shell脚本编写笔记
文章目录
- 1、shell基础
-
- 1.1 shell简介
- 1.2 bash基本功能
- 2、shell编程
-
- 2.1 条件判断与流程控制
- 2.1.1 条件判断语法结构
- 2.1.2 流程控制语句
- 2.2 循环语句
- 2.2.1 for循环语句
- 2.2.2 while循环语句
- 2.2.3 until循环
- 2.2.4 随机数
- 2.2.5 嵌套循环
- 2.2.6 循环总结
- 2.2.7 补充扩展expect
- 2.3 关于转义字符
- 2.4 函数
- 2.5 正则表达式
- 2.5.1 常用正则练习
- 2.6 扩展补充数组
- 2.6.1 数组定义
- 2.6.2 简单案例
1、shell基础
1.1 shell简介
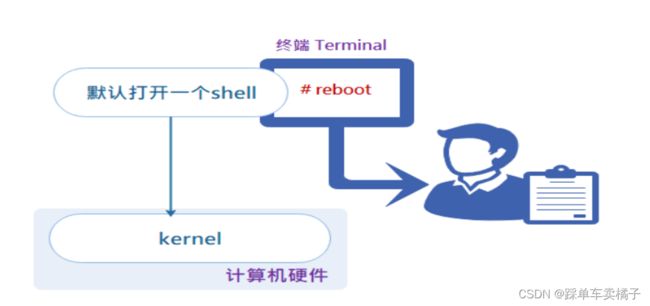
shell介于内核与用户之间,负责命令的解释,就是人机交互的一个桥梁。shell脚本就是将需要执行的命令保存到文本中,按照顺序执行。
若干命令 + 脚本的基本格式 + 脚本特定语法 + 思想= shell脚本

shell与终端的关系:
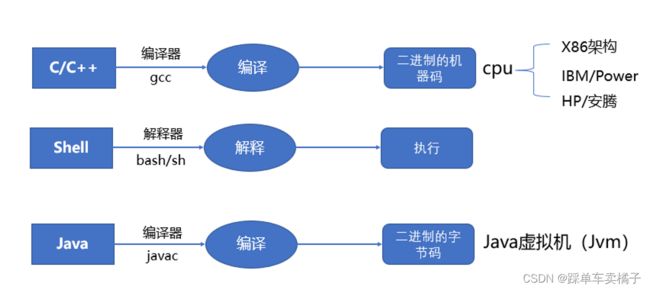
补充:编程语言的分类
• 编译型语言:
程序在执行之前需要一个专门的编译过程,把程序编译成为机器语言文件,运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如C、C++
• 解释型语言:
程序不需要编译,程序在运行时由解释器翻译成机器语言,每执行一次都要翻译一次。因此效率比较低。比如Python/JavaScript/ Perl /ruby/Shell等都是解释型语言。
1.2 bash基本功能
1、历史命令:history
history[选项][历史命令保存文件]
-c 清空历史命令
-w 把缓存中的历史命令写入历史命令保存文件
~/.bash_history
配置文件/etc/profile
2、命令别名
alias 别名=‘原命令’ #设定命令别名
unalias 别名 #删除别名
alias #查询命令别名
配置文件 /root/.bashrc
3、标准输入输出
| 设备 | 设备文件名 | 文件描述符 | 类型 |
|---|---|---|---|
| 键盘 | /dev/stdin | 0 | 标准输入 |
| 显示器 | /dev/stdout | 1 | 标准输出 |
| 显示器 | /dev/stderr | 2 | 标准错误输出 |
4、输出重定向
| 类型 | 符号 | 作用 |
|---|---|---|
| 标准输出重定向 | 命令 > 文件 | 以覆盖的方式,把命令的正确输出输出到指定的文件或设备当中。 |
| 命令 >> 文件 | 以追加的方式,把命令的正确输出输出到指定的文件或设备当中。 | |
| 标准错误输出重定向 | 错误命令 2> 文件 | 以覆盖的方式,把命令的错误输出输出到指定的文件或设备当中。 |
| 命令 2>> 文件 | 错误命令 2> 文件 | |
| 正确输出和错误输出同时保存 | 命令 > 文件 2>&1 | 以覆盖的方式,把正确输出和错误输出都保存到同一个文件当中。 |
| 命令 >> 文件 2>&1 | 以追加的方式,把正确输出和错误输出都保存到同一个文件当中。 | |
| 命令&>文件 | 以覆盖的方式,把正确输出和错误输出都保存到同一个文件当中。 | |
| 命令 &>>文件 | 以追加的方式,把正确输出和错误输出都保存到同一个文件当中。 | |
| 命令>>文件1 2 >>文件2 | 把正确的输出追加到文件1中,把错误的输出追加到文件2中 |
5、输出重定向
wc [选项] [文件名]
-c 统计字节数
-w 统计单词数
-l 统计行数
命令<文件 把文件作为命令的输入
命令<<标识符 把标识符之间内容作为命令的输入
6、多命令顺序执行
| 多命令执行符 | 格式 | 作用 |
|---|---|---|
| ; | 命令1;命令2 | 多个命令顺序执行,命令之间没有任何逻辑联系 |
| && | 命令1&&命令2 | 逻辑与;命令1正确执行,则命令2才会执行;当命令1执行不正确,则命令2不会执行 |
| || | 命令1||命令2 | 逻辑或;当命令1执行不正确,则命令2才会执行;当命令1正确执行,则命令2不会执行 |
7、管道符 |
命令1|命令2 #命令1的正确输出作为命令2的操作对象
8、grep命令:行过滤工具,用于根据关键字进行行过滤
语法:
grep [选项] '关键字' 文件名
常见选项:
OPTIONS:
-i: 不区分大小写
-v: 查找不包含指定内容的行,反向选择
-w: 按单词搜索
-o: 打印匹配关键字
-c: 统计匹配到的行数
-n: 显示行号
-r: 逐层遍历目录查找
-A: 显示匹配行及后面多少行
-B: 显示匹配行及前面多少行
-C: 显示匹配行前后多少行
-l:只列出匹配的文件名
-L:列出不匹配的文件名
-e: 使用正则匹配
-E:使用扩展正则匹配
^key:以关键字开头
key$:以关键字结尾
^$:匹配空行
--color=auto :可以将找到的关键词部分加上颜色的显示
临时设置:
# alias grep='grep --color=auto' //只针对当前终端和当前用户生效
永久设置:
1)全局(针对所有用户生效)
vim /etc/bashrc
alias grep='grep --color=auto'
source /etc/bashrc
2)局部(针对具体的某个用户)
vim ~/.bashrc
alias grep='grep --color=auto'
source ~/.bashrc
pgrep命令:以名称为依据从运行进程队列中查找进程,并显示查找的进程id
-o:仅显示找到的最小(起始)进程号;
-n:仅显示找到的最大(结束)进程号;
-l:显示进程名称;
-P:指定父进程号;pgrep -p 4764 查看父进程下的子进程id
-g:指定进程组;
-t:指定开启进程的终端;
-u:指定进程的有效用户ID。
9、cut工具:列截取工具,用于列的截取
cut 选项 文件名
-c: 以字符为单位进行分割,截取
-d: 自定义分隔符,默认为制表符\t
-f: 与-d一起使用,指定截取哪个区域
10、sort工具:用于排序;它将文件的每一行作为一个单位,从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
-u :去除重复行
-r :降序排列,默认是升序
-o : 将排序结果输出到文件中,类似重定向符号>
-n :以数字排序,默认是按字符排序
-t :分隔符
-k :第N列
-b :忽略前导空格。
-R :随机排序,每次运行的结果均不同
11、uniq工具:用于去除连续的重复行
常见选项:
-i: 忽略大小写
-c: 统计重复行次数
-d:只显示重复行
12、tee工具:是从标准输入读取并写入到标准输出和文件,即:双向覆盖重定向(屏幕输出|文本输入)
-a 双向追加重定向
13、diff工具:用于逐行比较文件的不同
diff [选项] 文件1 文件2
14、paste:用于合并文件航
tr:用于字符转换,替换和删除;主要用于删除文件中控制字符或进行字符转换
15、通配符
| 通配符 | 作用 |
|---|---|
| ? | 匹配一个任意字符 |
| * | 匹配0个或任意多个任意字符,也就是可以匹配任何内容 |
| [] | 匹配中括号中任意一个字符。例如:[abc]代表一定匹配一个字符,或者是a,或者是b,或者是c。 |
| [-] | 匹配中括号中任意一个字符,-代表一个范围。例如:[a-z]代表匹配一个小写字母。 |
| [^] | 逻辑非,表示匹配不是中括号内的一个字符。例如:[^0-9]代表匹配一个不是数字的字符。 |
16、bash中其他特殊符号
| 符号 | 作用 |
|---|---|
| ’ ’ | 单引号。在单引号中所有的特殊符号,如 $ 和 ` (反引号)都没有特殊含义。 |
| " " | 双引号。在双引号中特殊符号都没有特殊含义,但是$ ` 和 \是例外,拥有“调用变量的值”、“引用命令”和“转义符”的特殊含义。 |
| ` ` | 反引号。反引号括起来的内容是系统命令,在bash中会先执行它。和$()作用一样。 |
| $() | 和反引号作用一样,用来引用系统命令。 |
| # | 在shell脚本中,#开头的行代表注释。 |
| $ | 用于调用变量的值,如需要调用变量name的值时,需要用$name的方式得到变量的值。 |
| \ | 转义符,跟在\之后的特殊符号将失去特殊含义,变为普通字符。如\将输出$符号,而不当做是变量引用。 |
2、shell编程
2.1 条件判断与流程控制
2.1.1 条件判断语法结构
1、条件判断语法格式
格式1:test条件表达式
格式2:[ 条件表达式 ]
格式3:[[ 条件表达式 ]]
注意:[ xxx ] 中括号两边必须要有空格
2、条件判断相关参数
(1)判断文件类型
| 判断参数 | 含义 |
|---|---|
| -e | 判断文件是否存在(任何类型文件) |
| -f | 判断文件是否存在并且是一个普通文件 |
| -d | 判断文件是否存在并且是一个目录 |
| -L | 判断文件是否存在并且是一个软链接文件 |
| -b | 判断文件是否存在并且是一个块设备文件 |
| -S | 判断文件是否存在并且是一个套接字文件 |
| -c | 判断文件是否存在并且是一个字符设备文件 |
| -p | 判断文件是否存在并且是一个命名管道文件) |
| -s | 判断文件是否存在并且是一个非空文件(有内容) |
(2)判断文件权限
| 判断参数 | 含义 |
|---|---|
| -r | 当前用户对其是否可读 |
| -w | 当前用户对其是否可写 |
| -x | 当前用户对其是否可执行 |
| -u | 是否有suid,高级权限冒险位 |
| -g | 是否sgid,高级权限强制位 |
| -k | 是否有t位,高级权限粘滞位 |
(3)判断文件新旧
说明:这里的新旧指的是文件的修改时间。
| 判断参数 | 含义 |
|---|---|
| file1 -nt file2 | 比较file1是否比file2新 |
| file1 -ot file2 | 比较file1是否比file2旧 |
| file1 -ef file2 | 比较是否为同一个文件,或者用于判断硬链接,是否指向同一个inode |
(4)判断整数
| 判断参数 | 含义 |
|---|---|
| -eq | 相等 |
| -ne | 不等 |
| -gt | 大于 |
| -lt | 小于 |
| -ge | 大于等于 |
| -le | 小于等于 |
(5)判断字符串
| 判断参数 | 含义 |
|---|---|
| -z | 判断是否为空字符串,字符串长度为0则成立 |
| -n | 判断是否为非空字符串,字符串长度不为0则成立 |
| string 1 = string 2 | 判断字符串是否相等 |
| string 1 != string 2 | 判断字符串是否不相等 |
(6)多重条件判断
| 判断符号 | 含义 | 举例 |
|---|---|---|
| -a和&& | 逻辑与 | [ 1 -eq 1 -a 1 -ne 0 ] [1 -eq 1] &&[1 -ne 0] |
| -o和\ | 逻辑或 | [1 -eq 1 -a 1 -ne 0 ] [1 -eq 1] \ [1 -ne 0] |
2.1.2 流程控制语句
1、基本语法结构
(1) if结构
if [ condition ];then
command
command
fi
------------------------------
if test 条件;then
命令
fi
------------------------------
if [[ 条件 ]];then
命令
fi
------------------------------
[ 条件 ] && command
<2> if...else结构
if [ condition ];then
command1
else
command2
fi
------------------------------------
[ 条件 ] && command1 || command2
<3> if...elif...else结构
if [ condition1 ];then
command1 结束
elif [ condition2 ];then
command2 结束
else
command3
fi
注释:如果条件1满足,执行命令1后结束;如果条件1不满足,再看条件2,如果条件2满足执行命令2后结束;如果条件1和条件2都不满足执行命令3结束。
(2)嵌套结构
if [ condition1 ];then
command1
if [ condition2 ];then
command2
fi
else
if [ condition3 ];then
command3
elif [ condition4 ];then
command4
else
command5
fi
fi
注释:如果条件1满足,执行命令1;如果条件2也满足执行命令2,如果不满足就只执行命令1结束;如果条件1不满足,不看条件2;直接看条件3,如果条件3满足执行命令3;如果不满足则看条件4,如果条件4满足执行命令4;否则执行命令5。
例:判断两台服务器是否能ping通

2.2 循环语句
2.2.1 for循环语句
1、for循环语法结构
(1)列表循环
用于将一组命令执行已知的次数
for variable in {list}
do
command
command
…
done
或者
for variable in a b c
do
command
command
done
(2)不带列表循环
由用户指定参数和参数的个数
例:
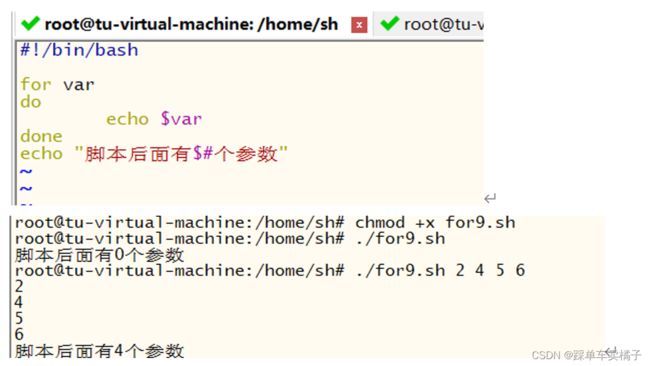
(3)类C风格的for循环
for(( expr1;expr2;expr3 ))
do
command
command
…
done
expr1:定义变量并赋初值
expr2:决定是否进行循环(条件)
expr3:决定循环变量如何改变,决定循环什么时候退出
2、循环控制语句
循环体:do…done之间的内容
continue:继续;表示循环体内下面的代码不执行,重新开始下一次循环
break:打断;马上停止执行本次循环,执行循环体后面的代码
exit:表示直接跳出程序
例:计算1-100之间所有质数之和

3、总结
• FOR循环语法结构
• FOR循环可以结合条件判断和流程控制语句
- do …done 循环体
- 循环体里可以是命令集合,再加上条件判断以及流程控制
• 控制循环语句
- continue 继续,跳过本次循环,继续下一次循环
- break 打断,跳出循环,执行循环体外的代码
- exit 退出,直接退出程序
2.2.2 while循环语句
特点:条件为真就进入循环;条件为假就退出循环
1、while循环语法结构
while 表达式
do
command...
done
while [ 1 -eq 1 ] 或者 (( 1 > 2 ))
do
command
command
...
done
例:计算1-50的偶数和
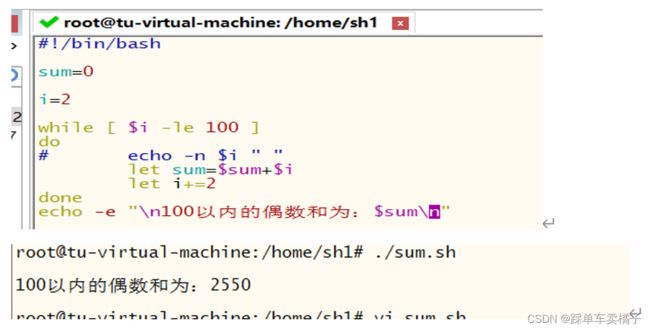
2.2.3 until循环
特点:条件为假就进入循环;条件为真就退出循环
until expression [ 1 -eq 1 ] (( 1 >= 1 ))
do
command
command
...
done
2.2.4 随机数
系统变量:RANDOM,默认会产生0~32767的随机整数
按照自己要求打印随机数
产生0~1之间的随机数
echo $[$RANDOM%2]
产生0~2之间的随机数
echo $[$RANDOM%3]
……
产生0~100内的随机数
echo $[$RANDOM%101]
产生50-100之内的随机数
echo $[$RANDOM%51+50]
产生三位数的随机数(100-999)
echo $[$RANDOM%900+100]
echo $[$RANDOM%a+b] b-(a+b-1)
echo $[$RANDOM%c] 0-(c-1)
2.2.5 嵌套循环
关键字:大圈套小圈
时钟:分针与秒针,秒针转⼀圈(60格),分针转1格。循环嵌套就是外层循环⼀次,内层循环⼀轮。
1、一个循环体内又包含另一个完整的循环结构,称为循环的嵌套。
2、每次外部循环都会触发内部循环,直至内部循环完成,才接着执行下一次的外部循环。
3、for循环、while循环和until循环可以相互嵌套。
2.2.6 循环总结
1、变量定义
(1)变量名=变量值
echo $变量名
echo ${变量名}
(2)read -p “提示用户信息:”变量名
(3)declare -I /-x/-r 变量名=变量值
2、流程控制语句
if [ 条件判断 ];then
command
fi
----------------------------
if [ 条件判断 ];then
command
else
command
fi
-------------------------------
if [ 条件判断1 ];then
command1
elif [ 条件判断2 ];then
command2
else
command3
fi
3、循环语句
目的:某个动作重复去做,用到循环
for while until
4、影响shell程序的内置命令
exit 退出整个程序
break 结束当前循环,或跳出本层循环
continue 忽略本次循环剩余的代码,直接进行下一次循环
shift 使位置参数向左移动,默认移动1位,可以使用shift 2
:
true
false
2.2.7 补充扩展expect
expect 自动应答tcl语言,是一个免费的编程工具,用来实现自动的交互式任务,而无需人为干预。说白了expect就是一套用来实现自动交互功能的软件需要自行安装
1、expect常用命令
spawn:用来启动新的进程,spawn后的expect和send命令都是和使用spawn启动的新进程进行交互。
expect:通常用来等待一个进程的反馈,我们根据进程的反馈,再使用send命令发送对应的交互命令。
send:接收一个字符串参数,并将该参数发送到进程。
interact:用的其实不是很多,一般情况下使用spawn、expect和send和命令就可以很好的完成我们的任务;但在一些特殊场合下还是需要使用interact命令的,interact命令主要用于退出自动化,进入人工交互。比如我们使用spawn、send和expect命令完成了ftp登陆主机,执行下载文件任务,但是我们希望在文件下载结束以后,仍然可以停留在ftp命令行状态,以便手动的执行后续命令,此时使用interact命令就可以很好的完成这个任务。
2、expect自动应答步骤
第一步: 运行一个程序或命令=> spawn 命令信息
第二步: 识别产生信息关键字=> expect 捕获关键字 {send 应答信息}
第三步: 根据识别关键做处理=> send 应答信息
3、举例
脚本远程登录服务器

把interact去掉,换成expect “#”
send “xxxxxxxxxxxx\r”
send ……
expect eof
就可以实现脚本自动远程登录并完成各种你想要的操作。
另外很多时候我们使用expect的场景都是结合bash在使用,expect只是作为bash脚本的部分调用,因为bash里我们还需要执行其他复杂的功能,我们将expect脚本嵌入ecpect <<-END之间即可,expect eof是指等待脚本执行结束。
#!/bin/bash
#判断公钥是否存在
[ ! -f /home/yunwei/.ssh/id_rsa ] && ssh-keygen -P '' -f ~/.ssh/id_rsa
#循环判断主机是否ping通,如果ping通推送公钥
tr ':' ' ' < /shell04/ip.txt|while read ip pass
do
{
ping -c1 $ip &>/dev/null
if [ $? -eq 0 ];then
echo $ip >> ~/ip_up.txt
/usr/bin/expect <<-END &>/dev/null
spawn ssh-copy-id root@$ip
expect {
"yes/no" { send "yes\r";exp_continue }
"password:" { send "$pass\r" }
}
expect eof
END
fi
}&
done
wait
echo "公钥已经推送完毕,正在测试...."
#测试验证
remote_ip=`tail -1 ~/ip_up.txt`
ssh root@$remote_ip hostname &>/dev/null
test $? -eq 0 && echo "公钥成功推送完毕"
补充:visudo命令可以添加普通用户使用sudo获取一些执行权限

2.3 关于转义字符
1、定义
转义字符(Escape character),所有的ASCII码都可以用“\”加数字(一般是8进制数字)来表示。而C中定义了一些字母前加""来表示常见的那些不能显示的ASCII字符,如\0,\t,\n等,就称为转义字符,因为后面的字符,都不是它本来的ASCII字符意思了。
2、字符表
所有的转义字符和所对应的意义:
| 转义字符 | 意义 | ASCII码值(十进制) |
|---|---|---|
| \a | 响铃(BEL) | 007 |
| \b | 退格(BS),将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF),将当前位置移到下一行开头 | 010 |
| \r | 回车(CR),将当前位置移到本行开头 | 013 |
| \t | 水平指表(HT)(跳到下一个TAB位置) | 009 |
| \v | 垂直制表(VT) | 011 |
| \\ | 代表一个反斜杠字符\ | 092 |
| \’ | 代表一个单引号(撇号)字符 | 039 |
| \" | 代表一个双引号字符 | 034 |
| \? | 代表一个问号 | 063 |
| \0 | 空字符(NUL) | 000 |
| \ddd | 1到3位八进制数所代表的任意字符 | 三位八进制 |
| \xhh | 十六进制所代表的任意字符 | 十六进制 |
注意:
(1)区分,斜杠:“/“与反斜杠:”\”,此处不可互换
(2)\xhh十六进制转义不限制字符个数‘\x000000000000F’==’\xF’
2.3 case语句+函数+正则
2.3.1 case语句
(1)case语句为多重匹配语句
(2)如果匹配成功,执行相匹配的命令
1、语法结构
说明:pattern表示需要匹配的模式
case var in 定义变量;var代表是变量名
pattern 1) 模式1;用 | 分割多个模式,相当于or
command1 需要执行的语句
;; 两个分号代表命令结束
pattern 2)
command2
;;
pattern 3)
command3
;;
*) default,不满足以上模式,默认执行*)下面的语句
command4
;;
esac esac表示case语句结束
2、举例:脚本传不同值做不同事
具体需求:当给程序传入start、stop、restart三个不同参数时分别执行相应命令

2.4 函数
1、函数定义
• shell中允许将一组命令集合或语句形成一段可用代码,这些代码块称为shell函数
• 给这段代码起个名字称为函数名,后续可以直接调用该段代码的功能
2、定义函数
方法1:
函数名( )
{
函数体(一堆命令的集合,来实现某个功能)
}
方法2:
function 函数名( )
{
函数体(一堆命令的集合,来实现某个功能)
}
函数中return说明:
(1)return可以结束一个函数。类似于循环控制语句break(结束当前循环,执行循环体后面的代码)。
(2)return默认返回函数中最后一个命令状态值,也可以给定参数值,范围是0-256之间。
(3)如果没有return命令,函数将返回最后一个指令的退出状态值。
3、调用函数
(1)当前命令行调用
source xxx.sh
./xxx.sh
(2)定义到用户的环境变量中
vi ~/.bashrc
当用户打开bash的时候会读取该文件
(3)脚本中调用
2.5 正则表达式
1、定义
正则表达式(Regular Expression、regex或regexp,缩写为RE),也译为正规表示法、常规表示法,是一种字符模式,用于在查找过程中匹配指定的字符。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。
正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。
支持正则表达式的程序如:locate |find| vim| grep| sed |awk
2、用途
(1)匹配邮箱、匹配身份证号码、手机号、银行卡号等
(2)匹配某些特定字符串,做特定处理等等
3、正则当中名词解释
元字符:指那些在正则表达式中具有特殊意义的专用字符,如:点(.) 星() 问号(?)等。
前导字符:位于元字符前面的字符。abc aooo.
4、第一类正则表达式
(1)正则中普通常用的元字符
| 元字符 | 功能 | 备注 |
|---|---|---|
| . | 匹配除了换行符以外的任意单个字符 | |
| * | 前导字符出现0次或连续多次 | |
| .* | 任意长度字符 | ab.* |
| ^ | 行首(以…开头) | ^root |
| $ | 行尾(以…结尾) | bash$ |
| ^$ | 空行 | |
| [] | 匹配括号里任意单个字符或一组单个字符 | [abc] |
| 匹配不包含括号里任一单个字符或一组单个字符 | abc | |
| ^[] | 匹配以括号里任意单个字符或一组单个字符开头 | ^[abc] |
| ^ | 匹配不以括号里任意单个字符或一组单个字符开头 | ^[^abc] |
(2)正则中其他常用元字符
| 元字符 | 功能 | 备注 |
|---|---|---|
| \< | 取单词的头 | |
| \> | 取单词的尾 | |
| \< \> | 精确匹配 | |
| \{n\} | 匹配前导字符连续出现n次 | |
| \{n,\} | 匹配前导字符至少出现n次 | |
| \{n,m\} | 匹配前导字符出现n次与m次之间 | |
| \{\} | 保存被匹配的字符 | |
| \d | 匹配数字(grep -P) | [0-9] |
| \w | 匹配字母数字下划线(grep -P) | [a-zA-Z0-9_] |
| \s | 匹配空格、制表符、换页符(grep -P) | [\t\r\n] |
(3)扩展类正则常用元字符
使用grep 加-E或者使用egrep
使用sed,必须加-r
| 扩展元字符 | 功能 | 备注 |
|---|---|---|
| + | 匹配一个或多个前导字符 | bo+匹配boo、bo |
| ? | 匹配零个或一个前导字符 | bo?匹配b、bo |
| \ | 或a\b匹配a或b | |
| () | 组字符(看成整体)(my\your)self:表示匹配mysql或匹配yourself | |
| {n} | 前导字符重复n次 | |
| {n,} | 前导字符重复至少n次 | |
| {n,m} | 前导字符重复n到m次 |
5、第二类正则
| 表达式 | 功能 | 示例 |
|---|---|---|
| [:alnum:] | 字母与数字字符 | [[:alnum:]]+ |
| [:alpha:] | 字母字符(包括大小写字母) | [[:alpha:]]{4} |
| [:blank:] | 空格与制表符 | [[:blank:]]* |
| [:digit:] | 数字 | [[:digit:]]? |
| [:lower:] | 小写字母 | [[:lower:]]{4,} |
| [:upper:] | 大写字母 | [[:upper:]]+ |
| [:punct:] | 标点符号 | [[:punct:]] |
| [:space:] | 包括换行符,回车等在内的所有空白 | [[:space:]]+ |
6、总结
(1)我要找什么?
找数字 [0-9]
找字母 [a-zA-Z]
找标点符号 [[:punct:]]
(2)我要如何找?
以什么为首 ^key
以什么结尾 key$
包含什么或不包含什么 [abc] ^[abc] [^abc] ^[^abc]
(3)我要找多少呀?
找前导字符出现0次或连续多次 ab*
找任意单个(一次)字符 ab.
找任意字符 ab.*
找前导字符连续出现几次 {n} {n,m} {n,}
找前导字符出现1次或多次 go+
找前到字符出现0次或1次 go?
补充:正则表达式匹配IP地址
[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}
([0-9]{1,3}\.){3}[0-9]{1,3}
\d+\.\d+\.\d+\.\d+
(\d+\.){3}\d+
2.5.1 常用正则练习
1、查找不以大写字母开头的行(三种写法)。
grep '^[^A-Z]' 2.txt
grep -v '^[A-Z]' 2.txt
grep '^[^[:upper:]]' 2.txt
2、查找有数字的行(两种写法)
grep '[0-9]' 2.txt
grep -P '\d' 2.txt
3、查找一个数字和一个字母连起来的
grep -E '[0-9][a-zA-Z]|[a-zA-Z][0-9]' 2.txt
4、查找不以r开头的行
grep -v '^r' 2.txt
grep '^[^r]' 2.txt
5、查找以数字开头的
grep '^[0-9]' 2.txt
6、查找以大写字母开头的
grep '^[A-Z]' 2.txt
7、查找以小写字母开头的
grep '^[a-z]' 2.txt
8、查找以点结束的
grep '\.$' 2.txt
9、去掉空行
grep -v '^$' 2.txt
10、查找完全匹配abc的行
grep '\' 2.txt
11、查找A后有三个数字的行
grep -E 'A[0-9]{3}' 2.txt 扩展正则
grep 'A[0-9]\{3\}' 2.txt
12、统计root在/etc/passwd里出现了几次
grep -o 'root' 1.txt |wc -l
13、用正则表达式找出自己的IP地址、广播地址、子网掩码
ifconfig eth0|grep Bcast|grep -o '[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}'
ifconfig eth0|grep Bcast| grep -E -o '([0-9]{1,3}.){3}[0-9]{1,3}'
ifconfig eth0|grep Bcast| grep -P -o '\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}'
ifconfig eth0|grep Bcast| grep -P -o '(\d{1,3}.){3}\d{1,3}'
ifconfig eth0|grep Bcast| grep -P -o '(\d+\.){3}\d+'
# egrep --color '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' /etc/sysconfig/network-scripts/ifcfg-eth0
IPADDR=10.1.1.1
NETMASK=255.255.255.0
GATEWAY=10.1.1.254
# egrep --color '[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}' /etc/sysconfig/network-scripts/ifcfg-eth0
IPADDR=10.1.1.1
NETMASK=255.255.255.0
GATEWAY=10.1.1.254
14、找出文件中的ip地址并且打印替换成172.16.2.254
grep -o -E '([0-9]{1,3}\.){3}[0-9]{1,3}' 1.txt |sed -n 's/192.168.0.\(254\)/172.16.2.\1/p'
15、找出文件中的ip地址
grep -o -E '([0-9]{1,3}\.){3}[0-9]{1,3}' 1.txt
16、找出全部是数字的行
grep -E '^[0-9]+$' test
17、找出邮箱地址
grep -E '^[0-9]+@[a-z0-9]+\.[a-z]+$'
grep --help:
匹配模式选择:
Regexp selection and interpretation:
-E, --extended-regexp 扩展正则
-G, --basic-regexp 基本正则
-P, --perl-regexp 调用perl的正则
-e, --regexp=PATTERN use PATTERN for matching
-f, --file=FILE obtain PATTERN from FILE
-i, --ignore-case 忽略大小写
-w, --word-regexp 匹配整个单词
加了-P参数,在使用了扩展正则的情况下可以不用加-E参数,如:ifconfig eth0 | grep -o -P '(\d{1,3}\.){3}\d{1,3}'
2.6 扩展补充数组
2.6.1 数组定义
1、数组分类
(1)普通数组:只能使用整数作为数组索引(元素的下标)
(2)关联数组:可以使用字符串作为数组索引(元素的下标)
2、普通数组定义
(1)一次赋予一个值
数组名[索引下标]=值
array[0]=v1
array[1]=v2
......
array[3]=v3
(2)一次赋多个值
数组名=(值1 值2 值3 ...)
array=(var1 var2 var3 var4)
(3)数组的读取
${数组名}[元素下标]
echo ${array[0]} 获取数组里第一个元素
echo ${array[*]} 获取数组里的所有元素
echo ${#array[*]} 获取数组里所有元素个数
echo ${!array[@]} 获取数组元素的索引下标
echo ${array[@]:1:2} 访问指定的元素;1代表从下标为1的元素开始获取;2代表获取后面几个元素
查看普通数组信息:
declare -a
3、关联数组的定义
(1)首先声明关联数组
declare -A asso_array1
declare -A asso_array2
declare -A asso_array3
(2)数组赋值
①一次赋一个值
数组名[索引|or下标]=变量名
asso_array1[linux]=one
asso_array1[java]=two
asso_array1[php]=three
②一次赋多个值
asso_array2=([name1]=harry [name2]=jack [name3]=mary [name4]=”Miss Hou”)
④ 查看关联数组
declare -A
2.6.2 简单案例
写一个脚本,统计web服务的不同连接状态个数
1、找出查看网站连接状态的命令 ss -natp|grep :80
2、如何统计不同的状态 循环去统计,需要计算
#!/bin/bash
#count_http_80_state
#统计每个状态的个数
declare -A array1
states=`ss -ant|grep 80|cut -d' ' -f1`
for i in $states
do
let array1[$i]++
done
#通过遍历数组里的索引和元素打印出来
for j in ${!array1[@]}
do
echo $j:${array1[$j]}
done
ss 是 Socket Statistics 的缩写。ss 命令可以用来获取 socket 统计信息,它显示的内容和 netstat 类似,但 ss 的优势在于它能够显示更多更详细的有关 TCP 和连接状态的信息,而且比 netstat 更快。