golang数据结构初探之管道chan
golang数据结构初探之管道chan
管道是go在语言层面提供的协程之间的通信方式,比unix的管道更易用也更轻便。
特效速览
初始化
声明和初始化管道的方式主要有以下两种:
- 变量声明
- 使用内置函数
变量声明
这种方式声明的管道,值为nil。每个管道只能存储一种类型的数据
var ch chan int //声明管道
使用内置函数 make()
使用内置函数make() 可以创建无缓冲管道和带缓冲管道
ch1:=make(chan string) //无缓冲管道
ch2:=make(chan string,5) //带缓冲管道
管道操作
操作符
操作符 “<-” 表示数据流向,管道在左表示向管道写入数据,管道在右表示从管道读取数据
ch := make(chan int,10)
ch <- 1 //数据写入管道
d := <- ch //从管道中读取数据
fmt.Println(d)
默认的管道是双向可读写,管道在函数间传递时可以使用操作符限制管道的读写,如下所示
func ChanParamRW(ch chan int){
//管道可读写
}
func ChanParamRW(ch <-chan int){
//管道只能读
}
func ChanParamRW(ch chan<- int){
//管道只能写
}
数据读写
- 管道没有缓冲区时,从管道读取数据会堵塞,直到有协程向管道中写入数据。类似的,写数据也会堵塞,直到有协程从管道读取数据、
- 管道有缓冲区时但缓冲区没有数据时,读数据会阻塞,直到有写入操作。类似的,写数据时,如果缓冲区已满,那么也会堵塞,直到有协程从管道中读取数据
- 对于值为nil的管道,无论读写都会堵塞,而且是永久堵塞。(协程无法释放,此处会出现协程泄漏)
- 使用内置函数close()可以关闭管道,尝试向关闭的管道写入数据会发生panic,但是关闭的管道依旧可读
管道读取表达式最多可以给两个变量赋值:
v1 := <-ch
x,ok :=<-ch
第一个变量表示读取的数据,第二个变量(bool 类型)表示是否成功读取了数据,需要注意的是,第二个变量不用于表示管道的关闭状态。
第二个变量通常被错误的理解成管道的关闭状态,那是因为它的值确实跟管道的关闭状态有关,更确切的说跟管道缓冲区中是否有数据有关。
一个已关闭的管道有两种情况:
- 管道缓冲区没有数据
- 管道缓冲区还有数据
对于第一种情况,管道已关闭且缓冲区没有数据,那么管道读取表达式返回的第一个变量为相应类型的零值,第二个变量为false
对于第二种情况,管道已关闭单缓冲区还有数据,那么管道读取表达式返回的第一个变量为读取到的数据,第二个变量为true。可以看到,只有管道已关闭且缓冲区中没有数据时,管道读取表达式返回的第二个变量才跟管道的关闭状态一致
小结
内置函数 len() 和 cap() 作用于管道,分别用于查询缓冲区中数据的个数和缓冲区的大小。
管道实现了一种FIFO(先入先出)的队列,数据总是按照写入的数据流出管道。
协程读取管道时,阻塞的条件有:
- 管道无缓冲区
- 管道的缓冲区中无数据(除了select case 语法,后续会对此写法有讲解)
- 管道的值为nil
协程写入管道时,阻塞的条件有:
- 管道无缓冲区
- 管道缓冲区已满
- 管道的值为nil
实现原理
数据结构
源码包中 src/runtime/chan.go:hchan 定义了管道的数据结构:
type hchan struct {
qcount uint // 当前队列中剩余的元素个数
dataqsiz uint // 环形队列长度,即可以存放的元素个数
buf unsafe.Pointer // 环形队列的指针
elemsize uint16 //每个元素的大小
closed uint32 //标识关闭状态
elemtype *_type // 每个元素的类型
sendx uint // 队列下标,表示元素写入时存放到队列中的位置
recvx uint // 队列下标。表示下一个被读取的元素在队列中的位置
recvq waitq // 等待读消息的协程队列
sendq waitq // 等待写消息的协程队列
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex //互斥锁,chan不允许并发读写
}
从数据结构可以看出管道由队列、类型信息、协程等待队列组成。
环形队列
chan内部实现了一个环形队列作为其缓冲区,队列的长度是在创建chan 时指定的。下图展示了一个可缓冲6个元素的管道。
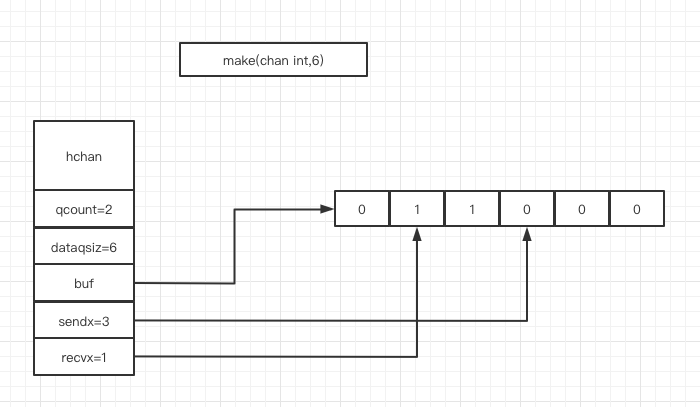
- dataqsiz 表示了队列长度为6,即可缓存6个数据
- buf 指向了队列的内存
- qcount 表示队列中还有两个元素
- sendx 表示后续写入的数据存储的位置,取值为[0:6)
- recvx 表示从该位置读取数据,取值为[0:6)
使用数组数显队列是比较常见的操作,sendx和recvx分别表示队尾和队首,sendx表示数据写入的位置,recvx表示数据读取的位置。
等待队列
从管道读取数据时,如果管道缓冲区为空或者没有缓冲区,则当前协程会被阻塞,并加入recvq队列。向管道写入数据时,如果管道没有缓冲区或者缓冲区已满,则当前协程会被阻塞,并加入sendq队列。
下图展示了一个没有缓冲区的管道,有几个协程等待读取数据:
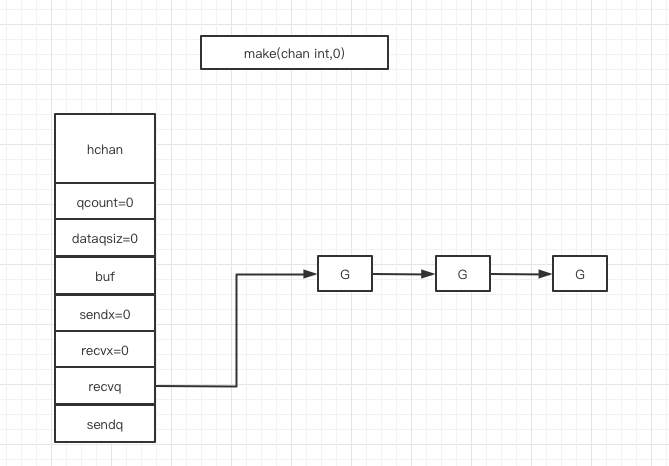
处于等待队列中的协程会在其他协程操作管道的时候被唤醒:
- 因读堵塞的协程会被向管道中写入数据的的协程操作唤醒
- 因写堵塞的协程会被向管道中读取数据的协程操作唤醒
注意,一般情况下recvq和sendq至少有一个为空。只有一个例外,那就是同一个协程使用select语句向管道中一边写入数据,一边读取数据,此时协程会分别位于两个等待队列中。
类型信息
一个管道只能传递一种类型的值,类型信息存储在hchan数据结构中。
- elemtype 代表类型,用于在数据传递过程中赋值
- elemsize 代表类型大小,用于在buf中定位元素的位置
如果需要想管道中传递任意类型的数据,则可以使用interface{}类型。
互斥锁
一个管道同时仅允许被一个协程读写,线程安全。
管道操作
创建管道
创建管道的过程实际上是初始化hchan结构,其中类型信息和缓冲器长度由内置函数make()指定,buf的大小则由元素大小和缓冲区长度共同决定。
创建管道的代码如下所示:
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// compiler checks this but be safe.
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// Hchan does not contain pointers interesting for GC when elements stored in buf do not contain pointers.
// buf points into the same allocation, elemtype is persistent.
// SudoG's are referenced from their owning thread so they can't be collected.
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
var c *hchan
switch {
case mem == 0:
// Queue or element size is zero.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// Elements do not contain pointers.
// Allocate hchan and buf in one call.
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// Elements contain pointers.
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
return c
}
向管道写入数据
像一个管道中写入数据的简单过程如下:
- 如果缓冲区中有空余位置,则将数据写入缓冲区,结束发送过程
- 如果缓冲区中没有空余位置,则将当前协程加入sendq队列,进入睡眠并等待被读协程唤醒
在实现时有一个小技巧,当接受队列recvq不为空时,说明缓冲区中没有数据但有协程在等待数据,此时会把数据直接传递给recvq队列中的第一个协程,而不必再写入缓冲区。
简单流程如下图所示:

从管道读取数据
从一个管道读取数据的简单过程如下:
- 如果缓冲区中有数据,则从缓冲区取出数据,结束读过程
- 如果缓冲区中没有数据,则将当前协程加入recvq队列,进入睡眠并等待被写协程唤醒
类似的,如果等待发送队列sendq不为空,且没有缓冲区,那么此时将直接从sendq队列的第一个协程中获取数据。
简单流程如下所示:

关闭管道
关闭管道时会把recvq中的协程全部唤醒,这些协程获取的数据都为对应类型的零食。同时会把sendq队列的协程全部唤醒,但这些协程会触发panic。
除此之外,其他会触发panic的操作还有:
- 关闭值为nil的管道
- 关闭已经关闭的管道
- 向已经关闭的管道写入数据
常见用法
单向管道
顾名思义,单向管道指只能用于发送或者读取数据,由管道的数据结构可以指导,实际上并没有单向管道。所谓单向管道只是对管道的一种使用限制,
一个简单的示例程序如下:
func readChan(ch <-chan int){
<- ch
}
func writeChan(ch chan<- int){
ch <- 1
}
func main(){
var mychan = make(chan int,10)
writeChan(mychan)
readChan(mychan)
}
mychan是一个正常的管道,而readChan()参数限制了传入的管道只能用来读,writeChan()参数限制了传入的管道只能用来写。
select
使用select可以监控多个管道,当其中某一个管道可操作时就触发相应的case分支。
一个简单的示例程序如下:
package main
import (
"fmt"
"time"
)
func addNUmberToChan(ch chan int) {
for {
ch <- 1
time.Sleep(1 * time.Second)
}
}
func main() {
var chan1 = make(chan int, 10)
var chan2 = make(chan int, 10)
go addNUmberToChan(chan1)
go addNUmberToChan(chan2)
for {
select {
case e := <-chan1:
fmt.Printf("Get element from chan1 : %d \n", e)
case e := <-chan2:
fmt.Printf("Get element from chan2 : %d \n", e)
default:
fmt.Printf("No element in chan1 and chan2. \n")
time.Sleep(1 * time.Second)
}
}
}
程序中创建了两个管道,chan1 和 chan2。addNUmberToChan()函数会向两个管道中周期性地写入数据。通过select可以监控到两个管道,任意一个可读时就从中读出数据。
程序输出如下:
No element in chan1 and chan2.
Get element from chan2 : 1
Get element from chan1 : 1
Get element from chan1 : 1
Get element from chan2 : 1
No element in chan1 and chan2.
No element in chan1 and chan2.
Get element from chan1 : 1
Get element from chan2 : 1
Get element from chan1 : 1
Get element from chan2 : 1
No element in chan1 and chan2.
No element in chan1 and chan2.
Get element from chan1 : 1
Get element from chan2 : 1
No element in chan1 and chan2.
由输出可见,从管道中读出数据的顺序是随机的,事实上select语句的多个case语句的执行顺序是随机的,关于select的实现原理后面会有专门的篇章进行分析。
通过这个例子可以看出,select的case语句读管道时不会堵塞,尽管管道中没有数据。这是由于case语句编译后调用读管道时会明确的传入不堵塞的参数,读取不到数据不会将当前的协程加入到等待队列,而是直接返回。
for-range
通过for-range可以持续的从管道中读取数据,好像在遍历一个数组一样,当管道中没有数据时会阻塞当前协程,与读管道时的阻塞处理机制一样。即便管道被关闭,for-range也可以优雅的结束,如下所示:
func chanRange(ch chan int) {
for e := range ch {
fmt.Printf("Get element from chan : %d \n", e)
}
}