数据上采样和下采样
By Isaac Backus and Bernease Herman
艾萨克·巴库斯(Isaac Backus)和伯尼瑟斯·赫曼(Bernease Herman)
It’s 2020 and most of us still don’t know when, where, why, or how our models go wrong in production. While we all know that “what can go wrong, will go wrong,” or that “the best-laid plans of mice and [data scientists] often go awry,” complicated models and data pipelines are all too often pushed to production with little attention paid to diagnosing the inevitable unforeseen failures.
到了2020年,我们大多数人仍然不知道何时,何地,为什么或我们的模型在生产中出现问题。 尽管我们都知道“哪里可能出毛病,都会出毛病”,或者“老鼠和[数据科学家]的最佳计划经常出错”,但复杂的模型和数据管道却往往很少投入生产重视诊断不可避免的意外故障。
In traditional software, logging and instrumentation have been adopted as standard practice to create transparency and make sense of the health of a complex system. When it comes to AI applications, logging is often spotty and incomplete. In this post, we outline different approaches to ML logging, comparing and contrasting them. Finally, we offer an open source library called WhyLogs that enables data logging and profiling only in a few lines of code.
在传统软件中,日志记录和检测已被用作标准做法,以创建透明性并了解复杂系统的运行状况。 当涉及到AI应用程序时,日志记录往往参差不齐且不完整。 在本文中,我们概述了ML日志记录的不同方法,并对其进行了比较和对比。 最后,我们提供了一个名为WhyLogs的开源库,该库仅用几行代码就可以进行数据记录和分析。
什么是传统软件中的日志记录? (What is logging in traditional software?)
Logging is an important tool for developing and operating robust software systems. When your production system reaches an error state, it is important to have tools to better locate and diagnose the source of the problem.
日志记录是开发和运行强大的软件系统的重要工具。 当生产系统达到错误状态时,拥有可更好地定位和诊断问题根源的工具非常重要。
For many software engineering disciplines, a stack trace helps to locate the execution path and determine the state of the program at the time of failure. However, a stack trace does not give insight on how the state has changed prior to failure. Logging (along with its related term, software tracing) is a practice in which program execution and event information are stored to one or many files. Logging is essential to diagnosing issues with software of all kinds; a must have for production systems.
对于许多软件工程学科而言,堆栈跟踪有助于定位执行路径并确定故障时程序的状态。 但是,堆栈跟踪无法提供有关故障之前状态如何变化的见解。 日志记录(及其相关术语,即软件跟踪)是一种将程序执行和事件信息存储到一个或多个文件的实践。 日志对于诊断各种软件的问题至关重要。 生产系统必须具备的。

数据记录有何不同?(How is data logging different?)
Statistical applications, such as those in data science and machine learning, are prime candidates for requiring logging. However, due to the complexity of these applications the available tools remain limited and their adoption is much less widespread than standard software logging.
诸如数据科学和机器学习中的统计应用程序是需要日志记录的主要候选对象。 但是,由于这些应用程序的复杂性,可用工具仍然受到限制,与标准软件日志记录相比,它们的采用范围不广。
Statistical applications are often non-deterministic and require many state changes. Due to the requirement of handling a broad distribution of states, strict, logical assertions must be avoided and machine learning software will often never reach an error state, instead silently producing a poor or incorrect result. This makes error analysis far more difficult as maintainers are not alerted to the problem as it occurs.
统计应用程序通常是不确定的,并且需要进行许多状态更改。 由于需要处理状态的广泛分布,因此必须避免使用严格的逻辑断言,并且机器学习软件通常永远不会达到错误状态,而只会静默地产生不良或不正确的结果。 这使错误分析变得更加困难,因为维护人员不会在问题发生时就对其发出警报。
When error states are detected, diagnosing the issue is often laborious. In contrast to explicitly defined software, datasets are especially opaque to introspection. Whereas software is fully specified by code and developers can easily include precise logging statements to pinpoint issues, datasets and data pipelines require significant analysis to diagnose.
当检测到错误状态时,诊断问题通常很麻烦。 与明确定义的软件相反,数据集对于内省而言尤其不透明。 尽管软件完全由代码指定,并且开发人员可以轻松地包含精确的日志记录语句来查明问题,但是数据集和数据管道需要大量分析才能进行诊断。
While effective logging practices in ML may be difficult to implement, in many cases they can be even more necessary than with standard software. In typical software development, an enormous amount of issues may be caught before deploying to production by compilers, IDEs, type checking, logical assertions, and standard testing. With data, things are not so simple. This motivates the need for improved tooling and best practices in ML operations which advance statistical logging.
尽管ML中有效的日志记录实践可能难以实现,但在许多情况下,与标准软件相比,它们甚至更必要。 在典型的软件开发中,在由编译器,IDE,类型检查,逻辑断言和标准测试部署到生产之前,可能会遇到大量问题。 有了数据,事情就不那么简单了。 这激发了对ML操作的改进工具和最佳实践的需求,以促进统计记录。
The generic requirements for good logging tools in software development may apply equally well in the ML operations domain as well. These requirements may include (but are of course not limited to) the following.
在软件开发中对好的日志记录工具的一般要求也同样适用于ML操作领域。 这些要求可能包括(但不限于)以下内容。
记录要求 (Logging requirements)
Ease of use
使用方便
Good logging aids in development by exposing internal functioning early and often to developers. If logging is clunky, no one is going to use it. Common logging modules in software development can be nearly as straightforward to use as print statements.
良好的日志记录会通过尽早向开发人员公开内部功能来帮助开发。 如果日志记录很笨拙,则没人会使用它。 软件开发中的常用日志记录模块几乎可以像打印语句一样直接使用。
Lightweight
轻巧的
Logging should not interfere with program execution, therefore it must be lightweight.
日志记录不应干扰程序执行,因此它必须是轻量级的。
Standardized and portable
标准化且便携
Modern systems are big and complex, and we must be able to debug them. Logging requires multi-language support. Output formats should be standard and easily searched, filtered, consumed, and analyzed easily from multiple sources.
现代系统既庞大又复杂,我们必须能够对其进行调试。 日志记录需要多语言支持。 输出格式应该是标准的,并且可以轻松地从多个来源进行搜索,过滤,使用和分析。
Configurable
可配置的
We must be able to modify verbosity, output location, possibly even formats, for all services without modifying the code. Verbosity and output requirements can be very different for a developer or a data scientist than on a production service.
我们必须能够修改所有服务的详细程度,输出位置,甚至可能是格式,而无需修改代码。 对于开发人员或数据科学家而言,详细度和输出要求可能会与生产服务完全不同。
Close to the code
接近代码
Logging calls should live within the code/service they refer to, and logging should let us very quickly pinpoint where the problem occurred within the service. Logging provides a systematic way to generate traces of the internal, logical functioning of a system.
记录调用应该存在于它们所引用的代码/服务中,并且记录应该使我们能够非常Swift地查明服务中出现问题的位置。 日志记录提供了一种系统的方式来生成对系统内部逻辑功能的跟踪。
ML日志记录有哪些可用的方法? (Which approaches are available when it comes to ML logging?)
标准代码内记录 (Standard in-code logging)
In data science, much can and should be done with standard logging modules. We can log data access, what steps (training, testing, etc…) are being executed. Model parameters and hyperparameters and greater details can be logged as well. Services and libraries focused on ML use cases (such as CometML) can expand the utility of such logging.
在数据科学中,使用标准日志记录模块可以而且应该做很多事情。 我们可以记录数据访问,正在执行哪些步骤(培训,测试等)。 模型参数和超参数以及更多详细信息也可以记录下来。 专注于ML用例的服务和库(例如CometML)可以扩展此类日志记录的实用程序。
While standard logging can provide much visibility, it provides little to no introspection into the data.
虽然标准日志记录可以提供很大的可见性,但是它几乎无法反省数据。
Pros
优点
- Flexible and configurable灵活且可配置
- Can track both intermediate results and data of low complexity可以跟踪中间结果和低复杂度的数据
- Allows reuse of existing non-ML logging tools允许重复使用现有的非ML日志记录工具
Cons
缺点
- High storage, I/O, and computational costs高存储,I / O和计算成本
- Logging format may be unfamiliar or inappropriate for data scientists日志记录格式可能对数据科学家不熟悉或不合适
- Log processing requires computationally expensive search, particularly for complex ML data日志处理需要计算量大的搜索,尤其是对于复杂的ML数据而言
- Lower data retention due to expensive storage costs; less useful for root cause analysis of past issues 由于昂贵的存储成本而降低了数据保留; 对于过去问题的根本原因分析没有多大用处
采样(Sampling)
A common approach to monitoring the enormous volumes of data typical to ML is to log a random subset of the data, whether during training, testing, or inference. It can be fairly straightforward and useful to randomly select some subset of the data and store it for reference later. Sampling-based data logging does not accurately represent outliers and rare events. As a result, important metrics such as minimum, maximum, and unique values can not be measured accurately. Outliers and uncommon values are important to retain as they often affect model behavior, cause problematic model predictions, and may be indicative of data quality issues.
监视ML典型的海量数据的一种常用方法是在训练,测试或推理期间记录数据的随机子集。 随机选择数据的某些子集并将其存储以供以后参考可能非常简单直接。 基于采样的数据记录不能准确表示异常值和稀有事件。 结果,无法准确地测量重要指标,例如最小值,最大值和唯一值。 异常值和异常值很重要,因为它们经常影响模型行为,导致模型预测有问题,并可能表示数据质量问题。
Pros
优点
- Straightforward to implement简单实施
- Requires less upfront design than other logging solutions与其他测井解决方案相比,所需的前期设计更少
- Log processing identical to analysis on raw data日志处理与原始数据分析相同
- Familiar data output format for data scientists数据科学家熟悉的数据输出格式
Cons
缺点
- High storage, I/O, and computational costs高存储,I / O和计算成本
- Noisy signals and limited coverage; small sample sizes required to be scalable and lightweight 信号嘈杂,覆盖范围有限; 小样本量要求可扩展且轻量
- Not human-readable or interpretable without statistical analysis processing step如果没有统计分析处理步骤,将无法被人类理解或解释
- Rare events and outliers will often be missed by sampling稀有事件和异常值通常会因采样而丢失
- Outlier-dependent metrics, such as min/max and unique values, cannot be accurately calculated无法精确计算与异常值相关的指标,例如最小值/最大值和唯一值
- Output format is dependent on the data, making it more difficult to integrate with monitoring, debugging, or introspection tools输出格式取决于数据,因此更难与监视,调试或自检工具集成
资料分析(Data profiling)
A promising approach to logging data is data profiling (also referred to as data sketching or statistical fingerprinting). The idea is to capture a human interpretable statistical profile of a given dataset to provide insight into the data. There already exist a broad range of efficient streaming algorithms to generate scalable, lightweight statistical profiles of datasets, and the literature is very active and growing. However, there exist significant engineering challenges around implementing these algorithms in practice, particularly in the context of ML logging. One project is working on overcoming these challenges.
记录数据的一种有前途的方法是数据概要分析(也称为数据素描或统计指纹识别)。 这个想法是捕获给定数据集的人类可解释的统计资料,以提供对数据的洞察力。 已经存在各种各样的有效流算法来生成可伸缩的,轻量级的数据集统计资料,并且文献非常活跃并且正在增长。 但是,在实践中围绕实现这些算法存在巨大的工程挑战,尤其是在ML日志记录的环境中。 一个项目正在致力于克服这些挑战。
Pros
优点
- Ease of use使用方便
- Scalable and lightweight可扩展且轻巧
- Flexible and configurable via text-based config files通过基于文本的配置文件灵活且可配置
- Accurately represents rare events and outlier-dependent metrics准确表示罕见事件和离群值相关指标
- Directly interpretable results (e.g., histograms, mean, std deviation, data type) without further processing可直接解释的结果(例如直方图,均值,标准差,数据类型),无需进一步处理
Cons
缺点
- No existing widespread solutions没有现有的广泛解决方案
- Involved mathematics and engineering problems behind solution解决方案背后涉及的数学和工程问题
使数据记录变得轻松而毫不妥协! 简介WhyLogs。 (Making data logging easy and uncompromising! Introducing WhyLogs.)
The data profiling solution, WhyLogs, is our contribution to modern, streamlined data logging to ML. WhyLogs is an open source library with the goal of bridging the ML logging gap by providing approximate data profiling and fulfilling the five logging requirements above (easy, lightweight, portable, configurable, close to code).
数据剖析解决方案WhyLogs是我们对ML现代化精简数据记录的贡献。 WhyLogs是一个开源库,其目的是通过提供近似的数据分析并满足上述五个日志记录要求(轻松,轻巧,可移植,可配置,接近代码)来弥合ML日志记录差距。
The estimated statistical profiles include per-feature distribution approximations which can provide histograms and quantiles, overall statistics such as min/max/standard deviation, uniqueness estimates, null counts, frequent items, and more. All statistical profiles are mergeable as well, making the algorithms trivially parallelizable, and allowing profiles of multiple datasets to be merged together for later analysis. This is key for achieving flexible granularity (since you can change aggregation levels, e.g., from hourly to daily or weekly) and for logging in distributed systems.
估计的统计资料包括按特征分布的近似值,可以提供直方图和分位数;总体统计信息,例如最小/最大/标准差,唯一性估计,空计数,频繁项等等。 所有统计配置文件也可以合并,从而使算法几乎可以并行化,并允许将多个数据集的配置文件合并在一起以供以后分析。 这是获得灵活粒度的关键(因为您可以更改聚合级别,例如,从每小时更改为每天或每周一次),并在分布式系统中进行记录。
WhyLogs also supports features that are suitable for production environments such as tagging, small memory footprint, and lightweight output.. Tagging and grouping features are key for enabling segment-level analysis and to map segments to core business KPIs.
WhyLogs还支持适用于生产环境的功能,例如标记,较小的内存占用量和轻量级输出。标记和分组功能是启用段级别分析并将段映射到核心业务KPI的关键。
轻巧便携 (Portable & Lightweight)
Currently, there are Python and Java implementations, which provide Python integration with pandas/numpy and scalable Java integration with Spark. The resulting log files are small and compatible across languages. We tested WhyLogs Java performance on the following datasets to validate WhyLogs memory footprint and the output binary size.
当前,有Python和Java实现,它们提供与pandas / numpy的Python集成以及与Spark的可伸缩Java集成。 生成的日志文件很小,并且可以跨语言兼容。 我们在以下数据集中测试了WhyLogs Java性能,以验证WhyLogs的内存占用量和输出二进制大小。
Lending Club Data: Kaggle Link
借贷俱乐部数据: Kaggle链接
NYC Tickets: Kaggle Link
纽约门票: Kaggle Link
Pain Pills in the USA: Kaggle Link
美国的止痛药: Kaggle链接
We ran our profile on each dataset and collected JMX metrics:
我们在每个数据集上运行配置文件并收集了JMX指标:
易于使用,可配置且接近代码 (Ease of use, Configurable & Close to code)
WhyLogs can be easily added to existing machine learning and data science code. The Python implementation can be `pip` installed and offers an interactive command line experience in addition to the library with an accessible API.
WhyLogs可以轻松添加到现有的机器学习和数据科学代码中。 Python实现可以安装在pip中,并且除了具有可访问API的库外,还提供了交互式命令行体验。
WhyLogs jupyter notebook example WhyLogs Jupyter笔记本示例更多例子(More Examples)
For more examples of using WhyLogs, check out the WhyLogs Getting Started notebook
有关使用WhyLogs的更多示例,请查看WhyLogs入门笔记本
强大的附加功能(Powerful Additional Features)
The full power of WhyLogs can be witnessed when combined with monitoring and other services for live data. To explore how these features pair with WhyLogs, check out the live sandbox of WhyLabs Platform running on a modified version of the Lending Club dataset and ingesting WhyLogs data daily.
与实时数据的监视和其他服务结合使用时,可以见证WhyLogs的全部功能。 要探索这些功能如何与WhyLogs配对,请查看在修改后的Lending Club数据集上运行的WhyLabs Platform实时沙盒,并每天提取WhyLogs数据。
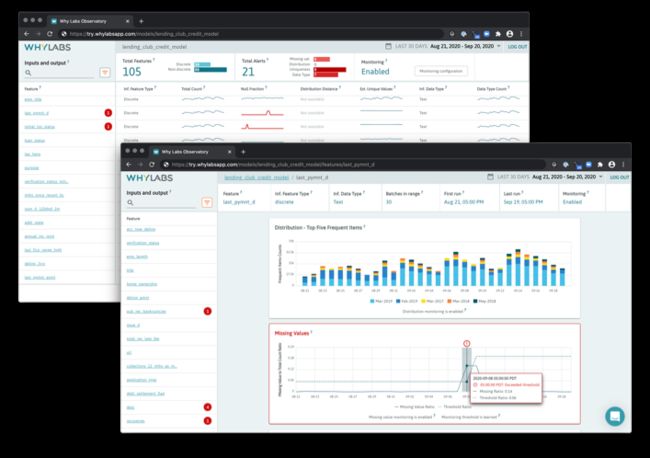
让我们使数据记录成为生产ML系统中的黄金标准!(Let’s make data logging a gold standard in production ML systems!)
Data science, machine learning, and the technology surrounding them are developing at a breakneck pace, along with the scale of these operations and the number of people involved in them. Along with that rapid growth comes the inevitable explosion of problems. Best practices remain very nascent in ML, but as has been the case with software and systems engineering, best practices must continue to grow and develop. Effective logging must certainly take a primary role among best practices for operating robust ML/AI systems. Projects like WhyLogs will be required to address the unique challenges of these statistical systems.
数据科学,机器学习以及围绕它们的技术以惊人的速度发展,这些操作的规模以及所涉及的人数也随之增长。 随着这种快速增长,不可避免地出现了问题的激增。 最佳实践在ML中仍处于萌芽状态,但是与软件和系统工程一样,最佳实践必须继续发展。 当然,有效的日志记录必须在操作健壮的ML / AI系统的最佳实践中起主要作用。 需要诸如WhyLogs之类的项目来应对这些统计系统的独特挑战。
Check out WhyLogs for Python here and Java here, or get started with the documentation. We love feedback and suggestions, so join our Slack channel or email us at [email protected]!
检查出的Python WhyLogs这里和Java在这里,或开始使用的文档。 我们喜欢反馈和建议,因此请加入我们的Slack频道或通过[email protected]向我们发送电子邮件!
Thanks to Bernease Herman, my WhyLabs teammate, for co-authoring the article. Follow Bernease on twitter
感谢我的WhyLabs队友Bernease Herman共同撰写了这篇文章。 在Twitter上关注Bernease
翻译自: https://towardsdatascience.com/sampling-isnt-enough-profile-your-ml-data-instead-6a28fcfb2bd4
数据上采样和下采样