ShardingJDBC数据库中间件学习笔记
简介
官网地址:https://shardingsphere.apache.org/index_zh.html

Apache ShardingSphere 产品定位为 Database Plus,旨在构建多模数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。ShardingSphere 站在数据库的上层视角,关注他们之间的协作多于数据库自身。
连接、增量和可插拔是 Apache ShardingSphere 的核心概念。
- 连接:通过对数据库协议、SQL 方言以及数据库存储的灵活适配,快速的连接应用与多模式的异构数据库;
- 增量:获取数据库的访问流量,并提供流量重定向(数据分片、读写分离、影子库)、流量变形(数据加密、数据脱敏)、流量鉴权(安全、审计、权限)、流量治理(熔断、限流)以及流量分析(服务质量分析、可观察性)等透明化增量功能;
- 可插拔:项目采用微内核 + 三层可插拔模型,使内核、功能组件以及生态对接完全能够灵活的方式进行插拔式扩展,开发者能够像使用积木一样定制属于自己的独特系统。

ShardingSphere-JDBC
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
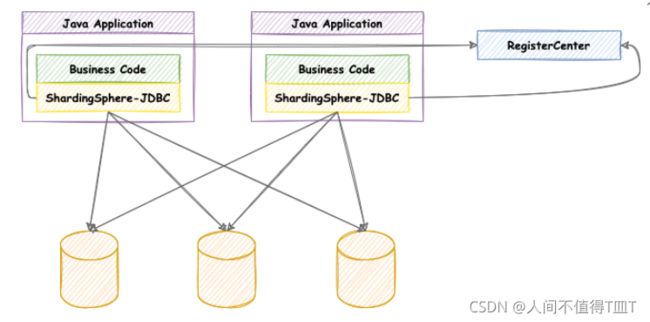
ShardingSphere-Proxy
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL(兼容 openGauss 等基于 PostgreSQL 的数据库)版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。

hardingSphere-Sidecar(TODO)
定位为 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的啮合层,即 Database Mesh,又可称数据库网格。
Database Mesh 的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互进行有效地梳理。 使用 Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。

| ShardingSphere-JDBC | ShardingSphere-Proxy | ShardingSphere-Sidecar |
|---|---|---|
| 数据库 | 任意 MySQL/PostgreSQL | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅 Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
hardingSphere功能清单
- 功能列表:1.数据库分片 2.分库分表 3.读写分离 4.分片策略定制化 5.无中心化分布式主键
- 分布式事务: 1.标准化事务接口 2.XA强一致事务 3.柔性事务 4.数据库治理
- 分布式治理: 1.弹性伸缩 2.可视化链路追踪 3.数据加密
ShardingSphere数据分片内核剖析
ShardingSphere的3个产品的数据分片主要流程是完全一致的。核心由SQL解析=>执行器优化=>SQL路由=>SQL改写=> SQL执行=>结果归并的流程组成。

ShardingJDBC准备
Mysql完成主从复制
liunx准备mysql数据库
概述
主从复制(也称AB复制)允许将来自一个MySQL数据库服务器(主服务器)的数据复制到一个或多个MySQL数据库服务器(从服务器)。
复制是异步的从站不需要永久连接以接收来自主站的更新。
根据配置,您可以复制数据库中的所有数据库,所选数据库甚至选定的表。
主从复制优点
- 横向扩展解决方案–在多个从站之间分配负载以提高性能。在此环境中,所有写入和更新都必须在主服务器上进行。但是,读取可以在一个或多个从设备上进行。该模型可以提高写入性能(因为主设备专用于更新),同时显着提高了越来越多的从设备的读取速度。
- 数据安全性·因为数据被复制到从站,并且从站可以暂停复制过程,所以可以在从站上运行备份服务而不会破坏相应的主数据。
- 分析–可以在主服务器上创建实时数据,而信息分析可以在从服务器上进行,而不会影响主服务器的性能。远程数据分发–您可以使用复制为远程站点创建数据的本地副本,而无需永久访问主服务器。
主从复制原理
前提是作为主服务器角色的数据库服务器必须开启二进制曰志
主服务器上面的任何修改都会通过自己的I/0 tread(I/O线程)保存在二进制日志 Binary log里面。
- 从服务器上面也启动一个I/0 thread,通过配置好的用户名和密码,连接到主服务器上面请求读取二进制日志,然后把读取到的二进制日志写到本地的一个Realy log(中继日志)里面。
- 从服务器上面同时开启一个SQL thread定时检查Realy log(这个文件也是二进制的),如果发现有更新立即把更新的内容在本机的数据库上面执行一遍。
每个从服务器都会收到主服务器二进制日志的全部内容的副本。 - 从服务醋设备负责决定应该执行二进制日志中的哪些语句。
除非另行指定,否则主从二进制日志中的所有事件都在从站上执行。如果需要。您可以将从服务器配置为仅处理一些特定数据库或表的事件。
基于Docker完成主从复制
原文链接:https://www.cnblogs.com/songwenjie/p/9371422.html
为什么基于Docker搭建?
- 资源有限
- 虚拟机搭建对机器配置有要求,并且安装mysql步骤繁琐
- 一台机器上可以运行多个Docker容器
- Docker容器之间相互独立,有独立ip,互不冲突
- Docker使用步骤简便,启动容器在秒级别
利用Docker搭建主从服务器
首先拉取docker镜像,我们这里使用5.7版本的mysql:
docker pull mysql:5.7
然后使用此镜像启动容器,这里需要分别启动主从两个容器
Master(主):
docker run -p 3339:3306 --name mymysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
Slave(从):
docker run -p 3340:3306 --name mymysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
Master对外映射的端口是3339,Slave对外映射的端口是3340。因为docker容器是相互独立的,每个容器有其独立的ip,所以不同容器使用相同的端口并不会冲突。这里我们应该尽量使用mysql默认的3306端口,否则可能会出现无法通过ip连接docker容器内mysql的问题。
使用docker ps命令查看正在运行的容器
[root@iz2vcbxtcjxxdepmmofk3hz mysql3307]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
66392fd83cf1 mysql:5.7 "docker-entrypoint.s…" 51 minutes ago Up 20 minutes 33060/tcp, 0.0.0.0:3308->3306/tcp mysql-slave
f5b9761e3dee mysql:5.7 "docker-entrypoint.s…" 51 minutes ago Up 35 minutes 33060/tcp, 0.0.0.0:3307->3306/tcp mysql-master
配置Master(主)
通过docker exec -it 627a2368c865 /bin/bash命令进入到Master容器内部,也可以通过docker exec -it mysql-master /bin/bash命令进入。627a2368c865是容器的id,而mysql-master是容器的名称。
cd /etc/mysql切换到/etc/mysql目录下,然后vi my.cnf对my.cnf进行编辑。此时会报出bash: vi: command not found,需要我们在docker容器内部自行安装vim。使用apt-get install vim命令安装vim
会出现如下问题:
Reading package lists... Done
Building dependency tree
Reading state information... Done
E: Unable to locate package vim
执行apt-get update,然后再次执行apt-get install vim即可成功安装vim。然后我们就可以使用vim编辑my.cnf,在my.cnf中添加如下配置:
[mysqld]
## 同一局域网内注意要唯一
server-id=100
## 开启二进制日志功能,可以随便取(关键)
log-bin=mysql-bin
配置完成之后,需要重启mysql服务使配置生效。使用service mysql restart完成重启。重启mysql服务时会使得docker容器停止,我们还需要docker start mysql-master启动容器。
下一步在Master数据库创建数据同步用户,授予用户 slave REPLICATION SLAVE权限和REPLICATION CLIENT权限,用于在主从库之间同步数据。
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%';
配置Slave(从)
和配置Master(主)一样,在Slave配置文件my.cnf中添加如下配置:
[mysqld]
## 设置server_id,注意要唯一
server-id=101
## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
## relay_log配置中继日志
relay_log=edu-mysql-relay-bin
配置完成后也需要重启mysql服务和docker容器,操作和配置Master(主)一致。
链接Master(主)和Slave(从)
在Master进入mysql,执行show master status;

File和Position字段的值后面将会用到,在后面的操作完成之前,需要保证Master库不能做任何操作,否则将会引起状态变化,File和Position字段的值变化。
在Slave 中进入 mysql,执行
change master to master_host='172.17.0.3', master_user='slave', master_password='123456', master_port=3306, master_log_file='mysql-bin.000001', master_log_pos= 3298, master_connect_retry=30;
命令说明:
master_host : Master的地址,指的是容器的独立ip,可以通过docker inspect --format='{{.NetworkSettings.IPAddress}}' 容器名称|容器id 查询容器的ip
master_port: Master的端口号,指的是容器的端口号
master_user: 用于数据同步的用户
master_password: 用于同步的用户的密码
master_log_file: 指定 Slave 从哪个日志文件开始复制数据,即上文中提到的 File 字段的值
master_log_pos: 从哪个 Position 开始读,即上文中提到的 Position 字段的值
master_connect_retry: 如果连接失败,重试的时间间隔,单位是秒,默认是60秒
在Slave 中的mysql终端执行show slave status \G;用于查看主从同步状态。
正常情况下,SlaveIORunning 和 SlaveSQLRunning 都是No,因为我们还没有开启主从复制过程。使用start slave开启主从复制过程,然后再次查询主从同步状态show slave status \G;。
SlaveIORunning 和 SlaveSQLRunning 都是Yes,说明主从复制已经开启。此时可以测试数据同步是否成功。
读写分离
项目测试
新建项目导入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>1.3.2version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.1.10version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0-RC1version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-core-commonartifactId>
<version>4.0.0-RC1version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
yaml配置
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置 显示SQl
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名
names: ds1,ds2
# 给master-ds1每个数据源配置数据库连接信息
ds1: # master
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3307/test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=true&nullCatalogMeansCurrent=true
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
ds2: # slave
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3308/test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=true&nullCatalogMeansCurrent=true
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
# 配置默认数据源
sharding:
# 默认数据源 主要用于写 注意一定要配置读写分离 如果不配做 那么就会把全部节点都当成slave
default-data-source-name: ds1
# 配置读写分离
masterslave:
name: ms # 名称 任意取
master-data-source-name: ds1 # 主库
slave-data-source-names: ds2 # 从库 多个逗号分割
# 从节点负载均衡策略 默认轮询 随机 RANDOM
load-balance-algorithm-type: round_robin
# mybatis 配置
mybatis:
mapper-locations: classpath*:mapper/*.xml
type-aliases-package: com.tuxc.entity
数据库表
DROP TABLE IF EXISTS `master_slave`;
CREATE TABLE `master_slave` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
测试代码编写
@Data
public class TestEntity {
// 主键
private Integer id;
// 姓名
private String name;
}
@Repository
@Mapper
public interface TestMapper {
@Select("select * from master_slave")
List<TestEntity> selectByAll();
@Insert("insert into master_slave (name) VALUES (#{name})")
void insert(TestEntity testEntity);
}
测试运行
@RestController
@RequestMapping("/test/user")
public class TestController {
@Autowired
private TestMapper testMapper;
@GetMapping
public String insert(){
TestEntity test = new TestEntity();
test.setName("ndsjjdaa");
testMapper.insert(test);
return "success";
}
@GetMapping("findByAll")
public List<TestEntity> findByAll(){
return testMapper.selectByAll();
}
}

由此实现了读写分离
分库分表
为什么要分库分表
一般的机器(4核16G),单库的MySQL并发(QPS+TPS)超过了2k,系统基本就完蛋了。最好是并发量控制在1k左右。这里就引出一个问题,为什么要分库分表?
分库分表目的:解决高并发,和数据量大的问题。
1、高并发情况下,会造成IO读写频繁,自然就会造成读写缓慢,甚至是宕机。一般单库不要超过2k并发,NB的机器除外。
2、数据量大的问题。主要由于底层索引实现导致,MySQL的索引实现为B+TREE,数据量其他,会导致索引树十分庞大,造成查询缓慢。
第二,innodb的最大存储限制64TB。
要解决上述问题。最常见做法,就是分库分表。
分库分表的目的,是将一个表拆成N个表,就是让每个表的数据量控制在一定范围内,保证SQL的性能。一个表数据建议不要超过500W。
概念
又分为垂直拆分和水平拆分。
水平拆分: 统一个表的数据拆到不同的库不同的表中。可以根据时间、地区、或某个业务键维度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致。
垂直拆分: 就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,可以根据业务维度进行拆分,如订单表可以拆分为订单、订单支持、订单地址、订单商品、订单扩展等表;也可以,根据数据冷热程度拆分,20%的热点字段拆到一个表,80%的冷字段拆到另外一个表。
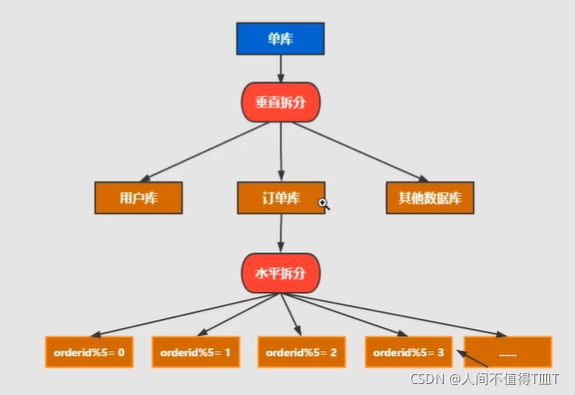
不停机分库分表数据迁移
一般数据库的拆分也是有一个过程的,一开始是单表,后面慢慢拆成多表。那么我们就看下如何平滑的从MySQL单表过度到MySQL的分库分表架构。
- 利用mysql+canal做增量数据同步,利用分库分表中间件,将数据路由到对应的新表中。
- 利用分库分表中间件,全量数据导入到对应的新表中。
- 通过单表数据和分库分表数据两两比较,更新不匹配的数据到新表中。
- 数据稳定后,将单表的配置切换到分库分表配置上。
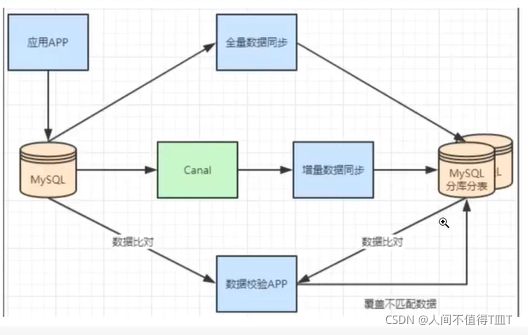
分库分表的方式
逻辑表
逻辑表是指:水平拆分的数据库或者数据表的相同路基和数据结构表的总称。比如用户数据根据用户id%2拆分为2个表,分别是:ksi_user0和ksd_user1。他们的逻辑表名是: ksd_user。
在shardingjdbc中的定义方式如下:
spring:
shardingsphere:
sharding:
tables:
# 逻辑表名称
master-savle:
分库分表数据节点- actual-data-nodes
spring:
shardingsphere:
sharding:
tables:
# 逻辑表名称
master-savle: # 有多少库和表则定义多少 否则会报错
# 数据节点:多数据源$->{0..N} 逻辑表名$ ->{0..N} 相同表
actual-data-nodes: ds$->{0..2}.master-savle$->{0..1}
# 数据节点;多数据源$->{0..N} 逻辑表名$ ->{0..N} 不同表
actual-data-nodes: ds0.master-savle$->{0..1}, ds1.master-savle$->{2..4}
# 指定单数据源的配置方式
actual-data-nodes: ds0.master-savle$->{0..4}
# 全部手动指定
actual-data-nodes: ds0.master-savle1, ds0.master-savle2, ds0.master-savle3
数据分片是最小单元。由数据源名称和数据表组成,比如: ds0.ksd_user0

分库分表5种分片策略
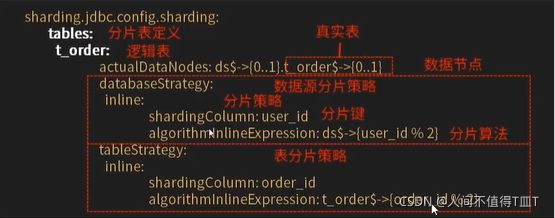
数据源分片分为两种:
- 数据源分片
- 表分片
这两个是不同维度的分片规则,但是它们额能用的分片策略和规则是一样的。它们由两部分构成:
- 分片键
- 分片算法
第一种: none
对应NoneShardingStragey,不分片策略,SQL会被发给所有节点去执行,这个规则没有子项目可以配置。
第二种:inline行表达时分片策略{核心,必须要掌握)
对应InlineShardingStragey。使用Groovy的表达时,提供对SQL语句种的=和in的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开放,如: ksd_user$(分片键(数据表字段) userid % 5)表示ksd_user表根据某字段(userid)模5.从而分为5张表,表名称为: ksd_user0到ksd_user4。如果库也是如此。
spring:
shardingsphere:
sharding:
tables:
# 逻辑表名称
master-savle:
# 数据节点:多数据源$->{0..N} 逻辑表名$ ->{0..N} 相同表
actual-data-nodes: ds$->{0..2}.master-savle$->{0..1}
# 数据源分片策略
databaseStrategy:
inline:
shardingColumn: user_id
algorithmlnlineExpression: ds$->{user_id%2}
# 表分片策略
tableStrategy:
inline:
shardingColumn: order_id
algorithmlnlineExpression: master-savle$->{order_id%2}
第三种:根据实时间日期–按照标准规则分库分表
标准分片- Standard(了解)
- 对应StrandardShardingStrategy.提供对SQL语句中的=,in和恶between and的分片操作支持。
- StrandardShardingStrategy只支持但分片键。提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
- PreciseShardingAlgorithm是必选的呃,用于处理=和IN的分片
- 和RangeShardingAlgbrithm是可选的,是用于处理Betwwen and分片,如果不配置和RangeShardingAlgorithm,SQL的Between AND将按照全库路由处理。
/**
* 标准分片- Standard(了解)
* 必须继承PreciseShardingAlgorithm
* @author tuxuchen
* @date 2021/11/25 11:41
*/
public class BirthdayAlgorithm implements PreciseShardingAlgorithm<Date> {
// 有几个数据源 放几条数据
List<Date> dateList = new ArrayList<>();
{
Calendar calendar1 = Calendar.getInstance();
calendar1.set(2021, 1, 1, 0, 0, 0);
Calendar calendar2 = Calendar.getInstance();
calendar2.set(2022, 1, 1, 0, 0, 0);
dateList.add(calendar1.getTime());
dateList.add(calendar2.getTime());
}
/**
*
* @param collection 数据源集合 ds1 ds2
* @param preciseShardingValue
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Date> preciseShardingValue) {
// 获得属性数据库的值
Date date = preciseShardingValue.getValue();
// 获取数据源的名称信息列表
Iterator<String> iterator = collection.iterator();
String target = null;
for (Date s : dateList) {
target = iterator.next();
// 如果数据晚于指定的日期直接返回
if (date.before(s)){
break;
}
}
return target; // 最后返回的是 ds1 ds2
}
}
spring:
shardingsphere:
sharding:
tables:
# 逻辑表名称
master-savle:
# 数据节点:多数据源$->{0..N} 逻辑表名$ ->{0..N} 相同表
actual-data-nodes: ds$->{0..2}.master-savle$->{0..1}
# 数据源分片策略
databaseStrategy:
standard:
shardingColumn: birthady # 字段名
preciseAlgorithmClassName: com.tuxc.config.BirthdayAlgorithm
# 表分片策略
tableStrategy:
inline:
shardingColumn: order_id
algorithmlnlineExpression: master-savle$->{order_id%2}
第四种: ShardingSphere -符合分片策略((了解)
- 对应接口:HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
- 对于分片字段非SQL决定,而是由其他外置条件决定的场景,克使用SQL hint灵活的注入分片字段。例如:按照用户登录的时间,主键等进行分库,而数据库中并无此字段。SQL hint支持通过Java API和SQL注解两种方式使用。让后分库分表更加灵活。

第五种:ShardingSphere - hint分片策略(了解)
- 对应ComplexShardingStrategy。符合分片策略提供对SQL语句中的-,in和between and的分片操作支持。
- ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键组合以及分片操作符透传至分片算法,完全由开发者自己实现,提供最大的灵活度。

分布式主键配置
问题:如果主键是自增长的情况下,存放在不同数据库里的数据,很容易出现主键相同的情况

ShardingSphere提供灵活的配置分布式主键生成策略方式。在分片规则配置模块克配置每个表的主键生成策略。默认使用雪花算法。(snowflake)生成64bit的长整型数据。支持两种方式配置
- SNOWFLAKE
- UUID
spring:
shardingsphere:
sharding:
tables:
# 逻辑表名称
master-savle:
key-generator:
#主键的列明 数据库类型 必须用 bigint类型
column: id
type: SHOWFLAKE # 注意要用大写
注意点:
- 数据库主键类型不要自增长,否则会插入不进去
- 使用SHOWFLAKE ,数据库列类型必须是bigint
- 配置主键策略使用大写
分布式事务管理
本地事务
在不开启任何分布式事务管理器的前提下,让每个数据节点各自管理自己的事务,它们之间没有协阅以及通信的能力,也并不互相知晓其他数据节点事务的成功与否。本地事务在性能方面无任何损耗,但在强一致性以及最终一致性方面则力不从心。
两阶段提交
XA协议最早的分布式事务模型是由X/Open国际联盟提出的X/Open Distributed Transaction Processing (DTP)模型,简称XA协议。
基于XA协议实现的分布式事务对业务侵入很小。它最大的优势就是对使用方通明,用户可以像使用本地事务一样使用基于XA协议的分布式事务。XA协议能够严格保障事务ACID特性。
严格保障事务ACID特性是一把双刃剑,事务执行在过程中需要将所需资源全部锁定,它更加适用于执行时间确定的短事务。对于长事务来说,整个事务进行期间对数据的独占,将导致对热点数据依赖的业务系统并发性能衰退明显。因此,在高并发的性能至上场景中,基于XA协议的分布式事务并不是最侄选择。
柔性事务
如果将实现了ACID的事务要素的事务称为刚性事务的话,那么基于BASE事务要素的事务则称为桑柔性事务。BASE是基本可用、柔性状态和最终―数性这三个要素的缩写。
- 基本可用(Basically Available)保证分布式事务参与方不一定同时在线。
- 柔性状态(Soft state)则允许系统状态更新有一定的延时,这个延时对客户来说不一定能够察觉。
- 而最终一致性(Eventually consistent)通常是通过消息传递的方式保证系统的最终一致性。
在ACID事务中对隔离性的要求很高,在事务执行过程中,必须将所有的资源锁定。柔性事务的理念则是通过业务逻辑将互斥锁操作从资源层面上移至业务层面。通过放宽对强一致性要求,来换取系统吞吐量的提升。
基于ACID的强一致性事务和基于BASE的最终一致性事务都不是银弹,只有在最适合的场景中才能发挥它们的最大长处,可通过下表详细对比它们之间的区别,以帮助开发者进行技术选型,
使用SpringBoot starter
引入 Maven 依赖
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>shardingsphere-transaction-xa-coreartifactId>
<version>${shardingsphere.version}version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>shardingsphere-transaction-base-seata-atartifactId>
<version>${shardingsphere.version}version>
dependency>
配置事务管理器
@Configuration
@EnableTransactionManagement
public class TransactionConfiguration {
@Bean
public PlatformTransactionManager txManager(final DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean
public JdbcTemplate jdbcTemplate(final DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
}
使用分布式事务
@Transactional
@ShardingSphereTransactionType(TransactionType.XA) // 支持TransactionType.LOCAL, TransactionType.XA, TransactionType.BASE
public void insert() {
jdbcTemplate.execute("INSERT INTO t_order (user_id, status) VALUES (?, ?)", (PreparedStatementCallback<Object>) ps -> {
ps.setObject(1, i);
ps.setObject(2, "init");
ps.executeUpdate();
});
}