ThreadLocal夺命11连问
点击上方“芋道源码”,选择“设为星标”
管她前浪,还是后浪?
能浪的浪,才是好浪!
每天 10:33 更新文章,每天掉亿点点头发...
源码精品专栏
原创 | Java 2021 超神之路,很肝~
中文详细注释的开源项目
RPC 框架 Dubbo 源码解析
网络应用框架 Netty 源码解析
消息中间件 RocketMQ 源码解析
数据库中间件 Sharding-JDBC 和 MyCAT 源码解析
作业调度中间件 Elastic-Job 源码解析
分布式事务中间件 TCC-Transaction 源码解析
Eureka 和 Hystrix 源码解析
Java 并发源码
前言
1. 为什么要用ThreadLocal?
2. ThreadLocal的原理是什么?
3. 为什么用ThreadLocal做key?
4. Entry的key为什么设计成弱引用?
5. ThreadLocal真的会导致内存泄露?
6. 如何解决内存泄露问题?
7. ThreadLocal是如何定位数据的?
8. ThreadLocal是如何扩容的?
9. 父子线程如何共享数据?
10. 线程池中如何共享数据?
11. ThreadLocal有哪些用途?
前言
前一段时间,有同事使用ThreadLocal踩坑了,正好引起了我的兴趣。
所以近期,我抽空把ThreadLocal的源码再研究了一下,越看越有意思,发现里面的东西还真不少。
我把精华浓缩了一下,汇集成了下面11个问题,看看你能顶住第几个?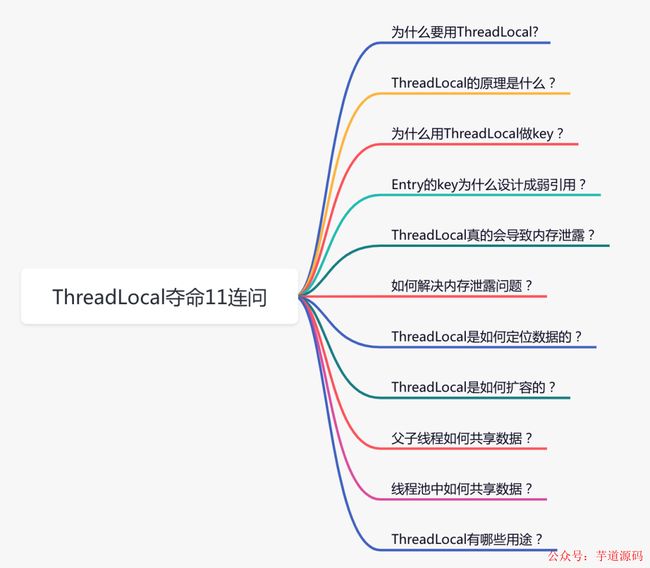
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能。
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
1. 为什么要用ThreadLocal?
并发编程是一项非常重要的技术,它让我们的程序变得更加高效。
但在并发的场景中,如果有多个线程同时修改公共变量,可能会出现线程安全问题,即该变量最终结果可能出现异常。
为了解决线程安全问题,JDK出现了很多技术手段,比如:使用synchronized或Lock,给访问公共资源的代码上锁,保证了代码的原子性。
但在高并发的场景中,如果多个线程同时竞争一把锁,这时会存在大量的锁等待,可能会浪费很多时间,让系统的响应时间一下子变慢。
因此,JDK还提供了另外一种用空间换时间的新思路:ThreadLocal。
它的核心思想是:共享变量在每个线程都有一个副本,每个线程操作的都是自己的副本,对另外的线程没有影响。
例如:
@Service
public class ThreadLocalService {
private static final ThreadLocal threadLocal = new ThreadLocal<>();
public void add() {
threadLocal.set(1);
doSamething();
Integer integer = threadLocal.get();
}
} 基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。
项目地址:https://github.com/YunaiV/onemall
2. ThreadLocal的原理是什么?
为了搞清楚ThreadLocal的底层实现原理,我们不得不扒一下源码。
ThreadLocal的内部有一个静态的内部类叫:ThreadLocalMap。
public class ThreadLocal {
...
public T get() {
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程的成员变量ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
if (map != null) {
//根据threadLocal对象从map中获取Entry对象
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
//获取保存的数据
T result = (T)e.value;
return result;
}
}
//初始化数据
return setInitialValue();
}
private T setInitialValue() {
//获取要初始化的数据
T value = initialValue();
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程的成员变量ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
//如果map不为空
if (map != null)
//将初始值设置到map中,key是this,即threadLocal对象,value是初始值
map.set(this, value);
else
//如果map为空,则需要创建新的map对象
createMap(t, value);
return value;
}
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程的成员变量ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
//如果map不为空
if (map != null)
//将值设置到map中,key是this,即threadLocal对象,value是传入的value值
map.set(this, value);
else
//如果map为空,则需要创建新的map对象
createMap(t, value);
}
static class ThreadLocalMap {
...
}
...
} ThreadLocal的get方法、set方法和setInitialValue方法,其实最终操作的都是ThreadLocalMap类中的数据。
其中ThreadLocalMap类的内部如下:
static class ThreadLocalMap {
static class Entry extends WeakReference> {
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
}
...
private Entry[] table;
...
} ThreadLocalMap里面包含一个静态的内部类Entry,该类继承于WeakReference类,说明Entry是一个弱引用。
ThreadLocalMap内部还包含了一个Entry数组,其中:Entry = ThreadLocal + value。
而ThreadLocalMap被定义成了Thread类的成员变量。
public class Thread implements Runnable {
...
ThreadLocal.ThreadLocalMap threadLocals = null;
}下面用一张图从宏观上,认识一下ThreadLocal的整体结构: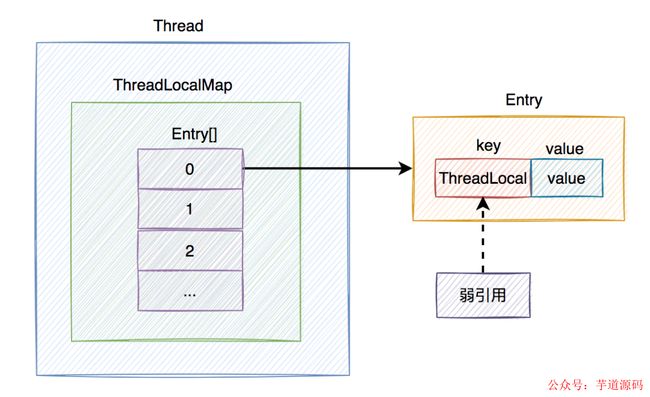 从上图中看出,在每个
从上图中看出,在每个Thread类中,都有一个ThreadLocalMap的成员变量,该变量包含了一个Entry数组,该数组真正保存了ThreadLocal类set的数据。
Entry是由threadLocal和value组成,其中threadLocal对象是弱引用,在GC的时候,会被自动回收。而value就是ThreadLocal类set的数据。
下面用一张图总结一下引用关系: 上图中除了Entry的key对ThreadLocal对象是
上图中除了Entry的key对ThreadLocal对象是弱引用,其他的引用都是强引用。
需要特别说明的是,上图中ThreadLocal对象我画到了堆上,其实在实际的业务场景中不一定在堆上。因为如果ThreadLocal被定义成了static的,ThreadLocal的对象是类共用的,可能出现在方法区。
3. 为什么用ThreadLocal做key?
不知道你有没有思考过这样一个问题:ThreadLocalMap为什么要用ThreadLocal做key,而不是用Thread做key?
如果在你的应用中,一个线程中只使用了一个ThreadLocal对象,那么使用Thread做key也未尝不可。
@Service
public class ThreadLocalService {
private static final ThreadLocal threadLocal = new ThreadLocal<>();
} 但实际情况中,你的应用,一个线程中很有可能不只使用了一个ThreadLocal对象。这时使用Thread做key不就出有问题?
@Service
public class ThreadLocalService {
private static final ThreadLocal threadLocal1 = new ThreadLocal<>();
private static final ThreadLocal threadLocal2 = new ThreadLocal<>();
private static final ThreadLocal threadLocal3 = new ThreadLocal<>();
} 假如使用Thread做key时,你的代码中定义了3个ThreadLocal对象,那么,通过Thread对象,它怎么知道要获取哪个ThreadLocal对象呢?
如下图所示:
因此,不能使用Thread做key,而应该改成用ThreadLocal对象做key,这样才能通过具体ThreadLocal对象的get方法,轻松获取到你想要的ThreadLocal对象。
如下图所示:
4. Entry的key为什么设计成弱引用?
前面说过,Entry的key,传入的是ThreadLocal对象,使用了WeakReference对象,即被设计成了弱引用。
那么,为什么要这样设计呢?
假如key对ThreadLocal对象的弱引用,改为强引用。 我们都知道ThreadLocal变量对ThreadLocal对象是有强引用存在的。
我们都知道ThreadLocal变量对ThreadLocal对象是有强引用存在的。
即使ThreadLocal变量生命周期完了,设置成null了,但由于key对ThreadLocal还是强引用。
此时,如果执行该代码的线程使用了线程池,一直长期存在,不会被销毁。
就会存在这样的强引用链:Thread变量 -> Thread对象 -> ThreadLocalMap -> Entry -> key -> ThreadLocal对象。
那么,ThreadLocal对象和ThreadLocalMap都将不会被GC回收,于是产生了内存泄露问题。
为了解决这个问题,JDK的开发者们把Entry的key设计成了弱引用。
弱引用的对象,在GC做垃圾清理的时候,就会被自动回收了。
如果key是弱引用,当ThreadLocal变量指向null之后,在GC做垃圾清理的时候,key会被自动回收,其值也被设置成null。
如下图所示: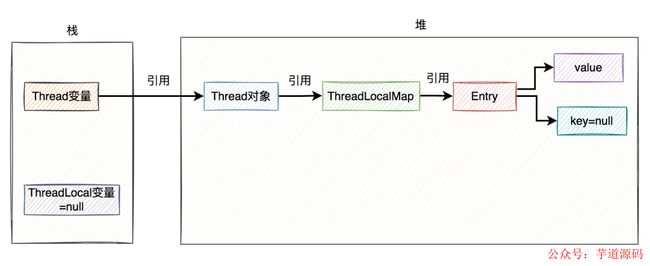 接下来,最关键的地方来了。
接下来,最关键的地方来了。
由于当前的ThreadLocal变量已经被指向null了,但如果直接调用它的get、set或remove方法,很显然会出现空指针异常。因为它的生命已经结束了,再调用它的方法也没啥意义。
此时,如果系统中还定义了另外一个ThreadLocal变量b,调用了它的get、set或remove,三个方法中的任何一个方法,都会自动触发清理机制,将key为null的value值清空。
如果key和value都是null,那么Entry对象会被GC回收。如果所有的Entry对象都被回收了,ThreadLocalMap也会被回收了。
这样就能最大程度的解决内存泄露问题。
需要特别注意的地方是:
key为null的条件是,ThreadLocal变量指向
null,并且key是弱引用。如果ThreadLocal变量没有断开对ThreadLocal的强引用,即ThreadLocal变量没有指向null,GC就贸然的把弱引用的key回收了,不就会影响正常用户的使用?如果当前ThreadLocal变量指向
null了,并且key也为null了,但如果没有其他ThreadLocal变量触发get、set或remove方法,也会造成内存泄露。
下面看看弱引用的例子:
public static void main(String[] args) {
WeakReference打印结果:
java.lang.Object@1ef7fe8e
null传入WeakReference构造方法的是直接new处理的对象,没有其他引用,在调用gc方法后,弱引用对象会被自动回收。
但如果出现下面这种情况:
public static void main(String[] args) {
Object object = new Object();
WeakReference执行结果:
java.lang.Object@1ef7fe8e
java.lang.Object@1ef7fe8e先定义了一个强引用object对象,在WeakReference构造方法中将object对象的引用作为参数传入。这时,调用gc后,弱引用对象不会被自动回收。
我们的Entry对象中的key不就是第二种情况吗?在Entry构造方法中传入的是ThreadLocal对象的引用。
如果将object强引用设置为null:
public static void main(String[] args) {
Object object = new Object();
WeakReference执行结果:
java.lang.Object@6f496d9f
java.lang.Object@6f496d9f
null第二次gc之后,弱引用能够被正常回收。
由此可见,如果强引用和弱引用同时关联一个对象,那么这个对象是不会被GC回收。也就是说这种情况下Entry的key,一直都不会为null,除非强引用主动断开关联。
此外,你可能还会问这样一个问题:Entry的value为什么不设计成弱引用?
答:Entry的value不只是被Entry引用,有可能被业务系统中的很多地方引用了。如果value改成了弱引用,被GC贸然回收了(数据突然没了),可能会导致业务系统出现异常。
而相比之下,Entry的key,引用的地方就非常明确了。
这就是Entry的key被设计成弱引用,而value没被设计成弱引用的原因。
5. ThreadLocal真的会导致内存泄露?
通过上面的Entry对象中的key设置成弱引用,并且使用get、set或remove方法清理key为null的value值,就能彻底解决内存泄露问题?
答案是否定的。
如下图所示: 假如ThreadLocalMap中存在很多key为null的Entry,但后面的程序,一直都没有调用过有效的ThreadLocal的
假如ThreadLocalMap中存在很多key为null的Entry,但后面的程序,一直都没有调用过有效的ThreadLocal的get、set或remove方法。
那么,Entry的value值一直都没被清空。
所以会存在这样一条强引用链:Thread变量 -> Thread对象 -> ThreadLocalMap -> Entry -> value -> Object。
其结果就是:Entry和ThreadLocalMap将会长期存在下去,会导致内存泄露。
6. 如何解决内存泄露问题?
前面说过的ThreadLocal还是会导致内存泄露的问题,我们有没有解决办法呢?
答:有办法,调用ThreadLocal对象的remove方法。
不是在一开始就调用remove方法,而是在使用完ThreadLocal对象之后。列如:
先创建一个CurrentUser类,其中包含了ThreadLocal的逻辑。
public class CurrentUser {
private static final ThreadLocal THREA_LOCAL = new ThreadLocal();
public static void set(UserInfo userInfo) {
THREA_LOCAL.set(userInfo);
}
public static UserInfo get() {
THREA_LOCAL.get();
}
public static void remove() {
THREA_LOCAL.remove();
}
} 然后在业务代码中调用相关方法:
public void doSamething(UserDto userDto) {
UserInfo userInfo = convert(userDto);
try{
CurrentUser.set(userInfo);
...
//业务代码
UserInfo userInfo = CurrentUser.get();
...
} finally {
CurrentUser.remove();
}
}需要我们特别注意的地方是:一定要在finally代码块中,调用remove方法清理没用的数据。如果业务代码出现异常,也能及时清理没用的数据。
remove方法中会把Entry中的key和value都设置成null,这样就能被GC及时回收,无需触发额外的清理机制,所以它能解决内存泄露问题。
7. ThreadLocal是如何定位数据的?
前面说过ThreadLocalMap对象底层是用Entry数组保存数据的。
那么问题来了,ThreadLocal是如何定位Entry数组数据的?
在ThreadLocal的get、set、remove方法中都有这样一行代码:
int i = key.threadLocalHashCode & (len-1);通过key的hashCode值,与数组的长度减1。其中key就是ThreadLocal对象,与数组的长度减1,相当于除以数组的长度减1,然后取模。
这是一种hash算法。
接下来给大家举个例子:假设len=16,key.threadLocalHashCode=31,
于是:int i = 31 & 15 = 1
相当于:int i = 31 % 15 = 1
计算的结果是一样的,但是使用与运算效率跟高一些。
为什么与运算效率更高?
答:因为ThreadLocal的初始大小是16,每次都是按2倍扩容,数组的大小其实一直都是2的n次方。这种数据有个规律就是高位是0,低位都是1。在做与运算时,可以不用考虑高位,因为与运算的结果必定是0。只需考虑低位的与运算,所以效率更高。
如果使用hash算法定位具体位置的话,就可能会出现hash冲突的情况,即两个不同的hashCode取模后的值相同。
ThreadLocal是如何解决hash冲突的呢?
我们看看getEntry是怎么做的:
private Entry getEntry(ThreadLocal key) {
//通过hash算法获取下标值
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
//如果下标位置上的key正好是我们所需要寻找的key
if (e != null && e.get() == key)
//说明找到数据了,直接返回
return e;
else
//说明出现hash冲突了,继续往后找
return getEntryAfterMiss(key, i, e);
}再看看getEntryAfterMiss方法:
private Entry getEntryAfterMiss(ThreadLocal key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
//判断Entry对象如果不为空,则一直循环
while (e != null) {
ThreadLocal k = e.get();
//如果当前Entry的key正好是我们所需要寻找的key
if (k == key)
//说明这次真的找到数据了
return e;
if (k == null)
//如果key为空,则清理脏数据
expungeStaleEntry(i);
else
//如果还是没找到数据,则继续往后找
i = nextIndex(i, len);
e = tab[i];
}
return null;
}关键看看nextIndex方法:
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}当通过hash算法计算出的下标小于数组大小,则将下标值加1。否则,即下标大于等于数组大小,下标变成0了。下标变成0之后,则循环一次,下标又变成1。。。
寻找的大致过程如下图所示: 如果找到最后一个,还是没有找到,则再从头开始找。
如果找到最后一个,还是没有找到,则再从头开始找。 不知道你有没有发现,它构成了一个:
不知道你有没有发现,它构成了一个:环形。
ThreadLocal从数组中找数据的过程大致是这样的:
通过key的hashCode取余计算出一个下标。
通过下标,在数组中定位具体Entry,如果key正好是我们所需要的key,说明找到了,则直接返回数据。
如果第2步没有找到我们想要的数据,则从数组的下标位置,继续往后面找。
如果第3步中找key的正好是我们所需要的key,说明找到了,则直接返回数据。
如果还是没有找到数据,再继续往后面找。如果找到最后一个位置,还是没有找到数据,则再从头,即下标为0的位置,继续从前往后找数据。
直到找到第一个Entry为空为止。
8. ThreadLocal是如何扩容的?
从上面得知,ThreadLocal的初始大小是16。那么问题来了,ThreadLocal是如何扩容的?
在set方法中会调用rehash方法:
private void set(ThreadLocal key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}注意一下,其中有个判断条件是:sz(之前的size+1)如果大于或等于threshold的话,则调用rehash方法。
threshold默认是0,在创建ThreadLocalMap时,调用它的构造方法:
ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}调用setThreshold方法给threshold设置一个值,而这个值INITIAL_CAPACITY是默认的大小16。
private void setThreshold(int len) {
threshold = len * 2 / 3;
}也就是第一次设置的threshold = 16 * 2 / 3, 取整后的值是:10。
换句话说当sz大于等于10时,就可以考虑扩容了。
rehash代码如下:
private void rehash() {
//先尝试回收一次key为null的值,腾出一些空间
expungeStaleEntries();
if (size >= threshold - threshold / 4)
resize();
}在真正扩容之前,先尝试回收一次key为null的值,腾出一些空间。
如果回收之后的size大于等于threshold的3/4时,才需要真正的扩容。
计算公式如下:
16 * 2 * 4 / 3 * 4 - 16 * 2 / 3 * 4 = 8也就是说添加数据后,新的size大于等于老size的1/2时,才需要扩容。
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
//按2倍的大小扩容
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}resize中每次都是按2倍的大小扩容。
扩容的过程如下图所示: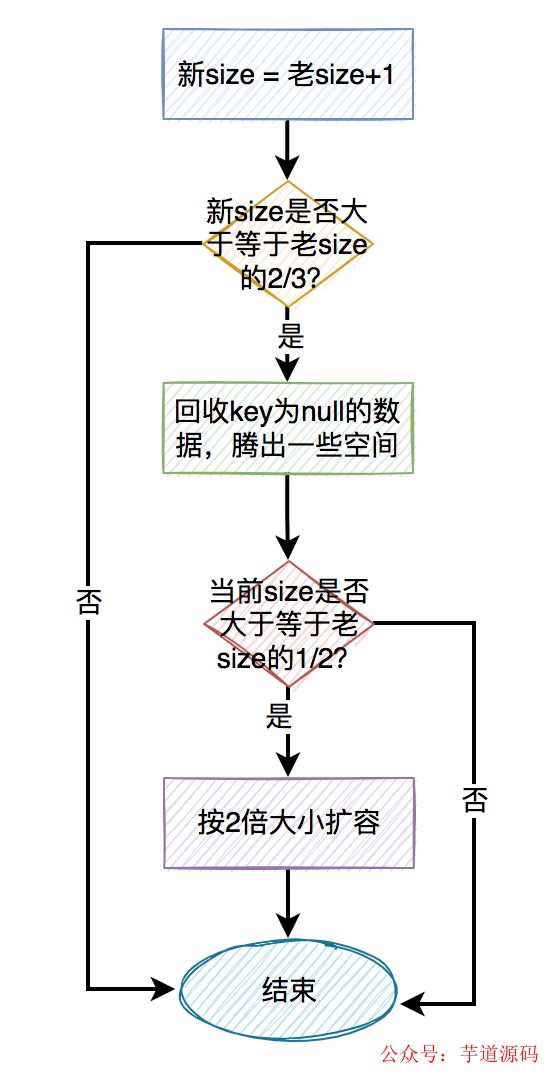 扩容的关键步骤如下:
扩容的关键步骤如下:
老size + 1 = 新size
如果新size大于等于老size的2/3时,需要考虑扩容。
扩容前先尝试回收一次key为null的值,腾出一些空间。
如果回收之后发现size还是大于等于老size的1/2时,才需要真正的扩容。
每次都是按2倍的大小扩容。
9. 父子线程如何共享数据?
前面介绍的ThreadLocal都是在一个线程中保存和获取数据的。
但在实际工作中,有可能是在父子线程中共享数据的。即在父线程中往ThreadLocal设置了值,在子线程中能够获取到。
例如:
public class ThreadLocalTest {
public static void main(String[] args) {
ThreadLocal threadLocal = new ThreadLocal<>();
threadLocal.set(6);
System.out.println("父线程获取数据:" + threadLocal.get());
new Thread(() -> {
System.out.println("子线程获取数据:" + threadLocal.get());
}).start();
}
} 执行结果:
父线程获取数据:6
子线程获取数据:null你会发现,在这种情况下使用ThreadLocal是行不通的。main方法是在主线程中执行的,相当于父线程。在main方法中开启了另外一个线程,相当于子线程。
显然通过ThreadLocal,无法在父子线程中共享数据。
那么,该怎么办呢?
答:使用InheritableThreadLocal,它是JDK自带的类,继承了ThreadLocal类。
修改代码之后:
public class ThreadLocalTest {
public static void main(String[] args) {
InheritableThreadLocal threadLocal = new InheritableThreadLocal<>();
threadLocal.set(6);
System.out.println("父线程获取数据:" + threadLocal.get());
new Thread(() -> {
System.out.println("子线程获取数据:" + threadLocal.get());
}).start();
}
} 执行结果:
父线程获取数据:6
子线程获取数据:6果然,在换成InheritableThreadLocal之后,在子线程中能够正常获取父线程中设置的值。
其实,在Thread类中除了成员变量threadLocals之外,还有另一个成员变量:inheritableThreadLocals。
Thread类的部分代码如下:
ThreadLocal.ThreadLocalMap threadLocals = null;
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;最关键的一点是,在它的init方法中会将父线程中往ThreadLocal设置的值,拷贝一份到子线程中。
感兴趣的小伙伴,可以找我私聊。或者看看我后面的文章,后面还会有专栏。
10. 线程池中如何共享数据?
在真实的业务场景中,一般很少用单独的线程,绝大多数,都是用的线程池。
那么,在线程池中如何共享ThreadLocal对象生成的数据呢?
因为涉及到不同的线程,如果直接使用ThreadLocal,显然是不合适的。
我们应该使用InheritableThreadLocal,具体代码如下:
private static void fun1() {
InheritableThreadLocal threadLocal = new InheritableThreadLocal<>();
threadLocal.set(6);
System.out.println("父线程获取数据:" + threadLocal.get());
ExecutorService executorService = Executors.newSingleThreadExecutor();
threadLocal.set(6);
executorService.submit(() -> {
System.out.println("第一次从线程池中获取数据:" + threadLocal.get());
});
threadLocal.set(7);
executorService.submit(() -> {
System.out.println("第二次从线程池中获取数据:" + threadLocal.get());
});
} 执行结果:
父线程获取数据:6
第一次从线程池中获取数据:6
第二次从线程池中获取数据:6由于这个例子中使用了单例线程池,固定线程数是1。
第一次submit任务的时候,该线程池会自动创建一个线程。因为使用了InheritableThreadLocal,所以创建线程时,会调用它的init方法,将父线程中的inheritableThreadLocals数据复制到子线程中。所以我们看到,在主线程中将数据设置成6,第一次从线程池中获取了正确的数据6。
之后,在主线程中又将数据改成7,但在第二次从线程池中获取数据却依然是6。
因为第二次submit任务的时候,线程池中已经有一个线程了,就直接拿过来复用,不会再重新创建线程了。所以不会再调用线程的init方法,所以第二次其实没有获取到最新的数据7,还是获取的老数据6。
那么,这该怎么办呢?
答:使用TransmittableThreadLocal,它并非JDK自带的类,而是阿里巴巴开源jar包中的类。
可以通过如下pom文件引入该jar包:
com.alibaba
transmittable-thread-local
2.11.0
compile
代码调整如下:
private static void fun2() throws Exception {
TransmittableThreadLocal threadLocal = new TransmittableThreadLocal<>();
threadLocal.set(6);
System.out.println("父线程获取数据:" + threadLocal.get());
ExecutorService ttlExecutorService = TtlExecutors.getTtlExecutorService(Executors.newFixedThreadPool(1));
threadLocal.set(6);
ttlExecutorService.submit(() -> {
System.out.println("第一次从线程池中获取数据:" + threadLocal.get());
});
threadLocal.set(7);
ttlExecutorService.submit(() -> {
System.out.println("第二次从线程池中获取数据:" + threadLocal.get());
});
} 执行结果:
父线程获取数据:6
第一次从线程池中获取数据:6
第二次从线程池中获取数据:7我们看到,使用了TransmittableThreadLocal之后,第二次从线程中也能正确获取最新的数据7了。
nice。
如果你仔细观察这个例子,你可能会发现,代码中除了使用TransmittableThreadLocal类之外,还使用了TtlExecutors.getTtlExecutorService方法,去创建ExecutorService对象。
这是非常重要的地方,如果没有这一步,TransmittableThreadLocal在线程池中共享数据将不会起作用。
创建ExecutorService对象,底层的submit方法会TtlRunnable或TtlCallable对象。
以TtlRunnable类为例,它实现了Runnable接口,同时还实现了它的run方法:
public void run() {
Map, Object> copied = (Map)this.copiedRef.get();
if (copied != null && (!this.releaseTtlValueReferenceAfterRun || this.copiedRef.compareAndSet(copied, (Object)null))) {
Map backup = TransmittableThreadLocal.backupAndSetToCopied(copied);
try {
this.runnable.run();
} finally {
TransmittableThreadLocal.restoreBackup(backup);
}
} else {
throw new IllegalStateException("TTL value reference is released after run!");
}
} 这段代码的主要逻辑如下:
把当时的ThreadLocal做个备份,然后将父类的ThreadLocal拷贝过来。
执行真正的run方法,可以获取到父类最新的ThreadLocal数据。
从备份的数据中,恢复当时的ThreadLocal数据。
11. ThreadLocal有哪些用途?
最后,一起聊聊ThreadLocal有哪些用途?
老实说,使用ThreadLocal的场景挺多的。
下面列举几个常见的场景:
在spring事务中,保证一个线程下,一个事务的多个操作拿到的是一个Connection。
在hiberate中管理session。
在JDK8之前,为了解决SimpleDateFormat的线程安全问题。
获取当前登录用户上下文。
临时保存权限数据。
使用MDC保存日志信息。
等等,还有很多业务场景,这里就不一一列举了。
由于篇幅有限,今天的内容先分享到这里。希望你看了这篇文章,会有所收获。
接下来留几个问题给大家思考一下:
ThreadLocal变量为什么建议要定义成static的?
Entry数组为什么要通过hash算法计算下标,即直线寻址法,而不直接使用下标值?
强引用和弱引用有什么区别?
Entry数组大小,为什么是2的N次方?
使用InheritableThreadLocal时,如果父线程中重新set值,在子线程中能够正确的获取修改后的新值吗?
欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:

已在知识星球更新源码解析如下:




最近更新《芋道 SpringBoot 2.X 入门》系列,已经 101 余篇,覆盖了 MyBatis、Redis、MongoDB、ES、分库分表、读写分离、SpringMVC、Webflux、权限、WebSocket、Dubbo、RabbitMQ、RocketMQ、Kafka、性能测试等等内容。
提供近 3W 行代码的 SpringBoot 示例,以及超 4W 行代码的电商微服务项目。
获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)