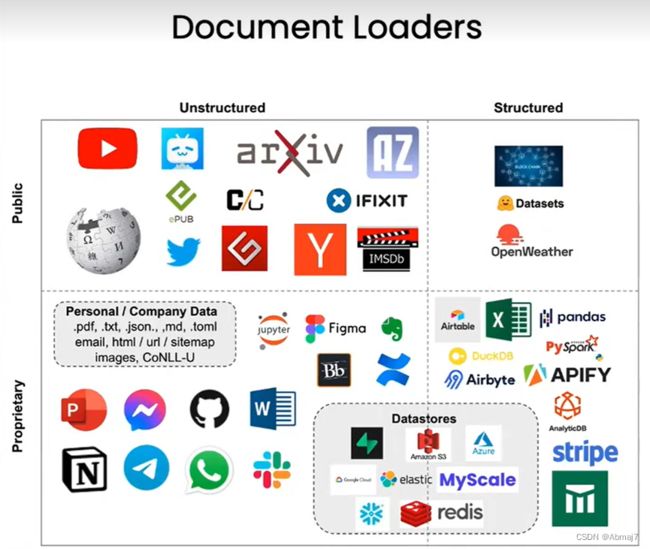
作用
把各种不同来源的数据转换成标准化格式
例如,把网站,数据库,youtube,或者PDF,html,JSON,Word,PPT等数据源,加载到标准的文档对象中
原理
以读Youtube为例:
最关键的部分是Youtube音频加载器(读取音频),和OpenAI Whisper解析器(用OpenAI的Whisper模型,将音频转成文字)
2.文档分割

分割的时刻
文档分割是发生在数据加载之后,但在向量存储之前
原理
正则匹配
类型
- 根据文本分割,比如10个字符为一组,或者根据”\n\n”做分割,等等
- 按照token做分割,比如说,10个token为一组,等等,但是注意:token != word也不等于字符
- markDown文本分割,按照markDown的章节去拆分
分割之后存储的内容
- 文本内容
- 元数据内容,比如当前页的文本内容是来自于哪里,是某个pdf,还是某个网站,或者当前页的内容是属于哪个章节,标题是什么
3.向量和embedding

作用
将这些分块放到索引中。这样,在回答有关的数据集问题时,可以轻松的检索到相关的分块。为了做到这一点,使用embedding和vector Store
Embedding

Embedding是一段文本在向量空间中的数字表示。
相似的文本在向量空间中,会有相似的向量值,然后我们可以通过找到相似的向量进而找到相似的文本片段
VectorStore向量存储
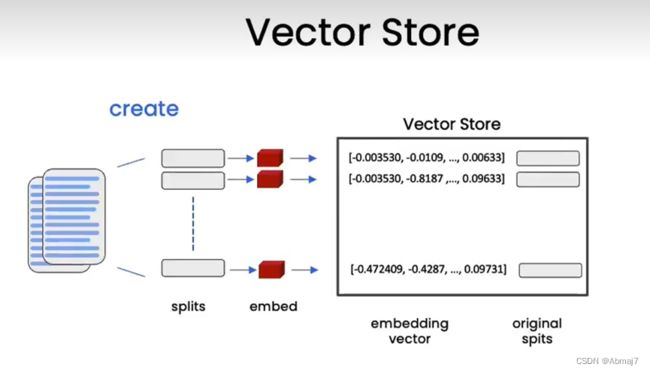
可以把向量存到数据库,然后我们可以生成问题的embedding,再与向量存储中的所有向量进行比较,然后选择最相似的前n个分块,最后,将这n个最相似的分块与原始的问题一起传给LLM,就可以得到答案
如何找到最相似的向量
通过点积来看的,点积越大,其相似度越高
4.检索
语义相似性搜索
API
直接用vectordb.similarity_search(question, k=xxx)就可以得到答案,k表示要求查询的相似向量的数量
可能出现的问题
提示词如果不够精确,可能会造成一些错误
比如:我给他一本书,并且提问,请告诉我第三章提到了关于线性回归的哪些知识?这里实际上有两个关键点,第三章和线性回归,但它有可能会忽略掉第三章这个关键点,可能会给我第二章里有关线性回归的内容,会出现错误
解决方式
①改提示词
②使用元数据过滤器,如果是markDown格式,可以指定它来自哪个章节,标题是哪个
最大边际相关性(MMR)搜索
背景
如果你总是选择与查询在嵌入空间中最相似的文档,你可能会错过多样的信息,所以有些时候,我们不仅要选最相似的文档,还要选,不那么相似的文档
比如我们询问一个关于全白蘑菇的问题
如果按照相似度去匹配的话,只能得到颜色,以及蘑菇基本的概念
但是,如果我们想知道蘑菇有没有毒,使用相似搜索是做不了的
为了解决这个问题,就可以用MMR来做
工作流

假如我们需要查3个结果,发送一个查询,一开始,会基于相似性搜索,初步查出一组结果(数量由fetch_k决定),接着在这些结果里,进一步筛选,此时不仅筛选语义相似性最高的文档,也会去选择那些多样性的文档(数量由k决定)
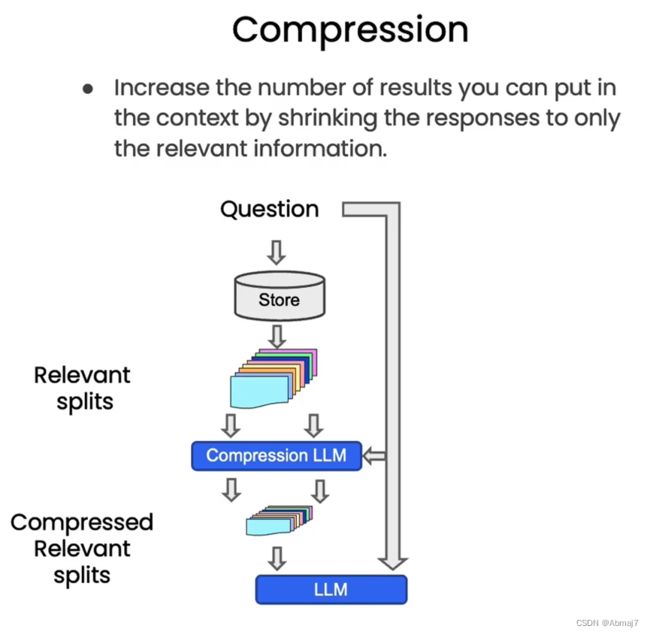
压缩检索
背景
在提问时,我们可能会得到存储的整个文档,即使只有前一两个句子是相关的,通过压缩,我们可以从中提取最相关的片段,然后只是将最相关的片段传递给最终的语言模型
压缩也是通过LLM来实现的,所以这个会花费更多的调用语言模型的成本,但是可以让模型在回复时更好的聚焦在那些最重要的内容上
工作流
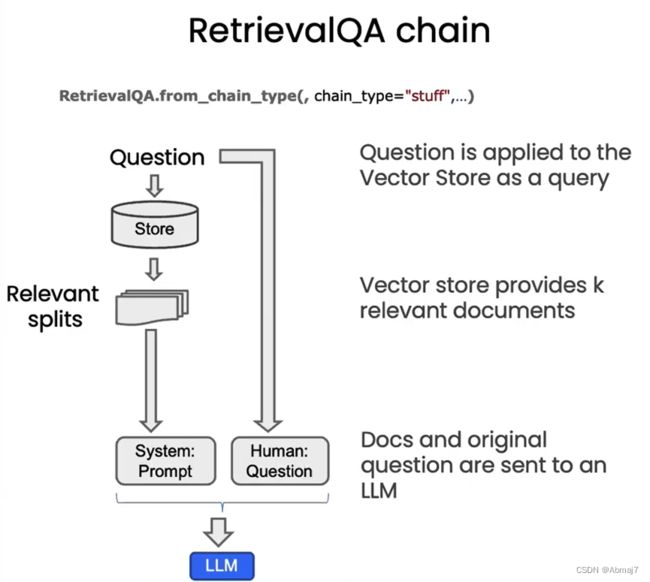
5.Question & Answer
作用
利用我们的文档,来做问答
工作流

进阶技巧
上面的方法,是把文档中所有与输入相似的部分,都塞到最后的prompt中,这种方法的局限性在于,如果文档太多,可能会触发token限制
MapReduce链
可以用MapReduce技术来做

在这种方式中,会将每个文档,单独发送到语言模型中,基于单个文档生成答案,然后将所有这些答案组合在一起,调用语言模型生成最终答案
缺点:需要调很多次语言模型,速度慢得多,由于是根据每个文档单独回答,结果可能更差
优点:可以处理任意多个文档
Refine链

比MapReduce链效果要更好,原因是,它是一次一次将信息组合起来的,它可以参考前面的回答去优化
6.加入聊天历史
让AI在回答问题的时候,会考虑到聊天历史
原理
把聊天历史也一起发给open ai的接口
风险与解决
有可能会触发token限制
解决方式:
使用摘要存储,langchain会把历史数据压缩到token限制内
参考文章&视频
宝玉xp的个人空间_哔哩哔哩_bilibili