学习笔记 | 独热编码(One-Hot Encoding)
最近学习机器学习,接触到独热编码相关内容,参考了一些资料,加上自己的思考,做出了如下总结。
一、什么是独热编码
独热编码,即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。(百度百科)
说起来这么复杂,举个例子就很容易理解了:
比如颜色特征有3种:红色、绿色和黄色,转换成独热编码分别表示为(此时上述描述中的N=3):001, 010, 100。(当然转换成100, 010, 001也可以,只要有确定的一一对应关系即可)
红色、绿色和黄色分别转换成1, 2, 3行不行,一般不这样处理,这样处理也不叫独热编码了,只能说是文本转换成数字,具体原因可以往下看。
二、为什么要使用独热编码
在机器学习算法中,一般是通过计算特征之间距离或相似度来实现分类、回归的。一般来说,距离或相似度都是在欧式空间计算余弦相似性得到。
对于上述的离散型颜色特征,1、2、3编码方式就无法用在机器学习中,因为它们之间存在大小关系,而实际上各颜色特征之间并没有大小关系,红色>绿色??? 所以,独热编码便发挥出了作用,特征之间的计算会更加合理。
三、独热编码的优缺点
优点:为处理离散型特征提供了方法,在一定程度上扩充了特征属性。
缺点:当特征的类别很多时,特征空间会变得非常大,在这种情况下,一般可以用PCA来减少维度。
四、什么时候不需要使用独热编码
1、离散特征的取值之间没有大小意义时,可以使用独热编码。
当离散特征的取值之间有大小意义或者有序时,比如衣服尺寸: [X, XL, XXL],那么就不能使用独热编码,而使用数值的映射{X: 1, XL: 2, XXL: 3}。
2、如果特征是离散的,并且不用独热编码就可以很合理的计算出距离,就没必要进行独热编码。
3、有些并不是基于向量空间度量的算法,数值只是类别符号,没有偏序关系,就不用进行独热编码。
五、如何用Python实现独热编码
方式一:get_dummies 官方文档
将类别变量转换成虚拟变量/指示变量,也叫哑变量。
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None,
sparse=False, drop_first=False, dtype=None)各参数的含义:
data: array-like, Series, or DataFrame
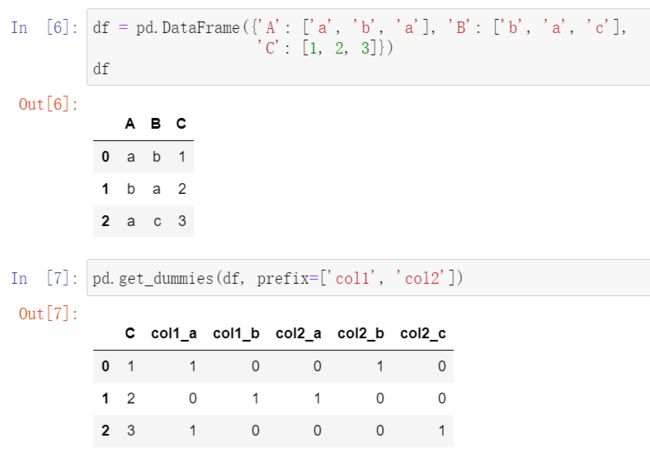
prefix: string, list of strings, or dict of strings, default None
prefix_sep: str, default '_' (转换后列名的前缀)
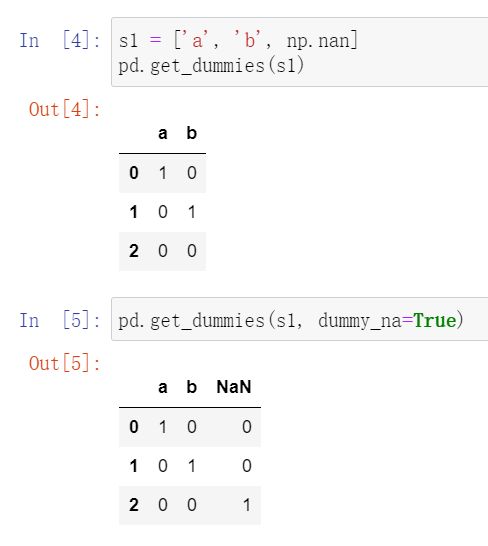
dummy_na: bool, default False(增加一列表示空缺值,如果False就忽略空缺值)
columns: list-like, default None (指定需要实现类别转换的列名)
sparse: bool, default False
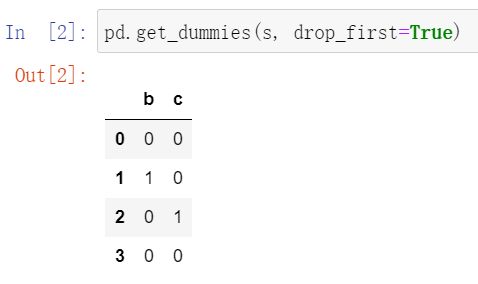
drop_first: bool, default False (获得k中的k-1个类别值,去除第一个)
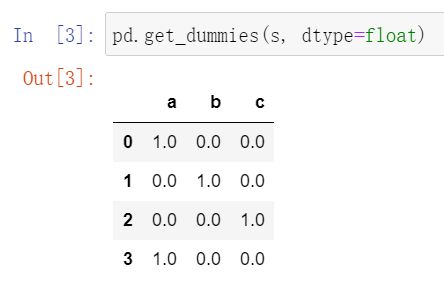
dtype: dtype, default np.uint8
——举例子:

方式二:sklearn
Sklearn提供了一个编码器OneHotEncoder,用于将整数分类值转换成独热向量。

一共有4个值,3个特征:
对于第1个特征,也即第1列 [0, 1, 0, 1],有0、1两种取值,对应的编码为10, 01;
对于第2个特征,也即第2列 [0, 1, 2, 0],有0、1、2三种取值,对应的编码为100, 010, 001;
对于第3个特征,也即第3列 [3, 0, 1, 2],有0、1、2、3四种取值,对应的编码为1000, 0100, 0010, 0001。
需要转换的是[0, 1, 2],对应的结果为100100010。
在sklearn中,可以先通过factorize()将文本转换为整数分类,然后通过OneHotEncoder将整数分类转换为独热向量。当然,也可以使用CategoricalEncoder类一步到位。
最后,欢迎大家关注我的WX公众号:且听数据说,更多内容与你分享,期待相遇。