高频面试题之JVM灵魂拷问,21题带你通关!
这是本期的 JVM面试题目录,不会的快快查漏补缺~

1. 什么是JVM内存结构?

jvm将虚拟机分为5大区域,程序计数器、虚拟机栈、本地方法栈、java堆、方法区;
-
程序计数器:线程私有的,是一块很小的内存空间,作为当前线程的行号指示器,用于记录当前虚拟机正在执行的线程指令地址;
-
虚拟机栈:线程私有的,每个方法执行的时候都会创建一个栈帧,用于存储局部变量表、操作数、动态链接和方法返回等信息,当线程请求的栈深度超过了虚拟机允许的最大深度时,就会抛出StackOverFlowError;
-
本地方法栈:线程私有的,保存的是native方法的信息,当一个jvm创建的线程调用native方法后,jvm不会在虚拟机栈中为该线程创建栈帧,而是简单的动态链接并直接调用该方法;
-
堆:java堆是所有线程共享的一块内存,几乎所有对象的实例和数组都要在堆上分配内存,因此该区域经常发生垃圾回收的操作;
-
方法区:存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码数据。即永久代,在jdk1.8中不存在方法区了,被元数据区替代了,原方法区被分成两部分;1:加载的类信息,2:运行时常量池;加载的类信息被保存在元数据区中,运行时常量池保存在堆中;
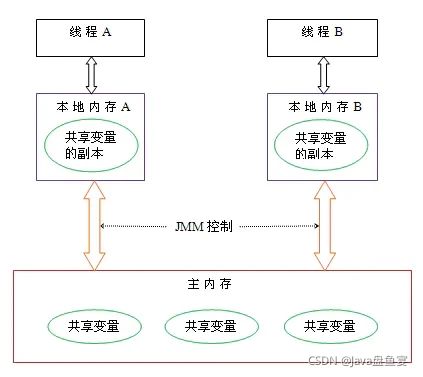
2. 什么是JVM内存模型?
Java 内存模型(下文简称 JMM )就是在底层处理器内存模型的基础上,定义自己的多线程语义。它明确指定了一组排序规则,来保证线程间的可见性。
这一组规则被称为 Happens-Before , JMM 规定,要想保证 B 操作能够看到 A 操作的结果(无论它们是否在同一个线程),那么 A 和 B 之间必须满足 Happens-Before 关系 :
-
单线程规则:一个线程中的每个动作都 happens-before 该线程中后续的每个动作
-
监视器锁定规则:监听器的 解锁 动作 happens-before 后续对这个监听器的 锁定 动作
-
volatile 变量规则:对 volatile 字段的写入动作 happens-before 后续对这个字段的每个读取动作
-
线程 start 规则:线程 start() 方法的执行 happens-before 一个启动线程内的任意动作
-
线程 join 规则:一个线程内的所有动作 happens-before 任意其他线程在该线程 join() 成功返回之前
-
传递性:如果 A happens-before B, 且 B happens-before C, 那么 A happens-before C
怎么理解 happens-before 呢?如果按字面意思,比如第二个规则,线程(不管是不是同一个)的解锁动作发生在锁定之前?这明显不对。happens-before 也是为了保证可见性,比如那个解锁和加锁的动作,可以这样理解,线程1释放锁退出同步块,线程2加锁进入同步块,那么线程2就能看见线程1对共享对象修改的结果。
Java 提供了几种语言结构,包括 volatile , final 和 synchronized , 它们旨在帮助程序员向 编译器 描述程序的并发要求,其中:
-
volatile- 保证 可见性 和 有序性
-
synchronized- 保证 可见性 和 有序性 ; 通过**管程(Monitor)* 保证一组动作的* 原子性
-
final- 通过禁止 在构造函数初始化 和 给 final 字段赋值 这两个动作的重排序,保证 可见性 (如果 this 引用逃逸 就不好说可见性了)
编译器在遇到这些关键字时,会插入相应的内存屏障,保证语义的正确性。
有一点需要 注意 的是, synchronized 不保证 同步块内的代码禁止重排序,因为它通过锁保证同一时刻只有 一个线程 访问同步块(或临界区),也就是说同步块的代码只需满足 as-if-serial 语义 - 只要单线程的执行结果不改变,可以进行重排序。
所以说,Java 内存模型描述的是多线程对共享内存修改后彼此之间的可见性,另外,还确保正确同步的 Java 代码可以在不同体系结构的处理器上正确运行。
3. heap 和stack 有什么区别?
(1)申请方式
stack:由系统自动分配。例如,声明在函数中一个局部变量 int b; 系统自动在栈中为 b 开辟空间
heap:需要程序员自己申请,并指明大小,在 c 中 malloc 函数,对于Java 需要手动 new Object()的形式开辟
(2)申请后系统的响应
stack:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
heap:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
(3)申请大小的限制
stack:栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS 下,栈的大小是 2M(默认值也取决于虚拟内存的大小),如果申请的空间超过栈的剩余空间时,将提示 overflow。因此,能从栈获得的空间较小。
heap:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的, 自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见, 堆获得的空间比较灵活,也比较大。
(4)申请效率的比较
stack:由系统自动分配,速度较快。但程序员是无法控制的。
heap:由 new 分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便。
(5)heap和stack中的存储内容
stack:在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址, 然后是函数的各个参数,在大多数的 C 编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
heap:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。