MDvsFA-cGAN算法论文阅读笔记Miss detection vs. false alarm: Adversarial learning for small object...
论文来自:
H. Wang, L. Zhou, and L. Wang, “Miss detection vs. false alarm: Adversarial learning for small object segmentation in infrared images,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2019, pp. 8509–8518.
这个笔记只是我自己学习中的记录,里面很多揣测作者的内容不保证完全的正确,如果有不足或理解错误的地方希望大佬指出
笔记作者:瀚
2023年春于国防科技大学
I. 核心思想
-
整个网络模型基于条件生成对抗网络cGAN
-
将对于小目标分割结果的漏检率(MD)的抑制和误报率(FA)的抑制,分别使用两个生成器进行训练
漏检率:目标被判断为背景
误报率:背景被判断为目标
他们的值一般和Confidence map中阈值的选取有关,显然更高的阈值使得误报率降低,但漏检率会显著增加,反之亦然。
-
损失函数包含对抗网络常见的对抗损失和数据损失,但为了使两个生成器之间进行数据的流动,作者添加了一个迫使两个生成器进行交流的“生成性一致损失”
II. 作者为什么会提出该算法
A. 传统算法的不足
-
传统算法通常来抑制背景并增强对象以获得Confidence map。之后,对该图进行自适应阈值处理以将对象分割出来。这其中不涉及任何的特征学习。作者认为不涉及特征学习的阈值选取很难应对真实场景中的复杂性。
Confidence maps(置信度图)是一种在计算机视觉和机器学习中常用的技术。它们是一种图像,其中的每个像素都表示了在某种程度上对于该像素的预测的置信度或概率。在人脸识别、姿势估计、目标检测等任务中,使用置信度图可以帮助算法对关键点、边界框、姿态等进行更准确的定位和检测。
通常情况下,置信度图是通过在训练过程中从标注数据中生成的,可以作为评估算法准确性的一种指标。
-
对于其他机器学习网络来说,传统算法的网络结构中有太多的池化层导致小目标的特征被抑制甚至消除。其他算法虽然设计了一些特殊的结构进行小目标的分割,但是这些方法多有其针对的运用场景。
这里作者用自己的 红外小目标分割 网络和其其他的 语义分割 网络进行对比,说他人的算法要不很容易忽略小目标,要不专一性比较强不适合小目标的识别。
这里作者把重点放在了 分割 算法的对比,而不是 小目标 算法的对比,从而提出了其他算法的种种不足。
-
传统算法强调使用网络,通过同时对MD和FA进行优化,来进行训练,而并没有将MD和FA的优化分开,这导致传统的方法都很难达到一种状态,这种状态是输出的MD与FA平衡且都处于较低的水平。
B. 作者提出的算法
首先提出了一个条件生成对抗网络框架,在这个框架中,一个 ISOS 任务被分解成两个子任务,构建了两个深度神经网络来分别关注这两个任务中的每一个:最小化 MD 、最小化 FA。这两个任务分别由两个神经网络进行解决,两个网络的输出以及真值被送入鉴别器。

对于生成器的网络模型选择:首先这是一个分割任务。在实验中发现在 ISOS 中,MD的抑制更喜欢局部视觉信息,而FA的抑制则受益于全局视觉信息。为了满足这一要求,作者在生成器的选择上考虑了上下文聚合网络(CAN),实现在两个生成器中使用不同大小的感受野。
对于鉴别器网络模型的选择:首先这是一个分类任务。作者简单的使用了基于CNN的分类网络。对图像的来源进行分类,即来自生成器1、来自生成器2、或来自ground truth。
在使用两个生成器和一个判别器的GAN中,每个生成器都试图最大化自己的生成能力,即让生成的数据尽可能逼真。因此,我们可以将GAN的目标视为一个多目标优化问题,其中每个生成器都有自己的优化目标。
Context Aggregation Network(CAN)是一种用于图像分割的深度卷积神经网络,由国防科技大学的研究团队于2018年提出。CAN 旨在解决在图像分割任务中上下文信息不足的问题,它能够充分利用不同尺度的上下文信息,提高图像分割的准确性和鲁棒性,具体而言,CAN 包含两个主要组件:金字塔池化模块和上下文聚合模块。其中,金字塔池化模块用于将输入图像分别进行不同尺度的池化操作,从而提取不同尺度的特征图。上下文聚合模块则将不同尺度的特征图进行聚合,并将聚合后的特征图用于图像分割。除此之外,CAN 还使用了一种类似于全连接层的模块,称为“通道空间卷积模块”(Channel Spatial Convolution Module),用于对特征图进行深度信息的融合和特征增强。这种模块能够有效地增加网络的非线性拟合能力,提高图像分割的准确性和鲁棒性。
C. 作者所提出算法的优势
-
使用两个模型分别进行训练,更有针对性的项目分配使得整个红外小目标分割项目的难度降低
-
两种模型间存在对抗训练,即特意设置了一个有关两个生成器的损失函数。这样使得在纳什均衡的情况下实现MD和FA的平衡与低比率
这里作者认为仅通过应用阈值或仅采用 MD 和 FA 的加权线性组合形式的损失函数可能无法充分实现这种平衡。所以作者认为使两个模型相互竞争,并期望在竞争达到稳定时出现这种平衡状态。事实上也做到了
-
通过两个使用模型使得针对于每一个子任务方面的开发更具灵活性,具体体现在对于MD和FA任务,其网络模型是一样的,但是根据其各自特点,网络的结构是不一样的
III. 算法介绍
A. 模型的构建

模型由两个生成器和一个判别器组成
生成器
进行从输出图像 I I I 到输出结果 S S S 的映射,表示如下:
G i ( I ) = S i i = 1 , 2 (1) G_i(I)=S_i \newline i=1,2 \tag{1} Gi(I)=Sii=1,2(1)
式子中的 G i G_i Gi 表示第 i i i 个生成器生成的结果。作者认为联合训练两个生成器可以有效沟通两个网络间的信息共享,而不是分别训练两个网络然后将结果简单的融合在一起。在这篇文章中, G 1 G_1 G1 被设计用来 m i n ( M D ) min(MD) min(MD) 类似的 G 2 G_2 G2 被设计用来 m i n ( F A ) min(FA) min(FA).
判别器
判别器被设计区分三个结果 S 0 , S 1 , S 2 S_0, S_1, S_2 S0,S1,S2 ,其中 S 0 S_0 S0 表示真值(1表示目标,0表示背景)。这里设计判别器考虑到了两个方面:
- 作为媒介促使生成器之间的信息交互

判别器作为媒介连接 G 1 G_1 G1 和 G 2 G_2 G2 使得信息可以在两个生成器之间流动。好处是可以使得例如最小化MD的生成器产生减小FA的能力。
- 作为监督者促进各个生成器的进步
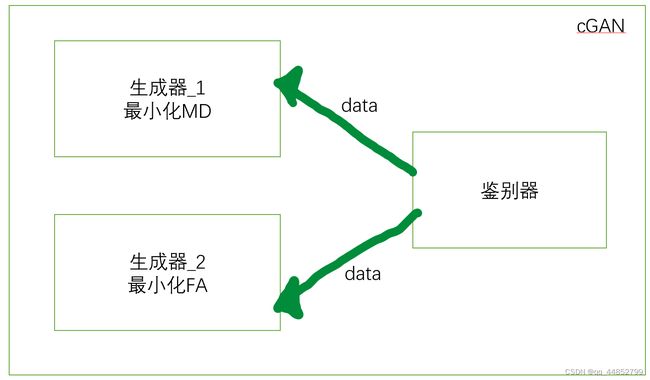
由于加入了 ground truth 导致两个 generators 的输出向 ground truth 收敛。
总结
作者不只希望两个生成器分别独立的进行两个任务的完成,更希望其进行合作。而合作的达成需要鉴别器的配合。
由于训练了两个 generators 并且使用 discriminator 进行监督,所以两个 generators 的最终训练权重都可以作为测试图像的分割结果。这里作者为了稳健,使用了两个生成器的平均输出作为最终的分割结果。
B. 损失函数
整个模型的损失由三类组成:
- Adversarial loss
- Generator consistency loss
- Data loss treating MD and FA
在 GAN 中,数据损失和对抗性损失分别处理两个不同的问题。
数据损失通常用于衡量生成器输出和真实数据之间的距离,帮助生成器尽可能地生成与真实数据相似的输出。也就是说,这是像素层面上的类似。在图像生成中,常用的数据损失包括 L1 损失和 L2 损失等。
L1和L2损失:
L 1 = 1 N ∑ i = 1 N ∣ y i − y ^ i ∣ L_1 = \frac{1}{N}\sum_{i=1}^{N}|y_i - \hat{y}_i| L1=N1i=1∑N∣yi−y^i∣L 2 = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 (*) L_2 = \frac{1}{N}\sum_{i=1}^{N}(y_i - \hat{y}_i)^2 \tag{*} L2=N1i=1∑N(yi−y^i)2(*)
其中, y i y_i yi 表示第 i i i 个真实值, y ^ i \hat{y}_i y^i 表示第 i i i 个预测值, N N N 表示样本数量。L1损失和L2损失都是衡量预测值与真实值之间的差异的指标,L1损失是预测值与真实值的绝对差异之和的平均值,L2损失是预测值与真实值的平方差之和的平均值。在深度学习中,L1损失和L2损失常用于回归问题中的损失函数。
对抗性损失则帮助判别器更好地区分生成器输出和真实数据,并鼓励生成器生成更逼真的数据。这一部分损失的最终目的是使得生成器生成的样本与真实数据的分布尽可能相似。也就是说,这是更高级别特征上的类似。GAN 中通常使用的是基于最大似然估计的交叉熵损失。
因此,优化数据损失可以使生成器生成更接近真实数据的输出,而优化对抗性损失可以帮助生成器更好地生成逼真的数据。同时,这两个损失也可以相互协同,相互加强,从而达到更好的效果。
至于本文中提出的另一个损失函数:Generator consistency loss,他负责增加两个生成器之间的数据流通。通过对两个生成器之间生成特征距离的优化,来迫使两个生成器进行沟通。
总的表示如下:
( G 1 ∗ , G 2 ∗ , D ) = arg min G 1 , G 2 max D ( L G C + α 1 L c G a n + α 2 ( L M F 1 + L M F 2 ) ) (G_1^*,G_2^*,D)=\arg \min_{G_1,G_2} \max_D (L_{GC}+\alpha_1 L_{cGan}+\alpha_2(L_{MF_1}+L_{MF_2})) (G1∗,G2∗,D)=argG1,G2minDmax(LGC+α1LcGan+α2(LMF1+LMF2))
具体的参数在下面进行详细分析。其中 arg \arg arg 表示使后式成立的变量取值。 α i \alpha_i αi 是权重因子,通过实验得到。
这个式子的求解过程可以通过交替训练生成器和判别器来实现,具体而言,首先固定生成器参数,更新判别器参数,使得损失函数最大化,然后固定判别器参数,更新生成器参数,使得损失函数最小化。这个过程可以不断迭代,直到达到预设的收敛条件。
Adversarial loss 对抗损失:
对抗损失用于确保生成器能够生成非常逼真(特征层面相似)的假样本。公式如下:

第一项代表对真实样本进行判断, D ( x ) D(x) D(x) 表示判别器将真实样本 x 判断为真实样本的概率。当 D ( x ) D(x) D(x) 越接近 1 时,第一项越接近 0,表示判别器的分类结果越准确。
后两项分别对应对于生成器生成的假样本, G ( z ) G(z) G(z) 表示生成器生成的假样本, D ( G ( z ) ) D(G(z)) D(G(z)) 表示判别器将生成器生成的假样本判断为真实样本的概率, 1 − D ( G ( z ) ) 1-D(G(z)) 1−D(G(z)) 表示判别器将生成器生成的假样本判断为假样本的概率。当 D ( G ( z ) ) D(G(z)) D(G(z)) 越接近 0 时,后两项越接近 0,表示判别器的分类结果越准确。
对于判别器的损失函数中为什么使用了对数函数,是因为对数函数可以将概率值映射到实数空间,使得计算交叉熵损失函数更加方便和稳定。同时,使用对数函数还可以加速模型的收敛,避免梯度消失的问题。
E \mathbb{E} E 表示期望
生成器目标是最小化上式,从而对 G 1 G 2 G_1 G_2 G1G2 进行权重训练,使其输出更接近真值。
判别器目标是最大化上式,从而对 D D D 进行权重训练,以增强其区分生成数据和真实数据的能力。
Generator consistency loss 生成器一致性损失:
生成器一致性损失用于确保两个生成器生成的样本在同一像素上是有竞争关系的,而不是分别以自己的方式收敛到 S 0 S_0 S0 即 enhance the information flow between the two generators。损失函数定义如下:
L G C ( G , D ) = 1 w ⋅ h ⋅ d ∣ ∣ ϕ ( I , S 1 ) − ϕ ( I , S 2 ) ∣ ∣ 2 2 L_{GC}(G,D)=\frac{1}{w\cdot h\cdot d}||\phi(I,S_1)-\phi(I,S_2)||^2_2 LGC(G,D)=w⋅h⋅d1∣∣ϕ(I,S1)−ϕ(I,S2)∣∣22
其中 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 表示特征映射, w , h , d w,h,d w,h,d 分别代表卷积特征图的三个维度。
这个式子是一个损失函数,用于衡量生成对抗网络中两个生成器之间的差距。
在这个损失函数中, w w w、 h h h、 d d d分别代表卷积特征图的三个维度,即宽度、高度和深度。 ∣ ∣ ⋅ ∣ ∣ 2 ||\cdot||_2 ∣∣⋅∣∣2表示 L 2 L_2 L2范数,它被用来计算输入图像在特征空间中的距离。因此,这个损失函数的含义是:将两个生成器对于输入 I I I的生成的图像 S 1 S_1 S1和 S 2 S_2 S2部分通过“corresponding feature mapping”转换到特征空间中,然后计算它们之间的 L 2 L_2 L2距离的平方。
对于将结果除以特征图的体积,即 w ⋅ h ⋅ d w\cdot h\cdot d w⋅h⋅d,作者可能是为了将获得不同尺寸特征图的损失函数归一化到相同量级。
Data loss 数据损失:
确保两个生成器生成的图像和真值进行像素级的相似。但是考虑到模型的任务是优化MD和FA,所以不简单的使用L1损失和L2损失,而是进行下式的改进:

其中 M D j i MD_{ji} MDji中的 j j j 代表两个生成器中的某一个, i i i 代表 n 张用来求和图片中的序号。 F A j i FA_{ji} FAji类似。 λ 1 , λ 2 \lambda_1,\lambda_2 λ1,λ2分别代表两个权重,因为每个生成器只注重一项任务,所以通过权重来集中其注意力。
作者这里用加号的用意我想是因为,由于希望得到的MD与FA尽量的小,所以其和也应该尽量的小。所以距离直接用两者的和来代表。
C. 网络结构
生成器
由于作者通过测试得到,对于不同的任务,其优化好坏与感受野有关,所以论文中选择G1 的感受野为 31 × 31,G2 的感受野为 257 × 257。
与G1相比,G2除了拥有更多的层数之外,还使用skip connections来连接具有相同dilation factors的层,以缓解模型深入时的梯度消失问题。
鉴别器
它由两个最大池化层(第 1 层和第 2 层)组成,用于对输入图像进行下采样,四层(第 3 ~ 6 层)网络模块由 conv 层 + BN(批量归一化)+ leaky-ReLU 激活组成,两个完全连接层(第 7 层和第 8 层)和具有 softmax 激活的输出层,以对输入图像的来源(来自 G1、G2 或ground truth)进行分类。
IV. 基于该算法的测试
测试结果可以看看原文,我可能会写一个有关红外弱小目标评测指标的博客,但是不会每一个论文都对其测试结果进行分析。
题外话(我做笔记时一些不懂的地方和自己搜寻的解释,和正文关系不大)
-
为什么discriminator的损失函数要用log表示
判别器的损失函数中使用了对数函数,是因为对数函数可以将概率值映射到实数空间,使得计算交叉熵损失函数更加方便和稳定。同时,使用对数函数还可以加速模型的收敛,避免梯度消失的问题。
-
这句话是什么意思:The objective of the proposed model consists of three
parts: the adversarial loss, a generator consistency loss, and a data loss treating MD and FA.这句话的意思是,所提出的模型的目标由三部分组成:对抗损失(adversarial loss)、生成器一致性损失(generator consistency loss)和对 MD 和 FA 进行处理的数据损失(data loss)。这些损失被用来训练模型,以达到最小化目标函数的目的。其中,
对抗损失用于确保生成器能够生成具有真实数据特征的样本,
生成器一致性损失则用于确保生成器的多个版本生成的样本之间具有一致性,
而数据损失则用于处理特定类型的数据,以进一步提高模型的性能
-
结合损失函数公式解读下面的话:Minimizing this objective with respect to the network weights of G1 and G2 encourages their outputs (i.e., S1 and S2 previously defined) to become similar as the ground truth S0. Maximizing it with respect to the network weights of D enhances its discrimination in the three segmentation results.
这段话的意思是,通过最小化公式中的目标函数来训练生成器 G1 和 G2 的权重,以使它们生成的输出(即先前定义的 S1 和 S2)与真实数据的分割结果 S0 相似。同时,通过最大化目标函数对判别器 D 的权重进行训练,以增强其在三个分割结果中的区分能力。
具体来说,生成器 G1 和 G2 的输出 S1 和 S2 都被用作分割网络的预测结果,其目标是使它们尽可能接近真实数据的分割结果 S0。通过最小化目标函数来训练生成器的权重,可以鼓励生成器输出的分割结果与真实数据的分割结果尽可能接近。
判别器 D 被用于对生成器输出和真实数据进行区分,其目标是将生成器的输出和真实数据的分割结果区分开来。通过最大化目标函数对判别器的权重进行训练,可以增强其在区分生成器输出和真实数据分割结果方面的能力。最终,生成器和判别器的训练通过反复迭代,可以使生成器输出的分割结果越来越接近真实数据的分割结果。