paddleOCR服务端安装部署二:paddleOCR hubserving 服务安装配置
intro
PaddleOCR提供2种服务部署方式:
- 基于PaddleHub Serving的部署:代码路径为"
PaddleOCR/deploy/hubservingg" 已集成到PaddleOCR中(code) - 基于PaddleServing的部署:代码路径为"
./deploy/pdserving" 详见PaddleServing官网demo, 尚未集成到PaddleOCR。
我们这里用的就是第一种HubServing啦~
当前用户在训练出一个可用的模型后,可以选择如下四种部署应用方式:
- 服务器端高性能部署:将模型部署在服务器上,利用服务器的高性能帮助用户处理推理业务
- 模型服务化部署:将模型以线上服务的形式部署在服务器或云端,用户通过客户端请求发送需要推理的输入内容,服务器或者云通过相应报文将推理结果返回给用户(paddle serving)
- 移动端部署:将模型部署在移动端上,例如手机/物联网的嵌入式端
- Web端部署:将模型部署在网页上,用户通过网页完成推理业务
Paddle Serving作为paddlepaddle开源的在线服务框架
服务部署下包括 检测、识别、检测+识别串联 三种服务包,根据需求选择相应的服务包进行安装和启动
deploy/hubserving/
└─ ocr_det 检测模块服务包
└─ ocr_rec 识别模块服务包
└─ ocr_system 检测+识别串联服务包 <==== 我们直接这个,包括先检测然后识别
每个服务包下包含3个文件。以检测+识别串联 目录为例,目录如下:
deploy/hubserving/ocr_system/
└─ __init__.py 空文件,必选
└─ config.json 配置文件,可选,使用配置启动服务时作为参数传入
└─module.py 主模块,必选,包含服务的完整逻辑
└─params.py 参数文件,必选,包含模型路径、前后处理参数等参数
具体步骤(ocr_system 检测+识别串联)
1. 准备环境
# 安装paddlehub
pip3 install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
这一部分因为我们是部署在离线服务器上的,这部分内容放到 xxxx 里了
但如果有网的话,就很简便用 pip就好
2. 从git clone/下载下来整个PaddleOCR项目
我们是离线,就直接下载的压缩包,然后将压缩包解压到任意你想放的位置。
目录大概是这样
3.下载推理模型
下载/使用自己的推理模型并放到正确路径,包括:
-
在PaddleOCR(也就是刚刚解压的目录下面)目录里
mkdir inference创建 inference 目录 -
从PaddleOCR提供的模型库下载以下三个模型压缩包
检测模型:ch_ppocr_server_v2.0_det_infer.tar 识别模型:ch_ppocr_server_v2.0_rec_infer.tar 方向分类器:ch_ppocr_mobile_v2.0_cls_infer -
把压缩包上传到Paddle/inference目录里,解压
-
检查一下解压出来的目录中,是否包含以下内容
./inference/ch_ppocr_server_v2.0_det_infer/ └─ inference.pdiparams └─ inference.pdiparams.info └─ inference.pdmodel ./inference/ch_ppocr_server_v2.0_rec_infer/ └─ ._inference.pdiparams └─ inference.pdiparams └─ ._inference.pdiparams.info └─ inference.pdiparams.info └─ ._inference.pdmodel └─ inference.pdmodel ./inference/ch_ppocr_mobile_v2.0_cls_infer/ └─ inference.pdiparams └─ inference.pdiparams.info └─ inference.pdmodel
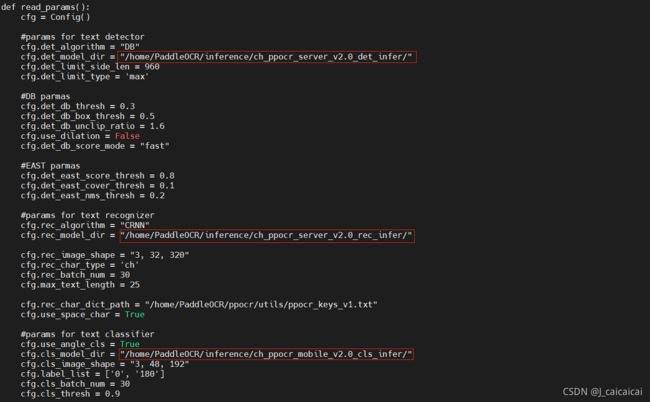
4. 修改参数文件params.py中的模型路径
因为我们这里是安装部署ocr_sysyem,所以就去改ocr_system的就ok啦。
ocr_system参数文件路径:PaddleOCR/deploy/hubserving/ocr_system/params.py
修改以下部分:
5. 安装服务模块
PaddleOCR提供3种服务模块,根据需要安装所需模块。(这里我们是安装的ocr_system)
在 PaddleOCR 这个目录(aka 你上一步创建然后压缩出来的文件夹)下运行
安装检测服务模块:
hub install deploy/hubserving/ocr_det/
或,安装识别服务模块:
hub install deploy/hubserving/ocr_rec/
或,安装检测+识别串联服务模块:
hub install deploy/hubserving/ocr_system/ <=== 这个这个♀️
这样就算成功
启动服务
方式1. 命令行命令启动(仅支持CPU)
启动命令:
$ hub serving start --modules [Module1==Version1,Module2==Version2,...] \
--port XXXX \
--use_multiprocess \
--workers \
参数:
| 参数 | 用途 |
|---|---|
| –modules/-m | PaddleHub Serving预安装模型,以多个Module==Version键值对的形式列出 当不指定Version时,默认选择最新版本 |
| –port/-p | 服务端口,默认为8866 |
| –use_multiprocess | 是否启用并发方式,默认为单进程方式,推荐多核CPU机器使用此方式 Windows操作系统只支持单进程方式 |
| –workers | 在并发方式下指定的并发任务数,默认为2*cpu_count-1,其中cpu_count为CPU核数 |
例如启动我们刚刚部署的检测+识别串联服务: hub serving start -m ocr_system
方式2. 配置文件启动(支持CPU、GPU)
启动命令:
hub serving start -c config.json
其中,config.json格式如下:
{
"modules_info":{
"ocr_system":{
"init_args":{
"version":"1.0.0",
"use_gpu": true
},
"predict_args":{
}
}
},
"port":8868,
"use_multiprocess": false,
"workers":2
}
init_args中的可配参数与module.py中的_initialize函数接口一致。其中,当use_gpu为true时,表示使用GPU启动服务。predict_args中的可配参数与module.py中的predict函数接口一致。
注意:
- 使用配置文件启动服务时,其他参数会被忽略。
- 如果使用GPU预测(即,
use_gpu置为true),则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,如:export CUDA_VISIBLE_DEVICES=0,否则不用设置。 use_gpu不可与use_multiprocess同时为true。
发送预测请求
配置好服务端,可使用以下命令发送预测请求,获取预测结果:
python tools/test_hubserving.py server_url image_path
需要给脚本传递2个参数:
- server_url:服务地址,格式为
http://[ip_address]:[port]/predict/[module_name]
例如,如果使用配置文件启动检测、识别、检测+识别2阶段服务,那么发送请求的url将分别是:
http://127.0.0.1:8866/predict/ocr_det
http://127.0.0.1:8867/predict/ocr_rec
http://127.0.0.1:8868/predict/ocr_system - image_path:测试图像路径,可以是单张图片路径,也可以是图像集合目录路径
这里我挂起服务之后用对本机请求测试了一下示例:
python tools/test_hubserving.py http://127.0.0.1:8868/predict/ocr_system ./doc/imgs/
找张有文字的图片传到服务器上,路径写在image_path参数位置
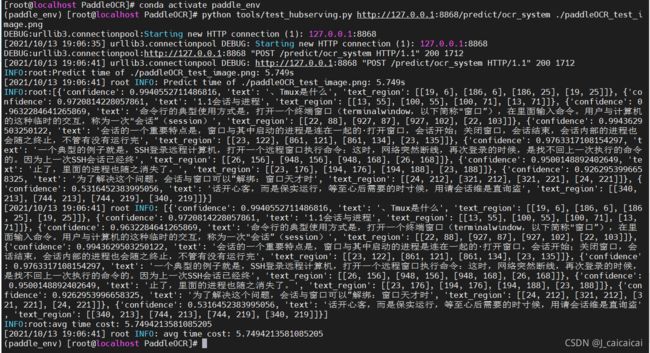
返回结果格式说明
返回结果为列表(list),列表中的每一项为词典(dict),词典一共可能包含3种字段,信息如下:
| 字段名称 | 数据类型 | 意义 |
|---|---|---|
| text | str | 文本内容 |
| confidence | float | 文本识别置信度 |
| text_region | list | 文本位置坐标 |
不同模块返回的字段不同,如,文本识别服务模块返回结果不含text_region字段,具体信息如下: