机器学习中常见的最优化算法_最常见的机器学习算法

机器学习中常见的最优化算法
Here you will learn about list of machine learning algorithms for beginners.
在这里,您将了解初学者的机器学习算法列表。
Hello there everyone! Hope you all are doing well. Today we are among you once again with another article on Machine Learning. We already have covered the introduction part and how to setup your environment for ML, so moving on in this very section we will be discussing on different algorithms that are being used widely in the ML domain. Without investing much of our time here, let’s get started.
大家好! 希望大家一切都好。 今天,我们再一次与您一同出现在机器学习上。 我们已经介绍了部分,以及如何为ML设置环境,因此在本节中,我们将讨论在ML域中广泛使用的不同算法。 在这里不花很多时间,让我们开始吧。
机器学习算法的类型 (Types of Machine Learning Algorithms)
Usually there exist three broader categories of ML algorithms containing several other algorithms within them. Here we will be discussing all of them one by one. Come let us have better insights over them.
通常,存在三种更广泛的ML算法类别,其中包含其他几种算法。 在这里,我们将一一讨论它们。 来吧,让我们对它们有更好的见解。
Three basic algorithms mentioned above are the Supervised Learning, Unsupervised Learning and Reinforcement Learning. Now let us get a grasp over all three of them one by one.
上面提到的三种基本算法是监督学习, 无监督学习和强化学习。 现在让我们一一掌握所有这三个方面。
1.监督学习 (1. Supervised Learning)
This is a group of algorithms in which an algorithm consist of a target variable (also called dependent variable) which needs to be predicted form the set of independent variables (predictors). The independent variable that we have in our dataset is used to generate a function that can be used to map the input data to the desired outputs.
这是一组算法,其中算法由目标变量(也称为因变量)组成,需要从一组独立变量(预测变量)中进行预测。 我们在数据集中拥有的自变量用于生成一个函数,该函数可用于将输入数据映射到所需的输出。
The training of the machine to produce the desired output goes on and on until and unless a satisfactory level of output’s efficiency is achieved.
对机器进行训练以产生所需输出的过程一直持续进行,直到并且除非达到令人满意的输出效率水平。
Some examples of Supervised Learning are:
监督学习的一些示例是:
- Regression 回归
- Logistic Regression 逻辑回归
- Random Forest 随机森林
- Decision Tree 决策树
- KNN etc. KNN等
Note: The independent variables mentioned above are the attributes that you can see in your dataset: the columns, and dependent variable is that column that represents the result (outcome). The training data only contains the independent variables for training the machine and the dependent variable is produced at the later stage.
注意:上面提到的自变量是您可以在数据集中看到的属性:列,因变量是代表结果(结果)的列。 训练数据仅包含用于训练机器的自变量,因变量在稍后阶段产生。
Here we have provided a dataset for your reference: Dataset.
在这里,我们提供了一个数据集供您参考: Dataset 。
Though we have also mentioned some sources in our previous article where you can find your desired datasets.
尽管我们在上一篇文章中也提到了一些资源,但是您可以在其中找到所需的数据集。
2.无监督学习 (2. Unsupervised Learning )
This very algorithm approach is different from Supervised approach as the algorithms here do not have and dependent/target variable or we can say these algorithms do not have anything to predict/estimate.
这种算法方法与有监督方法不同,因为此处的算法没有自变量/目标变量,或者我们可以说这些算法没有什么可预测/估计的。
These algorithms are basically used for the clustering purpose of the population in different groups.
这些算法基本上用于不同群体中人群的聚类目的。
Some examples of Unsupervised Learning are:
无监督学习的一些示例是:
- K-means K均值
- Apriori Algorithm 先验算法
3.强化学习 (3. Reinforcement Learning)
As we have seen and what our motive is in ML, this algorithm also do entertain the basic requirement that the machine is trained to perform specific tasks. The difference here is: machine is exposed to an environment where it learns from past experiences and tries to grasp the best possible way for efficient decision results. This approach involves trial and error.
正如我们所看到的以及ML的动机是什么,该算法也确实满足了对机器进行训练以执行特定任务的基本要求。 此处的区别是:机器处于一种可以从过去的经验中学到并试图掌握可能的最佳方法以获得有效决策结果的环境中。 此方法涉及反复试验。
Some examples of Reinforcement Learning are:
强化学习的一些示例是:
- Markov Decision Process 马尔可夫决策过程
Now as we have discussed the three basic types of algorithms that rule the ML domain, we now need to get some deeper insights over them. So, we are expected to explain all the algorithms that we have mentioned as an example in each of the learning processes and some more very crucial algorithms that you gonna need as a data scientist.
现在,当我们讨论了统治ML域的三种基本算法类型时,我们现在需要对它们进行更深入的了解。 因此,我们希望能够解释在每个学习过程中作为示例提到的所有算法,以及作为数据科学家需要使用的一些非常关键的算法。
重要的机器学习算法 (Important Machine Learning Algorithms)
Here we are going to explain those algorithms that play special roles in the data science and analytics world. So let’s get started quickly.
在这里,我们将解释那些在数据科学和分析领域中发挥特殊作用的算法。 因此,让我们开始快速入门。
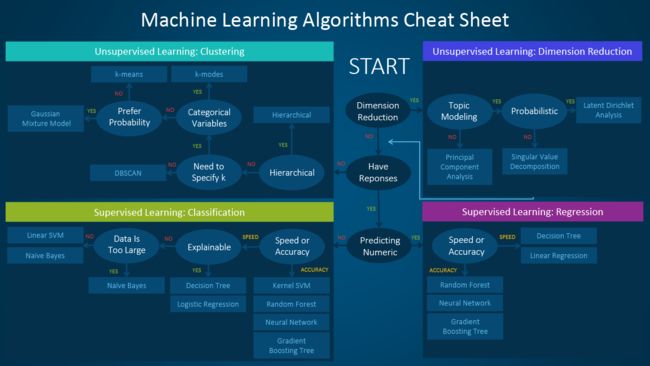
Image Source
图片来源
How to use this Cheat Sheet?
如何使用备忘单?
It is quite simple and easy to understand it’s working and make use of it. Let’s understand how:
理解它的工作原理并加以利用非常简单容易。 让我们了解如何:
Suppose you want to do Probabilistic Dimensionality Reduction then according to the sheet you should go for Latent Dirichlet Analysis.
假设您要进行概率降维,然后根据工作表进行潜在Dirichlet分析。
Isn’t that simple? I’m pretty sure you guys will now be convenient with the use of this sheet, if not please let us know in the comments section, we are here always to help you out.
这不是很简单吗? 我敢肯定,现在使用此表会很方便,如果没有,请在评论部分告诉我们,我们将始终在这里为您提供帮助。
Now let’s very quickly jump to the Algorithms without any further delay:
现在,让我们非常快速地跳转到算法,无需任何进一步的延迟:
1.线性回归 (1. Linear Regression)
Being the simplest among other algorithms LR (Linear Regression) is primarily used for the estimation/prediction of real values. For example: estimating the cost of a house, total sales, etc.
LR(线性回归)是其他算法中最简单的算法,主要用于实值的估计/预测。 例如:估算房屋成本,总销售额等。
In LR the relationship is established between dependent and independent variables with the help of a line called as Best Fit line or Regression line.
在LR中,借助称为最佳拟合线或回归线的线在因变量和自变量之间建立关系。
Best Fit line is represented by a linear equation: Y = m*X + c.
最佳拟合线由线性方程表示: Y = m * X + c 。
Where Y: Dependent Variable
Y:因变量
m: Slope
m:坡度
X: Independent Variable
X:自变量
c: Intercept
c:拦截
The coefficients ‘m’ and ‘c’ are obtained by minimizing the sum of squared difference of the distance between the data points and the best fit line.
系数“ m”和“ c”是通过最小化数据点和最佳拟合线之间的距离的平方差之和而获得的。
Let us understand this with the help of an example:
让我们借助示例了解这一点:
Suppose we are having the best fit line with linear equation: Y = 0.28X + 13.9
假设我们具有带有线性方程的最佳拟合线: Y = 0.28X + 13.9
According to the problem statement we have to find the weight of a person if height is known. And our motive is achieved using the Linear Regression as shown below:
根据问题陈述,如果身高已知,我们必须找到一个人的体重。 我们的动机是通过使用线性回归实现的,如下所示:
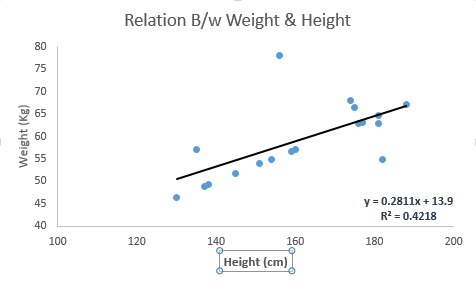
Image Source
图片来源
Linear Regression again is sub-divided into two parts-
线性回归又细分为两个部分:
Simple LR: having single independent variable
简单LR:具有单个自变量
Multiple LR: having more than one independent variable
多个LR:具有多个自变量
2. Logistic回归 (2. Logistic Regression)
Despite of having ‘regression’ in the name, it is a classification algorithm and is primarily used for estimation of the discrete values i.e. 0/1, true/false, etc. from the set of available independent variables.
尽管名称中具有“回归”,但它是一种分类算法,主要用于从可用的独立变量集中估算离散值,即0/1,true / false等。
The main aim of this algorithm is to predict the possibility of occurrence of an event and to achieve this, a function is used called Logit Function. Hence this technique is also being known by the name Logit Regression.
该算法的主要目的是预测事件发生的可能性,并通过使用称为Logit函数的函数来实现此目的。 因此,该技术也被称为Logit Regression。
The visualization in case of Logit Regression will look something like this:
Logit回归情况下的可视化效果如下所示:
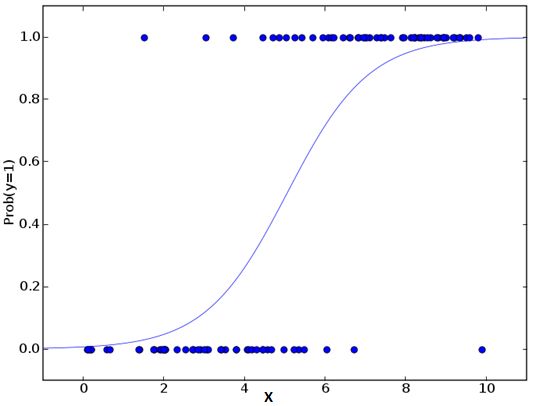
Image Source
图片来源
Some of the steps that are followed by the data scientists to improve the model are:
数据科学家为改善模型而遵循的一些步骤包括:
- Including interaction terms 包括互动条款
- Regularization 正则化
- Using non-linear model 使用非线性模型
- Feature removal 功能删除
3.支持向量机(SVM) (3. Support Vector Machine (SVM))
This algorithm is based on classification approach. In this the data points are plotted as a point in n-dimensional space, where ‘n’ is the number of features in our dataset. The value of each feature is the value of the particular coordinate.
该算法基于分类方法。 在这种情况下,数据点被绘制为n维空间中的一个点,其中“ n”是数据集中特征的数量。 每个要素的值就是特定坐标的值。
Let’s understand this too with an example: Suppose initially we have two features- Hair length and Height (also known as Support Vectors). Since we have only two variables, we would plot them in a two-dimensional space and each of the point will be having two coordinates according to the convention.
让我们也通过一个示例来理解这一点:假设最初我们有两个功能-头发的长度和高度(也称为支持向量 )。 由于我们只有两个变量,因此我们将它们绘制在二维空间中,并且根据约定,每个点将具有两个坐标。

Image Source
图片来源

Image Source
图片来源
The black line in the figure above is splitting the data in to two different groups and as we can see that the two closest points are the one farthest from the line, therefore this line is our Classifier. And the new data is classified solely based in the fact that on which side of the line do testing data lands.
上图中的黑线将数据分为两个不同的组,并且我们可以看到两个最接近的点距离该线最远,因此这条线是我们的分类器。 而且,仅根据测试数据在生产线的哪一侧登陆这一事实对新数据进行分类。
4. K最近邻居(KNN) (4. K-Nearest Neighbors (KNN))
KNN approach ignites dual behaviour i.e. can be used for both regression and classification. On the other hand it is observed and suggested by the data scientists for classification problems. This algorithm has a simple action plan- It accepts all the available cases and classify these cases on the basis of majority of votes from its ‘k’ neighbours. So, the case which is being decided for the class is decided in such a way that it must be common to the k neighbours when measured with the help of distance function.
KNN方法引发双重行为,即可以用于回归和分类。 另一方面,数据科学家对分类问题进行了观察和建议。 该算法有一个简单的行动计划-接受所有可用的案例,并根据其“ k”个邻居的多数票对这些案例进行分类。 因此,要为类别决定的情况以这样的方式决定:在借助距离函数进行测量时,它必须对k个邻居是共有的。
Now let us make this simple to understand by mapping it to our daily lives example: Suppose you want to know about a person you’ve never met before and completely unaware of, then your motive can be fulfilled by enquiring about him/her from the person he/she is in contact with (relate this with k-neighbours). You can take reference from the image below.
现在,让我们通过将其映射到我们的日常生活示例中来使它变得简单易懂:假设您想了解一个从未认识过的人,并且完全不知道,那么您可以通过向他/她询问来实现自己的动机。他/她与之联系的人(与k邻居相关)。 您可以从下图获取参考。
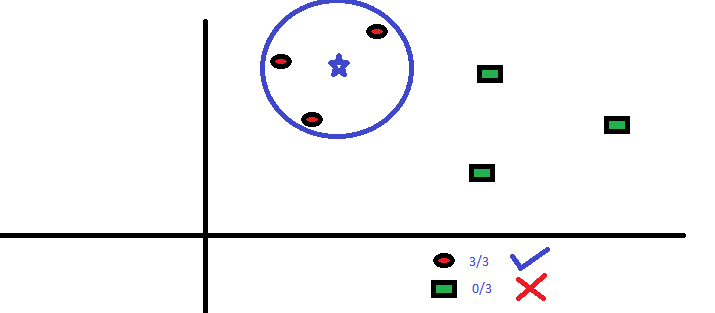
Image Source
图片来源
Dear readers before deciding to opt for K-NN consider these points for better approachability.
亲爱的读者在决定选择K-NN之前,应考虑这些要点,以实现更好的可及性。
- The variables used are required to normalized in order to restrain it from being biased by other variables. 需要使用所使用的变量进行归一化,以防止其受到其他变量的影响。
- It is more oriented towards noise removal, removing outliers, etc. rather than actual work. 它更着重于噪声消除,离群值等,而不是实际工作。
- K-NN is comparatively expensive than other algorithms. K-NN比其他算法昂贵。
5.决策树 (5. Decision Trees)
As theme of this algorithm can be inferred from its name itself that resemble to the trees in data structures. The very similar approach is carried out here too.
该算法的主题可以从其名称本身来推断,该名称类似于数据结构中的树。 这里也执行非常类似的方法。
Decision Tree algorithm to solve the problems is a descendent of Supervised Learning and is one of the favourite among the data scientists and engineer. Though this can be used for both classification and regression but is famous for classification more. In this approach the population is splitted in two or more possible distinct homogeneous sets strictly based on the independent variables.
解决问题的决策树算法是监督学习的后代,是数据科学家和工程师最喜欢的方法之一。 尽管这可以用于分类和回归,但是以分类而闻名。 在这种方法中,严格根据自变量将总体分为两个或更多可能不同的同质集。
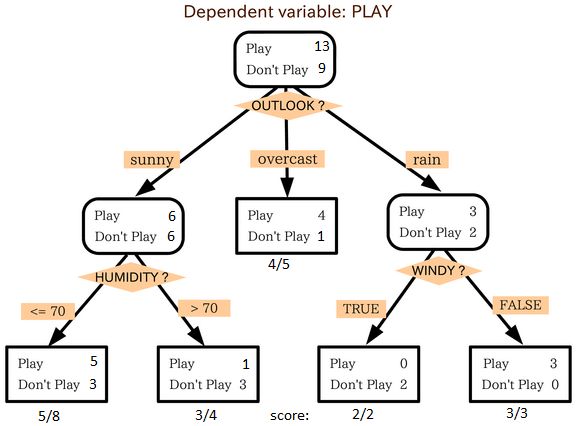
Image Source
图片来源
You can clearly spot in the image above how the population is being splitted based on different independent variables (attributes) to identify ‘if they will play or not.’ Decision tree uses different techniques like chi-square, Information Gain for splitting the population into various groups, to have detailed information on these techniques do refer to this webpage.
您可以在上面的图像中清楚地看到如何根据不同的独立变量(属性)对总体进行拆分,以识别“他们是否愿意参与”。 决策树使用不同的技术(例如卡方,信息增益)将总体分为多个组,有关这些技术的详细信息,请参阅此网页 。
Bonus Tip: to grasp a vivid knowledge on the Decision Trees do refer to a website famous for machine learning and data sciences: Analytics Vidya.
温馨提示:要掌握有关决策树的生动知识,请参考以机器学习和数据科学着称的网站: Analytics Vidya。
6.随机森林 (6. Random Forest)
Random Forest is the broader term used in reference to the decision trees. It is named as Random Forest because of the fact that it is a collection of decision trees. It comes under the Supervised Learning and can be used for the classification as well as regression.
随机森林是指决策树所使用的广义术语。 因为它是决策树的集合,所以被称为随机森林。 它属于“监督学习”类别,可以用于分类和回归。

Image Source
图片来源
For the classification of the new object on the basis of independent variables (attributes), vote is casted from each of the tree for the election of the classification. And the classification with maximum votes from the trees is chosen as visible in the image above.
为了基于自变量(属性)对新对象进行分类,从每个树中进行投票以选择分类。 在上面的图像中,可以看到树木投票最多的分类。
So readers, these were the some (not all) of the most famous machine learning algorithms that we have covered here. In our later blogposts we will be covering Gradient Boosting Algorithms and more. We hope you guys are having a great learning experience with us.
所以读者,这些是我们在这里介绍的一些(不是全部)最著名的机器学习算法。 在以后的博文中,我们将介绍梯度提升算法等。 我们希望你们在我们这里有很好的学习经验。
If there are any queries or suggestions please let us know in the comment section below. Till then have a good day.
如有任何疑问或建议,请在下面的评论部分中告诉我们。 直到有个美好的一天。
翻译自: https://www.thecrazyprogrammer.com/2017/12/machine-learning-algorithms.html
机器学习中常见的最优化算法