一个C语言的基本教程—基础篇
文章目录
- 1. 简介:
- 2. 一些基础内容
- 3. 来看看一段代码
- 4. 我们来解析一下吧
- 5. 数据是最重要的
-
-
- (1).变量与常量
- (2).C的历史与变量类型的声明
- (3).数据的存储方式:
- (4).基本数据类型
-
-
-
- 现在大家用的应该都是64位系统了吧我想
-
-
- (5).对数据进行一些操作
- (6).一些其他的数据操作
- (7).数据的关系运算符和逻辑运算符
- (8).三目表达式
- (9).赋值表达式
- (10).数据类型的相互转换
-
- 还有一个小问题
- 小结
-
1. 简介:
是上C语言课的一个机缘巧合,我觉得我可以通过写文档的方式来总结一下我学习到的C语言知识,可以充当自己的笔记,不过因为自己的语言习惯感觉也是可以让大家一起看看的hhhhh,所以就写了这么一篇基本教程。
2. 一些基础内容
学习C语言你首先需要准备一个合适的IDE,Code::Blocks,Dev-C++ 都是初学者不错的选择,未来你还可以选择像是 Microsoft Visual Studio,JetBrains CLion 这样的面向工程的高阶IDE,或者说你也可以选择 Sublime Text,Visual Studio Code,Vim甚至是Windows自带的记事本 等等编辑器完成代码的书写,然后使用gcc或者clang编译器自行编译.
不同于python使用缩进表示语句的层次,C语言对于缩进和空行的要求并不严格,所以甚至你可以把所有的代码都写在同一行,它也完全可以正常运行,例如:
#include 这看起来也没什么大不了的,但如果代码量大了,这样的代码可读性就会非常差,相信你也能理解对吧?
C语言更重要的是 { } (大括号) 和 ; (分号),大括号括起来的代码称作一个代码块,代码块中的代码不是简单的都在一块,他们还处于一个相同的,范围更小的局部作用域内,这在局部变量与全局变量中是相当重要的。分号用于一个语句的结束,分号出现则意味着前面所输入的语句已经结束,之后的内容均不会与之前的内容连接起来.
3. 来看看一段代码
#include 这段代码会在你的电脑上输出一段相当经典的文字——Hello, world!
4. 我们来解析一下吧
#include - #include 是C语言编译预处理的关键字
- 编译预处理是C语言在编译器对C语言源代码进行编译之前进行的一次“预先处理”,与之相同的还有 #define, #ifndef, #undef…
- #include 在此处的作用是引入些什么东西,<>中的stdio.h代表一个头文件,这个头文件中包含了一些常用的函数,例如printf(),scanf()等等,引入了这个头文件之后我们就可以不必再自己造轮子了,直接使用就好了
- 关于编译预处理究竟是什么的问题我们之后再来说
int main()
- int main() 是我们定义的main函数,返回类型为int整型,调用main函数的时候可以不用向内传入任何参数,当然,可选的参数有int argc和char* argv[],所以真正的main函数应该是这样:
int main(int argc, char* argv[])
printf("Hello, world!");
- 调用printf()函数并输出Hello,world!这条信息,很简单吧
return 0;
- 记得main函数的返回类型是int整型吗,这里我们需要返回一个整数值,返回这样一个值虽然好像没有什么用,但是在没有异常机制的C语言里,返回值的数字也是用于判断程序运行是否正常的重要根据
所以C语言真的很简单呢,让我们开始吧!
5. 数据是最重要的
你知道吗?计算机最早设计出来是用来计算的,真的,我又没有说假话,所以首先我们应该了解了解如何使用C语言存储并且对数据进行一定操作。
(1).变量与常量
- 这个变量和数学里的变量是一样的,比如一个x,这个x可以在一定范围内变化,所以这就是个变量了,C语言中则可以是int x = 1
- 常量也一样,比如数学中的1,可能在C语言中我们写const int x = 1,与变量相反,常量是一个不可以改变的量,所以x只能是1,不能变成2
(2).C的历史与变量类型的声明
- C语言其实是个非常非常老的语言了,看看它的历史
C语言,1972年诞生于美国的贝尔实验室,由丹尼斯·里奇(Dennis MacAlistair Ritchie)以肯尼斯·蓝·汤普森(Kenneth Lane Thompson)设计的B语言为基础发展而来。为了利于C语言的全面推广,许多专家学者和硬件厂商联合组成了C语言标准委员会,并在之后的1989年,诞生了第一个完备的C标准,简称“C89”,也就是“ANSI C”.
-
点我以了解更多C语言历史
-
那么1972年诞生的至今依旧非常流行的语言,肯定有一些比较经典的特性,引入数据类型大概也是因为存储各种不同类数据的方式不同,当时的编译器没有如此相当的智能帮你自动识别变量的类型,因此C和后续很多C-like语言也都必须在创建 变量/常量 前声明它们的类型。当然,如果你学的是python这样的语言就不需要。
(3).数据的存储方式:
在计算机中,数据是以二进制的形式存储的,即开关的开和关分别对应二进制的1和0,这样一来从机械上来说实现起来比较方便,因为只要去控制开关的通断,或者对电子元件通过高低电平就可以产生1和0的值了。因此,我们应该使用二进制的方式来存储数据
- 还有一些例如位(bit)和字节(byte)的基本概念
一位(bit)就是一个位置,一个位置只能存储一位的二进制数,即只有0和1两种状态,一个字节(byte)包含8位,我们平常所用到的 KB, MB之类的都是 xxxx-bytes,即 xxxx字节,如果要换算为位则为原来数字大小的八倍,而我们平时用的宽带速率200M,1000M这些单位其实都是MBit,所以实际的下载速率应该要除以8,如200M的理论速率是25 MBytes/s
- 举个例子
我们假设有一个一字节的二进制数据,如 00100010 0010 0010 00100010,我认为大家应该具有相当的数学能力,所以对于一个 n n n 位的二进制数,能够存取的范围应该是0 ≤ x ≤ 2 n − 1 \leq x \leq 2^n -1 ≤x≤2n−1,即从 0000 … 0000 ( n 个 0 ) 0000 \dots 0000 (n个0) 0000…0000(n个0) 到 1111 … 1111 ( n 个 1 ) 1111 \dots 1111 (n个1) 1111…1111(n个1)
- 很不一样的负数
我们采用一种叫做补码的方式来存取二进制的负数,如一个整数9,对应的二进制数为 00001001 0000 1001 00001001 ,首先取这个数字的反码,即取0为1,取1为0,则有反码 11110110 1111 0110 11110110,之后我们再给反码 + 1,则有 11110111 1111 0111 11110111,我们可以把这两个数字加起来试试看 00001001 + 11110111 = 000100000000 0000 1001 + 11110111 = 0001 0000 0000 00001001+11110111=000100000000,那么这个时候我们就发现,这个数字进了一位,这不好吧,不过计算机内用于存储数字的单元应当是固定的,所以8位的二进制数超过8位的部分就会被直接截断,那么最后 1 1 1被丢掉了,结果就是 00000000 0000 0000 00000000了,这样就实现了负数的表示
- 我相信你肯定看懂了上面这些操作是在做什么,但不知道为什么计算机要这么表示负数对吧,我们换个思路来理解。
一个很简单的问题: 32 − 3 = ? 32-3 = ? 32−3=?,答案是29,那这个29是怎么来的呢?首先把32的个位与3作差,发现2是不够的,然后从十位借了一位作为10来减3,这时候就是 12 − 3 = 9 12-3=9 12−3=9,而借了一位之后的3就变成了2,由此我们就得出了答案29,那么在计算机中我们也可以做一样的操作,例如 0 − 1 = − 1 0-1=-1 0−1=−1。
我们用八位二进制数来表示0,即 0000 , 0000 − 0000 , 0001 0000,0000-0000,0001 0000,0000−0000,0001,我们也按照借位的思想,第一位不够向第二位借,然后 10 − 01 = 01 10-01=01 10−01=01,之后发现第二位借的一位也是 0 − 1 0-1 0−1,那我们继续向前借位,则有 100 − 10 = 10 100-10=10 100−10=10,之后我们一位一位做下去,直到第八位时我们发现前面没有位数了,那怎么办?计算机是个很慷慨的东西,就算前面没有位数了,它还是借给了我们数字一个1,由此我们把每一次借位的结果全部加起来就会得到 1111 , 1111 1111,1111 1111,1111,于是这就是-1的二进制表示了,和我们利用补码的结果是一样的,这样是不是就很好理解了呢?
- 负数的一些问题
不难发现,如果每次都用补码的话,正数的表示范围只有最大范围的一半,负数也是,所以一个 n n n字节(感谢大家的指正)有符号的整型,它的范围一般为 − 2 8 n − 1 -2^{8n-1} −28n−1 ≤ x ≤ \leq x\leq ≤x≤ 2 8 n − 1 − 1 2^{8n-1} - 1 28n−1−1
- 等等,好像还有一件事
如果所有的数据都用二进制保存的话,那小数怎么办呢?我们可以很自然的想到二进制小数。当然,二进制小数的表示要比整数更加不直观,将十进制小数转换为二进制小数的一般的步骤如下:对于一个小数 ( 0. a 1 a 2 a 3 a 4 . . . a n ) 10 (0.a_1a_2a_3a_4...a_n)_{10} (0.a1a2a3a4...an)10(大于1的部分再用整数的方法转换为二进制数),乘2,然后得到 ( 0. ( 2 a 1 ) ( 2 a 2 ) ( 2 a 3 ) . . . ( 2 a n ) ) 10 (0.(2a_1)(2a_2)(2a_3)...(2a_n))_{10} (0.(2a1)(2a2)(2a3)...(2an))10,如果可以进位的话就进一位,比如得到 ( 1. b 1 b 2 b 3 . . . b n ) 10 (1.b_1b_2b_3...b_n)_{10} (1.b1b2b3...bn)10,之后观察整数部分,如果是0则记0,如果是1则记1并继续对小数部分进行乘2的操作,最终得到一串0和1组成的数字,如 00101011011 00101011011 00101011011,在前面加上 0. 0. 0.就可以变成十进制小数对应的二进制小数了,即 ( 0.00101011011 ) 2 (0.00101011011)_2 (0.00101011011)2。
经过这样的计算我们不难发现 ( 0.5 ) 10 (0.5)_{10} (0.5)10转换为二进制就是 ( 0.1 ) 2 (0.1)_2 (0.1)2,但是还有相当大一部分的数字经过这样的转换之后成为了无限循环小数,这样一来就产生了一个很大的麻烦,与我之前所说的负数问题一样,超过了存储单元位数的部分是会被直接截断的,比如有这么一个小数 ( 0.00110011001... ) 2 (0.00110011001...)_2 (0.00110011001...)2(以0011为循环节的无限循环小数),假设一个存储单位为8位,那么保存下来的数字或许只有 ( 0.00110011 ) 2 (0.00110011)_2 (0.00110011)2这样,而经过计算我们可以知道这个数字对应十进制下的0.2,而 ( 0.00110011 ) 2 (0.00110011)_2 (0.00110011)2对应的则是 ( 0.193359375 ) 10 (0.193359375)_{10} (0.193359375)10,这个误差很大是因为只保留了8位,如果保留了64位那么结果会精准很多,但是问题在于,这个误差是客观存在的,如果我们多次对浮点数进行乘法运算,那么这个误差会越来越大,以至于到最后导致结果与预期的完全不符。
所以如果涉及到精确计算时,千万不要用浮点数来完成,否则可能结果与实际完全不符,造成非常严重的后果。为了理解得更加深刻,你可以运行一下以下代码,结果肯定会让你非常惊讶
#include (4).基本数据类型
现在大家用的应该都是64位系统了吧我想
| 关键字 | 中文名 | 字节(位)数 | 基本数据类型 | 格式占位符 |
|---|---|---|---|---|
| short | 短整型 | 2字节(16位) | 整型 | %d |
| int | 整型 | 一般是4字节(32位) | 整型 | %d |
| long | 长整型 | 一般也是4字节(32位) | 整型 | %ld |
| long long | 超长整型 | 8字节(64位) | 整型 | %lld |
| unsigned int | 无符号整型 | 一般是4字节(32位) | 整型 | %u |
| unsigned long | 无符号长整型 | 一般也是4字节(32位) | 整型 | %lu |
| unsigned long long | 无符号超长整型 | 8字节(64位) | 整型 | %llu |
| float | 单精度浮点型 | 4字节(32位) | 浮点型 | %f |
| double | 双精度浮点型 | 8字节(64位) | 浮点型 | %lf |
| char | 字符型 | 1字节(8位) | 字符型 | %c |
- char关键字这个有点不太一样,字符型其实和整型很像,本身也是存储从0~127之间的128个数字,而这128个数字对应ASCII码中的各种字符,从而用来保存字符,对字符型进行简单的数学操作是一个比较常用的技巧
- unsigned关键字: 这个关键字可以加在以上几个整型前上,可以使之成为无符号的整型,好处就在于它真的是一一对应的表示出对应的数字,这个关键字可以用于一些不存在负数的变量,可以把最大数字扩展到原来的两倍,这可是一件很棒的事情呢
- 关于浮点数: 浮点数并不一定只有 0. a 1 a 2 a 3 a 4 . . . 0.a_1a_2a_3a_4... 0.a1a2a3a4...这样的格式,还可以使用科学计数法来表示一个形如 a × 1 0 n a\times 10^n a×10n的数字,只需要输入如下代码即可:
double sample = aEn; // aen这样中间为小写e也是可以的
还有一个问题是怎么在double和float之间做选择:我们一般选择double类型来表示浮点数
—————————————————————————————————
- 关于int和long的问题
你会发现,int和long居然都是表示32位整数,这不是一模一样吗?这其实是个历史遗留问题,早期部分编译器实现的short, int, long其实分别是1字节(8位), 2字节(16位), 4字节(32位)的整数,然后64位机器和32位机器共存的时候,为了更好地利用64位,增加了long long这个数据类型用来表示一般的64位整数。
后来大概是64位系统比较普及了,所以把这些数据类型都升级了一下,毕竟大家更常用的整型肯定是int而不是long对吧,大概是这个原因int就从16位整数变成了32位整数,而long并没有发生什么改变。
当然,有的编译器选择将long也作为64位的整数,所以如果你想知道是多少位的话,你可以使用printf(“%d”,sizeof(long));来看看你的编译器中long是什么样的。
所以一般来说用int和long能表达的数字范围是一样的,但是int会比long更好一些
—————————————————————————————————
(5).对数据进行一些操作
我记得之前说过计算机最早设计出来是用来计算的,所以我们可以对基本的数据类型进行一些四则运算之类的操作
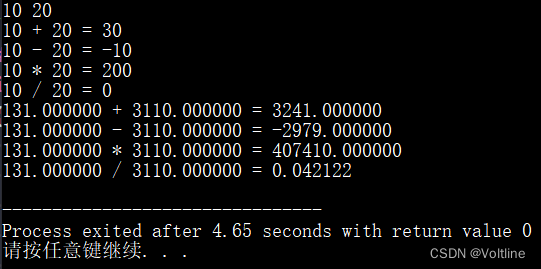
#include - 先看看代码的运行结果
//用于输入注释,在编译运行的过程中会被删去,但是保留在源代码中会非常有利于增加代码的可读性,//只能输入一行的注释,如果要输入多行,则需要利用/* Some Information */,例如:
// 我是单行的注释
// 第二行得这么写
/*
我
是
跨
行
的
注
释
*/
这段代码就要比之前的复杂多了,我们再来分析一下
int a, b;
- 这一行的代码声明了2个int类型的变量a和b
- 所以说,声明和定义变量的基本格式是
[TypeName] Variable-Name1; // 用于声明变量但不初始化
[TypeName] Variable-Name2 = ...SomeValue... // 定义变量
- [TypeName]为数据类型,不要把方括号也打上去了
- 定义时的…SomeValue…应该与类型匹配,否则可能会出现奇怪的问题
scanf("%d %d", &a, &b);
- scanf()函数是stdio.h头文件中定义的一个用于用户输入的函数
- 我们填入的参数为 “%d %d” , &a 和 &b ,那么 “%d %d” 是一个“模板”字符串,在用户输入的时候应当按照这样的格式进行操作,不过实际上比较宽泛,空格,制表符,Tab,甚至空行都是可以接受的
- 我们可以把 %d 这一类的字符称作占位符,即写代码时并不知道这个位置上的内容,但是在程序运行时需要把对应的数据放在这个位置上面。
- 在这里则是说,我要从输入流读取2个整数类型,所以用了两个%d表示接受两个整数,之后的 &a 和 &b 代表对变量a或者b进行一个神秘的操作,然后scanf函数就会帮忙把读取到的这两个整数存入a和b两个变量(之后的章节再介绍这个神秘操作)
printf("%d + %d = %d\n", a, b, a+b); // int + int
-
这行代码调用了printf函数用于在屏幕上打印出一条文字
-
%d 之类的也还是我之前说的占位符,其他已经确定的字符如’+‘,’=‘之类的也都会原封不动的打印出来,字符串的最后还有一个’\n’,这一类以 反斜杠和字符 组成的字符就叫做转义字符,他们发挥着不同的作用,下面是一些常用的转义字符和它们对应的意义
转义字符 ASCII码 意义 注释 \a 7 蜂鸣 你的机器可能发不出声音 \b 8 退格 如果后续没有字符,原有的字符不会消失 \f 12 走纸 来自于打字机 \n 10 换行 换行应当很好理解 \r 13 回车 来自于打字机 \t 9 水平制表符 将屏幕分成若干制表符位,将数据填入 \v 11 垂直制表符 与水平的相对应 \\ 92 反斜杠(\) 打印出一个反斜杠 \’ 39 单引号(') 打印出一个单引号 \" 34 双引号(") 打印出一个双引号 \? 63 问号(?) 打印出一个问号 \0 0 空字符(NULL) 与C语言的字符串有关 -
上述这些转义字符中用的比较多的有 \n, \t
-
\0 在C语言中有着特殊的意义,这在之后讲到字符串的时候你就明白了
-
回车和换行的来历
回车和换行都来自于最早的打字机,打字的过程中敲击键盘后,游标指针会往纸上敲你敲击键位对应的字母,这就涉及到两个问题,当一行打满之后,游标指针不能继续往右移动了(物理限制),那就需要回车,把游标指针从最右边回到最左边的初始位置上,但是回去之后又会继续从当前行打印,会覆盖之前的内容,所以就需要换行,换到第二行打印新的内容,因此虽然Windows下回车和换行好像是同一个操作,但其实最早的打字机中这两个是不同的操作。
- 所以其实说过了这三条代码之后其他的代码也可以看得懂了呢,你说对吧?
- One more thing. 你会发现在运行结果中有这么一行:
10 / 20 = 0
这是一件很奇怪的事情,10/20怎么会是0呢?不应该是0.5吗?非也,C语言中的/对于不同的数据类型有着不同的操作,对于两个整数使用除号就是整除,返回一个整型,而对于两个浮点数使用除号就是正常的除法了,返回一个浮点型,这对于另外三种运算也是成立的。
(6).一些其他的数据操作
- +, -, *, / 这四个运算符是基本的四则运算,与此同时还有如 %(取余),++(自增),–(自减)(两个减号),取余的操作我相信应该不用我说了,接下来我会介绍一下自增和自减运算符。
- ++(自增):如果你以前只学过python,你会发现,哇哦听都没听过,自增的操作就是使得某个变量a的值增加1,不过一般来说会遇到下面两种情况:
int a = 1;
a++; // 情况1
++a; // 情况2
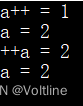
这当然不是打错了,两种情况都是正常且成立的,那这二者难道就没有区别了吗?当然是有的,来运行下面的程序:
#include 很显然我们可以从下图中看出,两次打印出的a++和++a的值是不一样的,a均为1的情况下,a++的返回值为1,而 ++a的返回值为2,因此我们可以很容易地看出前置自增和后置自增的区别,二者都会使得原本的变量+1,但是前置自增(++a)返回的值为增加后的值,后置自增(a++)返回的值为增加前的值.
- ++a 和 a++ 的妙用有的时候也能帮助我们写出非常巧妙的代码,不过在一些只需要变量数目增加的情况下,二者发挥一样的作用,例如:
for (int i = 0; i < 100; i++) {}
以上是一个简单的for循环语句,我们之后会提到
- –(自减):两种情况与自增都是完全一致的,只是自减的操作是将变量的值-1
(7).数据的关系运算符和逻辑运算符
判断关系也是C语言的控制结构中很重要的组成部分,里如一个计数变量不断自增,什么时候才会停止自增呢?这时候可能就需要用到关系运算符实现判断关系,从而达到控制程序运行的目的。
- 一般的关系运算符包括:>, <, ==, !=, >=, <=
- 以上关系运算符均符合小学数学中的各种关系,我就不再过多阐述,但是一定要记住一点,C语言的条件语句中是不可以连续使用关系运算符的,例如在python中可以
if 1 <= a <= 3:
...
这样的连续关系运算的确很方便,但是在C语言中,这样的操作会因为优先级的问题,产生与预期不符的结果。
对于语句 1 <= a <= 3 来说,C语言从左至右执行,首先执行 1 <= a,假设 a = 2;显然a >= 1成立,则这个表达式返回 1 ,即C语言中的真,之后将返回值 1 与 3进行 <= 的关系运算,即 1 <= 3,结果依旧返回 1,看起来似乎没啥问题,但无论a取何值, 1 <= a的运算只有0和1的结果,他们都小于3,所以运算的结果只能为 1,这显然和我们想的连续判断是不同的。那么怎么解决这个连续比较的问题呢?
- 我们采用逻辑运算符连接的方式解决这个问题
- 逻辑运算符包括:&&(与), ||(或), !(非),我想应该很容易理解怎么解决连续比较的问题了,1 <= a <= 3 等价于 a >= 1 && a <= 3,所以我们通过基本的逻辑运算符和关系运算符就可以构建一个相当完备的条件语句了!
(8).三目表达式
在C语言中有这样一种形式比较奇怪的表达式如下:
a > b ? a : b;
基本结构为(condition) ? (return_value1) : (return_value2); 当条件condition成立时,返回return_value1,否则返回return_value2,这个一个表达式可以很方便的帮助我们完成一些工作,比如求最大值:
...
int max = a > b ? a : b;
就这么简单一句就完成了这样的操作。
(9).赋值表达式
这一部分应该也是相对比较重要的,比如我们声明了一个int类型的变量a:
int a;
如果只是声明一个a,这个变量其实是不可用的,因为a没有初始值,就像是某公司决心做一个项目,结果到最后只是创建了一个文件夹,这根本就没什么用嘛,所以我们需要对这个变量进行赋值的操作:
a = 1;
当然a取各种各样的值也都是可以的,全凭你的喜好,不过在赋值的时候应该注意一下a这个变量的类型,例如int类型的范围是 − 2 31 ≤ a ≤ 2 31 − 1 -2^{31} \leq a \leq 2^{31}-1 −231≤a≤231−1,如果超过范围,a的值就会变成一些奇怪的数值,例如 2 31 − 1 2^{31} - 1 231−1是最大值,那我要是存入 2 31 2^{31} 231会发生什么呢?
#include ![]()
所以a的值从2147483648变成了-2147483648,这是为什么呢?
还记得我们说过的整数的二进制表示法吗,用一系列的 1111000010100010... 1111 0000 1010 0010... 1111000010100010...来表示一个数字,最后转换为十进制的数字,那么对于32位的整数 2 31 − 1 = 2147483647 2^{31}-1 = 2147483647 231−1=2147483647很容易可以得出它的二进制表示应该是 0111...1111 ( 32 位 ) 0111 ... 1111(32位) 0111...1111(32位),我们对它加一,得到的就是 1000...0000 1000...0000 1000...0000,而 ( − 2147483647 ) 10 = ( 1000...0001 ) 2 (-2147483647)_{10} = (1000...0001)_{2} (−2147483647)10=(1000...0001)2,再对其-1,得到的就是 ( 1000...0000 ) 2 (1000...0000)_{2} (1000...0000)2,因此,a的值就会从2147483648变成-2147483648。
(10).数据类型的相互转换
还记得这个例子吗?
...
// Input a = 10, b = 3
printf("%d / %d = %d\n", a, b, a/b); // int / int
...
试试看!你会发现程序打印出了以下的结果:
![]()
这这,这不对吧?10除以3得出的结果怎么会是3呢?实际上这就涉及到了数据类型的问题,之前在解析的时候已经提过了,那如果我就是想得到浮点数的结果呢,比如 10 ÷ 3 = 3.3... 10\div3 = 3.3... 10÷3=3.3...,我们就需要用到强制类型转换了。
#include 运行的结果如下
![]()
这下结果就符合我们的想法了,不过我们还是需要解析一下其中的一行代码:
printf("%d / %d = %f\n", a, b, (double)a/(double)b);
前面的占位符应该比较好理解,主要是(double)a和(double)b,这两个语句的意思便是将a和b的数据类型转换为double,再进行除法,这样就能输出一个double类型的结果了,所以将某一个数据类型强制转换为另一类型的话我们需要使用以下的语句:
(NewTypeName)Variable;
在圆括号中写出新的数据类型,后面跟上变量的名字,这样就可以转换数据类型了,是不是很简单呢?
还有一个小问题
再试试看下面这段代码,看看会有什么结果?
#include ![]()
哇哦我们会发现这个运行结果和之前把a和b都转换成double类型的运行结果是一样的诶,事实上,这样的操作叫做隐式类型转换,C语言在进行一些操作的时候如果同时出现了不同的数据类型会自动进行转换,就比如这个例子中一个double与一个int做除法,分母的int会被自动转换为double然后再进行除法的运算,其他的隐式转换规则可以自己试着探索一下哦。
小结
你看看,数据的确是很重要的一个内容呢!我用了如此大的篇幅介绍也没能展现其全貌,剩下的内容如位运算符会在之后的章节中提到,运算符之类的优先级和类型转换的更多内容可能就需要你自己去学习了。