Go语言的函数和defer用法
目录
函数的基本用法
函数中的变长参数
递归函数(recursion)
函数是“一等公民”
函数中defer的用法
defer的底层原理
使用 defer 跟踪函数的执行过程
defer的注意事项
(1)Go语言内置的函数中哪些可以作为deferred 函数
(2)注意 defer 关键字后面表达式的求值时机
(3)注意defer 带来的性能损耗
函数的基本用法
Go 语言中的函数可以使用和其它编程语言类似的方式定义,也可以将函数设置为一个变量,具体用法如下面的代码所示:
package main
import "fmt"
func main() {
/* 函数的定义 */
caclResult1 := cacl1(1, 2) // 3
fmt.Println(caclResult1)
//声明一个类型为函数类型的变量,直接写在一个已有的函数里面
var cacl2 = func(a int, b int) int {
return a + b
}
fmt.Println(cacl2(1, 2)) // 3
//多返回值
if caclResult3, errMsg := cacl3(-1, 2); errMsg == "" {
fmt.Println(caclResult3)
} else {
fmt.Println(errMsg) //a或者b不能小于0
}
/* 指针运算 */
var num = 1
ptr(&num)
fmt.Println(num) //2
}
// 定义函数的传统方式,指定一个int类型的返回值
func cacl1(a int, b int) int {
return a + b
}
// 函数支持多返回值
func cacl3(a int, b int) (int, string) {
if a < 0 || b < 0 {
return -1, "a或者b不能小于0"
}
return a + b, ""
}
// 为每个返回值声明变量名,这种带有名字的返回值被称为具名返回值
func cacl4(a int, b int) (result int, errMsg string) {
if a < 0 || b < 0 {
errMsg = "a或者b不能小于0"
return
}
result = a + b
return
}
// 指针运算
func ptr(n *int) {
*n++
}多个参数具有相同类型放在一起,可以只写一次类型:
package main
import "fmt"
func main() {
fmt.Println(Fun("A", "B", "C", -1)) //15 16 你好
}
func Fun(a, b, c string, d int) (x, y int, z string) {
x = 15
y = 16
z = "你好"
return
//return 15, 16, "你好" // 这样也可以
}Go 语言中的函数参数不管使用哪种数据类型都是值传递,也就是把实际参数的内存表示拷贝到了形式参数中。对于整型、数组、结构体 类型作为实参时,值传递拷贝的就是它们自身,传递的开销也与它们自身的大小成正比。但是 string、切片、map 这些类型作为实参时,值传递拷贝的是它们数据内容的“描述符”,不包括数据内容本身,所以这些类型传递的开销是固定的,与数据内容大小无关。这种只拷贝“描述符” 而不拷贝实际数据内容的拷贝过程就是 “浅拷贝”。
package main
import "fmt"
func main() {
/* Go 语言中的函数参数不管使用哪种数据类型都是值传递,是对数据进行一个拷贝, 但是具体分为引用类型和非引用类型 */
arr1 := [4]int{1, 2, 3, 4}
fmt.Println(arr1) //[1 2 3 4]
fun1(arr1)
fmt.Println(arr1) //[1 2 3 4]
println()
s1 := []int{1, 2, 3, 4}
fmt.Println(s1) // [1 2 3 4]
fun2(s1)
fmt.Println(s1) //[100 2 3 4]
}
func fun1(arr [4]int) {
arr[0] = 100
}
func fun2(sli []int) {
sli[0] = 100
}函数声明中的 func 关键字、参数列表和返回值列表共同构成了函数类型。而参数列表与返回值列表的组合也被称为函数签名,它是决定两个函数类型是否相同的决定因素。
因此,函数类型也可以看成是由 func 关键字与函数签名组合而成的。 如果两个函数类型的函数签名是相同的,即便参数列表中的参数名,以及返回值列表中的返回值变量名都是不同的,那么这两个函数类型也是相同类型。比如下面两个函数类型都是func (int, string) ([]string, error),因此它们是相同的函数类型。
func (a int, b string) (results []string, err error)
func (c int, d string) (sl []string, err error)函数中的变长参数
先来一个简单的例子感受一下可变长参数:
package main
import "fmt"
func main() {
fmt.Println(Sum(1, 2)) // 3
fmt.Println(Sum(1, 2, 3, 4)) // 10
fmt.Println(Sum(1, 2, 3, 4, 5, 6, 7)) // 28
//向可变长函数中传入一个切片,需要加上...
sli := []int{1, 2, 3, 4, 5}
fmt.Println(Sum(sli...)) //15
}
// 可变长参数入门,对多个数求和运算
func Sum(ops ...int) int {
ret := 0
for _, op := range ops {
ret += op
}
return ret
}Go语言支持形参传递变长参数,在具体的数据类型前面加上 ... 表示,比如:...int,...string 等。变长参数实际上是通过切片来实现的,所以在函数体中就可以使用切片支持的所有操作来操作变长参数,这会大大简化了变长参数的使用复杂度。需要注意,如果函数中既有普通参数又有可变参数,那么可变参数需要放在最后面,并且一个函数的参数列表中最多只能有一个可变参数。
package main
import "fmt"
func main() {
//myAppend
sl := []int{1, 2, 3}
sl = myAppend(sl) // no elems to append
fmt.Println(sl) // [1 2 3]
sl = myAppend(sl, 4, 5, 6)
fmt.Println(sl) // [1 2 3 4 5 6]
}
// 对于为变长参数的形参,Go 编译器会将零个或多个实参按一定形式转换为对应的变长形参
func myAppend(sl []int, elems ...int) []int {
fmt.Printf("%T\n", elems) // 输出变长参数的类型: []int, //变长参数实际上是通过切片来实现的
if len(elems) == 0 { //可以用切片的len()获取变长参数的个数
fmt.Println("no elems to append")
return sl
}
sl = append(sl, elems...)
return sl
}
递归函数(recursion)
一个函数自己调用自己,就叫做递归函数,递归函数要有一个退出的条件,否则就是死循环。
package main
import "fmt"
func main() {
/* 递归函数:计算斐波那契数列 */
fmt.Println(getFibonacci(12)) //144
}
func getFibonacci(n int) int {
if n == 1 || n == 2 {
return 1
}
return getFibonacci(n-1) + getFibonacci(n-2)
}函数是“一等公民”
为什么这么说?因为在Go语言中,函数可以存储在变量中,可以作为参数传递给函数,可以在函数内部创建并可以作为返回值从函数返回,因此可以被称为是“一等公民”。
(1)Go 函数可以存储在变量中,这种函数就是匿名函数;此时这个变量可以作为参数传递给其他函数,也可以拥有自己的类型。
package main
import (
"fmt"
)
// 把函数存储到一个变量中
var (
userId = 100
userData = func(username string, age int32) string { //这个函数就是个匿名函数,顾名思义,就是没有名字的函数
return fmt.Sprintf("用户名:%v,年龄:%d", username, age)
}
)
func main() {
fmt.Printf("%T \n", userData) //获取类型: func(string, int32) string
userInfo := fmt.Sprintf("用户ID: %v, 其它信息: %v", userId, userData("zhangsan", 18))
fmt.Println(userInfo) //用户ID: 100, 其它信息: 用户名:zhangsan,年龄:18
}(2)可以基于函数创建一个自定义类型,创建后的类型就是函数类型
type MyUserData func(float64, bool)(3)Go 函数不仅可以在函数外创建,还可以在函数内创建,函数也可以作为函数的参数和返回值(有点绕?细品!)
package main
import (
"fmt"
)
func main() {
getUserFunc("test") //getUserFunc: test ---
println()
getUserFunc("test")() //getUserFunc: test --- getUserFunc里面的func: test
println()
}
// 在函数内创建函数
func getUserFunc(username string) func() {
fmt.Print("getUserFunc: ", username, " --- ")
return func() {
fmt.Print("getUserFunc里面的func: ", username)
}
}再举个例子,比如有一个函数,要计算它的执行耗时,可以这么写:
package main
import (
"fmt"
)
func main() {
fmt.Println(timeCost(slowFun)(10))
}
func timeCost(myFunc func(num int) int) func(num int) int {
return func(n int) int {
start := time.Now()
ret := myFunc(n)
fmt.Println("time cost: ", time.Since(start).Seconds(), " 秒")
return ret
}
}
func slowFun(num int) int {
time.Sleep(time.Second * 1)
return num * num
}
怎么样,看到这里是不是对Go语言中的函数有点兴趣了?是不是有点渐入佳境的感觉?或者是更迷惑了?没关系,多看几次就清晰了。
(4)Go 语言中的闭包是在函数内部创建的匿名函数,这个匿名函数可以访问创建它的函数的参数与局部变量。
假设要实现一个监控告警的例子:根据不同的告警规则,触发不同渠道的不同紧急程度的告警。
告警支持多种通知渠道,包括:邮件、微信、语音电话。
通知的紧急程度有多种类型,包括:严重、紧急、普通。
package main
import "fmt"
func main() {
//传统的定义函数调用
fmt.Println(alarm("邮件", "严重"))
fmt.Println(alarm("邮件", "紧急"))
fmt.Println(alarm("邮件", "普通"))
fmt.Println(alarm("微信", "严重"))
fmt.Println(alarm("微信", "紧急"))
fmt.Println(alarm("微信", "普通"))
println("------------")
//使用闭包函数调用
email := myAlarm("邮件")
fmt.Println(email("严重"))
fmt.Println(email("紧急"))
fmt.Println(email("普通"))
weixin := myAlarm("微信")
fmt.Println(weixin("严重"))
fmt.Println(weixin("紧急"))
fmt.Println(weixin("普通"))
}
func alarm(messageType string, messageDegree string) string {
return fmt.Sprintf("消息类型:%v, 重要程度:%v", messageType, messageDegree)
}
func myAlarm(messageType string) func(string) string {
return func(messageDegree string) string {
return alarm(messageType, messageDegree)
}
}
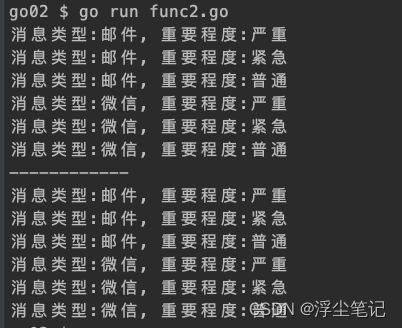
可以看到,两种方式输出的结果是一样的,第二种方式可以减少参数的重复输入。但是,你是否会觉得这样的简化程度意义不大?实际上这只是个简单的易于理解的例子,在很多复杂的场景下这种方式能起到很好的优化作用。这里的案例场景借鉴了我之前写的一篇文章:PHP设计模式之桥接模式_浮尘笔记的博客-CSDN博客
函数中defer的用法
一般在连接数据库并操作数据之后都会释放连接,比如在PHP中可能会写在 析构函数(__destruct)中销毁资源;或者又比如PHP中的 try...catch语句后面的 finally语句最终都会执行。类似的,Go 语言提供的 defer 是一种延迟调用机制,只有在函数和方法内部才能使用 defer。无论是执行到函数尾部返回,还是在某个错误处理分支显式 return,又或是出现 panic,已经存储到 deferred 函数栈中的函数都会被调度执行。简单地说:defer函数就是用来“收尾”的(例如清理资源、释放锁等)。举个例子:
package main
import "fmt"
func main() {
fmt.Println("数据库已连接")
defer closeDB()
fmt.Println("执行数据库查询...")
panic("不小心写错了SQL语句...")
fmt.Println("Unreachable code")
}
func closeDB() {
fmt.Println("数据库连接已关闭")
}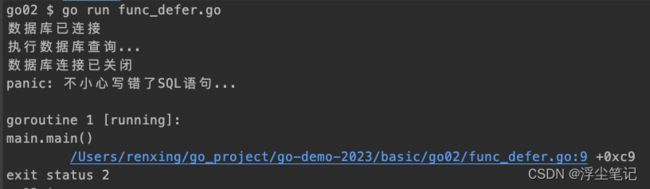
这里释放数据库函数的 defer 紧邻着数据库连接成功的动作,这样成对出现就可以很大程度降低遗漏释放资源的情况,代码的可读性也提高了。
defer的底层原理
defer 将函数或方法注册到其所在的 Goroutine 中,这些 deferred 函数将在执行 defer 的函数退出前按后进先出(LIFO)的顺序被调度执行,也就是“栈”,如下图所示:

使用 defer 跟踪函数的执行过程
按照上面defer的底层原理是个“栈”的逻辑,可以使用defer实现一个函数调用栈,跟踪函数的执行过程,代码如下:
package main
// 使用 defer 跟踪函数的执行过程
func main() {
defer Trace("main")()
foo()
}
func Trace(name string) func() {
println("enter:", name)
return func() {
println("exit:", name)
}
}
func foo() {
defer Trace("foo")()
bar()
}
func bar() {
defer Trace("bar")()
}
可以看到, 程序按 main -> foo -> bar 的函数调用次序执行,并且逐层返回。但是仔细看还是有一些“瑕疵”的,如下:
- 调用 Trace 时需手动显式传入要跟踪的函数名;
- 如果是并发应用,不同 Goroutine 中函数链跟踪混在一起无法分辨;
- 输出的跟踪结果缺少层次感,调用关系不易识别;
- 对要跟踪的函数,需手动调用 Trace 函数。
因此可以做一些优化,参考:https://www.cnblogs.com/rxbook/p/17397888.html
defer的注意事项
(1)Go语言内置的函数中哪些可以作为deferred 函数
扩展:Go 语言内置的函数如下 append cap close complex copy delete imag len make new panic print println real recover
var c chan int
var sl []int
var m = make(map[string]int, 10)
m["item1"] = 1
m["item2"] = 2
var a = complex(1.0, -1.4)
var sl1 []int
defer append(sl, 11)
defer cap(sl)
defer close(c)
defer complex(2, -2)
defer copy(sl1, sl)
defer delete(m, "item2")
defer imag(a)
defer len(sl)
defer make([]int, 10)
defer new(*int)
defer panic(1)
defer print("hello, defer\n")
defer println("hello, defer")
defer real(a)
defer recover()
从这组错误提示中可以看到: append、cap、len、make、new、imag 等内置函数都是不能直接作为 deferred 函数的,而 close、copy、delete、print、recover 等内置函数可以设置为 deferred 函数。
其实,对于不能直接作为 deferred 函数的内置函数,可以使用一个包裹它的匿名函数来间接实现,以 append 为例:
var slx []int
defer func() {
_ = append(slx, 11)
}()(2)注意 defer 关键字后面表达式的求值时机
defer 关键字后面的表达式,是在将 deferred 函数注册到deferred 函数栈的时候进行求值的。什么意思?看下面的例子:
package main
import "fmt"
func main() {
fmt.Print("testA result:")
testA()
println()
fmt.Print("testB result:")
testB()
println()
fmt.Print("testC result:")
testC()
println()
}
func testA() {
for i := 0; i <= 3; i++ {
defer fmt.Print(i, " ")
}
//输出 testA result:3 2 1 0
/*每当 defer 将fmt.Print 注册到 deferred 函数栈的时候,都会对 Print 后面的参数进行求值。依次压入 deferred 函数栈的函数是:
fmt.Print(0)
fmt.Print(1)
fmt.Print(2)
fmt.Print(3)
因此,当 testA 返回后,deferred 函数被调度执行时,上述压入栈的 deferred 函数将以LIFO 次序出栈执行,这时的输出的结果为:3,2,1,0
*/
}
func testB() {
for i := 0; i <= 3; i++ {
defer func(n int) {
fmt.Print(n, " ")
}(i)
}
//输出 testB result:3 2 1 0
/*每当 defer 将匿名函数注册到 deferred 函数栈的时候,都会对该匿名函数的参数进行求值。依次压入 deferred 函数栈的函数是:
func(0)
func(1)
func(2)
func(3)
因此,当 testB 返回后,deferred 函数被调度执行时,上述压入栈的 deferred 函数将以LIFO 次序出栈执行,因此输出的结果为:3,2,1,0
*/
}
func testC() {
for i := 0; i <= 3; i++ {
defer func() {
fmt.Print(i, " ")
}()
}
//输出 testC result:4 4 4 4
/* testC 中 defer 后面接的是一个不带参数的匿名函数。依次压入 deferred 函数栈的函数是:
func()
func()
func()
func()
所以,当 testC 返回后,deferred 函数被调度执行时,上述压入栈的 deferred 函数将以LIFO 次序出栈执行。
匿名函数会以闭包的方式访问外围函数的变量 i,并通过 Print 输出i 的值,此时 i 的值为 4,因此 testC 的输出结果为:4,4,4,4
*/
}因此,得到的结论是,无论以何种形式将函数注册到 defer 中,deferred 函数的参数值都是在注册的时候进行求值的。
(3)注意defer 带来的性能损耗
先写一段测试代码,分别使用defer和不使用defer,对比一下执行开销:
package main
import "testing"
func sum(max int) int {
total := 0
for i := 0; i < max; i++ {
total += i
}
return total
}
func fooWithDefer() {
defer func() {
sum(10)
}()
}
func fooWithoutDefer() {
sum(10)
}
// 测试带有 defer 的函数执行的性能
func BenchmarkFooWithDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
fooWithDefer()
}
}
// 测量不带有 defer 的函数的执行的性能
func BenchmarkFooWithoutDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
fooWithoutDefer()
}
}
使用Benchmark(性能基准测试)可以直观地看到 defer 会带来多少性能损耗,运行命令和结果如下:
go02 $ go test -bench . func_defer_test.go
goos: darwin
goarch: amd64
cpu: Intel(R) Core(TM) i5-5250U CPU @ 1.60GHz
BenchmarkFooWithDefer-4 143286962 8.390 ns/op
BenchmarkFooWithoutDefer-4 227384844 5.267 ns/op
PASS
ok command-line-arguments 3.793s可以看到 带有 defer 的函数执行开销大概是不带 defer 的函数的执行开销的 1.6 倍左右(不同的机器运行的效果也不一样),因此可以放心使用。
需要注意的是,在 Go 1.13 前的版本中,使用 defer 的函数的执行时间是没有使用 defer 函数的 8 倍左右,如果你用的是Go 1.13 之前的版本一定要留意。
源代码:https://gitee.com/rxbook/go-demo-2023/tree/master/basic/go02