Python 统计Zabbix监控告警表报统计
一.需求与分析
1.需要每周分析下系统告警汇总信息,加图表展示。
2.思路:调用zabbix api 获取,查询zabbix数据库的alters表来获取。
二.实现方法
1.核心部分是查询数据库提取告警次数,告警级别
坑就是很多网上发的sql是无法准确或者无法提取告警级别,告警次数的。
Trigger: Free disk space is less than 20% on volume /
Trigger status: PROBLEM
Trigger severity: Warning
Trigger URL:
Item values:
1. Free disk space on / (percentage) (prod_zhongyi002:vfs.fs.size[/,pfree]): 19.51 %
2. *UNKNOWN* (*UNKNOWN*:*UNKNOWN*): *UNKNOWN*
3. *UNKNOWN* (*UNKNOWN*:*UNKNOWN*): *UNKNOWN*
Original event ID: 28211677
恢复OK, 主机:Zabbix server: Too many processes running on Zabbix server已恢复!
告警主机:Zabbix server
告警时间:2020.07.22 04:08:57
告警等级:Warning
告警信息: Too many processes running on Zabbix server
告警项目:proc.num[,,run]
问题详情:Number of running processes:65
当前状态:OK:65
事件ID:28190140由上图sql中的message字段可以得出以下:
select from_unixtime(clock,'%Y-%m-%d') as time,
count(DISTINCT eventid) as id
from alerts
WHERE mediatypeid = 5
AND message LIKE '%Average%' #severity 过滤告警级别
AND message LIKE '%PROBLEM%' #status 过滤故障次数
AND SUBJECT LIKE '%PROBLEM%'
AND clock BETWEEN UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 7 DAY)) AND UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 1 DAY))
group by time
order by time asc

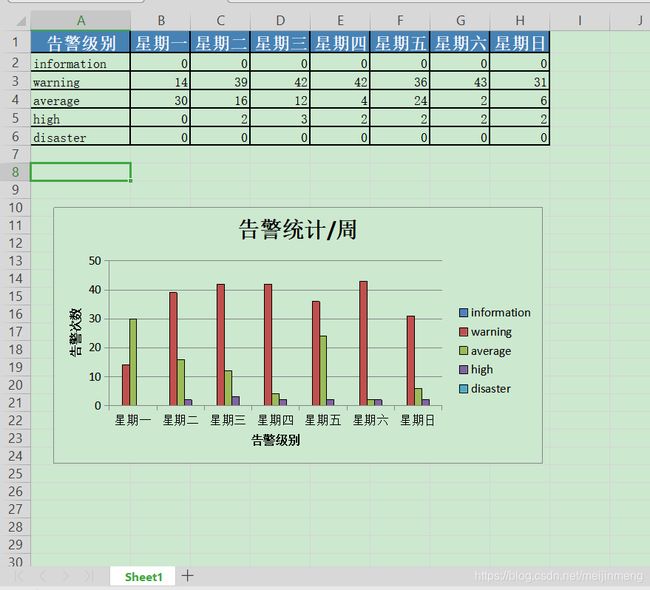
2.代码部分:生产excel文件,展示图表
【定时发送邮件可以自己配置】
# encoding:UTF-8
import xlsxwriter
import datetime
import pymysql
import numpy as np
import pandas
__author__ = 'jmmei'
__data__ = '2020/07/22'
averagesql = """
select from_unixtime(clock,'%Y-%m-%d') as time,
count(DISTINCT eventid) as id
from alerts
WHERE mediatypeid = 5
AND message LIKE '%Average%'
AND message LIKE '%PROBLEM%'
AND SUBJECT LIKE '%PROBLEM%'
AND clock BETWEEN UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 7 DAY)) AND UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 1 DAY))
group by time
order by time asc
"""
highsql = """
select from_unixtime(clock,'%Y-%m-%d') as time,
count(DISTINCT eventid) as id
from alerts
WHERE mediatypeid = 5
AND message LIKE '%PROBLEM%'
AND message LIKE '%High%'
AND SUBJECT LIKE '%PROBLEM%'
AND clock BETWEEN UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 7 DAY)) AND UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 1 DAY))
group by time
order by time asc
"""
warningsql = """
select from_unixtime(clock,'%Y-%m-%d') as time,
count(DISTINCT eventid) as id
from alerts
WHERE mediatypeid = 5
AND message LIKE '%PROBLEM%'
AND message LIKE '%Warning%'
AND SUBJECT LIKE '%PROBLEM%'
AND clock BETWEEN UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 7 DAY)) AND UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 1 DAY))
group by time
order by time asc
"""
informationsql = """
select from_unixtime(clock,'%Y-%m-%d') as time,
count(DISTINCT eventid) as id
from alerts
WHERE mediatypeid = 5
AND message LIKE '%PROBLEM%'
AND message LIKE '%Information%'
AND SUBJECT LIKE '%PROBLEM%'
AND clock BETWEEN UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 7 DAY)) AND UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 1 DAY))
group by time
order by time asc
"""
disastersql = """
select from_unixtime(clock,'%Y-%m-%d') as time,
count(DISTINCT eventid) as id
from alerts
WHERE mediatypeid = 5
AND message LIKE '%PROBLEM%'
AND message LIKE '%Diasater%'
AND SUBJECT LIKE '%PROBLEM%'
AND clock BETWEEN UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 7 DAY)) AND UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 1 DAY))
group by time
order by time asc
"""
#连接MySQL数据库
def get_count(sql):
'''
#zabbix数据库信息:
zdbhost = 'www.csdn.net'
zdbuser = 'python_test'
zdbpass = '123456'
zdbport = 3306
zdbname = 'zabbix'
'''
conn=pymysql.connect("www.csdn.net", "python_test", "123456", "zabbix", charset='utf8')
cursor = conn.cursor()
#print("===============cursor:",cursor,type(cursor))
cursor.execute(sql)
count = cursor.fetchall()
# 将rows转化为数组
#print("=================count:",count)
rows = np.array(count)
#print("============rows:",rows)
conn.close()
return count
def coloum(data, weekendtime):
#创建一个excel文件
workbook = xlsxwriter.Workbook(weekendtime +".xlsx")
#创建一个工作表,默认sheet1
worksheet = workbook.add_worksheet()
bold = workbook.add_format({'bold': 1})
#表头
title = ['告警级别', '星期一','星期二','星期三','星期四','星期五','星期六','星期日']
#列名
buname = ['information', 'warning','average', 'high', 'disaster']
# 定义数据formatter格式对象,设置边框加粗1像素
formatter = workbook.add_format()
formatter.set_border(2)
#定义格式:# 定义标题栏格式对象:边框加粗1像素,背景色为灰色,单元格内容居中、加粗,标题字体颜色
title_formatter = workbook.add_format()
title_formatter.set_border(2)
title_formatter.set_bg_color('#4682B4')
title_formatter.set_align('center')
title_formatter.set_bold()
title_formatter.set_color("#F8F8FF")
title_formatter.set_font_size(14)
chart_col = workbook.add_chart({'type': 'column'})
def chart_series(row):
chart_col.add_series(
{
'categories': '=Sheet1!$B$1:$H$1',
'values': '=Sheet1!$B${}:$H${}'.format(row, row),
'line': {'color': 'black'},
# 'name': '=Sheet1!$A${}'.format(row)
'name': '=Sheet1!$A$' + row
}
)
# 下面分别以行和列的方式将标题栏、业务名称、流量数据写入单元格,并引用不同的格式对象
worksheet.write_row('A1',title,title_formatter)
worksheet.write_column('A2',buname,formatter)
for i in range (2,7):
worksheet.write_row('B{}'.format(i),data[i-2],formatter)
print (i)
chart_series(str(i))
# 设置图表的title 和 x,y轴信息
chart_col.set_title({'name': '告警统计/周'})
chart_col.set_x_axis({'name': '告警级别'})
chart_col.set_y_axis({'name': '告警次数'})
# 设置图表的风格
#chart_col.set_style(9)
# 把图表插入到worksheet以及偏移
worksheet.insert_chart('A10', chart_col, {'x_offset': 25, 'y_offset': 10})
workbook.close()
#判断二维元组是否为空,长度是否满足要求,不满足则补0.
#输入为一个字典,判断是否为空,空则添加数据
def covertdata(jsondata,weektime):
listkey = list(jsondata.keys())
for i in weektime:
j = i.strftime("%Y-%m-%d")
if listkey:
if j not in listkey:
jsondata[j] = "0"
else:
jsondata[j] = "0"
#print ("jsondata:>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>",jsondata)
#按照时间对字典进行排序
sort = sorted(jsondata.items(), key=lambda d: d[0])
#将第二列取出来并转为列表
array = np.array(sort)
array2 = array[:, 1]
list2 = array2.tolist()
list3 = list(map(lambda x: float(x), list2))
#print("list2:>>>>>>>>>>>>>>>", list2)
#print("list3:>>>>>>>>>>>>>>>", list3)
return list3
if __name__ == '__main__':
yesterday = (datetime.date.today() + datetime.timedelta(days=-1)).strftime("%Y-%m-%d")
print(yesterday)
weeklist = pandas.date_range(end=yesterday, periods=7)
informationdata = get_count(informationsql)
informationlist = covertdata(dict(informationdata),weeklist)
warningdata = get_count(warningsql)
warninglist = covertdata(dict(warningdata),weeklist)
averagedata = get_count(averagesql)
averagelist = covertdata(dict(averagedata),weeklist)
highdata = get_count(highsql)
highlist = covertdata(dict(highdata),weeklist)
disasterdata = get_count(disastersql)
disasterlist = covertdata(dict(disasterdata),weeklist)
print (informationlist)
print (warninglist)
print (averagelist)
print (highlist)
print (disasterlist)
data1 = [informationlist, warninglist, averagelist, highlist, disasterlist]
coloum(data1,yesterday)
三.效果展示