第1章 课堂笔记


class (models.Model): title=models.CharField(max_length=32) price=models.DecimalField(max_digits=6,decimal_places=2) create_time=models.DateField() memo=models.CharField(max_length=32,default="") # book_obj.publish: 与这本书籍关联的出版社对象 publish=models.ForeignKey(to="Publish",default=1) # book_obj.author.all(): 与这本书关联的作者对象集合,Queryset [] author=models.ManyToManyField("Author") def __str__(self): return self.title class Publish(models.Model): name=models.CharField(max_length=32) email=models.CharField(max_length=32) class Author(models.Model): name=models.CharField(max_length=32) def __str__(self):return self.name 基于对象查询(子查询) 一对多 正向查询,按字段 Book-------------------->Publish <--------------------- 反向查询,按表名小写_set:book_set obj=Book.objects.fliter(title="python").first() obj.publish 多对多 正向查询,按字段 Book-------------------->Author <--------------------- 查询,按表名小写_set:book_set obj=Book.objects.fliter(title="python").first() obj.author.all() # [obj,....] 一对一: 正向查询,按字段 Book-------------------->Author <--------------------- 查询,按表名小写 基于queryset查询 正向查询,按字段 A-------------------->B <--------------------- 查询,按表名小写 聚合和分组 book id title publish 1 php 苹果 2 python 苹果 3 go 橘子 sql: select publish,Count(*) from Book group by publish #查询每一个出版社出版的书籍个数 # ret=Publish.objects.all().annotate(c=Count("book")).values("name","c") # print(ret) # 查询每一个作者出版的书籍的平均价格 ret=Author.objects.all().annotate(price_avg=Avg("book__price")).values("name","price_avg") print(ret) #查询每一本书籍名称以及作者的个数 ret=Book.objects.all().annotate(c=Count("author")).values("title","c") print(ret) # 查询价格大于200的每一本书籍名称以及作者的个数 ret = Book.objects.filter(price__gt=200).annotate(c=Count("author")).values("title", "c") print(ret) F查询与Q查询 # F from django.db.models import F,Q ret=Book.objects.filter(comment_num__gt=F("poll_num")) print(ret) ret=Book.objects.filter(comment_num__gt=F("read_num")*10) print(ret) Book.objects.all().update(price=F("price")+100) # Q ret=Book.objects.filter(title__startswith="java",price__gt=200) print(ret) ret = Book.objects.filter(Q(title__startswith="java")|~Q(price__lt=200)) print(ret) Ajax 请求形式: 地址栏 get form get post a标签 get ajax get post cookie session http协议: 基于请求响应 短连接 无状态保存 用户认证 form组件 中间件 作业1: 基于ajax和cookie实现登录验证 作业2; 查询练习题 Book publish id title publish_id id name email addr 1 php 1 1 AAA 123 beijing 2 python 1 Bookpublish id title publish_id id name email addr 1 php 1 1 AAA 123 beijing 2 python 1 1 AAA 123 beijing SELECT "app01_book"."title", "app01_publish"."name" FROM "app01_authordetail" INNER JOIN "app01_author" ON ("app01_authordetail"."author_id" = "app01_author"."id") LEFT OUTER JOIN "app01_book_author" ON ("app01_author"."id" = "app01_book_author"."author_id") LEFT OUTER JOIN "app01_book" ON ("app01_book_author"."book_id" = "app01_book"."id") LEFT OUTER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."id") WHERE "app01_authordetail"."tel" LIKE '1%' ESCAPE '\' LIMIT 21; args=('1%',) Author id name tel addr email 1 alex 123 beijing 123 2 egon 456 beijing 456 AuthorDetail id gf_name xingzuo xuexing author_id 1 xxx 天蝎 A 1 2 杠娘 双鱼 O 2
第2章 Django之ORM跨表操作(聚合查询,分组查询,F和Q查询等)
2.1 创建表
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);
一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
创建一对一的关系:OneToOne("要绑定关系的表名")
创建一对多的关系:ForeignKey("要绑定关系的表名")
创建多对多的关系:ManyToMany("要绑定关系的表名") 会自动创建第三张表
class Book(models.Model): nid = models.AutoField(primary_key=True) # 自增id(可以不写,默认会有自增id) title = models.CharField(max_length=32) publishDdata = models.DateField() # 出版日期 price = models.DecimalField(max_digits=5, decimal_places=2) # 一共5位,保留两位小数 #一个出版社有多本书,关联字段要写在多的一方 # 不用命名为publish_id,因为django为我们自动就加上了_id publish = models.ForeignKey("Publish") #foreignkey(表名)建立的一对多关系 # publish是实例对象关联的出版社对象 authorlist = models.ManyToManyField("Author") #建立的多对多的关系 def __str__(self): #__str__方法使用来吧对象转换成字符串的,你返回啥内容就打印啥 return self.title class Publish(models.Model): #不写id的时候数据库会自动给你增加自增id name =models.CharField(max_length=32) addr = models.CharField(max_length=32) def __str__(self): return self.name class Author(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() class AuthorDeital(models.Model): tel = models.IntegerField() addr = models.CharField(max_length=32) author = models.OneToOneField("Author") #建立的一对一的关系
注意:临时添加的字段,首先你得考虑之前的数据有没有。设置一个默认值。
wordNum = models.IntegerField(default=0)
通过logging可以查看翻译成的sql语句
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
注意事项:
1、 表的名称myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称
2、id 字段是自动添加的
3、对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名
4、这个例子中的CREATE TABLE SQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。
5、定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加models.py所在应用的名称。
6、外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
字段选项
每个字段有一些特有的参数,例如,CharField需要max_length参数来指定VARCHAR数据库字段的大小。还有一些适用于所有字段的通用参数。 这些参数在文档中有详细定义,这里我们只简单介绍一些最常用的:
1)null 如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False. (1)blank 如果为True,该字段允许不填。默认为False。 要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。 如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。 (2)default 字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。 (3)primary_key 如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True, Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为, 否则没必要设置任何一个字段的primary_key=True。 (4)unique 如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的 (5)choices 由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices , 默认的表单将是一个选择框而不是标准的文本框,而且这个选择框的选项就是choices 中的选项。 这是一个关于 choices 列表的例子: YEAR_IN_SCHOOL_CHOICES = ( ('FR', 'Freshman'), ('SO', 'Sophomore'), ('JR', 'Junior'), ('SR', 'Senior'), ('GR', 'Graduate'), ) 每个元组中的第一个元素,是存储在数据库中的值;第二个元素是在管理界面或 ModelChoiceField 中用作显示的内容。 在一个给定的 model 类的实例中,想得到某个 choices 字段的显示值,就调用 get_FOO_display 方法(这里的 FOO 就是 choices 字段的名称 )。例如: from django.db import models class Person(models.Model): SHIRT_SIZES = ( ('S', 'Small'), ('M', 'Medium'), ('L', 'Large'), ) name = models.CharField(max_length=60) shirt_size = models.CharField(max_length=1, choices=SHIRT_SIZES) >>> p = Person(name="Fred Flintstone", shirt_size="L") >>> p.save() >>> p.shirt_size 'L' >>> p.get_shirt_size_display() 'Large
一旦你建立好数据模型之后,django会自动生成一套数据库抽象的API,可以让你执行关于表记录的增删改查的操作。
2.2 添加记录
2.2.1 一对多添加记录:
# 一对多的添加 # 方式一:如果是这样直接指定publish_id字段去添加值,前提是你的主表里面必须有数据 # 主表:没有被关联的(因为book表是要依赖于publish这个表的)也就是publish表 # 子表:关联的表 models.Book.objects.create(title="追风筝的人",publishDdata="2015-5-8",price="111",publish_id=1) # 方式二:推荐 pub_obj = models.Publish.objects.filter(name="人民出版社")[0] print(pub_obj) models.Book.objects.create(title = "简爱",publishDdata="2000-6-6",price="222",publish=pub_obj) # 方式三:save pubObj= models.Publish.objects.get(name="人民出版社") #只有一个的时候用get,拿到的直接就是一个对象 bookObj = models.Book(title = "真正的勇士",publishDdata="2015-9-9",price="50",publish=pubObj) bookObj.save()
2.2.2 多对多添加记录:
书和作者是多对多的关系:一个书可以有多个作者,一个作者可以出版多本书
步骤:先找到书对象
再找到需要的作者对象
给书对象绑定作者对象(用add方法),也就是绑定多对多的关系
# 多对多的添加的两种方式 # 方式一: # 先创建一本书: pub_obj=models.Publish.objects.filter(name="万能出版社").first() book_obj = models.Book.objects.create(title="醉玲珑",publishDdata="2015-4-10",price="222",publish=pub_obj) # #通过作者的名字django默认找到id haiyan_obj = models.Author.objects.filter(name="haiyan")[0] egon_obj = models.Author.objects.filter(name="egon")[0] xiaoxiao_obj = models.Author.objects.filter(name="xiaoxiao")[0] # 绑定多对多的关系、 book_obj.authorlist.add(haiyan_obj, egon_obj, xiaoxiao_obj) # 方式二=========,查出所有的作者 pub_obj = models.Publish.objects.filter(name="万能出版社").first() book_obj = models.Book.objects.create(title="醉玲珑", publishDdata="2015-4-10", price="222", publish=pub_obj) authers = models.Author.objects.all() # #绑定多对多关系 book_obj.authorlist.add(*authers)
2.2.3 解除绑定
解除绑定:remove: # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[])
# 解除多对多的关系(remove) book_obj=models.Book.objects.filter(title="醉玲珑").last() #找到书对象 authers=models.Author.objects.filter(id__lt=3) #找到符合条件的作者对象 book_obj.authorlist.remove(*authers) #因为清除的是多条,得加个*
2.2.4 清除绑定
清除绑定:clear” #清空被关联对象集合。
# 清除关系方法(clear) book_obj= models.Book.objects.filter(title="红楼梦") for book_obj_item in book_obj:#把所有红楼梦的都给清空了 book_obj_item.authorlist.clear()
2.2.5 总结:remove和clear的区别
remove:得把你要清除的数据筛选出来,然后移除
clear:不用查,直接就把数据都清空了。
各有应用场景
2.3 基于对象的查询记录(相当于sql语句的where子查询)
2.3.1 一对一查询记录
一对一查询记录:author和authordetile是一对一的关系
正向查询(按字段author)
反向查询(按表名authordeital):因为是一对一的关系了,就不用_set了。
# 一对一的查询 # 正向查询:手机号为13245的作者的姓名 deital_obj = models.AuthorDeital.objects.filter(tel="13245").first() print(deital_obj.author.name) # 反向查询:查询egon的手机号 egon_obj = models.Author.objects.filter(name="egon").first() print(egon_obj.authordeital.tel)
2.3.2 一对多查询记录:
正向查询(按字段:publish):
反向查询(按表名:book_set):
# 正向查询:查询真正的勇士这本书的出版社的地址 book_obj = models.Book.objects.filter(title="真正的勇士")[0] # 找对象 print("======", book_obj.publish) # 拿到的是关联出版社的对象 print(book_obj.publish.addr) # 反向查询:查询人民出版社出版过的所有的书的价格和名字 pub_obj = models.Publish.objects.filter(name="人民出版社")[0] book_dic = pub_obj.book_set.all().values("price", "title")[0] print(book_dic) print(book_dic["price"]) # 查询 人民出版社出版过的所有书籍 publish=models.Publish.objects.get(name="人民出版社") #get得到的直接是一个对象,不过get只能查看有一条记录的 book_list=publish.book_set.all() # 与人民出版社关联的所有书籍对象集合 for book_obj in book_list: print(book_obj.title) 注意这里用for循环或是用values,vauleslist都是可以的。
2.3.3 多对多查询记录:
正向查询(按字段authorlist)
反向查询(按表名book_set)
# 多对多的查询 # 正向查询:查询追风筝的人的这本书的所有的作者的姓名和年龄 book_obj = models.Book.objects.filter(title="红楼梦")[0] print(book_obj.authorlist.all().values("name", "age")) # 这本书关联的所有作者对象的集合 # 反向查询:查询作者是haiyan的这个人出了哪几本书的信息 haiyan_obj = models.Author.objects.filter(name="haiyan")[0] print("bookinfo====", haiyan_obj.book_set.all().first().title) # 与该作者关联的所有书对象的集合 return HttpResponse("ok")
你可以通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name 的值来覆写 FOO_set 的名称。例如,如果 Article model 中做一下更改: publish = ForeignKey(Blog, related_name='bookList'),那么接下来就会如我们看到这般:
# 查询 人民出版社出版过的所有书籍 publish=Publish.objects.get(name="人民出版社") book_list=publish.bookList.all() # 与人民出版社关联的所有书籍对象集合
2.4 基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的 model 为止。(相当于用sql语句用join连接的方式,可以在settings里面设置,可查看sql语句)
2.4.1 一对多查询:
练习1、查询人民出版社出版过的所有的书的价格和名字
# 基于双下划线的方式查询1================一对多 # 第一种查法 ret = models.Publish.objects.filter(name="人民出版社").values("book__price","book__title") print(ret) # 第二种查法 ret2 = models.Book.objects.filter(publish__name="人民出版社").values("price","title") print(ret2)
练习2、查询linux这本书的出版社的地址:filer先过滤,,values显示要求的字段
第一种查法 ret = models.Book.objects.filter(title="linux").values("publish__addr") print(ret) 第二种查法 ret2 = models.Publish.objects.filter(book__title="linux").values("addr") print(ret2)
2.4.2 多对多查询:
练习1、查询egon出过的所有书的名字
#方式一 ret = models.Author.objects.filter(name="egon").values("book__title") print(ret) #方式二:两种方式也就是逻辑不一样 ret2 = models.Book.objects.filter(authorlist__name="egon").values("title") print(ret2)
练习2、查询手机号以151开头的作者出版过的所有书的名称以及出版社的名称
# 方式一: author_obj = models.AuthorDeital.objects.filter(tel__startswith="151").first() print(author_obj.author.book_set.all().values("title","publish__name")) # 方式二: ret = models.Book.objects.filter(authorlist__author_deital__tel__startswith="151").values("title","publish__name") print(ret)
2.5 聚合查询与分组查询(很重要!!!)
2.5.1 聚合查询
聚合查询:aggregate(*args, **kwargs),只对一个组进行聚合
from django.db.models import Avg,Sum,Count,Max,Min # 1、查询所有图书的平均价格 print(models.Book.objects.all().aggregate(Avg("price")))
aggregate()是QuerySet 的一个终止子句(也就是返回的不再是一个QuerySet集合的时候),意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
from django.db.models import Avg,Sum,Count,Max,Min # 1、查询所有图书的平均价格 print(models.Book.objects.all().aggregate(avgprice = Avg("price")))
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
print(models.Book.objects.all().aggregate(Avg("price"),Max("price"),Min("price"))) #打印的结果是: {'price__avg': 174.33333333333334, 'price__max': Decimal('366.00'), 'price__min': Decimal('12.00')}
2.5.2 分组查询
分组查询 :annotate():为QuerySet中每一个对象都生成一个独立的汇总值。
是对分组完之后的结果进行的聚合
1、统计每一本书的作者个数
# 方式一: print(models.Book.objects.all().annotate(authorNum = Count("authorlist__name")).values("authorNum")) # 方式二: booklist =models.Book.objects.all().annotate(authorNum=Count("authorlist__name")) for book_obj in booklist: print(book_obj.title,book_obj.authorNum)
2、统计每一个出版社最便宜的书
# 2、统计每一个出版社的最便宜的书 # 方式一: print(models.Book.objects.values("publish__name").annotate(nMinPrice=Min('price'))) 注意:values内的字段即group by的字段,,也就是分组条件 # 方式二: print(models.Publish.objects.all().annotate(minprice=Min("book__price")).values("name","minprice")) # 方式三 publishlist = models.Publish.objects.annotate(minprice = Min("book__price")) for publish_obj in publishlist: print(publish_obj.name,publish_obj.minprice)
3、统计每一本以py开头的书籍的作者个数:
print(models.Book.objects.filter(title__startswith="py").annotate(authNum = Count("authorlist__name")).values("authNum"))
(4)统计不止一个作者的图书:
print(models.Book.objects.annotate(num_authors=Count('authorlist__name')).filter(num_authors__gt=1).values("title","num_authors"))
(5)根据一本图书作者数量的多少对查询集QuerySet进行排序:
print(models.Book.objects.all().annotate(authorsNum=Count("authorlist__name")).order_by("authorsNum"))
(6)查询各个作者出的书的总价格:
# 方式一 print(models.Author.objects.all().annotate(priceSum = Sum("book__price")).values("name","priceSum")) # 方式二 print(models.Book.objects.values("authorlist__name").annotate(priceSum=Sum("price")).values("authorlist__name","priceSum"))
2.6 F查询和Q查询
2.6.1 F查询
F查询:
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
1、查看评论数大于阅读数的书
from django.db.models import F,Q print(models.Book.objects.filter(commentNum__gt=F("readNum")))
2、修改操作也可以使用F函数,比如将id大于1的所有的书的价格涨价100元
print(models.Book.objects.filter(nid__gt=1).update(price=F("price")+100))
3、Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
# 查询评论数大于收藏数2倍的书籍
models.Book.objects.filter(commnetNum__lt=F('keepNum')*2)
2.6.2 Q查询
Q查询:
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
1、查询id大于1并且评论数大于100的书
print(models.Book.objects.filter(nid__gt=1,commentNum__gt=100)) print(models.Book.objects.filter(nid__gt=1).filter(commentNum__gt=100)) print(models.Book.objects.filter(Q(nid__gt=1)&Q(commentNum__gt=100)))
2、查询评论数大于100或者阅读数小于200的书
print(models.Book.objects.filter(Q(commentNum__gt=100)|Q(readNum__lt=200))) Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
3、查询年份等于2017年或者价格大于200的书
print(models.Book.objects.filter(Q(publishDdata__year=2017)|Q(price__gt=200)))
4、查询年份不是2017年或者价格大于200的书
print(models.Book.objects.filter(~Q(publishDdata__year=2017)&Q(price__gt=200)))
注意:
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
bookList=models.Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017), title__icontains="python" )
2.7 关于查询知识点总结
models.Book.objects.filter(**kwargs): querySet [obj1,obj2]
models.Book.objects.filter(**kwargs).values(*args) : querySet [{},{},{}]
models.Book.objects.filter(**kwargs).values_list(title) : querySet [(),(),()]
跨表查询总结:
2.7.1 创建表
class Book(models.Model): title = models.CharField(max_length=32) publish=models.ForeignKey("Publish") # 创建一对多的外键字段 authorList=models.ManyToManyField("Author") # 多对多的关系,自动创建关系表 class Publish(models.Model): name = models.CharField(max_length=32) addr = models.CharField(max_length=32) class Author(models.Model): name=models.CharField(max_length=32) age=models.IntegerField() ad=models.models.OneToOneField("AuthorDetail") #创建一对一的关系 class AuthorDetail(models.Model): tel=models.IntegerField()
2.7.2 基于对象关联查询:
if 一对多查询(Book--Publish):
正向查询,按字段:
book_obj.publish : 与这本书关联的出版社对象 book_obj.publish.addr: 与这本书关联的出版社的地址
反向查询,按表名_set
publish_obj.book_set: 与这个出版社关联的书籍对象集合 publish_obj.book_set.all() :[obj1,obj2,....]
if 一对一查询(Author---AuthorDetail):
正向查询,按字段:
author_obj.ad : 与这个作者关联的作者详细信息对象
反向查询:按表名:
author_detail_obj.author : 与这个作者详细对象关联的作者对象
if 多对多(Book----Author):
正向查询,按字段:
book_obj.authorList.all(): 与这本书关联的所有这作者对象的集合 [obj1,obj2,....]
book_obj.authorList.all().values("name"): 如果想查单个值的时候可以这样查
反向查询,按表名_set:
author_obj.book_set.all() : 与这个作者关联的所有书籍对象的集合
book_obj.book_set.all().values("name"): 如果想查单个值的时候可以这样查
2.7.3 基于双下滑线的跨表查询:
if 一对多查询(Book--Publish):
正向查询,按字段:
# 查询linux这本书的出版社的名字: models.Book.objects.all().filter(title="linux").values("publish__name")
反向查询:按表名:
# 查询人民出版社出版过的所有书籍的名字 models.Publish.objects.filter(name="人民出版社出版").values("book__title")
if 一对一查询(Author---AuthorDetail):
正向查询,按字段:
#查询egon的手机号 models.Author.objects.filter(name="egon").values("ad__tel")
反向查询:按表名:
#查询手机号是151的作者 models.AuthorDetail.objects.filter(tel="151").values("author__name")
if 多对多(Book----Author):
正向查询,按字段:
#查询python这本书的作者的名字 models.Book.objects.filter(title="python").values("authorList__name") [{},{},{},{}]
正向查询,按表名:
#查询alex出版过的出的价格 models.Author.objects.filter(name="alex").values("book__price")
注意:
publish=models.ForeignKey("Publish",related_name="bookList")
authorlist=models.ManyToManyField("Author",related_name="bookList")
ad=models.models.OneToOneField("AuthorDetail",related_name="authorInfo")
反向查询的时候都用:related_name的值
2.7.4 聚合查询:
querySet().aggregate(聚合函数)------返回的是一个字典,不再是一个querySet
Book.objects.all().aggregate(average_price=Avg('price'))
2.7.5 分组查询:
querySet().annotate() --- 返回的是querySet
#统计每一个出版社中最便宜的书籍的价格
sql: select Min(price) from book group by publish_id; ORM: models.Book.objects.values("publish__name").annotate(Min("price"))
第3章 初始Ajax
3.1 Ajax准备知识:json
说起json,我们大家都了解,就是python中的json模块,那么json模块具体是什么呢?那我们现在详细的来说明一下
1、json(Javascript Obiect Notation,JS对象标记)是一种轻量级的数据交换格式。
它基于 ECMAScript (w3c制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。
简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
2、json其实是从js中拿出来的一个对象,也可以说json是js的一个子集。

需要知道的:json的格式来源于js的格式
1、js支持单引号,也支持双引号,也可以没有引号
//在js中吧{}这样的类型叫做对象,js中没有字典一说 data = { 'name':'haiyan', "name":"haiyan", name:"haiyan" } //js对象默认会把自己的键当成字符串处理,所以可以加引号也可以不加
2、json的格式:
1、json只认双引号的
2、json一定是一个字符串
3、下面我们看看哪些是合格的字符串,那些不是?
合格的json对象:
["one", "two", "three"] { "one": 1, "two": 2, "three": 3 } {"names": ["张三", "李四"] } [ { "name": "张三"}, {"name": "李四"} ]
不合格的json对象:
{ name: "张三", 'age': 32 } // 属性名必须使用双引号
[32, 64, 128, 0xFFF] // 不能使用十六进制值
{ "name": "张三", "age": undefined } // 不能使用undefined
{ "name": "张三",
"birthday": new Date('Fri, 26 Aug 2011 07:13:10 GMT'),
"getName": function() {return this.name;} // 不能使用函数和日期对象
}
3.1.1 python中的序列化(dumps)与反序列化(loads)
+++++++++++++++python中的序列化(dumps)与反序列化(loads)++++++++++++++
import json i = 10 s = "dsfdsf" l = [11,22,33] dic = {"name":"haiyna","age":22} b = True # #吧基本数据类型转换成字符串的形式 print(json.dumps(i),type(json.dumps(i))) #10print(json.dumps(s),type(json.dumps(s))) #"dsfdsf" print(json.dumps(l),type(json.dumps(l))) #[11, 22, 33] print(json.dumps(dic),type(json.dumps(dic))) #{"name": "haiyna", "age": 22} print(json.dumps(b),type(json.dumps(b))) #true # ===============json反序列化============= d = {"a":1,"b":"fdgfd"} data = json.dumps(d) print(data,type(data)) f = open("a.txt","w") f.write(data) #注意这会写进去的字符串时双引号的格式 f.close() # ===============json序列化============= f = open("a.txt","r") datat = f.read() print(datat,type(datat)) #{"a": 1, "b": "fdgfd"} data = json.loads(datat) print(data,type(data)) #{'a': 1, 'b': 'fdgfd'}
3.1.2 JS中的序列化(stringify)与反序列化(parse)
+++++++++++++++JS中的序列化(stringify)与反序列化(parse)++++++++++++++++++
JSON.stringify():用于将一个JavaScript对象转换为JSON字符串
JSON.parse():用于将一个JSON字符串转换为JavaScript对象
3.2 JSON和XML的比较
1、XML也是存数据的一种格式,也是一种标记语言。它是利用节点进行查找的
2、JSON 格式于2001年由 Douglas Crockford 提出,目的就是取代繁琐笨重的 XML 格式。
JSON 格式有两个显著的优点:书写简单,一目了然;符合 JavaScript 原生语法,可以由解释引擎直接处理,不用另外添加解析代码。所以,JSON迅速被接受,已经成为各大网站交换数据的标准格式,并被写入ECMAScript 5,成为标准的一部分。
XML和JSON都使用结构化方法来标记数据,下面来做一个简单的比较。
3.2.1 用XML表示中国部分省市数据如下:
"1.0" encoding="utf-8"?>中国 黑龙江 哈尔滨 大庆 广东 广州 深圳 珠海 台湾 台北 高雄 新疆 乌鲁木齐
3.2.2 用JSON表示如下:
{ "name": "中国", "province": [{ "name": "黑龙江", "cities": { "city": ["哈尔滨", "大庆"] } }, { "name": "广东", "cities": { "city": ["广州", "深圳", "珠海"] } }, { "name": "台湾", "cities": { "city": ["台北", "高雄"] } }, { "name": "新疆", "cities": { "city": ["乌鲁木齐"] } }] }
可以看到,JSON 简单的语法格式和清晰的层次结构明显要比 XML 容易阅读,并且在数据交换方面,由于 JSON 所使用的字符要比 XML 少得多,可以大大得节约传输数据所占用得带宽。
3.2.3 注意:
JSON格式取代了xml给网络传输带来了很大的便利,但是却没有了xml的一目了然,尤其是json数据很长的时候,我们会陷入繁琐复杂的数据节点查找中。
但是国人的一款在线工具 BeJson 、SoJson在线工具让众多程序员、新接触JSON格式的程序员更快的了解JSON的结构,更快的精确定位JSON格式错误。
3.3 Ajax简介
3.3.1 简单介绍
我们以前知道的前端向后端发送数据的方式有:
GET:地址栏、a标签、Form表单
POST:Form表单
那么现在我们在学习一种:那就是ajax
ajax:也是前端向后端发送数据的一种方式
AJAX(Asynchronous Javascript And XML)翻译成中文就是“异步Javascript和XML”。即使用Javascript语言与服务器进行异步交互,传输的数据为XML(当然,传输的数据不只是XML)。
- 同步交互:客户端发出一个请求后,需要等待服务器响应结束后,才能发出第二个请求;
- 异步交互:客户端发出一个请求后,无需等待服务器响应结束,就可以发出第二个请求。
Ajax的特点:
异步交互: 当请求发出后,浏览器还可以进行其他操作,无需等待服务器的响应!
局部刷新: 整个过程中页面没有刷新,只是刷新页面中的局部位置而已!
js的局部刷新:
"en"> "UTF-8">Title
3.3.2 ajax的创建应用场景
当我们在百度中输入一个“老”字后,会马上出现一个下拉列表!列表中显示的是包含“老”字的4个关键字。
其实这里就使用了AJAX技术!当文件框发生了输入变化时,浏览器会使用AJAX技术向服务器发送一个请求,查询包含“老”字的前10个关键字,然后服务器会把查询到的结果响应给浏览器,最后浏览器把这4个关键字显示在下拉列表中。
- 整个过程中页面没有刷新,只是刷新页面中的局部位置而已!
- 当请求发出后,浏览器还可以进行其他操作,无需等待服务器的响应!
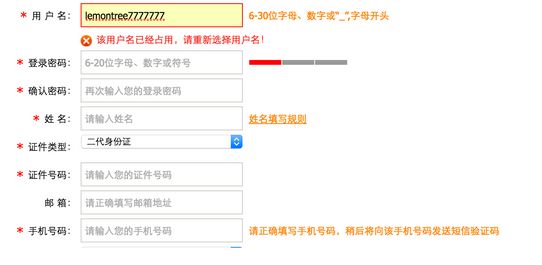
当输入用户名后,把光标移动到其他表单项上时,浏览器会使用AJAX技术向服务器发出请求,服务器会查询名为zhangSan的用户是否存在,最终服务器返回true表示名为lemontree7777777的用户已经存在了,浏览器在得到结果后显示“用户名已被注册!”。
- 整个过程中页面没有刷新,只是局部刷新了;
- 在请求发出后,浏览器不用等待服务器响应结果就可以进行其他操作;
3.3.3 ajax的优点,特点也就是优点
优点:
AJAX使用Javascript技术向服务器发送异步请求;
AJAX无须刷新整个页面;
因为服务器响应内容不再是整个页面,而是页面中的局部,所以AJAX性能高;
3.4 jQuery实现的ajax
3.4.1 tishi.html
"en"> "UTF-8"> "X-UA-Compatible" content="IE=edge"> "viewport" content="width=device-width, initial-scale=1">Title "/get_OK/">点击class="error">
姓名"text">
密码"password">
class="login_error">
3.4.2 view
def tishi_ajax(request): username=request.GET.get("name") password=request.GET.get("pwd") response={"flag":False} if username=="yuan" and password=="123": response["flag"]=True import json import time return HttpResponse(json.dumps(response)) def tishi(request): return render(request,"tishi.html") {% load staticfiles %} "en"> "UTF-8">Title
3.5 ajax参数
3.5.1 请求参数
######################------------data---------################ data: 当前ajax请求要携带的数据,是一个json的object对象,ajax方法就会默认地把它编码成某种格式 (urlencoded:?a=1&b=2)发送给服务端;此外,ajax默认以get方式发送请求。 function testData() { $.ajax("/test",{ //此时的data是一个json形式的对象 data:{ a:1, b:2 } }); //?a=1&b=2 ######################------------processData---------################ processData:声明当前的data数据是否进行转码或预处理,默认为true,即预处理;if为false, 那么对data:{a:1,b:2}会调用json对象的toString()方法,即{a:1,b:2}.toString() ,最后得到一个[object,Object]形式的结果。 ######################------------contentType---------################ contentType:默认值: "application/x-www-form-urlencoded"。发送信息至服务器时内容编码类型。 用来指明当前请求的数据编码格式;urlencoded:?a=1&b=2;如果想以其他方式提交数据, 比如contentType:"application/json",即向服务器发送一个json字符串: $.ajax("/ajax_get",{ data:JSON.stringify({ a:22, b:33 }), contentType:"application/json", type:"POST", }); //{a: 22, b: 33} 注意:contentType:"application/json"一旦设定,data必须是json字符串,不能是json对象 ######################------------traditional---------################ traditional:一般是我们的data数据有数组时会用到 :data:{a:22,b:33,c:["x","y"]}, traditional为false会对数据进行深层次迭代;
3.5.2 响应参数
/*
dataType: 预期服务器返回的数据类型,服务器端返回的数据会根据这个值解析后,传递给回调函数。
默认不需要显性指定这个属性,ajax会根据服务器返回的content Type来进行转换;
比如我们的服务器响应的content Type为json格式,这时ajax方法就会对响应的内容
进行一个json格式的转换,if转换成功,我们在success的回调函数里就会得到一个json格式
的对象;转换失败就会触发error这个回调函数。如果我们明确地指定目标类型,就可以使用
data Type。
dataType的可用值:html|xml|json|text|script
见下dataType实例
*/
3.5.3 示例:
from django.shortcuts import render,HttpResponse from django.views.decorators.csrf import csrf_exempt # Create your views here. import json def login(request): return render(request,'Ajax.html') def ajax_get(request): l=['alex','little alex'] dic={"name":"alex","pwd":123} #return HttpResponse(l) #元素直接转成字符串alexlittle alex #return HttpResponse(dic) #字典的键直接转成字符串namepwd return HttpResponse(json.dumps(l)) return HttpResponse(json.dumps(dic))# 传到前端的是json字符串,要想使用,需要JSON.parse(data) //--------------------------------------------------- function testData() { $.ajax('ajax_get', { success: function (data) { console.log(data); console.log(typeof(data)); //console.log(data.name); //JSON.parse(data); //console.log(data.name); }, //dataType:"json", } )} 注解:Response Headers的content Type为text/html,所以返回的是String;但如果我们想要一个json对象 设定dataType:"json"即可,相当于告诉ajax方法把服务器返回的数据转成json对象发送到前端.结果为object 当然, return HttpResponse(json.dumps(a),content_type="application/json") 这样就不需要设定dataType:"json"了。 content_type="application/json"和content_type="json"是一样的!
第4章 ajax补充--------FormData等
4.1 回顾上节知识点
4.1.1 什么是json字符串?
轻量级的数据交换格式
4.1.2 定时器:关于setTimeout
setTimeout(foo,3000) # 3000表示3秒,foo表示一个函数,3秒后执行foo函数
"en"> "UTF-8"> "X-UA-Compatible" content="IE=edge"> "viewport" content="width=device-width, initial-scale=1">Title "/get_OK/">点击class="error">
{% csrf_token %}姓名"text">
密码"password">
class="login_error">
4.1.3 ajax的参数补充
- type不写的话默认是GET
- dataType和ContentType:
dataType: 浏览器发给服务器希望返回的数据类型 。。如果我们明确地指定目标类型,就可以使用data Type。
ContentType:
请求头里有:浏览器告诉服务器内容的类型
响应头里也有:服务器响应浏览器的内容
4.1.4 JS和JQuery对象之间的转换
jQuery对象加[0]就转换成了dom对象
dom对象加$符就转换成了jquery对象
4.1.5 processDate 默认为True ,预处理; 如果改为False,不做预处理
4.2 csrf跨站请求伪造
如果把type:"GET" 改为type:"POST" 会报一个Forbidden的错
解决办法有三种:
4.2.1 方式一:
$.ajaxSetup({ data:{csrfmiddlewaretoken:'{{ csrf_token }}'} }); 注意:要放在ajax请求的前面,在发送之前组装一组字符串,在第一步render的时候就发了 所以有局限性: 如果把JS代码放到静态文件中,不会渲染,不会执行{{csrf_token}},只能在HTML页面中使用
4.2.2 方式二:自己组装一组键值对 ( 推荐)
4.2.3 方式三:自己设置头信息
$.ajax({ url:"/serialize/", type:"POST", headers:{"X-CSRFToken":$.cookie('csrftoken')}, })
4.3 jQuery.serialize()
4.3.1 介绍
serialize()函数用于序列化一组表单元素,将表单内容编码为用于提交的字符串。
serialize()函数常用于将表单内容序列化,以便用于AJAX提交。
该函数主要根据用于提交的有效表单控件的name和value,将它们拼接为一个可直接用于表单提交的文本字符串,该字符串已经过标准的URL编码处理(字符集编码为UTF-8)。
该函数不会序列化不需要提交的表单控件,这和常规的表单提交行为是一致的。例如:不在。
与常规表单提交不一样的是:常规表单一般会提交带有name的按钮控件,而serialize()函数不会序列化带有name的按钮控件。更多详情请点击这里。
语法:
jQueryObject.serialize( )
serialize()函数的返回值为String类型,返回将表单元素编码后的可用于表单提交的文本字符串。
请参考下面这段初始HTML代码:
对