第四章 Flink实战之WordCount基础入门
1、Flink开发环境搭建
1.1、创建Maven项目
- 1、选择“File” -->“New”–>“Project”
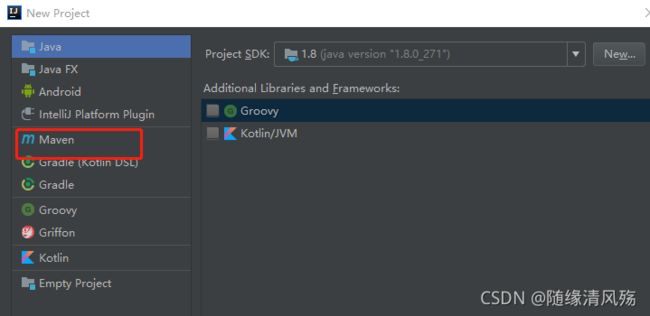
- 2、选择 Maven,设置JDK版本,选择maven项目的模板

org.apache.maven.archetypes:maven-archetype-quickstart
#代表普通的maven项目面板
- 3、设置Groupid和Artifactid
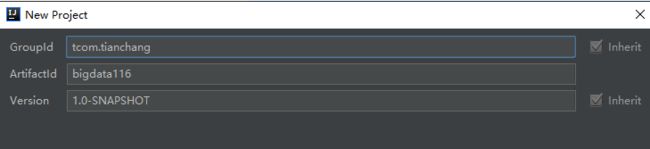
Groupid:公司名称
Artifactid:项目模块
- 4、检查Maven环境,选择”Next“

主要选择maven路径和settings路径
- 5、检查项目名和工作空间,选择finish

- 6、等待项目创建,下载资源,创建完成后目录结构如下

1.2、pom文件配置
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.hainiugroupId>
<artifactId>hainiuflinkartifactId>
<version>1.0version>
<properties>
<java.version>1.8java.version>
<scala.version>2.11scala.version>
<flink.version>1.9.3flink.version>
<parquet.version>1.10.0parquet.version>
<hadoop.version>2.7.3hadoop.version>
<fastjson.version>1.2.72fastjson.version>
<redis.version>2.9.0redis.version>
<mysql.version>5.1.35mysql.version>
<log4j.version>1.2.17log4j.version>
<slf4j.version>1.7.7slf4j.version>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<maven.compiler.compilerVersion>1.8maven.compiler.compilerVersion>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.build.scope>compileproject.build.scope>
<mainClass>com.hainiu.DrivermainClass>
properties>
<dependencies>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>${slf4j.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>${log4j.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-hadoop-compatibility_${scala.version}artifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_${scala.version}artifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-scala_${scala.version}artifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_${scala.version}artifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-runtime-web_${scala.version}artifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-statebackend-rocksdb_${scala.version}artifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-hbase_${scala.version}artifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-elasticsearch5_${scala.version}artifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka-0.10_${scala.version}artifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-filesystem_${scala.version}artifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>${mysql.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>${redis.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.parquetgroupId>
<artifactId>parquet-avroartifactId>
<version>${parquet.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.parquetgroupId>
<artifactId>parquet-hadoopartifactId>
<version>${parquet.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-parquet_${scala.version}artifactId>
<version>${flink.version}version>
<scope>${project.build.scope}scope>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>${fastjson.version}version>
<scope>${project.build.scope}scope>
dependency>
dependencies>
<build>
<resources>
<resource>
<directory>src/main/resourcesdirectory>
resource>
resources>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<descriptors>
<descriptor>src/assembly/assembly.xmldescriptor>
descriptors>
<archive>
<manifest>
<mainClass>${mainClass}mainClass>
manifest>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-surefire-pluginartifactId>
<version>2.12version>
<configuration>
<skip>trueskip>
<forkMode>onceforkMode>
<excludes>
<exclude>**/**exclude>
excludes>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.1version>
<configuration>
<source>${java.version}source>
<target>${java.version}target>
<encoding>${project.build.sourceEncoding}encoding>
configuration>
plugin>
plugins>
build>
project>
2、Flink开发流程
2.1、获取执行环境
2.1.1、批处理环境获取
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
2.1.2、流处理环境获取
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
2.1.3、自动模式
- Flink.12开始,流批一体,自动获取模式 - AUTOMATIC()
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
2.2、创建/加载数据源
2.1.2、从本地文件加载数据源 - 批处理
String path = "H:\\flink_demo\\flink_test\\src\\main\\resources\\wordcount.txt";
DataSet<String> inputDataSet = env.readTextFile(path);
2.1.2、从scoket中读取数据 - 流处理
DataStreamSource<String> elementsSource= env.socketTextStream("10.50.40.131", 9999);
- scoket:
2.1.3、从文件中动态读取数据 - 流处理
DataStream lines = env.readTextFile("file:///path");
2.3、数据转换处理
- 对数据加工转换:扁平化 + 分组 + 聚合
DataSet<Tuple2<String, Integer>> resultDataSet = inputDataSet.flatMap(new MyFlatMapFunction())
.groupBy(0) // (word, 1) -> 0 表示 word
.sum(1);
2.4、数据输出/存储
- 输出位置:输出到文件,输出到控制台,输出到MQ,输出到DB,输出到
scoket…
//print()它会对流中的每个元素都调用 toString() 方法。
resultDataSet.print();
2.5、计算模型

- 获取执行环境(execution environment)
- 加载/创建初始数据集
- 对数据集进行各种转换操作(生成新的数据集)
- 指定将计算的结果放到何处去
- 触发APP执行
3、实战案例
3.1、批处理开发样例
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class WordCount {
public static void main(String[] args) throws Exception {
// 1、创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2、读取数据
String path = "H:\\flink_demo\\flink_test\\src\\main\\resources\\wordcount.txt";
// DataSet -> Operator -> DataSource
DataSet<String> inputDataSet = env.readTextFile(path);
// 3、扁平化 + 分组 + sum
DataSet<Tuple2<String, Integer>> resultDataSet = inputDataSet.flatMap(new MyFlatMapFunction())
.groupBy(0) // (word, 1) -> 0 表示 word
.sum(1);
resultDataSet.print();
}
public static class MyFlatMapFunction implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = input.split(" ");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
}
}
- 运行结果

3.2、流处理开发样例
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamCount {
public static void main(String[] args) throws Exception {
// 1、创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、读取 文件数据 数据
DataStreamSource<String> inputDataStream = env.readTextFile("H:\\flink_demo\\flink_test\\src\\main\\resources\\wordcount.txt");
// 3、计算
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = input.split(" ");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
}).keyBy(0)
.sum(1);
// 4、输出
resultDataStream.print();
// 5、启动 env
env.execute();
}
}
- 运行结果
统计文本:Flink
输出:Flink,1
统计文本:增加Spark
输出:Flink,2 Spark,1
统计文本:新增python
输出:Flink,3 Spark,2 python,1
3.3、流/批不同
流式处理的结果:是不断刷新的,在这个例子中,数据时一行一行进入处理任务的,进来一批处理一批,没有数据就处于等待状态。
4、Flink在Yarn部署
4.1、代码打包
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamCount {
public static void main(String[] args) throws Exception {
// 1、创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、读取 文件数据 数据
//DataStreamSource inputDataStream = env.readTextFile("H:\\flink_demo\\flink_test\\src\\main\\resources\\wordcount.txt");
//2.2、用parameter tool工具从程序启动参数中提取配置项
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
DataStreamSource<String> inputDataStream = env.socketTextStream(host,port);
// 3、计算
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = inputDataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = input.split(" ");
for (String word : words) {
collector.collect(new Tuple2<>(word, 1));
}
}
}).keyBy(0)
.sum(1);
// 4、输出
resultDataStream.print().setParallelism(1);
//打印执行计划图
System.out.println(env.getExecutionPlan());
// 5、启动 env
env.execute();
}
}
- 先编译后打包

4.2、通过UI界面部署到集群
(1)将jar包上传到flink集群
- Flink-ui界面 -》submit new job -》Add New

(2)配置参数
entry class:入口类
program Arguments:入口参数
parallelism:并行度,作业提交job时,如果代码没有配,以全局并行度为准,没有以此并性都为准,没有,以全局并行度为准
savapoint path:保存点,从之前存盘的地方启动

(3)运行结果
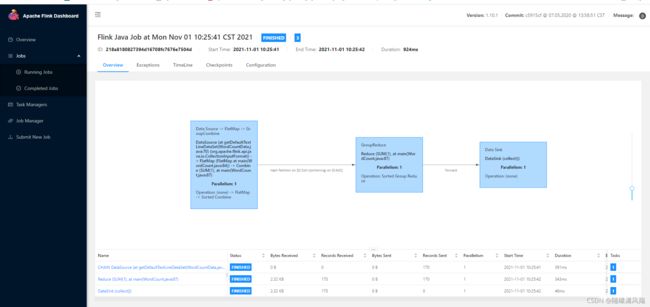
5、疑难杂症
5.1、maven的Plugin文件爆红
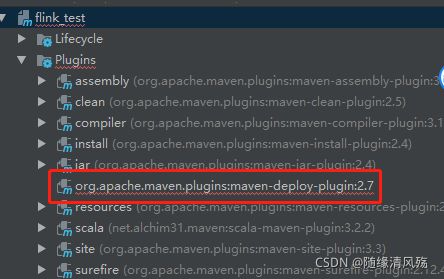
- 解决方式 - 设置maven为本地maven库
New -> Settings -> maven

6.2、Flink Web UI截面提交时显示Server reponse message

- 解决方式
vim {flink_home}/log
![]()