ASP.NET MVC Filters 4种默认过滤器的使用【附示例】
过滤器(Filters)的出现使得我们可以在ASP.NET MVC程序里更好的控制浏览器请求过来的URL,不是每个请求都会响应内容,只响应特定内容给那些有特定权限的用户,过滤器理论上有以下功能:
- 判断登录与否或用户权限
- 决策输出缓存
- 防盗链
- 防蜘蛛
- 本地化与国际化设置
- 实现动态Action(做权限管理系统的好东西)
先来看一个简单的例子:新建一个AuthFiltersController,里面有两个Action
public ActionResult Index()
{
return View();
}
[Authorize]
public ActionResult Welcome()
{
return View();
}
很显然,第一个名为Index的Action是没有过滤的,任何身份的请求都可以通过,只要在浏览器的URL栏里键入:localhost:****/AuthFilters/Index 就能得到对应的视图响应;
而第二个名为Welcome的Action上面标注了[Authorize],表示这是一个只处理那些通过身份验证的URL请求,如果没有通过身份验证就请求这个Action会被带到登录页面。看看配置文件:
根据配置文件的定义,登录页面就是AccountController下名为LogOn的Action,那么就新建一个AccountController,并新建两个Action:
public ActionResult LogOn()
{
return View();
}
[HttpPost]
public ActionResult LogOn(LogOnViewModel model)
{
if (model.UserName.Trim() == model.Password.Trim()) //伪代码,只要输入的用户名和密码一样就过
{
if (model.RememberMe)
FormsAuthentication.SetAuthCookie(model.UserName, true); //2880分钟有效期的cookie
else
FormsAuthentication.SetAuthCookie(model.UserName, false); //会话cookie
return RedirectToAction("Welcome", "AuthFilters");
}
else
return View(model);
}
第一个是处理Get请求用于响应视图页面的,第二个是处理用户点击提交回发的登录表单。
LogOnViewModel是用户登录实体类,看具体定义:
////// 用户登录类 /// public class LogOnViewModel { ////// 用户名 /// public string UserName { get; set; } ////// 密码 /// public string Password { get; set; } ////// 记住我 /// public bool RememberMe { get; set; } }
ok,按F6编译下项目,再按Ctrl + F5运行下项目,在URL里输入:localhost:****/AuthFilters/Index 很轻松的得到了Index这个Action的响应

再定位到:localhost:****/AuthFilters/Welcome

可见,虽然定位到了Welcome这个Action,但是却并不像Index一样直接返回对应的视图,而是被带到了登录页面。就是因为Welcome这个Action上被标注了[Authorize],拒绝了所以未验证用户的访问。
既然拒绝了未验证的用户,那就登录下通过验证,看看上面LogOn里写的伪代码就知道,输入相同的用户名和密码就能登录成功,用户名和密码都输入“wangjie”试试:
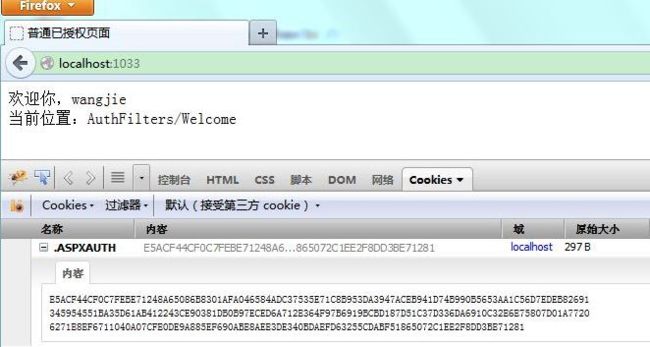
已经通过验证并得到Welcome这个Action的响应了。相比之前就是多生成了一个名为“.ASPXAUTH”的Cookie,这是个默认名,配置文件里可以修改。同时,如果登录的时候勾选了“记住我”那么此Cookie的过期时间就是配置文件里定义的2880分钟。
ok,现在提高下难度,只设置名为“a”、“bb”、“ccc”的用户可以访问欢迎页面:
[Authorize(Users = "a,bb,ccc")]
public ActionResult Welcome()
{
ViewBag.Message = "已登录";
return View();
}
再用“wangjie”登录下发现跳不到欢迎页面了,因为指定了a、bb、ccc这三个用户才可以登录。
先不管为何在Action上标注Users = "a,bb,ccc"就可以控制可以访问的用户,但从操作性上来说这样控制Action的访问权限还是很方便的。但是如果项目大,用户对应的角色和权限变化比较大,每次变化都来重新标注Action显然不合适。MVC框架提供的过滤器(Filters)就派上了用场:

上图是Asp.Net MVC框架提供的几种默认Filter:授权筛选器、操作筛选器、结果筛选器、异常筛选器,下面来一一讲解,先看演示Demo结构图:

一、授权筛选器
授权筛选器用于实现IAuthorizationFilter接口和做出关于是否执行操作方法(如执行身份验证或验证请求的属性)的安全决策。 AuthorizeAttribute类和RequireHttpsAttribute类是授权筛选器的示例。授权筛选器在任何其他筛选器之前运行。
新建一个继承AuthorizeAttribute类的UserAuthorize类,F12定位到AuthorizeAttribute类,看看内部申明:
public AuthorizeAttribute();
public string Roles { get; set; }
public override object TypeId { get; }
public string Users { get; set; }
protected virtual bool AuthorizeCore(HttpContextBase httpContext);
protected virtual void HandleUnauthorizedRequest(AuthorizationContext filterContext);
public virtual void OnAuthorization(AuthorizationContext filterContext);
protected virtual HttpValidationStatus OnCacheAuthorization(HttpContextBase httpContext);
上面演示的指定用户才可以访问就是利用了Users属性,并由基类帮助我们验证,只放指定的Users用户通过。要实现自定义的验证只需重写下OnAuthorization和AuthorizeCore方法。为了演示效果,新建一个SampleData类用来初始化数据:
////// 测试数据(实际项目中,这些数据应该从数据库拿) /// public class SampleData { public static Listusers; public static List roles; public static List roleWithControllerAndAction; static SampleData() { // 初始化用户 users = new List (){ new User(){ Id=1, UserName="wangjie", RoleId=1}, new User(){ Id=2, UserName ="senior1", RoleId=2}, new User(){ Id=3, UserName ="senior2", RoleId=2}, new User(){ Id=5, UserName="junior1", RoleId=3}, new User(){ Id=6, UserName="junior2", RoleId=3}, new User(){ Id=6, UserName="junior3", RoleId=3} }; // 初始化角色 roles = new List () { new Role() { Id=1, RoleName="管理员", Description="管理员角色"}, new Role() { Id=2, RoleName="高级会员", Description="高级会员角色"}, new Role() { Id=3, RoleName="初级会员", Description="初级会员角色"} }; // 初始化角色控制器和Action对应类 roleWithControllerAndAction = new List () { new RoleWithControllerAction(){ Id=1, ControllerName="AuthFilters", ActionName="AdminUser", RoleIds="1"}, new RoleWithControllerAction(){ Id=2, ControllerName="AuthFilters", ActionName="SeniorUser", Ids="1,2"}, new RoleWithControllerAction(){ Id=3, ControllerName="AuthFilters", ActionName="JuniorUser", Ids="1,2,3"}, new RoleWithControllerAction(){ Id=4, ControllerName="ActionFilters", ActionName="Index", RoleIds="2,3"} }; } }
简单明了,用户拥有角色,不同角色可以访问的Action也不同。这比较符合权限项目里的控制。再看看UserAuthorize类的具体定义:
////// 自定义用户授权 /// public class UserAuthorize : AuthorizeAttribute { ////// 授权失败时呈现的视图 /// public string AuthorizationFailView { get; set; } ////// 请求授权时执行 /// public override void OnAuthorization(AuthorizationContext filterContext) { //获得url请求里的controller和action: string controllerName = filterContext.RouteData.Values["controller"].ToString().ToLower(); string actionName = filterContext.RouteData.Values["action"].ToString().ToLower(); //string controllerName = filterContext.ActionDescriptor.ControllerDescriptor.ControllerName; //string actionName = filterContext.ActionDescriptor.ActionName; //根据请求过来的controller和action去查询可以被哪些角色操作: Models.RoleWithControllerAction roleWithControllerAction = base.SampleData.roleWithControllerAndAction.Find(r => r.ControllerName.ToLower() == controllerName && tionName.ToLower() == actionName); if (roleWithControllerAction != null) { this.Roles = roleWithControllerAction.RoleIds; //有权限操作当前控制器和Action的角色id } base.OnAuthorization(filterContext); //进入AuthorizeCore } ////// 自定义授权检查(返回False则授权失败) /// protected override bool AuthorizeCore(HttpContextBase httpContext) { if (httpContext.User.Identity.IsAuthenticated) { string userName = httpContext.User.Identity.Name; //当前登录用户的用户名 Models.User user = Database.SampleData.users.Find(u => u.UserName == userName); //当前登录用户对象 if (user != null) { Models.Role role = Database.SampleData.roles.Find(r => r.Id == user.RoleId); //当前登录用户的角色 foreach (string roleid in Roles.Split(',')) { if (role.Id.ToString() == roleid) return true; } return false; } else return false; } else return false; //进入HandleUnauthorizedRequest } ////// 处理授权失败的HTTP请求 /// protected override void HandleUnauthorizedRequest(AuthorizationContext filterContext) { filterContext.Result = new ViewResult { ViewName = AuthorizationFailView }; } }
自定义好授权类就可以到控制器上使用了,看看AuthFiltersController类:
public class AuthFiltersController : Controller
{
public ActionResult Index()
{
return View();
}
//[Authorize(Users = "a,bb,ccc")]
[Authorize]
public ActionResult Welcome()
{
ViewBag.Message = "普通已授权页面";
return View();
}
[UserAuthorize(AuthorizationFailView = "Error")] //管理员页面
public ActionResult AdminUser()
{
ViewBag.Message = "管理员页面";
return View("Welcome");
}
[UserAuthorize(AuthorizationFailView = "Error")] //会员页面(管理员、会员都可访问)
public ActionResult SeniorUser()
{
ViewBag.Message = "高级会员页面";
return View("Welcome");
}
[UserAuthorize(AuthorizationFailView = "Error")] //游客页面(管理员、会员、游客都可访问)
public ActionResult JuniorUser()
{
ViewBag.Message = "初级会员页面";
return View("Welcome");
}
}
Welcome这个Action使用了默认的授权验证,只要登陆成功就可以访问。其他几个Action上都标注了自定义的UserAuthorize,并没有标注Users="....",Roles=".....",因为这样在Action上写死用户或者角色控制权限显然是不可行的,用户和角色的对应以及不同的角色可以操作的Action应该是从数据库里取出来的。为了演示就在SampleData类里初始化了一些用户和角色信息,根据SampleData类的定义,很明显wangjie拥有1号管理员角色,可以访问AuthFilters这个控制器下的所有Action,senior1、senior2拥有2号高级会员的角色,可以访问AuthFilters这个控制器下除了AdminUser之外的Action等等
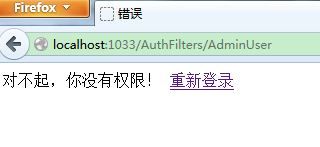
再次登陆下,就发现拥有高级会员角色的用户senior1是不可以访问AdminUser这个Action,会被带到AuthorizationFailView属性指定的Error视图:
二、操作筛选器、结果筛选器
操作筛选器用于实现IActionFilter接口以及包装操作方法执行。IActionFilter接口声明两个方法:OnActionExecuting和OnActionExecuted。OnActionExecuting在操作方法之前运行。OnActionExecuted在操作方法之后运行,可以执行其他处理,如向操作方法提供额外数据、检查返回值或取消执行操作方法。
结果筛选器用于实现IResultFilter接口以及包装ActionResult对象的执行。IResultFilter接口声明两个方法OnResultExecuting和OnResultExecuted。OnResultExecuting在执行ActionResult对象之前运行。OnResultExecuted在结果之后运行,可以对结果执行其他处理,如修改 HTTP 响应。OutputCacheAttribute 类是结果筛选器的一个示例。
操作筛选器和结果筛选器都实现ActionFilterAttribute类,看看类里定义的方法:
public virtual void OnActionExecuted(ActionExecutedContext filterContext); public virtual void OnActionExecuting(ActionExecutingContext filterContext); public virtual void OnResultExecuted(ResultExecutedContext filterContext); public virtual void OnResultExecuting(ResultExecutingContext filterContext);
根据方法的名字就知道4个方法执行的顺序了:
OnActionExecuting是Action执行前的操作、OnActionExecuted则是Action执行后的操作、OnResultExecuting是解析ActionResult前执行、OnResultExecuted是解析ActionResult后执行
即:Action执行前:OnActionExecuting方法先执行→Action执行 →OnActionExecuted方法执行→OnResultExecuting方法执行→返回的ActionRsult中的 executeResult方法执行→OnResultExecuted执行
完全可以重写OnActionExecuting方法实现上面授权筛选器一样的功能,因为OnActionExecuting方法是在Action方法执行前运行的,自定义一个实现ActionFilterAttribute类的ActionFilters类,OnActionExecuting方法这么写:
////// 在执行操作方法之前由 MVC 框架调用 /// public override void OnActionExecuting(ActionExecutingContext filterContext) { string userName = filterContext.HttpContext.User.Identity.Name; //当前登录用户的用户名 Models.User user = Database.SampleData.users.Find(u => u.UserName == userName); //当前登录用户对象 if (user != null) { Models.Role role = Database.SampleData.roles.Find(r => r.Id == user.RoleId); //当前登录用户的角色 //获得controller: string controllerName = filterContext.RouteData.Values["controller"].ToString().ToLower(); //string actionName = filterContext.RouteData.Values["action"].ToString().ToLower(); if (ActionName == null) ActionName = filterContext.RouteData.Values["action"].ToString(); //查询角色id Models.RoleWithControllerAction roleWithControllerAction = .SampleData.roleWithControllerAndAction.Find(r => r.ControllerName.ToLower() == controllerName && Name.ToLower() == ActionName.ToLower()); if (roleWithControllerAction != null) { this.Roles = roleWithControllerAction.RoleIds; //有权限操作当前控制器和Action的角色id } if (!string.IsNullOrEmpty(Roles)) { foreach (string roleid in Roles.Split(',')) { if (role.Id.ToString() == roleid) return; //return就说明有权限了,后面的代码就不跑了,直接返回视图给浏览器就好 } } filterContext.Result = new EmptyResult(); //请求失败输出空结果 HttpContext.Current.Response.Write("对不起,你没有权限!"); //打出提示文字 //return; } else { //filterContext.Result = new ViewResult { ViewName = "Error" }; filterContext.Result = new EmptyResult(); HttpContext.Current.Response.Write("对不起,请先登录!"); //return; } //base.OnActionExecuting(filterContext); }
看看如何在ActionFiltersController控制器里使:
public class ActionFiltersController : Controller
{
[ActionFilters]
public ActionResult Index()
{
return View();
}
[ActionFilters(ActionName = "Index")]
public ActionResult Details()
{
return View();
}
[ActionFilters]
public ActionResult Test()
{
return View();
}
}
很明显Index和Details这两个Action同用一个权限,看看初始化数据SampleData类的定义:
new RoleWithControllerAction(){ Id=4, ControllerName="ActionFilters", ActionName="Index", RoleIds="2,3"}
只有2和3号角色可以访问,那么1号角色的wangjie用户应该是访问不了的,登录试试:

三、异常筛选器
异常筛选器用于实现IExceptionFilter接口,并在ASP.NET MVC管道执行期间引发了未处理的异常时执行。异常筛选器可用于执行诸如日志记录或显示错误页之类的任务。HandleErrorAttribute类是异常筛选器的一个示例。
有之前授权筛选器、操作和结果筛选器的使用经验,再看异常筛选器就简单许多了,来看看自定义的继承自HandleErrorAttribute类的异常筛选类ExceptionFilters:
////// 异常筛选器 /// public class ExceptionFilters : HandleErrorAttribute { ////// 在发生异常时调用 /// public override void OnException(ExceptionContext filterContext) { //if (!filterContext.ExceptionHandled && filterContext.Exception is NullReferenceException) if (!filterContext.ExceptionHandled) { //获取出现异常的controller名和action名,用于记录 string controllerName = (string)filterContext.RouteData.Values["controller"]; string actionName = (string)filterContext.RouteData.Values["action"]; //定义一个HandErrorInfo,用于Error视图展示异常信息 HandleErrorInfo model = new HandleErrorInfo(filterContext.Exception, controllerName, actionName); ViewResult result = new ViewResult { ViewName = this.View, ViewData = new ViewDataDictionary(model) //定义ViewData,泛型 }; filterContext.Result = result; filterContext.ExceptionHandled = true; } //base.OnException(filterContext); } }
看看如何在视图中使用:
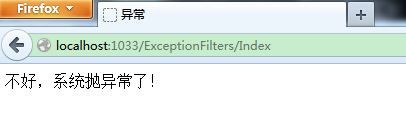
[ExceptionFilters(View = "Exception")]
public ActionResult Index()
{
throw new NullReferenceException("测试抛出异常!");
}
View是制定的捕获异常后显示给用户的视图:
再看一个Action:
[ExceptionFilters(View = "ExceptionDetails")]
public ActionResult Details()
{
int i = int.Parse("hello,world!");
return View();
}
把string类型的数据强转int,肯定得报FormatException异常,看看ExceptionDetails视图如何定义的:
@model System.Web.Mvc.HandleErrorInfo
@{
Layout = null;
}
异常
抛错控制器:@Model.ControllerName 抛错方法:@Model.ActionName 抛错类型:@Model.Exception.GetType
().Name
异常信息:@Model.Exception.Message
堆栈信息:
@Model.Exception.StackTrace
浏览器显示结果:

转载自:http://www.360doc.com/showweb/0/0/765540458.aspx
数据库常见死锁原因及处理
数据库是一个多用户使用的共享资源,当多个用户并发地存取数据时,在数据库中就会产生多个事务同时存取同一数据的情况。若对并发操作不加控制就可能会读取和存储不正确的数据,破坏数据库的一致性。加锁是实现数据库并发控制的一个非常重要的技术。在实际应用中经常会遇到的与锁相关的异常情况,当两个事务需要一组有冲突的锁,而不能将事务继续下去的话,就会出现死锁,严重影响应用的正常执行。
在数据库中有两种基本的锁类型:排它锁(Exclusive Locks,即X锁)和共享锁(Share Locks,即S锁)。当数据对象被加上排它锁时,其他的事务不能对它读取和修改。加了共享锁的数据对象可以被其他事务读取,但不能修改。数据库利用这两种基本的锁类型来对数据库的事务进行并发控制。
下面总结下这两种锁造成的常见的死锁情况与解决方案:
一. 事务之间对资源访问顺序的交替
- 出现原因:
一个用户A 访问表A(锁住了表A),然后又访问表B;另一个用户B 访问表B(锁住了表B),然后企图访问表A;这时用户A由于用户B已经锁住表B,它必须等待用户B释放表B才能继续,同样用户B要等用户A释放表A才能继续,这就死锁就产生了。 - 解决方法:
这种死锁比较常见,是由于程序的BUG产生的,除了调整的程序的逻辑没有其它的办法。仔细分析程序的逻辑,对于数据库的多表操作时,尽量按照相同的顺序进行处理,尽量避免同时锁定两个资源,如操作A和B两张表时,总是按先A后B的顺序处理, 必须同时锁定两个资源时,要保证在任何时刻都应该按照相同的顺序来锁定资源。
二. 并发修改同一记录
- 出现原因:
用户A查询一条纪录,然后修改该条纪录;这时用户B修改该条纪录,这时用户A的事务里锁的性质由查询的共享锁企图上升到独占锁,而用户B里的独占锁由于A有共享锁存在所以必须等A释放掉共享锁,而A由于B的独占锁而无法上升的独占锁也就不可能释放共享锁,于是出现了死锁。这种死锁由于比较隐蔽,但在稍大点的项目中经常发生。
一般更新模式由一个事务组成,此事务读取记录,获取资源(页或行)的共享 (S) 锁,然后修改行,此操作要求锁转换为排它 (X) 锁。如果两个事务获得了资源上的共享模式锁,然后试图同时更新数据,则一个事务尝试将锁转换为排它 (X) 锁。共享模式到排它锁的转换必须等待一段时间,因为一个事务的排它锁与其它事务的共享模式锁不兼容;发生锁等待。第二个事务试图获取排它 (X) 锁以进行更新。由于两个事务都要转换为排它 (X) 锁,并且每个事务都等待另一个事务释放共享模式锁,因此发生死锁。 - 解决方法:
a. 使用乐观锁进行控制。乐观锁大多是基于数据版本(Version)记录机制实现。即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个“version”字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。乐观锁机制避免了长事务中的数据库加锁开销(用户A和用户B操作过程中,都没有对数据库数据加锁),大大提升了大并发量下的系统整体性能表现。Hibernate 在其数据访问引擎中内置了乐观锁实现。需要注意的是,由于乐观锁机制是在我们的系统中实现,来自外部系统的用户更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库中。
b. 使用悲观锁进行控制。悲观锁大多数情况下依靠数据库的锁机制实现,如Oracle的Select … for update语句,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。如一个金融系统,当某个操作员读取用户的数据,并在读出的用户数据的基础上进行修改时(如更改用户账户余额),如果采用悲观锁机制,也就意味着整个操作过程中(从操作员读出数据、开始修改直至提交修改结果的全过程,甚至还包括操作员中途去煮咖啡的时间),数据库记录始终处于加锁状态,可以想见,如果面对成百上千个并发,这样的情况将导致灾难性的后果。所以,采用悲观锁进行控制时一定要考虑清楚。
c. SqlServer可支持更新锁
为解决死锁,SqlServer引入更新锁,它有如下特征:
(1) 加锁的条件:当一个事务执行update语句时,数据库系统会先为事务分配一把更新锁。
(2) 解锁的条件:当读取数据完毕,执行更新操作时,会把更新锁升级为独占锁。
(3) 与其他锁的兼容性:更新锁与共享锁是兼容的,也就是说,一个资源可以同时放置更新锁和共享锁,但是最多放置一把更新锁。这样,当多个事务更新相同的数据时,只有一个事务能获得更新锁,然后再把更新锁升级为独占锁,其他事务必须等到前一个事务结束后,才能获取得更新锁,这就避免了死锁。
(4) 并发性能:允许多个事务同时读锁定的资源,但不允许其他事务修改它。
例子如下:
T1:
begin tran
select * from table(updlock) (加更新锁) update table set column1='hello' T2: begin tran select * from table(updlock) update table set column1='world'更新锁的意思是:“我现在只想读,你们别人也可以读,但我将来可能会做更新操作,我已经获取了从共享锁(用来读)到排他锁(用来更新)的资格”。一个事物只能有一个更新锁获此资格。
T1执行select,加更新锁。
T2运行,准备加更新锁,但发现已经有一个更新锁在那儿了,只好等。
当后来有user3、user4…需要查询table表中的数据时,并不会因为T1的select在执行就被阻塞,照样能查询,提高了效率。
三. 索引不当导致全表扫描
- 出现原因:
如果在事务中执行了一条不满足条件的语句,执行全表扫描,把行级锁上升为表级锁,多个这样的事务执行后,就很容易产生死锁和阻塞。类似的情况还有当表中的数据量非常庞大而索引建的过少或不合适的时候,使得经常发生全表扫描,最终应用系统会越来越慢,最终发生阻塞或死锁。 - 解决方法:
SQL语句中不要使用太复杂的关联多表的查询;使用“执行计划”对SQL语句进行分析,对于有全表扫描的SQL语句,建立相应的索引进行优化。
四.事务封锁范围大且相互等待
.NET源码中的链表
.NET中自带的链表是LinkedList类,并且已经直接实现成了双向循环链表。
其节点类LinkedListNode的数据结构如下,数据项包括指示到某个链表的引用,以及左,右节点和值。
- public sealed class LinkedListNode<T>
- {
- internal LinkedList<T> list;
- internal LinkedListNode<T> next;
- internal LinkedListNode<T> prev;
- internal T item;
- }
另外,获取前一个节点和后一个节点的实现如下:注意:里面的if-else结构的意义是当前一个(后一个)节点不为空且不是头节点时才不返回null,这样做的意义是当链表内只有1个节点时,其prev和next是指向自身的。
- [__DynamicallyInvokable]
- public LinkedListNode
Next - {
- [__DynamicallyInvokable] get
- {
- if (this.next != null && this.next != this.list.head)
- return this.next;
- else
- return (LinkedListNode
) null; - }
- }
- [__DynamicallyInvokable]
- public LinkedListNode
Previous - {
- [__DynamicallyInvokable] get
- {
- if (this.prev != null && this != this.list.head)
- return this.prev;
- else
- return (LinkedListNode
) null; - }
- }
过有一个把链表置为无效的方法定义如下:
- internal void Invalidate()
- {
- this.list = (LinkedList
) null; - this.next = (LinkedListNode
) null; - this.prev = (LinkedListNode
) null; - }
而LinkedList的定义如下:主要的两个数据是头节点head以及长度count。
- public class LinkedList
: ICollection , IEnumerable , ICollection, IEnumerable, ISerializable, IDeserializationCallback - {
- internal LinkedListNode
head; - internal int count;
- internal int version;
- private object _syncRoot;
- private SerializationInfo siInfo;
- private const string VersionName = "Version";
- private const string CountName = "Count";
- private const string ValuesName = "Data";
而对此链表的主要操作,包括:
- 插入节点到最后,Add(),也是AddLast()。
- 在某个节点后插入,AddAfter(Node, T)。
- 在某个节点前插入,AddBefore(Node, T)。
- 插入到头节点之前,AddFirst(T)。
- 清除所有节点,Clear()。
- 是否包含某个值,Contains(T),也就是Find()。
- 查找某个节点的引用,Find()和FindLast()。
- 复制到数组,CopyTo(Array)
- 删除某个节点,Remove(T)。
- 内部插入节点,InternalInsertNodeBefore()
- 内部插入节点到空链表,InternalInsertNodeToEmptyList()
- 内部删除节点,InternalRemoveNode()
- 验证新节点是否有效,ValidateNewNode()
- 验证节点是否有效,ValidateNode()
- public void AddLast(LinkedListNode
node) - {
- this.ValidateNewNode(node);
- if (this.head == null)
- this.InternalInsertNodeToEmptyList(node);
- else
- this.InternalInsertNodeBefore(this.head, node);
- node.list = this;
- }
- internal void ValidateNewNode(LinkedListNode
node) - {
- if (node == null)
- throw new ArgumentNullException("node");
- if (node.list != null)
- throw new InvalidOperationException(SR.GetString("LinkedListNodeIsAttached"));
- }
如果头节点为空,则执行插入到空链表的操作:将节点的next和prev都指向为自己,并作为头节点。
- private void InternalInsertNodeToEmptyList(LinkedListNode
newNode) - {
- newNode.next = newNode;
- newNode.prev = newNode;
- this.head = newNode;
- ++this.version;
- ++this.count;
- }
- private void InternalInsertNodeBefore(LinkedListNode
node, LinkedListNode newNode) - {
- newNode.next = node;
- newNode.prev = node.prev;
- node.prev.next = newNode;
- node.prev = newNode;
- ++this.version;
- ++this.count;
- }
而插入新节点到指定节点之后的操作如下:同样还是调用的内部函数,把新节点插入到指定节点的下一个节点的之前。有点绕,但确实让这个内部函数起到多个作用了。
- public void AddAfter(LinkedListNode
node, LinkedListNode newNode) - {
- this.ValidateNode(node);
- this.ValidateNewNode(newNode);
- this.InternalInsertNodeBefore(node.next, newNode);
- newNode.list = this;
- }
而插入新节点到指定节点之前的操作如下:直接调用插入新节点的内部函数,另外还要判断指定的节点是否是头节点,如果是的话,要把头节点变成新的节点。
- public void AddBefore(LinkedListNode
node, LinkedListNode newNode) - {
- this.ValidateNode(node);
- this.ValidateNewNode(newNode);
- this.InternalInsertNodeBefore(node, newNode);
- newNode.list = this;
- if (node != this.head)
- return;
- this.head = newNode;
- }
把新链表插入到第一个节点(也就是变成头节点)的操作如下:如果链表为空就直接变成头节点,否则就插入到头节点之前,取代头节点。
- public void AddFirst(LinkedListNode
node) - {
- this.ValidateNewNode(node);
- if (this.head == null)
- {
- this.InternalInsertNodeToEmptyList(node);
- }
- else
- {
- this.InternalInsertNodeBefore(this.head, node);
- this.head = node;
- }
- node.list = this;
- }
查找链表中某个值的操作如下:注意直接返回null的条件是头节点为空。然后就是遍历了,因为是双向链表,所以要避免死循环(遍历到头节点时跳出)。
- public LinkedListNode
Find(T value) - {
- LinkedListNode
linkedListNode = this.head; - EqualityComparer
@default = EqualityComparer .Default; - if (linkedListNode != null)
- {
- if ((object) value != null)
- {
- while (!@default.Equals(linkedListNode.item, value))
- {
- linkedListNode = linkedListNode.next;
- if (linkedListNode == this.head)
- goto label_8;
- }
- return linkedListNode;
- }
- else
- {
- while ((object) linkedListNode.item != null)
- {
- linkedListNode = linkedListNode.next;
- if (linkedListNode == this.head)
- goto label_8;
- }
- return linkedListNode;
- }
- }
- label_8:
- return (LinkedListNode
) null; - }
删除某个节点的操作如下:
- public void Remove(LinkedListNode
node) - {
- this.ValidateNode(node);
- this.InternalRemoveNode(node);
- }
同样,内部删除节点的实现如下:如果节点指向自己,说明是头节点,所以直接把头节点置null。然后就是指针的指向操作了。
- internal void InternalRemoveNode(LinkedListNode
node) - {
- if (node.next == node)
- {
- this.head = (LinkedListNode
) null; - }
- else
- {
- node.next.prev = node.prev;
- node.prev.next = node.next;
- if (this.head == node)
- this.head = node.next;
- }
- node.Invalidate();
- --this.count;
- ++this.version;
- }
而清空链表的操作如下:遍历链表,逐个设置为无效,最后将内部的头节点也置为null。
- public void Clear()
- {
- LinkedListNode
linkedListNode1 = this.head; - while (linkedListNode1 != null)
- {
- LinkedListNode
linkedListNode2 = linkedListNode1; - linkedListNode1 = linkedListNode1.Next;
- linkedListNode2.Invalidate();
- }
- this.head = (LinkedListNode
) null; - this.count = 0;
- ++this.version;
- }
- public void CopyTo(T[] array, int index)
- {
- if (array == null)
- throw new ArgumentNullException("array");
- if (index < 0 || index > array.Length)
- {
- throw new ArgumentOutOfRangeException("index", SR.GetString("IndexOutOfRange", new object[1]
- {
- (object) index
- }));
- }
- else
- {
- if (array.Length - index < this.Count)
- throw new ArgumentException(SR.GetString("Arg_InsufficientSpace"));
- LinkedListNode
linkedListNode = this.head; - if (linkedListNode == null)
- return;
- do
- {
- array[index++] = linkedListNode.item;
- linkedListNode = linkedListNode.next;
- }
- while (linkedListNode != this.head);
- }
- }
以上。
多线程下C#如何保证线程安全?
多线程编程相对于单线程会出现一个特有的问题,就是线程安全的问题。所谓的线程安全,就是如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的。 线程安全问题都是由全局变量及静态变量引起的。
为了保证多线程情况下,访问静态变量的安全,可以用锁机制来保证,如下所示:

1 //需要加锁的静态全局变量
2 private static bool _isOK = false;
3 //lock只能锁定一个引用类型变量
4 private static object _lock = new object();
5 static void MLock()
6 {
7 //多线程
8 new System.Threading.Thread(Done).Start();
9 new System.Threading.Thread(Done).Start();
10 Console.ReadLine();
11 }
12
13 static void Done()
14 {
15 //lock只能锁定一个引用类型变量
16 lock (_lock)
17 {
18 if (!_isOK)
19 {
20 Console.WriteLine("OK");
21 _isOK = true;
22 }
23 }
24 }
需要注意的是,Lock只能锁住一个引用类型的对象。另外,除了锁机制外,高版本的C#中加入了async和await方法来保证线程安全,如下所示:
1 public static class AsynAndAwait
2 {
3 //step 1
4 private static int count = 0;
5 //用async和await保证多线程下静态变量count安全
6 public async static void M1()
7 {
8 //async and await将多个线程进行串行处理
9 //等到await之后的语句执行完成后
10 //才执行本线程的其他语句
11 //step 2
12 await Task.Run(new Action(M2));
13 Console.WriteLine("Current Thread ID is {0}", System.Threading.Thread.CurrentThread.ManagedThreadId);
14 //step 6
15 count++;
16 //step 7
17 Console.WriteLine("M1 Step is {0}", count);
18 }
19
20 public static void M2()
21 {
22 Console.WriteLine("Current Thread ID is {0}", System.Threading.Thread.CurrentThread.ManagedThreadId);
23 //step 3
24 System.Threading.Thread.Sleep(3000);
25 //step 4
26 count++;
27 //step 5
28 Console.WriteLine("M2 Step is {0}", count);
29 }
30 }
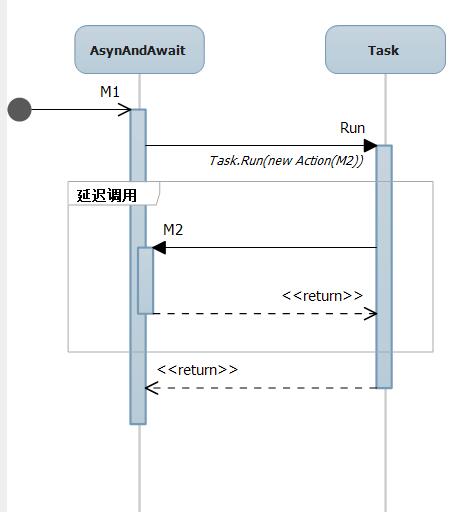
在时序图中我们可以知道,共有两个线程进行交互,如下图所示:
用async和await后,上述代码的执行顺序为下图所示:

若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时对一个变量执行读写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
转载自:http://www.cnblogs.com/isaboy/p/C_async_await_lock_safe_thread_multi.html
.net实现支付宝在线支付
流程参考《实物商品交易服务集成技术文档2.0.pdf》
网关地址http://paytest.rupeng.cn/AliPay/PayGate.ashx
网关参数说明:
partner:商户编号
return_url:回调商户地址(通过商户网站的哪个页面来通知支付成功!)
subject:商品名称
body:商品描述
out_trade_no:订单号!!!(由商户网站生成,支付宝不确保正确性,只负责转发。)
total_fee:总金额
seller_email:卖家邮箱
sign:数字签名。
为按顺序连接 (总金额、 商户编号、订单号、商品名称、商户密钥)的MD5值。
重定向的url("http://paytest.rupeng.cn/AliPay/PayGate.ashx?partner="
+ partner + "&return_url=" + Server.UrlEncode(return_url)
+ "&subject="
+ Server.UrlEncode(subject)
+ "&body=" + Server.UrlEncode(body)
+ "&out_trade_no=" + out_trade_no
+ "&total_fee=" + total_fee + "&seller_email="
+ Server.UrlEncode(seller_email) + "&sign=" + sign)
回调商户接口地址参数说明:
out_trade_no :订单号。给PayGate.ashx传过去的out_trade_no再传回来
returncode :返回码,字符串。ok为支付成功,error为支付失败。
total_fee :支付金额
sign :数字签名。为按顺序连接 (订单号、返回码、支付金额、商户密钥)为新字符串的MD5值。
(每个商户的密钥是商户自己设置的,每个人的都不一样,只有支付宝和商户知道,所以无法猜测、假冒)
MD5算法要用以下的,大小写都不能错:
///
/// 得到字符串的MD5散列值
///
///
///
public static String GetMD5(this string input)
{
System.Security.Cryptography.MD5CryptoServiceProvider x = new System.Security.Cryptography.MD5CryptoServiceProvider();
byte[] bs = System.Text.Encoding.UTF8.GetBytes(input);
bs = x.ComputeHash(bs);
System.Text.StringBuilder s = new System.Text.StringBuilder();
foreach (byte b in bs)
{
s.Append(b.ToString("x2").ToLower());
}
return s.ToString();
}
///
/// 付款
///
///
///
protected void Unnamed1_Click(object sender, EventArgs e)
{
string partner = "2";//商户编号
string return_url = "http://localhost:5059/ReturnPage.ashx";//回调商户地址(通过商户网站的哪个页面来通知支付成功!)
string subject = "飞机"; //商品名称
string body = "非常大的飞机"; //商品描述
string out_trade_no = "aaabbb888"; //订单号!(由商户网站生成,支付宝不确保正确性,只负责转发。)
string total_fee = "9"; //总金额
string seller_email = "[email protected]";//卖家邮箱
//商户密钥 abc123//不要写到url中
//为按顺序连接 (总金额、 商户编号、订单号、商品名称、商户密钥)的MD5值。
string sign = CommonHelper.getMD5Str(total_fee + partner + out_trade_no + subject + "abc123");//数字签名。
Response.Redirect("http://paytest.rupeng.cn/AliPay/PayGate.ashx?partner="
+ partner + "&return_url=" + Server.UrlEncode(return_url) + "&subject=" + Server.UrlEncode(subject) + "&body=" + Server.UrlEncode(body) + "&out_trade_no=" + out_trade_no + "&total_fee=" + total_fee + "&seller_email=" + Server.UrlEncode(seller_email) + "&sign=" + sign);
}
public void ProcessRequest(HttpContext context)
{
context.Response.ContentType = "text/html";
context.Response.Write("支付宝消息返回到了我的商户网站的这个页面\r\n");
string out_trade_no = context.Request["out_trade_no"];//订单号。给PayGate.ashx传过去的out_trade_no再传回来
string returncode = context.Request["returncode"];//返回码,字符串。ok为支付成功,error为支付失败。
string total_fee = context.Request["total_fee"];//支付金额
string sign = context.Request["sign"];//支付宝端返回 的数字签名
string MySign = CommonHelper.getMD5Str(out_trade_no + returncode + total_fee + "abc123");//为按顺序连接 (订单号、返回码、支付金额、商户密钥)为新字符串的MD5值。
if (sign!=MySign)
{
//提交的数据 =验证失败
context.Response.Write("提交的数据 =验证失败");
return;
}
if (returncode=="ok")
{
context.Response.Write("支付成功");
}
else if (returncode == "error")
{
context.Response.Write("支付失败");
}
}
转载自:https://blog.csdn.net/u014297475/article/details/52419202
彻头彻尾理解单例模式与多线程
摘要:
本文首先概述了单例模式产生动机,揭示了单例模式的本质和应用场景。紧接着,我们给出了单例模式在单线程环境下的两种经典实现:饿汉式 和 懒汉式,但是饿汉式是线程安全的,而懒汉式是非线程安全的。在多线程环境下,我们特别介绍了五种方式来在多线程环境下创建线程安全的单例,使用 synchronized方法、synchronized块、静态内部类、双重检查模式 和 ThreadLocal 实现懒汉式单例,并总结出实现效率高且线程安全的单例所需要注意的事项。
版权声明:
本文原创作者:书呆子Rico
作者博客地址:http://blog.csdn.net/justloveyou_/
一. 单例模式概述
单例模式(Singleton),也叫单子模式,是一种常用的设计模式。在应用这个模式时,单例对象的类必须保证只有一个实例存在。许多时候,整个系统只需要拥有一个的全局对象,这样有利于我们协调系统整体的行为。比如在某个服务器程序中,该服务器的配置信息存放在一个文件中,这些配置数据由一个单例对象统一读取,然后服务进程中的其他对象再通过这个单例对象获取这些配置信息,显然,这种方式简化了在复杂环境下的配置管理。
特别地,在计算机系统中,线程池、缓存、日志对象、对话框、打印机、显卡的驱动程序对象常被设计成单例。事实上,这些应用都或多或少具有资源管理器的功能。例如,每台计算机可以有若干个打印机,但只能有一个 Printer Spooler (单例) ,以避免两个打印作业同时输出到打印机中。再比如,每台计算机可以有若干通信端口,系统应当集中 (单例) 管理这些通信端口,以避免一个通信端口同时被两个请求同时调用。总之,选择单例模式就是为了避免不一致状态,避免政出多头。
综上所述,单例模式就是为确保一个类只有一个实例,并为整个系统提供一个全局访问点的一种方法。
二. 单例模式及其单线程环境下的经典实现
单例模式应该是23种设计模式中最简单的一种模式了,下面我们从单例模式的定义、类型、结构和使用要素四个方面来介绍它。
1、单例模式理论基础
定义: 确保一个类只有一个实例,并为整个系统提供一个全局访问点 (向整个系统提供这个实例)。
类型: 创建型模式
结构:
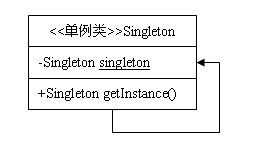
特别地,为了更好地理解上面的类图,我们以此为契机,介绍一下类图的几个知识点:
- 类图分为三部分,依次是类名、属性、方法;
- 以<<开头和以>>结尾的为注释信息;
- 修饰符+代表public,-代表private,#代表protected,什么都没有代表包可见;
- 带下划线的属性或方法代表是静态的。
三要素:
-
私有的构造方法;
-
指向自己实例的私有静态引用;
-
以自己实例为返回值的静态的公有方法。
2、单线程环境下的两种经典实现
在介绍单线程环境中单例模式的两种经典实现之前,我们有必要先解释一下 立即加载 和 延迟加载 两个概念。
-
立即加载 : 在类加载初始化的时候就主动创建实例;
-
延迟加载 : 等到真正使用的时候才去创建实例,不用时不去主动创建。
在单线程环境下,单例模式根据实例化对象时机的不同,有两种经典的实现:一种是 饿汉式单例(立即加载),一种是 懒汉式单例(延迟加载)。饿汉式单例在单例类被加载时候,就实例化一个对象并交给自己的引用;而懒汉式单例只有在真正使用的时候才会实例化一个对象并交给自己的引用。代码示例分别如下:
饿汉式单例:
// 饿汉式单例
public class Singleton1 { // 指向自己实例的私有静态引用,主动创建 private static Singleton1 singleton1 = new Singleton1(); // 私有的构造方法 private Singleton1(){} // 以自己实例为返回值的静态的公有方法,静态工厂方法 public static Singleton1 getSingleton1(){ return singleton1; } }我们知道,类加载的方式是按需加载,且加载一次。。因此,在上述单例类被加载时,就会实例化一个对象并交给自己的引用,供系统使用;而且,由于这个类在整个生命周期中只会被加载一次,因此只会创建一个实例,即能够充分保证单例。
懒汉式单例:
// 懒汉式单例
public class Singleton2 { // 指向自己实例的私有静态引用 private static Singleton2 singleton2; // 私有的构造方法 private Singleton2(){} // 以自己实例为返回值的静态的公有方法,静态工厂方法 public static synchronized Singleton2 getSingleton2(){ // 被动创建,在真正需要使用时才去创建 if (singleton2 == null) { singleton2 = new Singleton2(); } return singleton2; } }我们从懒汉式单例可以看到,单例实例被延迟加载,即只有在真正使用的时候才会实例化一个对象并交给自己的引用。
总之,从速度和反应时间角度来讲,饿汉式(又称立即加载)要好一些;从资源利用效率上说,懒汉式(又称延迟加载)要好一些。
3、单例模式的优点
我们从单例模式的定义和实现,可以知道单例模式具有以下几个优点:
-
在内存中只有一个对象,节省内存空间;
-
避免频繁的创建销毁对象,可以提高性能;
-
避免对共享资源的多重占用,简化访问;
-
为整个系统提供一个全局访问点。
4、单例模式的使用场景
由于单例模式具有以上优点,并且形式上比较简单,所以是日常开发中用的比较多的一种设计模式,其核心在于为整个系统提供一个唯一的实例,其应用场景包括但不仅限于以下几种:
- 有状态的工具类对象;
- 频繁访问数据库或文件的对象;
5、单例模式的注意事项
在使用单例模式时,我们必须使用单例类提供的公有工厂方法得到单例对象,而不应该使用反射来创建,否则将会实例化一个新对象。此外,在多线程环境下使用单例模式时,应特别注意线程安全问题,我在下文会重点讲到这一点。
三. 多线程环境下单例模式的实现
在单线程环境下,无论是饿汉式单例还是懒汉式单例,它们都能够正常工作。但是,在多线程环境下,情形就发生了变化:由于饿汉式单例天生就是线程安全的,可以直接用于多线程而不会出现问题;但懒汉式单例本身是非线程安全的,因此就会出现多个实例的情况,与单例模式的初衷是相背离的。下面我重点阐述以下几个问题:
-
为什么说饿汉式单例天生就是线程安全的?
-
传统的懒汉式单例为什么是非线程安全的?
-
怎么修改传统的懒汉式单例,使其线程变得安全?
-
线程安全的单例的实现还有哪些,怎么实现?
-
双重检查模式、Volatile关键字 在单例模式中的应用
-
ThreadLocal 在单例模式中的应用
特别地,为了能够更好的观察到单例模式的实现是否是线程安全的,我们提供了一个简单的测试程序来验证。该示例程序的判断原理是:
开启多个线程来分别获取单例,然后打印它们所获取到的单例的hashCode值。若它们获取的单例是相同的(该单例模式的实现是线程安全的),那么它们的hashCode值一定完全一致;若它们的hashCode值不完全一致,那么获取的单例必定不是同一个,即该单例模式的实现不是线程安全的,是多例的。注意,相应输出结果附在每个单例模式实现示例后。
若看官对上述原理不够了解,请移步我的博客《Java 中的 ==, equals 与 hashCode 的区别与联系》。
public class Test { public static void main(String[] args) { Thread[] threads = new Thread[10]; for (int i = 0; i < threads.length; i++) { threads[i] = new TestThread(); } for (int i = 0; i < threads.length; i++) { threads[i].start(); } } } class TestThread extends Thread { @Override public void run() { // 对于不同单例模式的实现,只需更改相应的单例类名及其公有静态工厂方法名即可 int hash = Singleton5.getSingleton5().hashCode(); System.out.println(hash); } }1、为什么说饿汉式单例天生就是线程安全的?
// 饿汉式单例
public class Singleton1 { // 指向自己实例的私有静态引用,主动创建 private static Singleton1 singleton1 = new Singleton1(); // 私有的构造方法 private Singleton1(){} // 以自己实例为返回值的静态的公有方法,静态工厂方法 public static Singleton1 getSingleton1(){ return singleton1; } }/* Output(完全一致): 1028355155 1028355155 1028355155 1028355155 1028355155 1028355155 1028355155 1028355155 1028355155 1028355155 *///:~我们已经在上面提到,类加载的方式是按需加载,且只加载一次。因此,在上述单例类被加载时,就会实例化一个对象并交给自己的引用,供系统使用。换句话说,在线程访问单例对象之前就已经创建好了。再加上,由于一个类在整个生命周期中只会被加载一次,因此该单例类只会创建一个实例,也就是说,线程每次都只能也必定只可以拿到这个唯一的对象。因此就说,饿汉式单例天生就是线程安全的。
2、传统的懒汉式单例为什么是非线程安全的?
// 传统懒汉式单例
public class Singleton2 { // 指向自己实例的私有静态引用 private static Singleton2 singleton2; // 私有的构造方法 private Singleton2(){} // 以自己实例为返回值的静态的公有方法,静态工厂方法 public static synchronized Singleton2 getSingleton2(){ // 被动创建,在真正需要使用时才去创建 if (singleton2 == null) { singleton2 = new Singleton2(); } return singleton2; } }/* Output(不完全一致): 1084284121 2136955031 2136955031 1104499981 298825033 298825033 2136955031 482535999 298825033 2136955031 *///:~上面发生非线程安全的一个显著原因是,会有多个线程同时进入 if (singleton2 == null) {…} 语句块的情形发生。当这种这种情形发生后,该单例类就会创建出多个实例,违背单例模式的初衷。因此,传统的懒汉式单例是非线程安全的。
3、实现线程安全的懒汉式单例的几种正确姿势
1)、同步延迟加载 — synchronized方法
// 线程安全的懒汉式单例
public class Singleton2 { private static Singleton2 singleton2; private Singleton2(){} // 使用 synchronized 修饰,临界资源的同步互斥访问 public static synchronized Singleton2 getSingleton2(){ if (singleton2 == null) { singleton2 = new Singleton2(); } return singleton2; } }/* Output(完全一致): 1104499981 1104499981 1104499981 1104499981 1104499981 1104499981 1104499981 1104499981 1104499981 1104499981 *///:~该实现与上面传统懒汉式单例的实现唯一的差别就在于:是否使用 synchronized 修饰 getSingleton2()方法。若使用,就保证了对临界资源的同步互斥访问,也就保证了单例。
从执行结果上来看,问题已经解决了,但是这种实现方式的运行效率会很低,因为同步块的作用域有点大,而且锁的粒度有点粗。同步方法效率低,那我们考虑使用同步代码块来实现。
更多关于 synchronized 关键字 的介绍, 请移步我的博文《Java 并发:内置锁 Synchronized》。
2)、同步延迟加载 — synchronized块
// 线程安全的懒汉式单例
public class Singleton2 { private static Singleton2 singleton2; private Singleton2(){} public static Singleton2 getSingleton2(){ synchronized(Singleton2.class){ // 使用 synchronized 块,临界资源的同步互斥访问 if (singleton2 == null) { singleton2 = new Singleton2(); } } return singleton2; } }/* Output(完全一致): 16993205 16993205 16993205 16993205 16993205 16993205 16993205 16993205 16993205 16993205 *///:~该实现与上面synchronized方法版本实现类似,此不赘述。从执行结果上来看,问题已经解决了,但是这种实现方式的运行效率仍然比较低,事实上,和使用synchronized方法的版本相比,基本没有任何效率上的提高。
3)、同步延迟加载 — 使用内部类实现延迟加载
// 线程安全的懒汉式单例
public class Singleton5 { // 私有内部类,按需加载,用时加载,也就是延迟加载 private static class Holder { private static Singleton5 singleton5 = new Singleton5(); } private Singleton5() { } public static Singleton5 getSingleton5() { return Holder.singleton5; } } /* Output(完全一致): 482535999 482535999 482535999 482535999 482535999 482535999 482535999 482535999 482535999 482535999 *///:~如上述代码所示,我们可以使用内部类实现线程安全的懒汉式单例,这种方式也是一种效率比较高的做法。至于其为什么是线程安全的,其与问题 “为什么说饿汉式单例天生就是线程安全的?” 相类似,此不赘述。
更多关于 内部类 的介绍, 请移步我的博文《 Java 内部类综述 》。
关于使用双重检查、ThreaLocal实现线程安全的懒汉式单例分别见第四节和第五节。
四. 单例模式与双重检查(Double-Check idiom)
使用双重检测同步延迟加载去创建单例的做法是一个非常优秀的做法,其不但保证了单例,而且切实提高了程序运行效率。对应的代码清单如下:
// 线程安全的懒汉式单例
public class Singleton3 { //使用volatile关键字防止重排序,因为 new Instance()是一个非原子操作,可能创建一个不完整的实例 private static volatile Singleton3 singleton3; private Singleton3() { } public static Singleton3 getSingleton3() { // Double-Check idiom if (singleton3 == null) { synchronized (Singleton3.class) { // 1 // 只需在第一次创建实例时才同步 if (singleton3 == null) { // 2 singleton3 = new Singleton3(); // 3 } } } return singleton3; } }/* Output(完全一致): 1104499981 1104499981 1104499981 1104499981 1104499981 1104499981 1104499981 1104499981 1104499981 1104499981 *///:~ 如上述代码所示,为了在保证单例的前提下提高运行效率,我们需要对 singleton3 进行第二次检查,目的是避开过多的同步(因为这里的同步只需在第一次创建实例时才同步,一旦创建成功,以后获取实例时就不需要同步获取锁了)。这种做法无疑是优秀的,但是我们必须注意一点:
必须使用volatile关键字修饰单例引用。
那么,如果上述的实现没有使用 volatile 修饰 singleton3,会导致什么情形发生呢? 为解释该问题,我们分两步来阐述:
(1)、当我们写了 new 操作,JVM 到底会发生什么?
首先,我们要明白的是: new Singleton3() 是一个非原子操作。代码行 singleton3 = new Singleton3(); 的执行过程可以形象地用如下3行伪代码来表示:
memory = allocate(); //1:分配对象的内存空间 ctorInstance(memory); //2:初始化对象 singleton3 = memory; //3:使singleton3指向刚分配的内存地址但实际上,这个过程可能发生无序写入(指令重排序),也就是说上面的3行指令可能会被重排序导致先执行第3行后执行第2行,也就是说其真实执行顺序可能是下面这种:
memory = allocate(); //1:分配对象的内存空间 singleton3 = memory; //3:使singleton3指向刚分配的内存地址 ctorInstance(memory); //2:初始化对象这段伪代码演示的情况不仅是可能的,而且是一些 JIT 编译器上真实发生的现象。
(2)、重排序情景再现
了解 new 操作是非原子的并且可能发生重排序这一事实后,我们回过头看使用 Double-Check idiom 的同步延迟加载的实现:
我们需要重新考察上述清单中的 //3 行。此行代码创建了一个 Singleton 对象并初始化变量 singleton3 来引用此对象。这行代码存在的问题是,在 Singleton 构造函数体执行之前,变量 singleton3 可能提前成为非 null 的,即赋值语句在对象实例化之前调用,此时别的线程将得到的是一个不完整(未初始化)的对象,会导致系统崩溃。下面是程序可能的一组执行步骤:
1、线程 1 进入 getSingleton3() 方法;
2、由于 singleton3 为 null,线程 1 在 //1 处进入 synchronized 块;
3、同样由于 singleton3 为 null,线程 1 直接前进到 //3 处,但在构造函数执行之前,使实例成为非 null,并且该实例是未初始化的;
4、线程 1 被线程 2 预占;
5、线程 2 检查实例是否为 null。因为实例不为 null,线程 2 得到一个不完整(未初始化)的 Singleton 对象;
6、线程 2 被线程 1 预占。
7、线程 1 通过运行 Singleton3 对象的构造函数来完成对该对象的初始化。
显然,一旦我们的程序在执行过程中发生了上述情形,就会造成灾难性的后果,而这种安全隐患正是由于指令重排序的问题所导致的。让人兴奋地是,volatile 关键字正好可以完美解决了这个问题。也就是说,我们只需使用volatile关键字修饰单例引用就可以避免上述灾难。
特别地,由于 volatile关键字的介绍 和 类加载及对象初始化顺序 两块内容已经在我之前的博文中介绍过,再此只给出相关链接,不再赘述。
更多关于 volatile关键字 的介绍, 请移步我的博文《 Java 并发:volatile 关键字解析》。
更多关于 类加载及对象初始化顺序的介绍, 请移步我的博文《 Java 继承、多态与类的复用》。
五. 单例模式 与 ThreadLocal
借助于 ThreadLocal,我们可以实现双重检查模式的变体。我们将临界资源线程局部化,具体到本例就是将双重检测的第一层检测条件 if (instance == null) 转换为 线程局部范围内的操作 。这里的 ThreadLocal 也只是用作标识而已,用来标识每个线程是否已访问过:如果访问过,则不再需要走同步块,这样就提高了一定的效率。对应的代码清单如下:
// 线程安全的懒汉式单例
public class Singleton4 { // ThreadLocal 线程局部变量 private static ThreadLocal<Singleton4> threadLocal = new ThreadLocal<Singleton4>(); private static Singleton4 singleton4 = null; // 不需要是 private Singleton4(){} public static Singleton4 getSingleton4(){ if (threadLocal.get() == null) { // 第一次检查:该线程是否第一次访问 createSingleton4(); } return singleton4; } public static void createSingleton4(){ synchronized (Singleton4.class) { if (singleton4 == null) { // 第二次检查:该单例是否被创建 singleton4 = new Singleton4(); // 只执行一次 } } threadLocal.set(singleton4); // 将单例放入当前线程的局部变量中 } }/* Output(完全一致): 1028355155 1028355155 1028355155 1028355155 1028355155 1028355155 1028355155 1028355155 1028355155 1028355155 *///:~借助于 ThreadLocal,我们也可以实现线程安全的懒汉式单例。但与直接双重检查模式使用,本实现在效率上还不如后者。
更多关于 ThreadLocal 的介绍, 请移步我的博文《 Java 并发:深入理解 ThreadLocal》。
六. 小结
本文首先介绍了单例模式的定义和结构,并给出了其在单线程和多线程环境下的几种经典实现。特别地,我们知道,传统的饿汉式单例无论在单线程还是多线程环境下都是线程安全的,但是传统的懒汉式单例在多线程环境下是非线程安全的。为此,我们特别介绍了五种方式来在多线程环境下创建线程安全的单例,包括:
-
使用synchronized方法实现懒汉式单例;
-
使用synchronized块实现懒汉式单例;
-
使用静态内部类实现懒汉式单例;
-
使用双重检查模式实现懒汉式单例;
-
使用ThreadLocal实现懒汉式单例;
当然,实现懒汉式单例还有其他方式。但是,这五种是比较经典的实现,也是我们应该掌握的几种实现方式。从这五种实现中,我们可以总结出,要想实现效率高的线程安全的单例,我们必须注意以下两点:
-
尽量减少同步块的作用域;
-
尽量使用细粒度的锁。
七. 更多
本文涉及内容比较广,涉及到 hashcode、synchronized 关键字、内部类、 类加载及对象初始化顺序、volatile关键字 和 ThreadLocal 等知识点,这些知识点在我之前的博文中均专门总结过,现附上相关链接,感兴趣的朋友可以移步到相关博文进行查看。
更多关于 hashCode 与相等 的介绍,请移步我的博客《Java 中的 ==, equals 与 hashCode 的区别与联系》。
更多关于 synchronized 关键字 的介绍, 请移步我的博文《Java 并发:内置锁 Synchronized》。
更多关于 内部类 的介绍, 请移步我的博文《 Java 内部类综述 》
更多关于 volatile关键字 的介绍, 请移步我的博文《 Java 并发:volatile 关键字解析》。
更多关于 类加载及对象初始化顺序的介绍, 请移步我的博文《 Java 继承、多态与类的复用》。
更多关于 ThreadLocal 的介绍, 请移步我的博文《 Java 并发:深入理解 ThreadLocal》。
此外,
更多关于 Java SE 进阶 方面的内容,请关注我的专栏 《Java SE 进阶之路》。本专栏主要研究Java基础知识、Java源码和设计模式,从初级到高级不断总结、剖析各知识点的内在逻辑,贯穿、覆盖整个Java知识面,在一步步完善、提高把自己的同时,把对Java的所学所思分享给大家。万丈高楼平地起,基础决定你的上限,让我们携手一起勇攀Java之巅…
更多关于 Java 并发编程 方面的内容,请关注我的专栏 《Java 并发编程学习笔记》。本专栏全面记录了Java并发编程的相关知识,并结合操作系统、Java内存模型和相关源码对并发编程的原理、技术、设计、底层实现进行深入分析和总结,并持续跟进并发相关技术。
引用
Java 中的双重检查(Double-Check)
单例模式与双重检测
用happen-before规则重新审视DCL
JAVA设计模式之单例模式
23种设计模式(1):单例模式
转载自:http://www.mamicode.com/info-detail-1728587.html
App.Config详解及读写操作
配置文件的根节点是configuration。我们经常访问的是appSettings,它是由.Net预定义配置节。我们经常使用的配置文件的架构是象下面的形式。
先大概有个印象,通过后面的实例会有一个比较清楚的认识。下面的“配置节”可以理解为进行配置一个XML的节点。
1. 向项目添加 app.config 文件:
}
读语句:
写语句:
cfa.AppSettings.Settings["DemoKey"].Value = "DemoValue";
cfa.Save();
配置文件内容格式:(app.config)
红笔标明的几个关键节是必须的
但是现在FrameWork2.0已经明确表示此属性已经过时。并建议改为ConfigurationManager
或WebConfigurationManager。并且AppSettings属性是只读的,并不支持修改属性值.
但是要想调用ConfigurationManager必须要先在工程里添加system.configuration.dll程序集的引用。
(在解决方案管理器中右键点击工程名称,在右键菜单中选择添加引用,.net TablePage下即可找到)
添加引用后可以用 String str = ConfigurationManager.AppSettings["Key"]来获取对应的值了。
更新配置文件:
等等...
最后调用
cfa.Save();
当前的配置文件更新成功。
*****************************************************************************************************************
读写配置文件app.config
在.Net中提供了配置文件,让我们可以很方面的处理配置信息,这个配置是XML格式的。而且.Net中已经提供了一些访问这个文件的功能。
1、读取配置信息
下面是一个配置文件的具体内容:
.net提供了可以直接访问
2、设置配置信息
如果配置信息是静态的,我们可以手工配置,要注意格式。如果配置信息是动态的,就需要我们写程序来实现。在.Net中没有写配置文件的功能,我们可以使用操作XML文件的方式来操作配置文件。下面就是一个写配置文件的例子。
{
XmlDocument doc=new XmlDocument();
//获得配置文件的全路径
string strFileName=AppDomain.CurrentDomain.BaseDirectory.ToString()
doc.LOAd(strFileName);
//找出名称为“add”的所有元素
XmlNodeList nodes=doc.GetElementsByTagName("add");
for(int i=0;i
//获得将当前元素的key属性
XmlAttribute att=nodes[i].Attributes["key"];
//根据元素的第一个属性来判断当前的元素是不是目标元素
if (att.Value=="ConnectionString")
{
//对目标元素中的第二个属性赋值
att=nodes[i].Attributes["value"];
att.Value=ConnenctionString;
break;
}
}
//保存上面的修改
doc.Save(strFileName);
}
判断客户端是iOS还是Android,判断是不是在微信浏览器打开
bool flag = false;
string agent = System.Web.HttpContext.Current.Request.UserAgent.ToLower();
string[] keywords = { "iphone", "ipod", "ipad", "itouch" };
foreach (string item in keywords)
{
if (agent.Contains(item))
{
flag = true;
break;
}
}
if (flag)
{
ViewBag.Phone = "iOS";
}
else {
ViewBag.Phone = "Android";
}
if (agent.ToLower().Contains("micromessenger")
{
微信浏览器
}