指令集及流水线基本概念
1地址总线、数据总线和机器字长
1.1 数据总线
数据总线DB(DataBus)用于传送数据信息。数据总线是双向三态形式的总线,即它既可以把CPU的数据传送到存储器或输入输出接口等其它部件,也可以将其它部件的数据传送到CPU。
1.2 地址总线
地址总线AB(Address Bus;又称位址总线) 属于一种电脑总线 (一部份),是由CPU 或有DMA 能力的单元,用来沟通这些单元想要存取(读取/写入)电脑内存元件/地方的实体位址。
地址总线AB是专门用来传送地址的,由于地址只能从CPU传向外部存储器或I/O端口,所以地址总线总是单向三态的,这与数据总线不同。地址总线的位数(宽度)决定了CPU可直接寻址的内存空间大小,即决定有多少的内存可以被存取。
1.3 机器字长
机器字长是指CPU一次处理数据的宽度,我们通常所说的“32位CPU”、“64位CPU”中的“32”、“64”就是机器字长。机器字长主要由运算器、寄存器决定,通常寄存器长度等于机器字长。如32位处理器,每个寄存器能存储32bit数据,加法器支持两个32bit数据进行相加。
目前嵌入式处理器大都以32位为主,32位处理器的地址总线通常都是32位,可寻址范围是4Gbyte,地址总线越宽,可寻址范围越大。通常数据总线的带宽都要高于机器字长,32位处理器很多都采用64bit、128bit的数据带宽,这样可以一次读取更多的数据。
2 机器语言和指令集
2.1 机器语言
语言主要包括以下要素:
1.词汇。一个词汇代表一个意象片段,每个词汇与某事物一一对应。
2.语法。包括格式、结构和规则。
3.语句。词汇按照一定的语法规则有机组合形成语句。
4.语义。亦即动机性,即维特根斯坦说的语言中训练的部分。它包括词汇的表意和语句的含义,表达信息或操作命令。
CPU不认识汇编语言,更不认识C/C++等高级语言,它只认识机器语言。计算机数字逻辑电路只认识以高低电平或者开关通断状态信号来量化的二进制0和1,因此机器语言都是基于二进制的编码序列。
在远古时代,只能使用机器语言编程。当程序需要被运行时,程序员需要将他写的程序写入到存储设备上,最原始的存储设备就是纸带,即在纸带上打相应的孔。每个孔代表一位,穿孔表示0,未穿孔表示1,这些孔序列汇编成机器语言,由译码器(扫描器)识别。计算机运算完毕,需要人工翻译结果。
二进制机器码太难记了,可以想见打孔编程的工作是多么的枯燥和乏味。于是人们发明了汇编语言,使用人类语言的单词作为助记符与机器码建立一一对应关系。汇编器维护了这张映射表,并在汇编阶段将汇编代码翻译成指令机器码。从大的方面讲,汇编是相当简单的,它只是使用助记符号替代对应的机器码元。
下表列出了MIPS32中汇编指令add/and与机器码的对应关系。
ASM
31-26
25-21
20-16
15-11
10-6
5-0
add d,s,t
0
s
t
d
0
32
and d,s,t
0
s
t
d
0
36
MIPS有32个通用寄存器(编码占5bit),所有指令都是32位(无Intelx86那样的可变长指令),3操作数运算指令的操作数只能是寄存器。
“add d,s,t”和“and d,s,t”都属于3寄存器算术/逻辑运算指令组,域31-26为6位长的主操作码“op”,add和and共享op域,都为0;域5-0为子操作码域,用于区分add(32)和and(36)。25-21为第一个源操作数寄存器s的编码;20-16为第二个源操作数寄存器t的编码;15-11为目的操作数寄存器d的编码。
2.2 指令集
在机器语言中,指令就是一个语句。指令格式为“操作码域+操作数域”,操作码域指明了指令的操作性质及功能,操作数域则给出了操作数或操作数的地址。操作码和操作数是机器可识别的词汇,包括“操作命令”、“内存地址”、“字节”、“寄存器”,它们组合在一起的机器指令体现语义。不同类型的操作命令和操作数,具有不同的组合表现形式。
指令集(IA:InstructionSet)是指CPU指令系统所能识别(翻译)执行的全部指令的集合。处理器要完成计算任务,需要具备以下几种指令类型。
(1)运算指令
运算由运算器单元(ALU)实现,指令包括算术运算指令、逻辑运算指令和移位指令。
算术运算指令实现加减乘除(+-*/)等基本的算术运算;逻辑运算指令实现与或非(&|~)等基本的逻辑运算;移位指令实现二进制比特位(bit)的左右移(<<>>)运算。
(2)控制指令
除了做计算外,CPU还要实现循环。循环是由跳转指令实现的,跳回去执行就是循环。循环在一定条件下跳出,否则就成死循环了,条件跳转指令能完成这个功能。条件跳转指令在一定条件下实现跳转,它能实现分支功能。跳转指令也称为控制指令。控制由CPU控制器单元实现。
(3)数据传送指令
运算和控制指令的操作数从哪里来的呢?操作数都放在存储器中。在x86 IA中,运算指令的操作数既可以是寄存器,也可以是存储器;而在其他RISCIA例如MIPS中,运算指令的操作数只能是寄存器,因此需要先使用加载(load)指令将存储器中的数据导入到寄存器中,运算完成后,再用存储(store)指令将寄存器中的运算结果数据导出到存储器中。这类指令就是数据传送指令。
有了这三类指令,CPU就能完成各种复杂的运算。
2.3 CISC和RISC
处理器的指令集可简单分为两种:复杂指令集(CISC,Complex InstructionSet Computer)和精简指令集(RISC,Reduced Instruction Set Computer)。
(1)指令集的演进
一开始的处理器都是CISC架构,随着时间的演进,有越来越多的指令集加入。采用复杂指令系统的计算机有着较强的处理高级语言的能力,这对提高计算机的性能是有益的。当计算机的设计沿着这条道路发展时,有些人没有随波逐流,他们回过头去看一看过去走过的道路,开始怀疑这种传统的做法:IBM公司设在纽约Yorktown的JhomasI.Wason研究中心于1975年组织力量研究指令系统的合理性问题。因为当时已感到,日趋庞杂的指令系统不但不易实现,而且还可能降低系统性能。
1979年以帕特逊教授为首的一批科学家也开始在美国加册大学伯克莱分校开展这一研究,结果表明,CISC存在许多缺点。首先,在这种体系架构中,各种指令的使用频率相差悬殊:一个典型程序的运算过程所使用的80%指令只占一个处理器指令系统的20%,剩余80%的指令则只占整个程序的20%。事实上最频繁使用的指令是取、存和加这些最简单的指令。于是帕特逊教授提出了精简指令集的理念,主张指令系统应当只包含那些使用频率很高的少量指令,较为复杂的指令则利用常用的简单指令去组合。按照这个原则发展而成的计算机被称为精简指令集计算机(Reduced Instruction Set Computer)结构,简称RISC。
在设计理念上,RISC的设计重点在于降低由硬件执行指令的复杂度,因为软件比硬件容易提供更大的灵活性和更高的智能,因此RISC设计对编译器有更高的要求;CISC的设计则更侧重于硬件执行指令的功能,使CISC的指令变得很复杂。总之RISC对编译器的要求高,CISC强调硬件的复杂性,CPU的实现更复杂。CISC提供了很多微码支持,使得汇编程序的工作量减少,而RISC完成同样的操作则需要更多的指令。
(2)RISC与CISC的比较
<1>指令集——RISC处理器减少指令集的种类,只提供固定长度的简单指令,大多都在四五个周期内完成,通常一个周期执行一条指令。
<2>寄存器——RISC的寄存器拥有更多的通用寄存器,寄存器操作较多,例如MIPS提供了32个通用寄存器,ARM提供了27个通用寄存器,CISC的寄存器都是用于特定目的的。
<3>内存访问——处理器只处理寄存器中的数据,运算指令的操作数只能是寄存器。这是因为访问存储器很耗时,同时对外部存储器的读写会影响其寿命;CISC能够在存储器中直接运行。对内存变量的直接访存不利于流水线实现,因此RISC没有实现可以操作内存变量的指令。RISC内存引用总是通过load指令将内存变量加载到寄存器,通过store指令将寄存器中的值写回到内存,大型寄存器堆使得这不会成为一个大问题。
<4>简化的寻址方式——RISC不像CISC那样的复杂众多的寻址方式。例如MIPS只有一种数据寻址模式,几乎所有的加载和存储的内存地址都是通过单个基址寄存器的值加上一个16位的有符号偏移量来选择。
<5>高效的流水线特性——流水线的本质就是CPU并行运行,只是并行运行不像FPGA中的那么直接,它只是把一条指令分成几个更小的执行单元;CISC指令的执行需要调用一个微码,明显没有RISC的指令吞吐量大。
固定的指令长度、大型寄存器堆和load/store结构可充分发挥流水线特性。在并行处理方面RISC明显优于CISC,RISC可同时执行多条指令,它可将一条指令分割成若干个进程或线程,交由多个处理器同时执行。由于RISC执行的是精简指令集,所以它的制造工艺简单且成本低廉。
<6>子程序调用——在CISC中,程序调用返回时需要将上下文保存到堆栈中,push/pop指令需要访问内存操作;而RISC没有提供push/pop支持,将它们存放在寄存器中,而且参数也是用寄存器传递。RISC中断可视为特殊的子程序调用:CISC发生中断时,所有的寄存器内容都被压入堆栈中,而RISC对中断进行区分对待,分为轻量级和重量级。对于轻量级中断只保存需要保存的寄存器内容;对于重量级中断的处理如同常规中断。
<7>RISC的缺点——代码密度不高,可执行文件体积较大,汇编代码可读性差。代码密度不高是值得关注的问题:若不使用cache,会需要更大的指令存储控件,取指时也占用更大的内存带宽;若采用cache,又会降低cache的命中率。而从CPU的设计上来讲,由于RISC的核心代码要少很多,使得其结构相应简化,因此在体积、造价、功耗、散热和价格上都具有优势。
<8>CISC与RISC的融合演进
从以上的比较来看,RISC与CISC各有千秋,由于RISC具有更强的实用性,故应该是未来处理器的发展方向。但事实上,当今时代wintel一统江湖,且早期很多软件都是根据CISC设计的,单纯的RISC将无法兼容。此外,现代CISC结构的CPU已经融合了很多RISC的成分,其性能差距已经越来越小。复杂指令可以提供更多的功能,这是程序设计所需要的。例如ARM提供了DSP& SIMD扩展:增强型DSP指令(E变种)和媒体功能扩展(SIMD变种)。因此,CISC与RISC的融合应该是未来的发展方向。
(3)指令集的五朵金花
处理器公司很多,品牌也很多,而指令集则相对稳定,用指令集对处理器公司分类是比较常见的做法。有5种指令集最为常见,它们构成了处理器领域的5朵金花。
<1>x86——硕大的大象
Intel x86是经典的CISC体系结构,它是史上最赚钱的指令集,几乎所有的个人计算机都使用Intel x86指令集的处理器。
英特尔的钟摆策略:在奇数年,英特尔将会推出新的工艺;而在偶数年,英特尔则会推出新的架构。简单的说,就是奇数工艺年和偶数架构年的概念。钟摆策略能够体现英特尔技术变化方向。当有英特尔钟摆往左摆的时候,tick这个策略会更新工艺;往右摆的时候,tock会更新处理器微架构。
<2>ARM——稳扎稳打的蚁群
如果要问哪个指令集的处理器销量最大,很多人会认为是Intel,不过一家来自英国的公司让我们大跌眼镜,这家公司就是ARM公司。
在智能手机领域,ARM(Acorn RISCMachine)独领风骚,占据了手机市场90%以上的份额。当今手机上的应用处理器,不管是高通还是TI的,东芝还是三星的,在内部都采用了ARM内核。
ARM11之后的处理器家族改称为Cortex,并针对高、中、低阶划分为A、R、M三大系列处理器。高阶智能手机普遍采用Coretex-A系列,例如苹果iPhone 4、4s和5所采用的A4/A5/A6处理器,设计结构分别是Cortex-A8/Cortex-A9/非标准ARM,都是基于指令集:ARMv7 (Cortex)。
<3>MIPS——优雅的孔雀
如果要说最经典的RISC处理器,那么非MIPS莫属,就连它的竞争对手,也不得不承认它的优雅,它被作为处理器教科书的典范,很多其他的处理器,都能看到它的身影。
MIPS全称为Microprocessor without Interlocked Piped Stages,无内部互锁流水级的微处理器。中国科学院计算所自主研发的龙芯,采用类似于MIPS的简单指令集。
<4>Power——昔日的贵族
最早提出RISC思想的是IBM公司,PowerPC是一种RISC多发射体系结构。
1990年,IBM推出了高性能的POWER(Performance Optimized With Enhanced RISC)处理器。POWER性能卓越,一直以来都被用在IBM自己的服务器上。1997年与国际象棋大师卡斯帕罗夫交战的深蓝计算机,使用POWER2处理器,2011年参加知识竞赛电视节目“Jeopardy!”挑战人类的Watson计算机,使用的是POWER7处理器。
由于POWER的高性能,IBM想到可以将POWER用于PC领域,因此IBM向Apple抛了橄榄枝,Apple当然求之不得。Apple一直都使用Motorola的处理器,因此Apple又把Motorola拉下了水。这3家公司一拍即合,富有传奇色彩的三大巨头,同时又是在PC时代只能赚吆喝的3个难兄难弟终于结拜在了一起,于1991年成立了AIM联盟(AIM为Apple、IBM、Motorola的3个首字母)。AIM对POWER处理器进行了修改,于是就形成了PowerPC,PC是Performance Computing的缩写。
Apple公司的Macintosh过去十几年来用的是IBM研发的PowerPC处理器,但是苹果于2005年6月宣布终止与IBM和摩托罗拉长期合作关系,放弃PowerPC支持 全面Intel化。苹果CEO史蒂夫·乔布斯(Steve Jobs)指出,转换芯片架构是因为英特尔提供更优越的产品蓝图。
<5>C6000——偏安一隅的独立王国
以上介绍的这些处理器,都是较通用的处理器,还有一种较专业的处理器,它的名字叫DSP(Digital SignalProcessor,数字信号处理器),专业做信号处理运算的。
这几年,全球的无线通信网络建设如火如荼,视频网站、视频通信系统也如雨后春笋般涌现出来,在这些产品或服务的背后,一个是无线通信技术,一个是音视频技术,这二者的共同点在于:它们都需要大量的信号处理运算,而这正是DSP的强项。
20世纪80年代初,Motorola和TI(德州仪器)都推出了自己的手机DSP芯片,Motorola要强于TI,但由于Motorola的芯片只给自己的手机用,诺基亚、爱立信等公司选择了TI,从此成就了TI。
现在的DSP芯片主要由TI、Freescale、LSI等公司推出,TI DSP一家独大,占据绝大部分市场份额。TI也是半导体领域的先驱之一,第一块集成电路的发明人、诺贝尔奖得主Jack Kilby就来自于TI。
C6000系列DSP是TI的高端DSP,C62/C64/C64+是定点DSP内核,C67是浮点DSP内核,C66是定点/浮点融合的内核。
与C6000直接竞争的,是Starcore体系结构,最早由Infineon、Agere、Motorola的合资公司设计,公司经过多年的分与合之后,目前这个体系结构的DSP由Freescale和LSI推出。
3 指令的执行
3.1 通用寄存器
指令的语义主要是完成一定的功能操作,其操作对象就是操作数。在进行运算之前,数据必须就位,那么操作数放在哪里呢?
CPU内部有很多通用寄存器(General Purpose Register),这些寄存器用来存储指令的操作数,它对程序员可见。例如x86有8个通用寄存器,MIPS有32个寄存器。这一堆寄存器也被叫做寄存器堆(Register File)。寄存器一般为SRAM,可将其看做CPU的缓存。
在硬件实现上,算术逻辑运算单元ALU直接访问通用寄存器进行计算。通用寄存器中的数据需要先读到ALU输入寄存器(ALU Input Register)中,ALU运算结束后,数据会存储在ALU输出寄存器(ALU Output Register)中,最后再送回通用寄存器中。
在MIPS中,运算指令的操作数只能是寄存器,因此在执行运算指令之前,调用数据传送指令load将数据从内存加载到通用寄存器中。在x86中一般使用mov指令进行数据传送。
3.2 指令执行过程
指令的执行过程按时间顺序可分为以下几个步骤:
(1)CPU发出指令地址。将指令指针寄存器(IP)的内容——指令地址,经地址总线送入存储器的地址寄存器中。
(2)从地址寄存器中读取指令。将读出的指令暂存于存储器的数据寄存器中。
(3)将指令送往指令寄存器。将指令从数据寄存器中取出,经数据总线送入控制器的指令寄存器中。
(4)指令译码。指令寄存器中的操作码部分送指令译码器,经译码器分析产生相应的操作控制信号,送往各个执行部件。
(5)按指令操作码执行。
(6)修改程序计数器的值,形成下一条要取指令的地址。若执行的是非转移指令,即顺序执行,则指令指针寄存器的内容加1,形成下一条要取指令的地址。指令指针寄存器也称为程序计数器(PC)。
4 流水线作业
4.1 流水线的概念
关于流水线,生活中到处可见,工厂的生产流水线和食堂的打饭流水线都是流水线的经典范例。在《MIPS体系结构透视》中借用食堂打饭流水线的例子很好的阐述了流水线的概念。
所谓流水线(pipeline),就是将那些重复性的工作分解成几个串行的部分,使得工作能在工人中间移动。每个熟练工人只需要依次将他们熟悉的那部分工作做好即可。虽然每个顾客等待服务的总时间有所增加,但是却有四个顾客能同时接受服务,这样在午餐高峰期能够接待的顾客数量增加了三倍。
假如Evie的小卖部新增了一种炸鸡腿,交由Bert负责派发,这样Bert在给顾客派发炸土豆时还得派发炸鸡腿。此时,Bert这一环节相比以前耗时增加,导致流水线效率下降。如是,Evie再请了一个朋友加入食物派发流水线,专门负责派发鸡腿。我们说Evie店的流水线从四步(step)增加到了五步,流水线的级数(深度)增加了一级,相应增加了人力成本。
4.2 CPU指令执行流水线
如果将程序看成是内存中存储的一些指令的话,一个即将运行的程序看起来和排着队等待接受服务的顾客没什么相似之处。但是,在CPU看来,情况就不一样了。CPU从内存中提取每条指令,进行译码,找到所需要的操作数,执行相应操作,并存储运算产生的结果——然后又从头开始重复同样的工作。这样等待执行的程序就是一个指令的序列,该队列中一次只有一条指令经过CPU。
由于每条指令要做不同的工作,因此在CPU内部已经配有各种不同的专用的大块逻辑电路(每一流水阶段都有独立的逻辑电路来处理),所以构造一个流水线并没有使CPU复杂度增加多少,只是让CPU工作得更努力一些而已。
采用流水线技术后,并没有加速单条指令的执行,每条指令的操作步骤一个也不能少,只是多条指令的不同操作步骤同时执行,因而从总体上看加快了指令流速度,缩短了程序执行时间。
为了进一步满足普通流水线设计所不能适应的更高时钟频率的要求,高档次处理器中的流水线的深度(级数)在逐代增多。当流水线深度在5~6级以上时,通常称为超流水线结构(SuperPipeline)。显然,流水线级数越多,每级所花的时间越短,时钟周期就可以设计的越短,指令速度越快,指令平均执行时间也就越短,但是相应设计成本也会增加。
在TI C6000 DSP中,所有指令的执行大概分为Fetch(取指)、Decode(译码)、Execute(执行)三个大的步骤,每个大的步骤又可以细分为一些小的步骤,实现了更深的流水线。
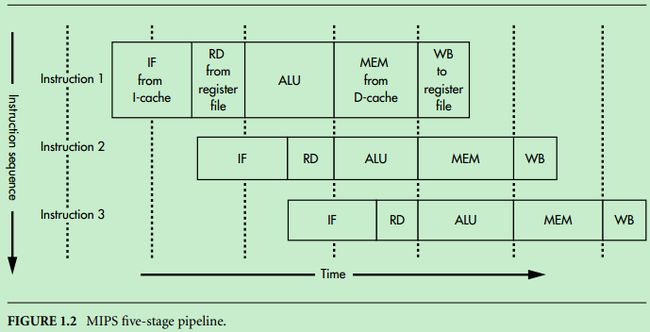
4.3 MIPS经典五级流水线
(1)MIPS的五级流水线
MIPS体系架构依据流水线结构设计。只要CPU从缓存中获取数据,那么执行每条MIPS指令就被分成五个流水阶段,并且每个阶段占用固定的时间,通常是只耗费一个处理器时钟周期。RD/WB操作只占用半个时钟周期,故MIPS五段流水线只占用四个时钟周期。
MIPS处理器在设计时,将处理器的执行阶段划分为以下五个阶段:
<1> IF:Instruction Fetch,取指。从指令缓存(I-Cache)中获取下一条指令。
<2> ID(RD):InstructionDecode(Read Register),译码(读寄存器)。翻译指令,识别操作码和操作数,从寄存器堆中读取数据到ALU输入寄存器。
<3> EX(ALU):Execute,执行(算术/逻辑运算)。在一个时钟周期内,完成算术或逻辑操作。注意,浮点算术运算和整数乘除运算不能在一个时钟周期内完成。
<4> MEM:Memory Access,内存数据读或者写。在该阶段,指令可以从数据缓存(D-Cache)中读/写内存变量。平均来说,大约四分之三的指令在这一阶段没有执行任何操作,为每条指令分配这个阶段是为了保证同一时刻不会有两条指令都访问数据缓存。
<5> WB:Write Back,写回。操作完成后,将计算结果从ALU输出寄存器写回到通用寄存器中。
对于运算指令,在MEM阶段空闲。对于load指令,在EX阶段计算要访问的地址,在MEM阶段从内存中将数据读入到MEMregister(MEM和WB之间的流水线寄存器)中,在WB阶段,将MEM register的数据写回到Register File中。对于store指令,在EX阶段计算要访问的地址,在MEM阶段将寄存器中的数据写回到存储器中。
(2)流水线和缓存
高效的流水线操作要求每个阶段占用相同的时间。高效的流水线还依赖于高速缓存(Cache),可以将内存访问速度提高50倍左右。当CPU需要数据时,首先在缓存中查找,如果该数据在缓存中则命中,那么缓存很快就把数据返回给CPU。由于无法猜测CPU将使用什么数据,故缓存仅存储最近一段时间内CPU从主内存中获取的数据副本。如果缓存缺失(没有命中),则需要重填(Invalidate and Refill)。
x86的寄存器个数很少,所以同样的程序编译给x86会比MIPS使用多得多的数据存取操作。当然,x86使用堆栈来代替寄存器给这些额外存取使用,这些堆栈位置将是内存中使用非常频繁的区域,对应高速缓存的使用效率非常高。
MIPS体系架构设计时采用了独立的指令缓存和数据缓存,这样CPU就可以同时获取指令和读写内存变量。
(3)严格流水线的限制
RISC(Reduced Instruction Set Computing,精简指令集)相对CISC(Complex Instruction Set Computing,复杂指令集)对指令集作了巧妙和有效的规定,从而使得流水线可以高效和成功的实现。所有的MIPS指令都经过严格的定义,以遵循同样的流水线阶段顺序,即使这些指令在某个流水线阶段什么也不做。于是最终结果是:只要CPU保持从缓存中命中(hit)数据,就能在每个时钟周期开始一条指令。
流水线的严格要求限制了指令的某些操作能力。
首先,要求所有的指令一样长(刚好是一个机器字长32位),这样的指令可以在固定时间被读取。定长指令的要求限制了操作的复杂程度。比如,在指令中没有足够的位空间对真正复杂的寻址模式进行编码。定长指令直接导致的一个问题就是,一个典型的程序在支持变长指令的x86体系架构上,编译后其指令平均长度只有3个字节,在MIPS代码中则全部是4个字节,从而占用了更多的内存空间。通常MIPS二进制文件要比680x0或80x86二进制文件大20%~30%。
第二,MIPS中的指令操作必须符合流水线特性。指令操作只有在正确的流水线阶段才能够执行,并且必须在一个时钟周期内执行完毕。比如,寄存器写回阶段只允许一个值存储到寄存器堆,因此这些MIPS指令只能修改一个寄存器的值。出栈操作需要将两个值(栈中的数据以及递增的栈指针值)写回到寄存器中,因此它不适合流水线。所以,MIPS没有提供对栈操作的硬件支持,没有x86那样的push/pop指令。
第三,流水线的设计规则没有实现可以操作内存变量的指令。缓存或者内存的数据只有在流水线的第四阶段才能够获得。对于ALU而言,这些数据来得太迟了。内存访问仅通过简单的load/store指令来将数据导入或导出寄存器。