kubernetes(k8s): service 和 ingress
文章目录
- 一 总述
-
- 1 service 作用
- 2 service资源及实现模型
-
- 1 service 概述
- 2 虚拟IP和服务代理
-
- 1 虚拟IP
- 2 代理模型
- 二 service 资源基本应用
-
- 1 创建service 资源
-
- 1 使用命令行创建service资源
- 2 使用配置文件创建service
- 2 service 会话粘滞性
-
- 1 概述
- 2 设置字段解析
- 3 部署实例并验证
- 3 服务发现
-
- 1 概述
- 2 服务发现实现机制
- 3 服务发现类型
- 4 服务发现
- 4 服务暴露
-
- 1 service类型
- 三. ingress资源应用
-
- 1 概述
- 2 ingress 和 ingress controller
一 总述
1 service 作用
POD 中运行的容器存在动态、弹性的变化(容器的重启IP地址会变化),因此便产生了service,其资源为此类POD对象提供一个固定、统一的访问接口及负载均衡能力,并借助DNS系统的服务发现功能,解决客户端发现容器难得问题
service 和POD 对象的IP地址在集群内部可达,但集群外部用户无法接入服务,解决的思路有:
1 在POD上做端口暴露(hostPort)
2 在工作节点上公用网络名称空间(hostNetwork)
3 使用service 的NodePort 或 loadbalancer (service 依赖于 DNS资源服务)
4 ingress七层负载均衡和反向代理资源
2 service资源及实现模型
1 service 概述
1 service是微服务的一种实现,事实上其是一种抽象:通过关注定义出多个POD对象组合而成的逻辑集合,以及访问这组POD的策略,service关联POD 需要标签选择器完成,其基于标签选择器将一组POD定义成一个逻辑集合,并通过自己的IP地址和端口调度代理请求至后端POD之上。
2 service 对象的IP地址称为cluster IP,位于K8S集群配置指定的专用IP地址范围内,其是一种虚拟IP地址,其在service对象创建后保持不变,并且能够被同一集群中的POD资源访问,service端口接受客户端的请求并将其转发至后端POD中的相应端口,因此,其又被称为四层代理,因其工作在TCP/IP层。
3 service 资源通过API server 持续监视标签选择器匹配到的后端POD对象,并实时跟踪各对象的变动,service并不直接连接POD对象,而是通过endpoints 资源对象类型处理,其有IP地址和端口组成,默认情况下,当创建service对象时,其关联的endpoints对象也会被自动创建。
2 虚拟IP和服务代理
1 虚拟IP
一个service对象就是工作节点上的一些iptables或ipvs,用于将到达service对象的IP地址的流量转发到相应的endpoint对象指定的IP地址和端口上,kube-proxy组件通过api-server持续监控着各个service及其相关的POD对象,并将其创建或变动实时反映到工作节点的iptable或ipvs上。
ipvs是借助于netfilter实现的网络请求报文调度框架,支持rr、wrr、lc、wlc、sh、sed和nq 等十余种调度算法,用户空间的命令行工具是ipvsadm,用于管理工作于ipvs上的调度规则。
service IP 事实上是用于生成iptables 或 ipvs 规则时使用的ip地址,仅用于实现K8S集群网络的内部通信,并能够通过规则中定义的转发服务请求作为目标地址予以响应,这也是其成为虚拟IP地址的原因。
2 代理模型
1 userspace 代理模型(用户空间模型)
userspace 是Linux操作系统的用户空间,这种模型中,kube-proxy 负责跟踪API server 上的endpoints对象的变动,并根据其进行相关的调整策略。
对于每个service对象,其都会随机打开一个本地端口,任何到达此端口的请求都会被代理到当前service资源的后端各个POD对象上,其默认使用RR调度策略。
其代理的过程是: 请求到达service后,其被转发到内核,经由套接字送往用户空间的kube-proxy,而后经由kube-proxy送回内核空间,并调度至后端POD,其传输方式效率太低。在1.1 版本之前,其是默认的转发策略。
2 iptables代理模型
kube-proxy 负责跟踪API server上 service和 endpoints对象的变动,并据此作出service资源定义的变动,对于每个service,都会创建iptabls规则直接捕获到达clusterIP 和PORT 的流量,并将其重定向到当前的service后端,默认算法是随机调度算法,POD 直接请求service IP 地址通过其直接访问对应的POD服务,在1.2开始成为默认类型,其使用的是iptables的目标地址转换至后端的POD对象,相对而言,其不用在内核和用户空间之间切换,因此更加高效,但其不能再被挑中的POD资源无响应时进行重定向,但用户空间(userspace)模型可以。
3 ipvs模型
此模型跟踪API service上的service和endpoints对象的变动,据此来调用netlink接口创建IPVS规则,并确保API server中的变动保持同步,其流量调度策略在IPVS中实现,其余的在iptables中实现。
ipvs 支持众多调度算法,如rr、lc、dh、sh、sed和nq 等。
二 service 资源基本应用
service 本身不提供服务,其是通过后端POD提供对应的服务,因此,service资源对象通常要和deployment完成应用的创建和对外发布。
1 创建service 资源
1 使用命令行创建service资源
创建POD资源
kubectl run nginx --image=nginx:1.14 --replicas=3
查看deployment资源
 其名称为nginx
其名称为nginx
创建对应的service资源
kubectl expose deployment nginx --name=nginx --port=80 --target-port=80 --protocol=TCP
查看生成的service
 查看生成的endpoints对应关系
查看生成的endpoints对应关系
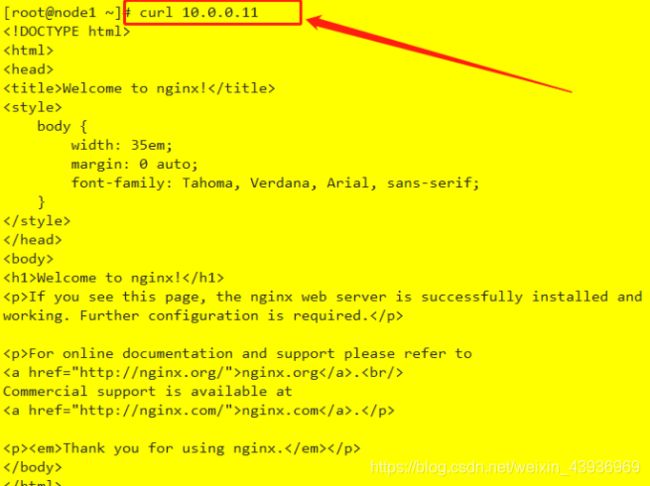
 node节点资源访问
node节点资源访问
2 使用配置文件创建service
#[root@master1 service]# cat demo.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: service-demo
namespace: default
spec:
selector: #用于匹配后面POD对象
matchLabels:
app: service
template:
metadata:
labels:
app: service
spec:
containers:
- name: service-demo
image: nginx:1.14
ports: # 配置暴露端口
- name: http
containerPort: 80
readinessProbe: #增加就绪性探测,用于探测服务是否正常运行,若未就绪则service不能向该POD上调度流量
httpGet:
port: 80
path: /index.html
---
apiVersion: v1
kind: Service
metadata:
name: demo-service # service名称
spec:
selector: # 用于匹配后面POD对象
app: service
ports:
- protocol: TCP # 使用的协议
port: 80 #service 端口号
targetPort: 80 # 后端POD端口号
部署
kubectl apply -f demo.yaml
查看service访问的接口
 查看service详细信息
查看service详细信息
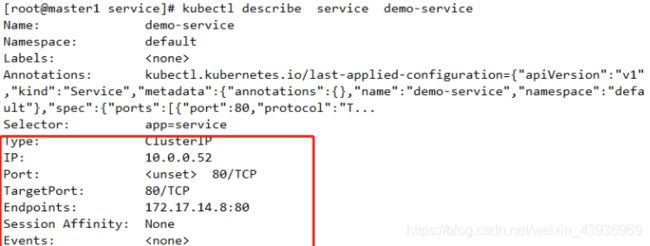
- 其默认类型是clusterIP,使用地址为自动配置,此类型的service对象只能通过集群内部访问。若集群中的POD对象的标签为app=service,则其会被自动关联至service后端
创建http服务用以验证
kubectl run http --image=httpd -l app=service
查看POD是否启动成功
 查看 endpoints
查看 endpoints
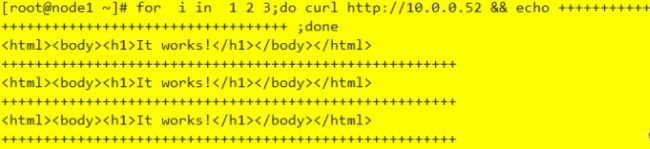
 测试
测试
其IP地址为service对应的IP地址
for i in 1 2 3;do curl http://10.0.0.52 && echo ++++++++++++++++++++++++++++++++++++++++++++++++++++++ ;done
查看


 当kubernetes 集群的service代理模式为
当kubernetes 集群的service代理模式为iptables,它默认使用的算法是随机调度,因此service会将客户端的请求随机调度至关联的某个POD资源上。
2 service 会话粘滞性
1 概述
service 会话粘滞性
service 资源支持session affinity(黏性会话或会话黏性)机制,能够将来自同一个客户端的请求始终转发至同一个后端POD,其会降低负载均衡的效果,因此,当客户端访问POD中的应用程序时,如果有基于客户端身份保存某些私有信息,并基于这些私有信息追踪用户的活动一类的需求时,就应该启动会话保持机制。
session affinity的效果会在一定时间期限内生效,默认是10800秒,超出此时间之后,客户端的再次访问会被调度算法重新调度,另外service资源的session affinity 机制仅能基于客户端IP地址识别客户端身份,他会把经由同一个NAT 服务器进行源地址转换的所有客户端识别为统一客户端,调度粒度粗糙且效果不佳,因此,实践中不推荐使用此种方法实现粘性会话。
2 设置字段解析
kubectl explain service.spec.sessionAffinityConfig.clientIP.timeoutSeconds
用于配置配置其会话保持时长,是一个嵌套字段,使用时长是1-86400,默认是10800
kubectl explain service.spec.sessionAffinity
用于定义要使用的黏性会话的类型,其仅支持"none
和"clinetIP"两种类型。
none :不使用sessionaffinity,默认值
clientIP:基于客户端IP地址识别客户端身份,把来自同一个源IP地址的请求始终调度到同一个POD对象上。
3 部署实例并验证
1 删除上面创建实例
kubectl delete -f demo.yaml
修改实例
[root@master1 service]# cat demo1.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: service-demo
namespace: default
spec:
selector: #用于匹配后面POD对象
matchLabels:
app: service
template:
metadata:
labels:
app: service
spec:
containers:
- name: service-demo
image: nginx:1.14
ports: # 配置暴露端口
- name: http
containerPort: 80
readinessProbe: #增加就绪性探测,用于探测服务是否正常运行,若未就绪则service不能向该POD上调度流量
httpGet:
port: 80
path: /index.html
---
apiVersion: v1
kind: Service
metadata:
name: demo-service # service名称
spec:
selector: # 用于匹配后面POD对象
app: service
ports:
- protocol: TCP # 使用的协议
port: 80 #service 端口号
targetPort: 80 # 后端POD端口号
sessionAffinity: ClientIP #配置会话粘滞基于客户端
sessionAffinityConfig: # 配置会话粘滞时间
clientIP:
timeoutSeconds: 86400
部署
kubectl apply -f demo1.yaml
查看后端POD情况
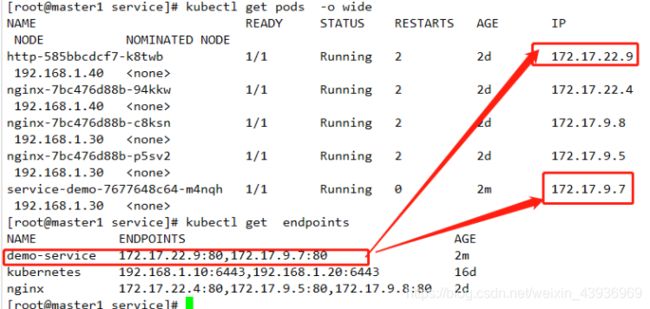 查看serviceIP地址
查看serviceIP地址
 测试
测试
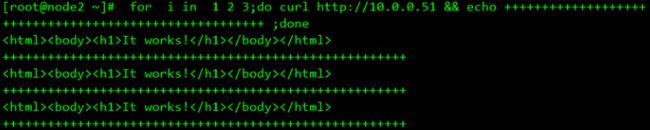
 其实现了会话保持
其实现了会话保持
3 服务发现
1 概述
由于各个服务之间需要能够够正常通信并提供统一的稳定的访问入口,所以POD客户端中的应用需要知道某service资源的IP地址和端口号,这边产生了service discovery
2 服务发现实现机制
1 部署稳定的服务注册中心
2 服务提供者(POD及其应用)提供自己的位置信息,并在变动后及时更新信息
3 消费者(serice)周期性层注册中心获取服务者提供的最新信息从而发现要访问的目标服务字段
3 服务发现类型
1 客户端发现: 由客户端到注册中心发现其依赖到服务的相关信息,其需要内置的发现程序和发现逻辑
2 服务端发现:需要使用中央路由器或服务均衡器的组件,服务消费者(客户端 )将其请求发送到中央路由器或负载均衡器,由他们负责查询服务注册中心获取服务提供者的位置信息,并将服务消费者的请求转发给服务提供者(POD及其应用)
coreDNS
DNS是原始的服务发现系统之一,但其传播速度过慢,后期常见的服务注册中心是zookeeper 和 etcd 等分布式键值存储系统,其只提供基本的数据存储功能,距离实现完整的服务发现机制还有大量的开发任务,
Netflix 和 eureka 是目前较流行的服务发现系统之一,是专门开发用来实现服务发现的系统,以可用性目的为先,可以在多种故障期间保持服务发现和服务注册功能的可用,
传统DNS不适合微服务环境,但skyDNS实现了,
自K8S 1.3 开始,其服务发现的DNS 更新为了kubeDNS,而另一个较新的是 coreDNS,是基于GO语言开发,通过串接一组实现DNS功能的插件的插件连进行工作,自1.11开始coreDNS取代了kubeDNS成为默认的DNS附件。
4 服务发现
1 环境变量
创建POD资源时,kubelet会将其所属名称空间内的每个活动的service对象以一系列环境变量的形式注入其中,其支持使用kubernetes service环境变量以及与docker的links 兼容的环境变量
1 kubernetes service 环境变量
kubernetes 为每个service资源生成包括下面形式的环境变量,在同一名称空间(默认名称空间default)中创建的POD对象自动拥有这些变量
.{SVCNAME}_SERVICE_HOST
.{SVCNAME}_SERVICE_PORT
注意 : 如果SVCNAME 中使用了链接线,则kubernetes会在定义为环境变量时将其转换为下划线
2 docker link 形式的环境变量
Docker使用–link 选项实现容器链接时所设置的环境变量形式,在创建POD对象时,kubernetes会将与此形式兼容的一系列环境变量注入POD对象中。
查看之前创建的POD的环境变量
1 进入POD
kubectl exec -it service-demo-7677648c64-m4nqh -- /bin/bash
查看
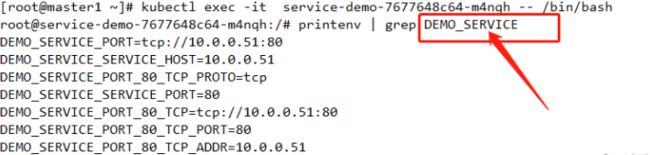
其中DEMO_SERVICE 是之前创建的service的名称,其以DEMO_SERVICE_SERVICE开头的是kubernetes service资源的环境变量
基于环境变量的服务发现其功能简单,已用,但存在局限,仅有那些与创建POD对象在同一名称空间中且实现存在的service对象的信息才能以环境变量的形式入驻,那些处于非同一名称空间或者在POD资源创建之后创建的service对象的相关环境变量则不会被添加。
2 cluster DNS
kubernetes上用于名称解析和服务发现的clusterDNS
是集群的核心附件之一,集群中创建的每个service对象,都会有其自动生成相关资源记录,默认情况,集群中各POD对象会自动配置clusterDNS
作为其名称解析服务器,并在其DNS搜索列表中包含其所属的名称空间的域名后缀。
不管是使用clusterDNS还是coreDNS,其提供的DNS的服务发现解决方案都会负责解析下面资源类型以实现服务发现。
1 拥有clusterIP的service资源,具有下面类型的资源记录
A 记录: <service>.<ns>.svc.<zone>.<ttl> IN A <cluster-ip>
SRV记录: <port>.<proto>.<service>.<ns>.svc.<zone>.<ttl> IN SRV <weight> <priority><port-number><service>.<ns>.svc.<zone>
PTR记录:<d>.<c>.<b><a>.in-addr.arpa.<ttl> IN PTR <service>.<ns>.svc.<zone>
2 headless 类型的service 资源
A 记录 : <service>.<ns>.svc.<zone>.<ttl> IN A <endpoint-ip>
SRV 记录 : <port>.<proto>.<service>.<ns>.svc.<zone>.<ttl> IN <weight><priority> <port-number> <hostname>.<ns>.svc.<zone>
PTR 记录:<d>.<c>.<b>.<a>.in-addr-arpa.<ttl>IN PTR <hostname>.<service>.<ns>.svc.<zone>
3 externalName 类型资源的service资源,具有CNAME类型的资源记录 。
CNAME 记录: <service>.<ns>.svc.<zone>.<ttl> IN CNAME <extname>
名称解析和服务发现是kubernetes系统需要功能得以实现的基础服务,其通常是集群安装完成应该部署的附加组件,使用kubeadm 初始化一个集群时,其会自动部署。
3 DNS
创建service资源对象时,clusterDNS 会自动创建资源记录用于名称解析和服务注册。POD可直接使用其DNS 访问service资源,每个service对象相关的DNS 记录如下:
.{SVCNAME}.{NAMESPACE}.{CLUSTER_DOMAIN}
.{SVCNAME}.{NAMESPACE}.svc.{CLUSTER_DOMAIN}
--cluster-dns 指定了集群DNS服务的工作地址
--cluster-domino 定义了集群使用的本地域名。因此系统初始化默认会将"cluster.local."和主机所在的域"ilinux.io."作为DNS的本地域使用,这些信息会在POD创建时以DNS配置的相关信息注入它的/etc/resolv.conf 配置文件中
查看

{NAMESPACE}.svc.{CLUSTER_DEMAIN}: 如 default.svc.cluster.local
svc.{CLUSTER_DOMAIN}: 如 svc.luster.local
{CLUSTER_DOMAIN}: 如 cluster.local
{WORK_NODE_DOMAIN}: 如上述未定义
4 服务暴露
默认的service 的IP默认是在集群内部可达,但若需要外部访问,则需要进行处理
1 service类型
1 clusterIP : 集群内部可达,无法被外部客户端访问,创建service的默认访问类型
2 NodePort:建立在clusterIP之上(集群上的NODE节点+端口)均和访问到。
3 loadbalancer:在NodePort之上,通过cloud provider提供的负载均衡器将服务暴露到集群外部,因此loadbalancer具有NodePort和clusterIP。一个loadbalancer类型的service会指向关联至kubernetes集群外部的,切实存在的某个负载均衡设备,该设备通过工作节点上的NodePort 向集群内部发送请求流量,其优势在于能够把来自集群外部客户端的请求调度至所有节点的NodePort 之上,而不是依赖于客户端自动决定链接至那个节点,从而避免了因客户端指定的节点故障而导致的服务不可用。
4 externalName: 通过将service映射到映射至由externalName字段的内容指定的主机名来暴露服务,此主机名需要被DNS服务解析成CNAME 类型的记录,其无clusterIP 和 Noport,也没有标签选择器,因此没endpoints ,其是一个域名,是CNAME结构,集群内部的域名。
具体详尽实例见前篇博客内容
三. ingress资源应用
1 概述
kubernetes 提供了两种内建的负载均衡机制,一种是位于传输层的TCP/IP service资源,其实现的是TCP负载均衡器,另一种是ingress资源,其实现的是HTTP(S)负载均衡器。
TCP负载均衡器
iptables 和 ipvs均实现的是四层调度,其不能基于URL 的请求调度机制,其也不支持为此类负载均衡配置任何类型的健康检查机制。
2 ingress 和 ingress controller
ingress 是kubernetes API 的标准资源类型之一,其其实是一组基于DNS名称或URL路径把请求转发至service资源的规则,用于将集群外部的请求流量转发至集群内部完成服务发布,ingress 资源自身并不能进行"流量穿透" ,其仅仅是一组路由规则的集合,这些规则要发挥相应的作用,则需要ingress controller,其可监听套接字,然后给据这些规则的匹配机制路由请求流量。
注意 :ingress 不同于deployment,其不是直接运行与kube-controller-manager的一部分,其是kubernetes集群的一个重要附件,需要单独安装才能使用。
ingress 控制器可以由任何具有反向代理(http/https)功能的服务器程序实现,如nginx、envoy、haproxy、vulcand和traefik等,ingress控制器自身也是运行与集群中的POD资源对象,其与北代理的运行的POD资源的应用运行于同一网络中。
另外: ingress控制器可基于ingress资源定义的规则将客户端请求流量直接转发到service对应的后端POD资源上,其会绕过service资源,省去了kube-proxy实现的端口代理开销。